- The paper introduces a novel byte-level Sequential Monte Carlo framework enabling globally normalized ensembling for language models.
- It demonstrates that consensus-seeking aggregation, particularly the product operator, significantly enhances structured text generation accuracy.
- Empirical results on tasks like JSON schema generation and Text-to-SQL validate that proper inference improves the synergy and robustness of LM ensembles.
Ensembling LLMs with Sequential Monte Carlo
LLM (LM) ensembles have demonstrated that models trained on distinct data or architectures can yield complementary error patterns. Traditional ensembling aggregates predictions from diverse models to improve predictive performance. However, for LLMs generating sequences, naive next-token probability averaging—while ubiquitous—yields only a locally normalized, biased approximation to the theoretically correct global ensemble string distribution. The primary challenge is that autoregressive LMs define distributions over strings, and string-level ensembling is intractable due to the exponentially large sequence space. Moreover, various ensembling strategies exist (e.g., product of experts, mixture, min, max), each imparting different inductive biases and potentially superior or inferior performance on language modeling tasks.
The paper introduces a formal framework for composing K LMs into $-ensemble distributions over strings using general aggregation functions. To enable rigorous model composition, particularly when models differ in their tokenization, the authors propose mapping models to character-level probabilistic models and develop a byte-level Sequential Monte Carlo (SMC) algorithm that admits arbitrary aggregation functions and consistent global sampling.
## Generalized Ensemble Distributions
A core contribution is the formalization of$-ensembles, where f is a user-chosen aggregation function over the string probabilities assigned by the base models. The ensemble distribution is defined as
q(y)=Zf(p1(y),…,pK(y))
where Z is the normalizer over all possible strings. For practical instantiations, the focus is on the family of generalized means, with parameter τ, which interpolate between consensus-seeking (e.g., min, product) and coverage-seeking (e.g., sum, max) behaviors. The choice of aggregation function is justified via a variational principle involving α-divergences, unifying many ensembling paradigms (mixture, product, min, max) under a single framework.
Crucially, the theoretical analysis shows that only consensus-seeking (τ≤0) operators focus mass on the intersection of high-probability outputs across models, while coverage-seeking (τ≥1) spread probability over the union. This has direct implications for ensembling efficacy, depending on the relative strengths and weaknesses of the models being combined.
Inference via Sequential Monte Carlo
Direct sampling from the globally normalized −ensembledistributionisintractable.ThepaperdevelopsasequentialimportancesamplingandSMCframeworkforautoregressiveLMsatthecharacterlevel.Byexploitingcharacter−levelrepresentations,themethodsidestepsthetokenizationmismatchissueinmulti−modelensembling,allowingarbitrarymodelcombinations.TheSMCprocedureincrementallyextends"particles"(partialstringhypotheses)usingtractablesurrogateproposaldistributionsderivedfromthelocalnext−symboldistributionsshapedbyf$. At each step, importance weights are updated, and periodic resampling reallocates computation to promising hypotheses. The algorithm is formally justified to provide unbiased normalization estimates and consistent importance weight updates, with the proposal optimality argument grounded in variance minimization of the importance weights. The SMC methodology admits any annihilative aggregation function—encompassing all generalized means—ensuring correctness.
## Empirical Results and Analysis
The experimental evaluation is systematic and comprehensive. Ensembles are tested on three structured text generation tasks: function-calling JSON schema generation, word sorting (Big-Bench Hard), and Text-to-SQL (SPIDER). For each task, the authors examine within-model prompt ensembles and cross-model ensembles across three LM families (Llama3, Qwen2.5, Phi-4), with rigorous baselines (best single prompt, local probability averaging, etc.).
Qualitative and quantitative findings are as follows:
- **Consensus-seeking ensembles (min, product)**: Substantial improvements in expected accuracy over both the best single-prompt and local-probability-averaged baselines. The product (PoE) operator consistently delivers the strongest gains, especially when both models have complementary capabilities.
- **Coverage-seeking ensembles (sum, max)**: Performance is generally bounded above by the best base model, sometimes degrading as predicted by theoretical expectations.
- **Impact of approximation quality**: For consensus-seeking ensembles, improved SMC posterior approximation directly correlates with increased expected accuracy, as measured via per-instance correlation between log marginal likelihood estimates and performance.
- **Synergistic effects**: Ensembles outperform base models mostly when both experts provide moderate but non-overlapping competence; when one dominates or both fail, ensembling provides little benefit. Cross-model ensembles can outperform any prompt-wise ensembles, indicating architectural and pretraining diversity as a critical ensembling asset.
- **Token vs. byte-level SMC**: Byte-level SMC enables unification across tokenizations but incurs additional computational overhead relative to token-level schemes.
(Figure 1)
*Figure 1: Prompt intersection experiment shows locally normalized ensembling misallocates string probability mass compared to globally normalized (SMC-based) ensembles, especially for intersectional completions (e.g., "Carl Sagan." vs. "a great guy.").*
(Figure 2)
*Figure 2:$-ensembles with SMC outperform the best single-prompt baselines, particularly consensus-seeking (product, min) operators.*
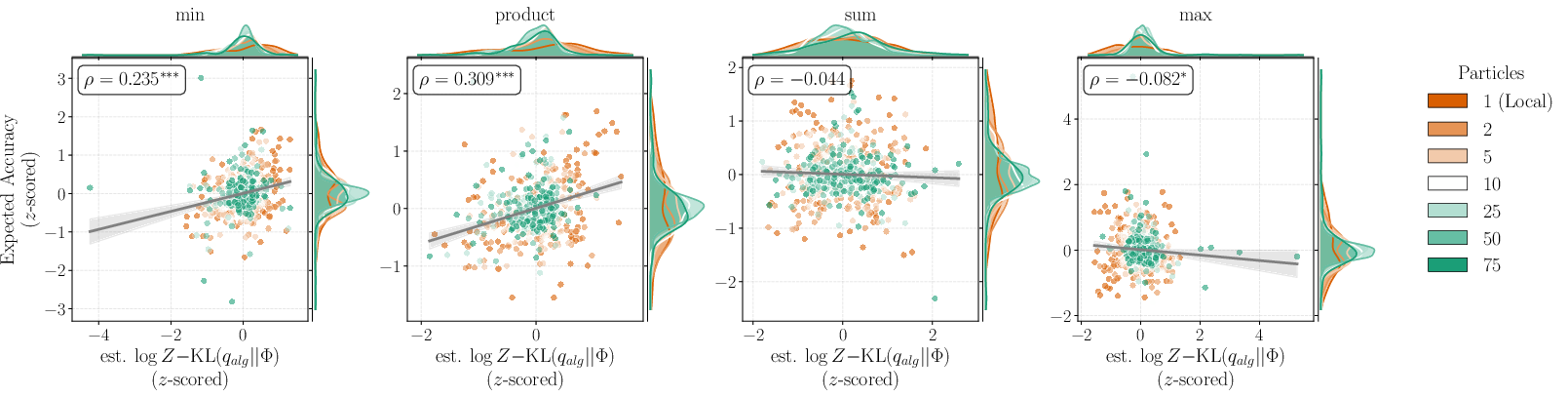
Figure 1: Expected accuracy versus log marginal likelihood on BBH for Llama; higher approximation quality (via more SMC particles) predicts better downstream accuracy.
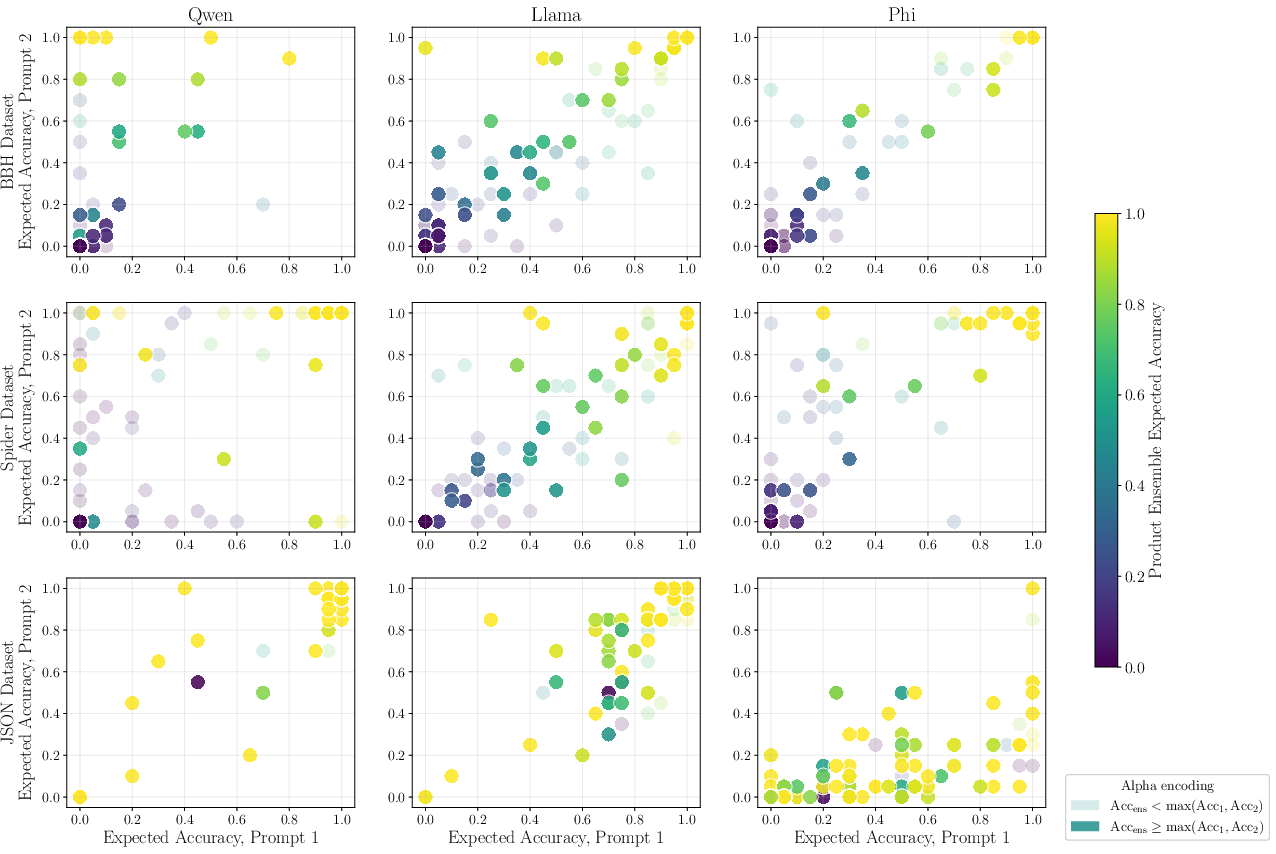
Figure 2: Prompt-level accuracy scatter shows ensemble gains are concentrated where both prompts are moderately competent, and ensembles rarely help when prompts disagree strongly.
Theoretical and Practical Implications
The demonstration that only consensus-seeking operators such as the product (PoE) and minimum can consistently outperform singular models on expected accuracy has strong implications for both the theory and practice of LM ensembling. In scenarios where model diversity reflects orthogonal strengths, harnessing consensus amplifies joint capabilities and reduces variance in prediction.
On a practical level, SMC-based global ensembling unlocks the ability to combine (1) models with incompatible tokenizers, (2) arbitrary prompt strategies, and (3) architectural heterogeneity. Approximate inference quality is crucial; increased particles or proposal sophistication can monotonically improve accuracy for consensus-based ensembles, but do not assist coverage-based ones.
The results challenge the practice of local next-token probability averaging as the de facto standard for model fusion at inference—a critical insight for practitioners designing high-stakes or controllable text generation pipelines.
Future Directions
The authors acknowledge computational constraints inherent to SMC, especially as the number of ensemble participants or level of output structure increases. Extending the framework to larger ensembles (K>2), higher-fidelity modeling of proposal distributions, and integration with routing/reranking schemes are natural extensions.
The demonstrated success of SMC in the multi-agent, multi-prompt LM setting suggests a larger role for probabilistic inference methods—beyond simple heuristic averaging—in advanced LM system design. Future work could also study the impact of domain overlap, specialization, or hierarchical ensembling strategies on both structured and free-form generation tasks.
Conclusion
The paper provides a rigorous unification of ensembling methods for LLMs, connecting variational inference, α-divergences, and classical ML ensembling frameworks. The adoption of byte-level SMC for global string-level inference solves long-standing challenges of tokenization mismatch and biased local ensembling. Empirical results confirm the theoretical predictions—model ensembles, when coupled with correct inference and principled aggregation (specifically, consensus-seeking), yield robust and repeatable improvements over constituent models. The practical significance for structured language generation and controlled text synthesis is substantial, and the methodological contributions lay a foundation for further advances in ensemble-based language modeling.