- The paper introduces a novel SSRR loss that reconstructs self-supervised speech representations to significantly improve intelligibility in streaming codecs.
- It employs a causal Transformer with optimized RVQ and FlashAttention, reducing word error rates by up to 50% at early training stages.
- The approach enforces semantic–acoustic alignment, ensuring robust performance in low-resource, real-time streaming and cross-lingual scenarios.
Self-Supervised Representation Reconstruction for High-Intelligibility Streaming Neural Audio Codecs
Introduction
The paper "Reconstruct! Don't Encode: Self-Supervised Representation Reconstruction Loss for High-Intelligibility and Low-Latency Streaming Neural Audio Codec" (2603.05887) addresses a critical limitation in neural audio codecs operating as tokenizers for LLM-driven speech generation. Conventional codecs optimize primarily for acoustic fidelity via mel-spectrogram and waveform losses, neglecting semantic and linguistic preservation. As such, applying these representations to text-to-speech and speech-to-speech tasks results in compromised intelligibility, particularly under streaming constraints for real-time systems. The authors propose a self-supervised representation reconstruction (SSRR) loss as an auxiliary objective, targeting the reconstruction of self-supervised speech representations (SSR) from codec outputs—shifting optimization from purely acoustic features toward linguistically meaningful ones.
Architecture and Design Choices
The JHCodec architecture implements a fully causal Transformer backbone, inspired by TS3-Codec, and optimized with FlashAttention for low-latency processing. The encoder and decoder each utilize 8 Transformer decoder layers with Pre-Layer Normalization, rotary positional embeddings, SwiGLU activations, and LayerScale. The input window of 320 samples is upsampled to a 1024-dimensional latent space.
Crucially, the codec employs residual vector quantization (RVQ) for latent discretization, evaluating both DAC-style and Mimi-style variants using 8 codebooks at a high frame rate (50 Hz) to maximize intelligibility while minimizing latency. Deep RVQ hierarchies, as used in Mimi [moshi], are mitigated by this configuration to avoid compounding latency and computational overhead.
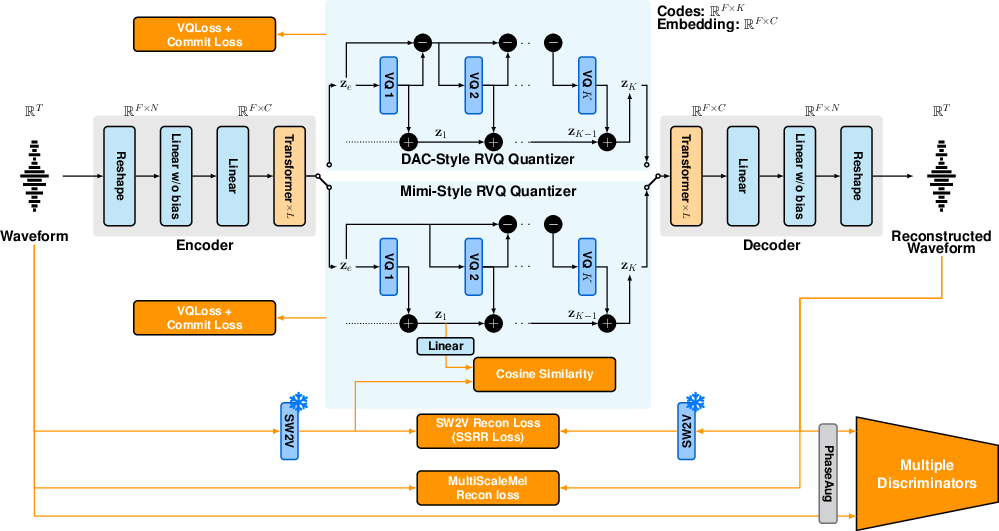
Figure 1: Overall system architecture of JHCodec, illustrating the two RVQ variants, DAC-style and Mimi-style.
To further enhance robustness, encoder inputs are occasionally perturbed with Gaussian or sinusoidal noise during training, leveraging GAN-based denoising effects.
Self-Supervised Representation Reconstruction Loss
The SSRR loss is formulated as an L1 distance between SSR features extracted from the original and reconstructed audio, employing a causal distilled variant of W2V-BERT 2.0 (SW2V). Unlike semantic encoder distillation (SED), which constrains only the encoder, SSRR directly propagates gradients through the decoder and quantizer, enforcing semantic consistency at the reconstruction stage.
This approach enables significant improvements in both convergence speed and intelligibility. The SSRR loss regularizes discrete representations, mitigating quantization drift and enforcing linguistically consistent tokenization, which is crucial in low-resource streaming scenarios.
Experimental Evaluation
Training Methodology
JHCodec models were trained on a diverse English corpus, including LibriTTS-R, MLS-en, VCTK, LibriHeavy-Large, HiFi-TTS, LJSpeech, RAVDESS, and Emilia. Training proceeded in stages, initially disabling SSRR and GAN losses for the first 10k steps to stabilize optimization.
Metrics
Intelligibility was measured via ASR-based word error rate (WER) and character error rate (CER), using Whisper Large-v3. Speaker similarity (S-SIM) employed WavLM embeddings, and perceptual quality followed UTMOS v2. Robustness was further benchmarked on the TITW-Hard test set and MLS non-English splits for cross-lingual generalization.
Ablations
Ablation studies highlighted the SSRR loss as the dominant factor improving WER and S-SIM, with nearly 50% reduction in WER at early training stages (300k steps on a single GPU). Mimi-style RVQ proved more robust than DAC-style under incomplete optimization, but the gap narrowed with extended training.
(Figure 2)
Figure 2: Ablation study shows SSRR loss halving WER for both RVQ variants at 300k steps across bitrates and improving S-SIM consistently.
Baseline Comparison
JHCodec-M-8 was compared with DAC-8, BigCodec, TAAE, NanoCodec (non-streaming), and Mimi-32, FocalCodec-Stream, MagiCodec (streaming). JHCodec achieves state-of-the-art WER, S-SIM, and perceptual quality with minimal latency and GPU training budget, outperforming Mimi-32 on clean data with a fraction of resources. RVQ quantizer dropout and optimized parallelism further enhance efficiency.
(Figure 3)
Figure 3: JHCodec achieves minimal end-to-end latency and competitive real-time factors compared to contemporary streaming codecs.
Downstream Implications and Future Directions
The SSRR loss presents a nuanced solution to the semantic-acoustic conflict observed in prior codecs, directly regularizing reconstructed content toward self-supervised linguistic features. This enables practical, high-intelligibility streaming codecs suitable for real-time dialogue and low-latency speech-to-speech systems, without reliance on heavy frame sizes or lookahead mechanisms. JHCodec's architecture achieves high performance on both clean and noisy benchmarks (LibriSpeech test-other, TITW-Hard), robust cross-lingual generalization, and efficient decoding—markedly lowering barriers for deployment in resource-constrained environments.
The theoretical implication is a shift from encoder-only semantic alignment (SED) to full-system semantic guarantee via decoder-involved SSRR loss. This paradigm could be extended to general audio codecs leveraging multimodal SSR models, expanding from speech-to-speech to universal audio generation and compression [samaudio].
Conclusion
The introduction of self-supervised representation reconstruction loss redefines optimization objectives in neural audio codec training, yielding substantial gains in intelligibility, convergence speed, and resource efficiency for streaming architectures. SSRR directly enforces semantic consistency in reconstructed audio, addressing fundamental shortcomings of acoustic-only or encoder-constrained losses. JHCodec’s practical architecture and open-source release catalyze future research in low-latency, high-intelligibility neural audio coding, with anticipated impact extending to universal audio representations and real-time generative AI systems.

