- The paper presents a novel Residual Masking Network that leverages Unet-based Masking Blocks to refine spatial features for improved FER.
- It demonstrates significant accuracy gains on FER2013 (up to 76.82% in ensemble mode) and VEMO datasets compared to state-of-the-art models.
- The approach enhances complex emotion recognition by emphasizing key facial regions, such as eyes and mouth, using localized attention scores.
Residual Masking Network for Facial Expression Recognition: Technical Summary
Problem Motivation and Context
Facial Expression Recognition (FER) is critical for HCI applications requiring robust emotion detection across variable real-world conditions. Classical methods relying on handcrafted features and facial landmark extraction suffer from performance degradation in uncontrolled environments due to occlusions and pose variations. Deep CNN-based approaches have improved FER accuracy but lack explicit spatial focus mechanisms for relevant facial regions, such as eyes and mouth, which are most informative for emotion discrimination. Integration of attention mechanisms has enhanced CNNs, but existing modules face limitations in scoring the importance of spatial features and localizing attention deeply.
Residual Masking Network Architecture
The Residual Masking Network (ResMaskingNet) introduces a novel Masking Block based on a Unet-like structure, embedded within a deep residual backbone (ResNet34), to refine spatial feature maps and generate localized attention scores across multiple resolution levels. Each Residual Masking Block combines a residual unit with a Masking Block. The Masking Block acts as an attention facility, using encoder-decoder pathways to generate score maps characterizing pixel-wise importance. These scores are fused element-wise to the feature maps, producing refined activation maps and preventing undesired feature suppression via residual learning. This facilitates enhanced attention to emotion-related facial regions throughout the CNN hierarchy.
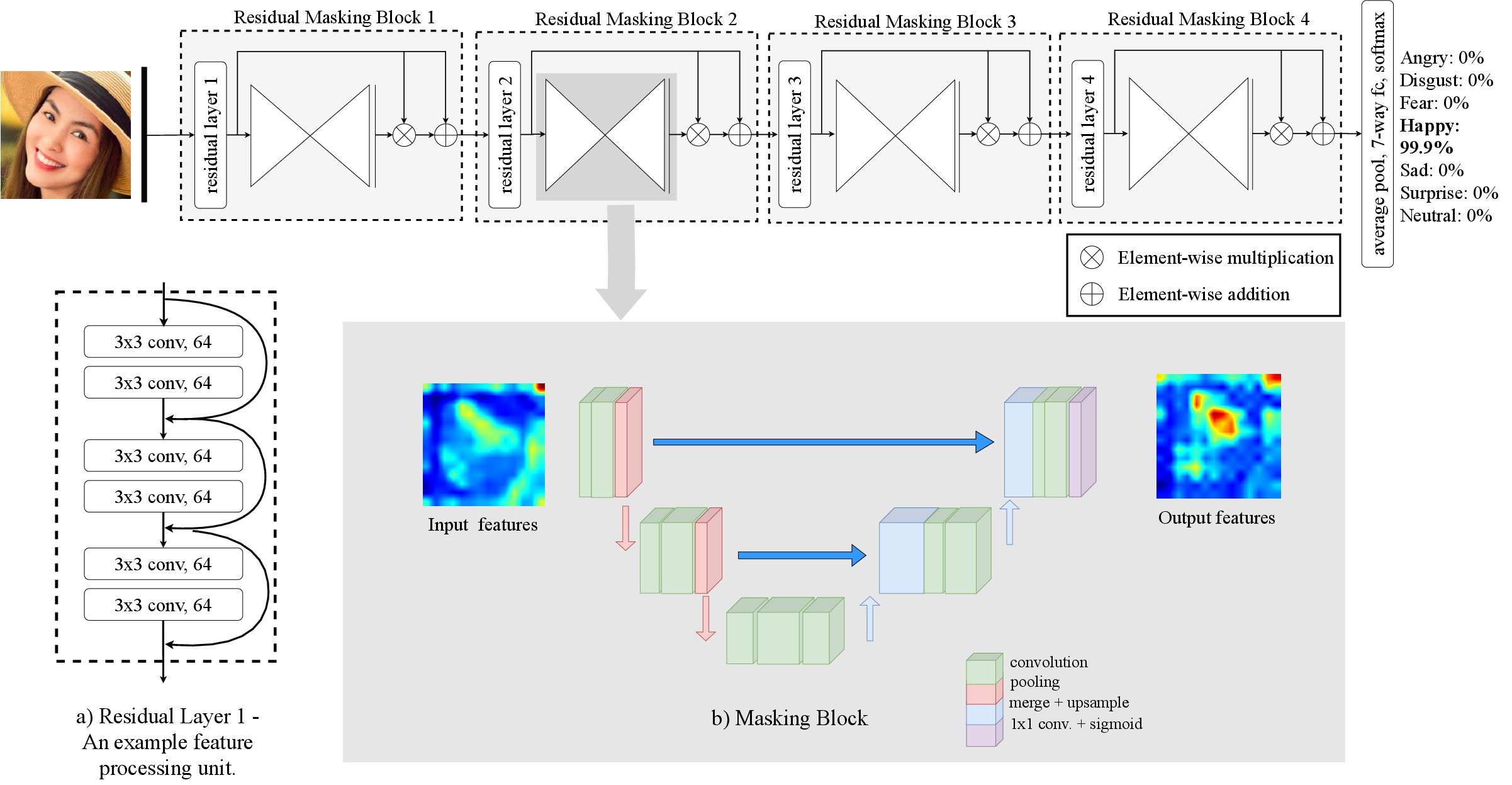
Figure 1: High-level overview of the Residual Masking Network illustrating the sequential arrangement of Residual Masking Blocks.
Masking Block and Spatial Attention Mechanism
The Masking Block operationalizes spatial attention by leveraging an Unet-based localization network at each residual stage; it computes importance masks on feature maps, highlighting relevant facial regions. The process combines the residual output FR and the mask FM via FN=FR+FR⊗FM, ensuring the focus on critical details while retaining the original feature information. This design explicitly boosts attention to areas such as the mouth and eyes, substantiated by activation visualizations and Grad-CAM overlays.
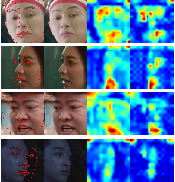
Figure 2: Examples showcasing facial landmark detection, input image, and activation maps before and after the Masking Block, revealing enhanced attention to facial regions post-masking.

Figure 3: Grad-CAM visualizations of testing images indicating concentrated network attention near the mouth and eyes, validating the Masking Block’s spatial efficacy.
Experimental Evaluation
The Residual Masking Network was evaluated on both the FER2013 benchmark and a newly collected VEMO dataset. Training conditions featured standard image preprocessing, augmentation, and hyperparameter setups consistent with SOTA baselines for direct comparison. ResMaskingNet outperformed established models (e.g., ResNet152, CBAM-ResNet50, Densenet121) in accuracy and demonstrated strong real-time inference speed (100 fps per single face on consumer hardware).
On FER2013:
- ResMaskingNet achieved 74.14% accuracy in non-ensemble mode, surpassing all comparable CNN architectures.
- In ensemble mode (with six additional CNNs), ResMaskingNet produced 76.82% accuracy, outperforming ensemble baselines by more than 1%.
On VEMO:
- ResMaskingNet yielded 65.94% classification accuracy, exceeding ResAttNet56, ResNet18, and ResNet34.


Figure 4: Representative images from FER2013 and VEMO datasets illustrating variation in facial expression categories.
Figure 5: Diagrammatic structure of the experimental framework detailing model setup and data flow.
Analysis of Recognition and Error Patterns
Quantitative assessments via confusion matrices revealed high recognition rates for happiness (0.91) and surprise (0.85), while fear and sadness registered lower accuracies (0.56 and 0.59, respectively). Class imbalance and inherent subjectivity in emotion annotation contribute to these discrepancies. Error analysis highlighted common misclassifications arising from ambiguous facial expressions or unreliable ground-truth labels, aligning with known human limitations (human accuracy ~65%).
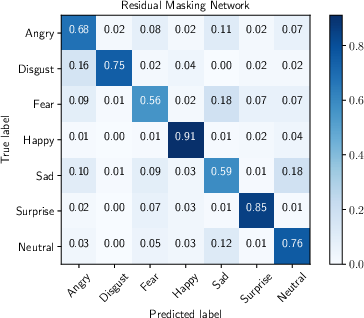
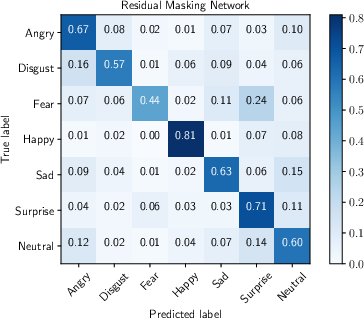
Figure 6: Confusion matrices for FER2013 and VEMO datasets, illustrating per-class prediction fidelity.

Figure 7: Examples of mispredicted expressions on FER2013 and VEMO datasets, demonstrating typical error cases (Ground truth / Prediction).
Implications and Future Directions
The integration of Masking Blocks within residual architectures establishes a flexible and effective mechanism for spatial attention in FER. The proposed network demonstrates superior accuracy and scalability within real-time constraints. The methodology is generalizable and can be extended to other vision tasks requiring localized attention, such as object detection and fine-grained classification. Key future avenues include parameter optimization for deployment in resource-constrained environments, evaluation on larger datasets (e.g., ImageNet), and adaptation to multimodal HCI systems.
Conclusion
This work introduces the Residual Masking Network, which employs Unet-based Masking Blocks nested within a deep residual backbone for advanced spatial attention in FER tasks. Empirical results across public and private datasets substantiate the network's enhanced accuracy, particularly for complex and imbalanced emotional categories. The Masking Block framework offers a modular upgrade path for attention mechanisms within CNNs and signals promising applicability to broader computer vision challenges, with further developments anticipated in generalization and efficiency optimizations (2603.05937).