- The paper introduces CODEC, a method leveraging sparse autoencoders to extract sparse contribution modes that reveal the causal drivers of neural network outputs.
- It employs gradient-based attribution and PCA to quantify hidden units’ causal effects, demonstrating superior interpretability over traditional activation-based methods.
- The framework enables precise output control via targeted ablation experiments and extends its applicability to both artificial and biological neural networks.
Causal Contribution Decomposition: Mechanistic Analysis of Neural Network Computation
Introduction
The paper "Causal Interpretation of Neural Network Computations with Contribution Decomposition" (2603.06557) establishes a principled framework for dissecting the causal roles of hidden units in both artificial and biological neural networks. The proposed method, CODEC (Contribution Decomposition), leverages sparse autoencoders to extract sparse computational motifs—termed "contribution modes"—from hidden-layer contributions, surpassing traditional activation-based interpretability methods in identifying units that are necessary and sufficient for specific outputs. CODEC elucidates the transformation of input to output through cascading nonlinearities, offering both causal and human-interpretable decompositions.
Theoretical Framework: From Receptive and Projective Fields to Contribution Analysis
The paper reframes network interpretability using concepts adapted from systems neuroscience: each hidden component’s action is viewed as a composition of its receptive field (input sensitivity) and its projective field (output influence). This compositional perspective is operationalized via contribution analysis, which quantifies each unit’s effect on outputs, distinguishing causal drivers from irrelevant representational activity.
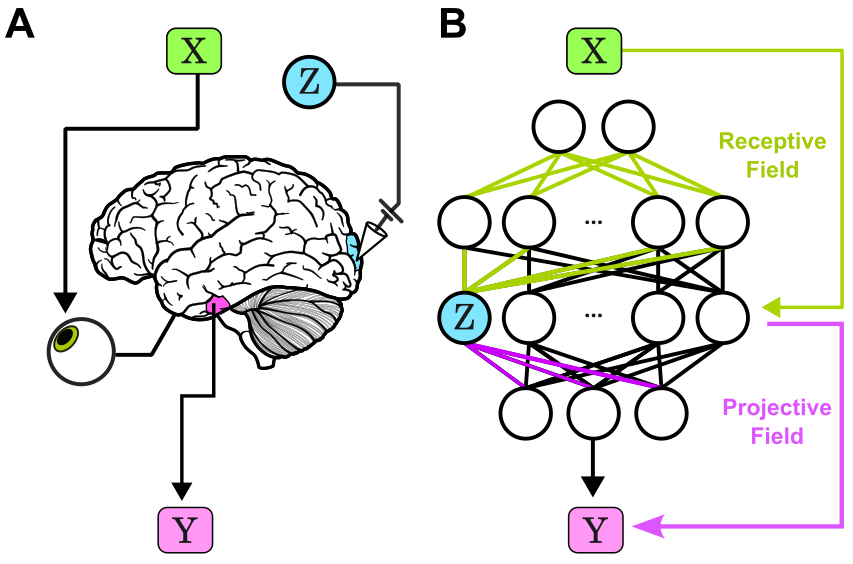
Figure 1: Illustration of receptive-projective field composition in biological and artificial circuits, defining contributions of intermediates to computation.
Most prior interpretability techniques (e.g., saliency mapping, concept activation vector analysis) quantify network representations but do not address the causal integration of features across units. CODEC advances attribution by capturing how groups of hidden neurons act in concert to construct outputs, targeting scalar functions of the output (e.g., top logit, entropy) to enable tractable decomposition.
Quantification of Hidden Contributions: Gradient-Based Mechanisms
Contribution computation utilizes adaptations of Integrated Gradients, ActGrad, and SmoothGrad to attribute output changes to hidden units. The paper standardizes the approach by spatial summation over convolutional feature maps, yielding per-channel causal contributions. Integrated Gradients is favored for its completeness guarantee: contributions sum to the scalar output, allowing rigorous assignment of causal effects.
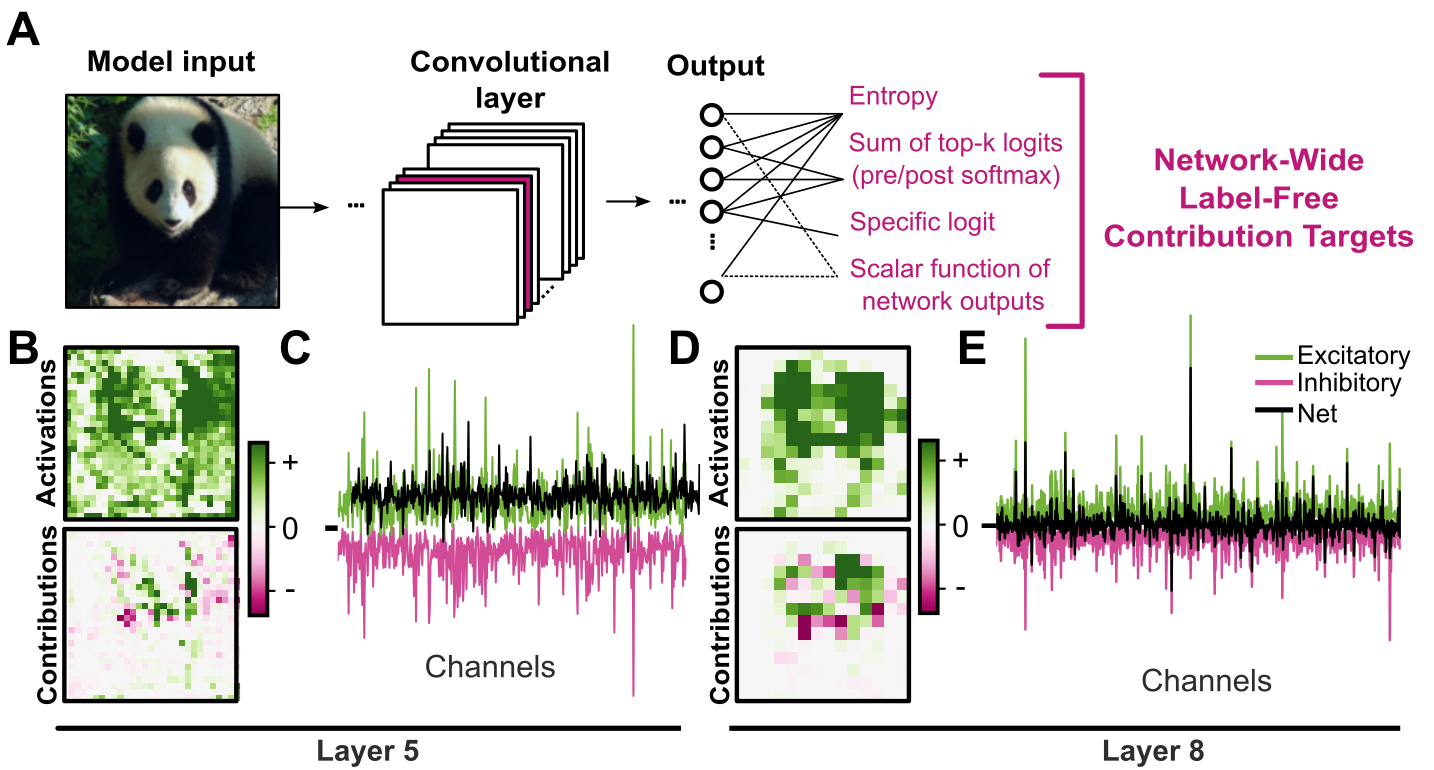
Figure 2: Pipeline for contribution computation in ResNet-50, spatial maps of channel activations vs. contributions, and summary of positive/negative/net channel effects.
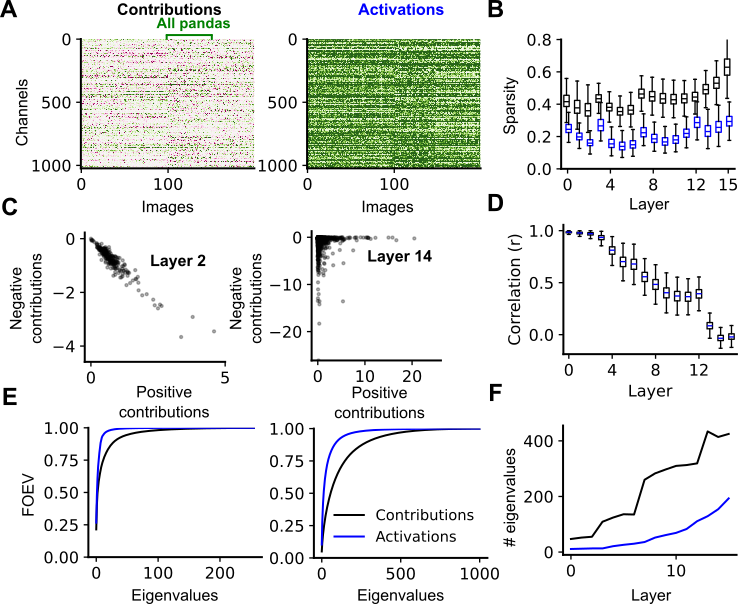
Spatially aggregated channel contributions across datasets generate matrices amenable to further analysis, such as PCA for dimensionality assessment and autoencoder-based population motif discovery.
Structural Evolution of Contributions in Deep Networks
Layerwise analysis reveals several key emergent properties:
CODEC applies sparse autoencoders to matrices of channel contributions, identifying high-fidelity modes that reconstruct network output with R2∼0.85. Each mode corresponds to a motif of coordinated channel activity causally driving specific outputs. Correlation analysis demonstrates that contribution modes are more tightly aligned with class semantics than activation modes, especially at intermediate layers.
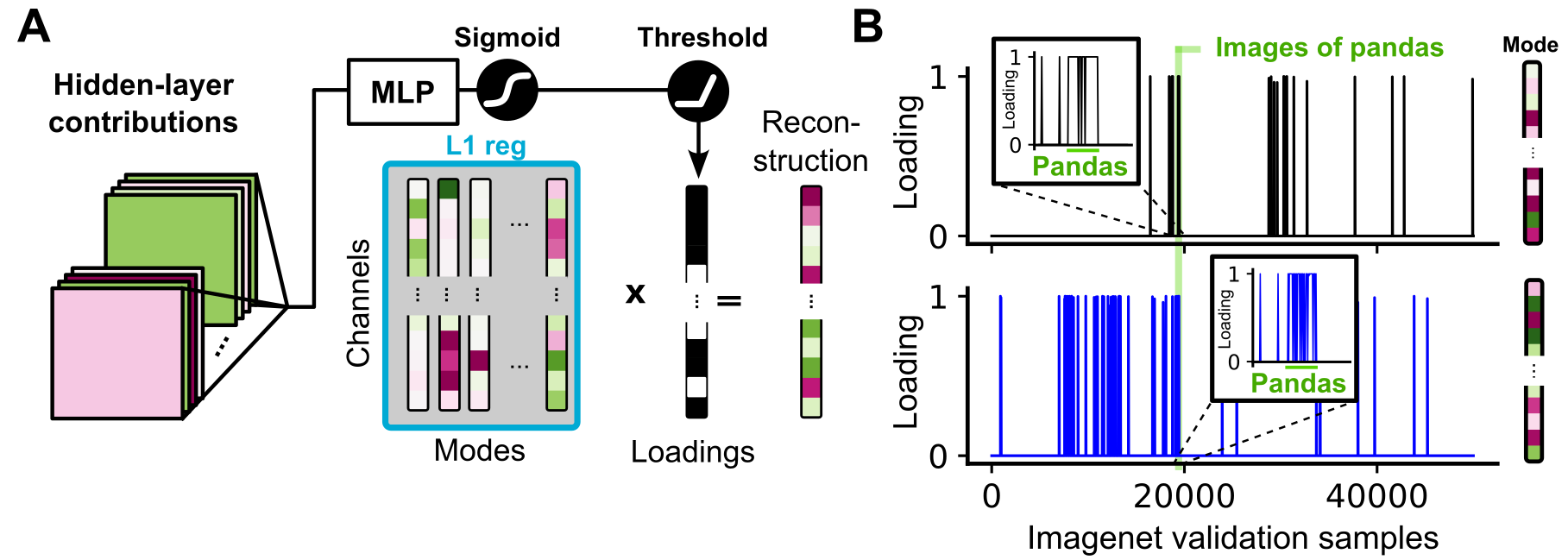
Figure 4: Schematic and example of sparse mode loadings, showing strong class correlation in contribution modes.
Modes are robust to autoencoder hyperparameters and generalize across architectures. The loadings of these motifs are highly correlated with semantic classes in ImageNet, capturing the necessary dimensions for output-specific control.
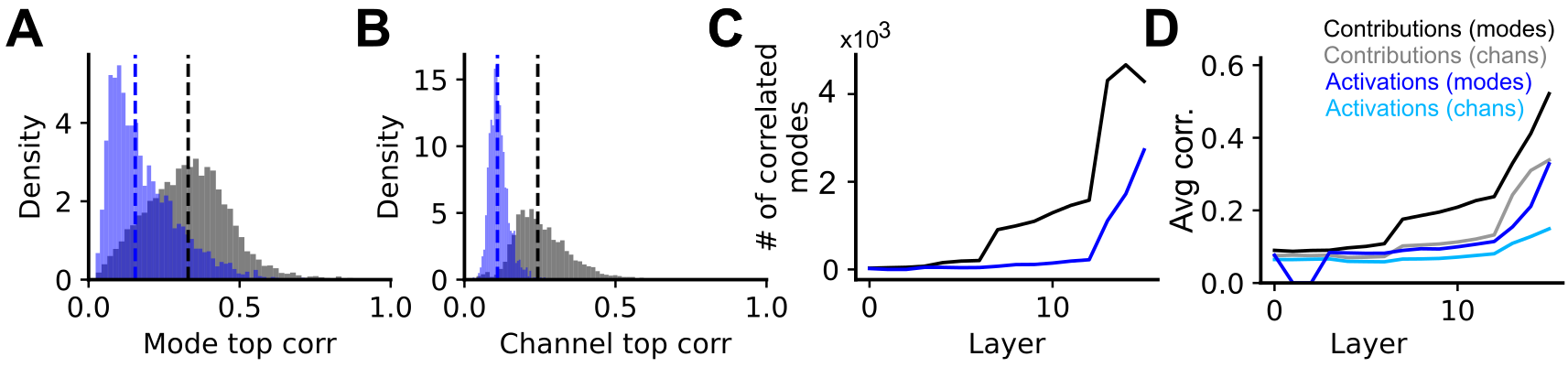
Figure 5: Histograms and statistics quantifying mode/class correlations—contribution modes outperform activation modes and individual channels.
Causal Manipulation and Network Control via Modes
The identification of contribution modes enables direct perturbation experiments. Targeted ablation or preservation of channels corresponding to a specific mode for a class produces precise changes in classification performance. This yields strong specificity: ablation of only 2% of salient channels from the top modes eliminates target-class accuracy without affecting off-target classes, outperforming activation-based strategies.
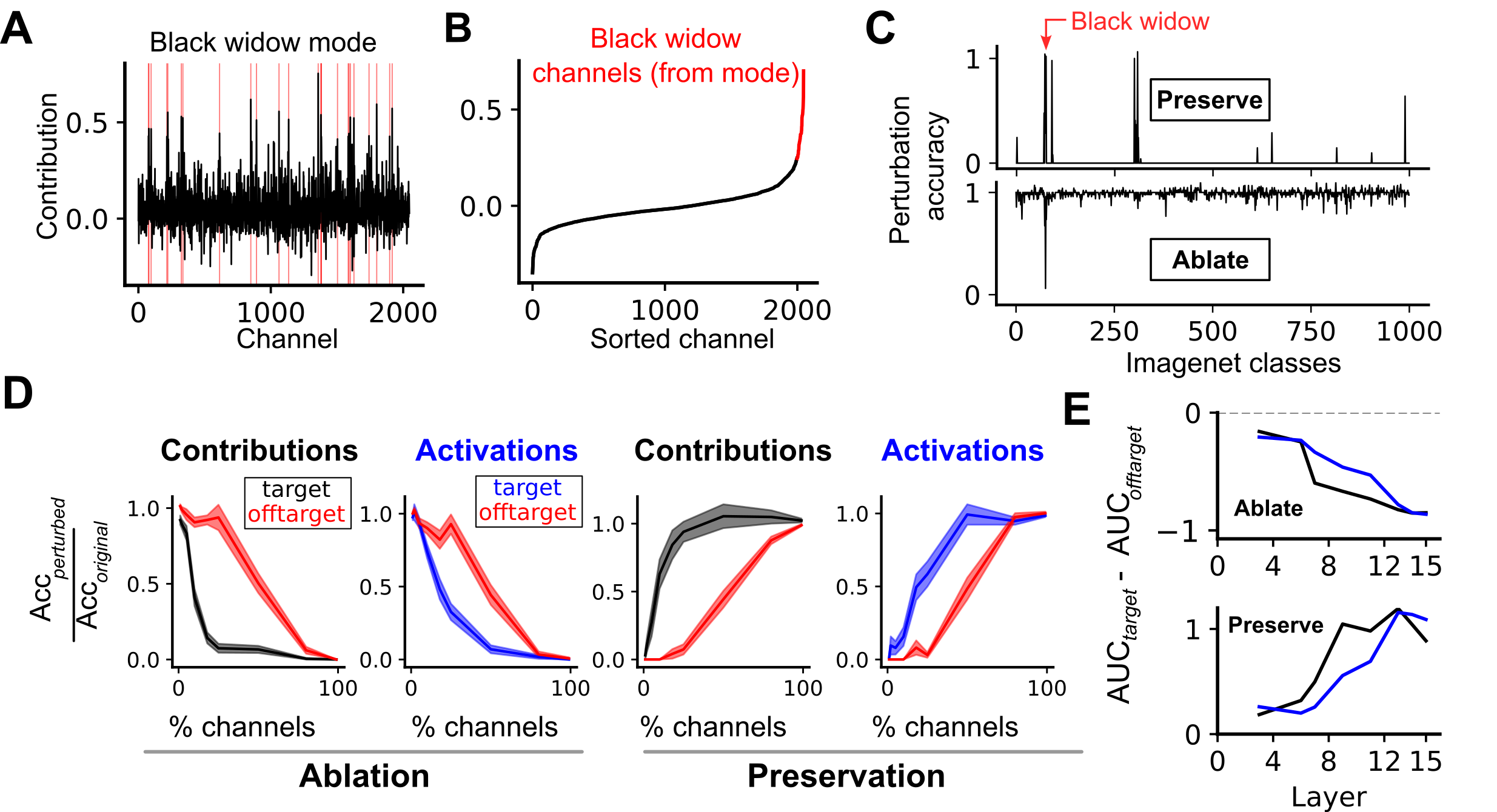
Figure 6: Mode-guided ablation and preservation experiments establish necessity/sufficiency of identified channels for target class output.
Ablation specificity increases with depth, indicating a transition to semantically localized causal mechanisms. The same mode-based protocol manipulates superordinate taxonomies (e.g., "dog" classes), showing general applicability to higher-level representation control.
The method extends traditional saliency analysis by mapping input regions driving mode contributions, decomposing the standard input-output gradient into mode-specific pathways. Contribution maps reveal interpretable visual features (e.g., parts, textures) causally linked to classification output, aspects often missed in activation-based explanations.
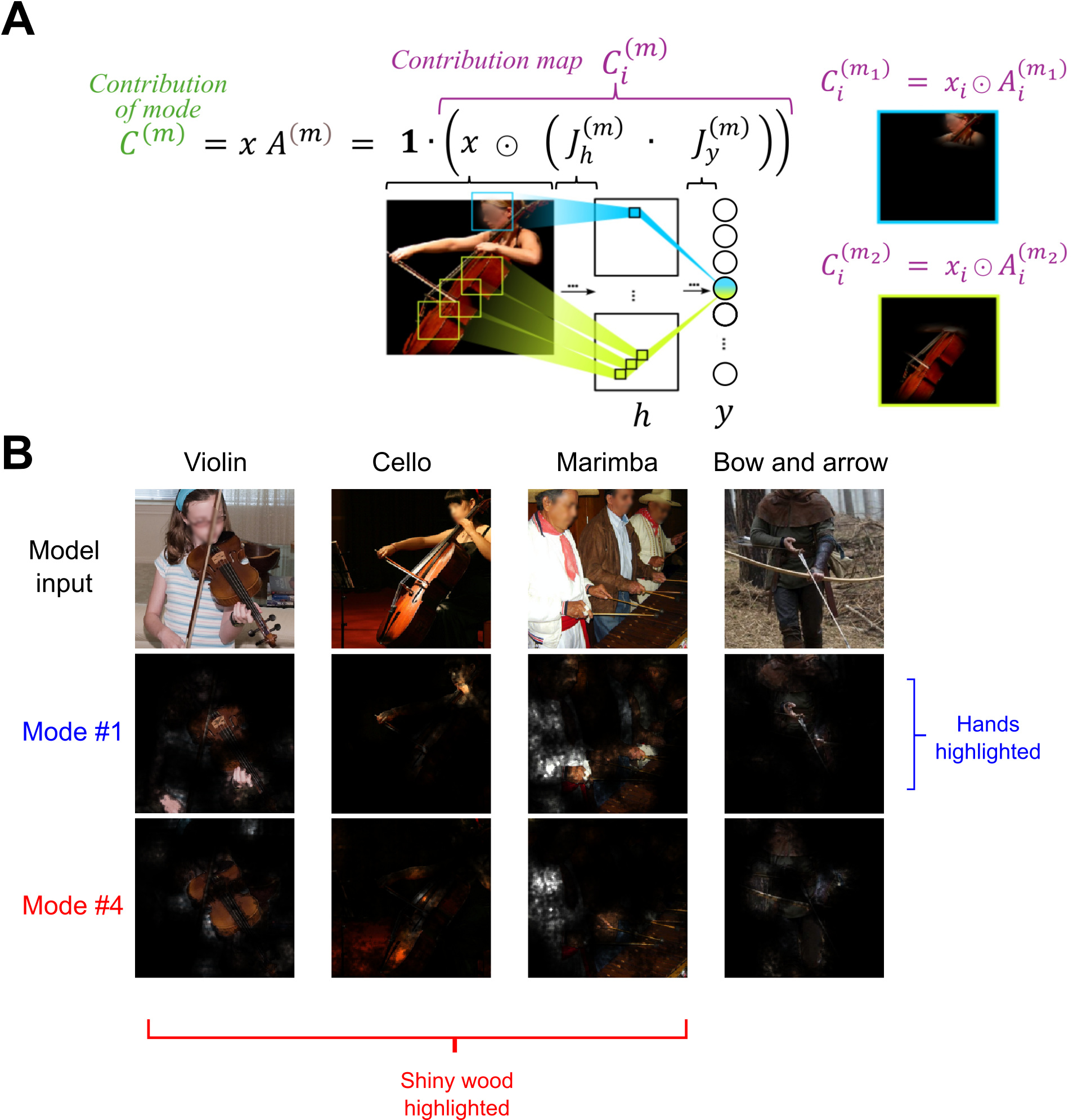
Figure 7: Visualization of input regions contributing through modes across classes, demonstrating compositional, interpretable features (e.g., shiny wood, hands, etc.).
Application to Biological Neural Networks
CODEC is applied to convolutional models fit to retinal ganglion cell (RGC) responses under natural stimuli, using surprisal as a target. Modes correspond to combinatorial activity of interneurons—mirroring biological mechanisms for dynamic receptive field generation. Clustering of RGCs in mode space recovers known functional classes, and analysis of instantaneous receptive fields under mode activation recapitulates experimentally observed diversity (from center-surround to oriented textures).
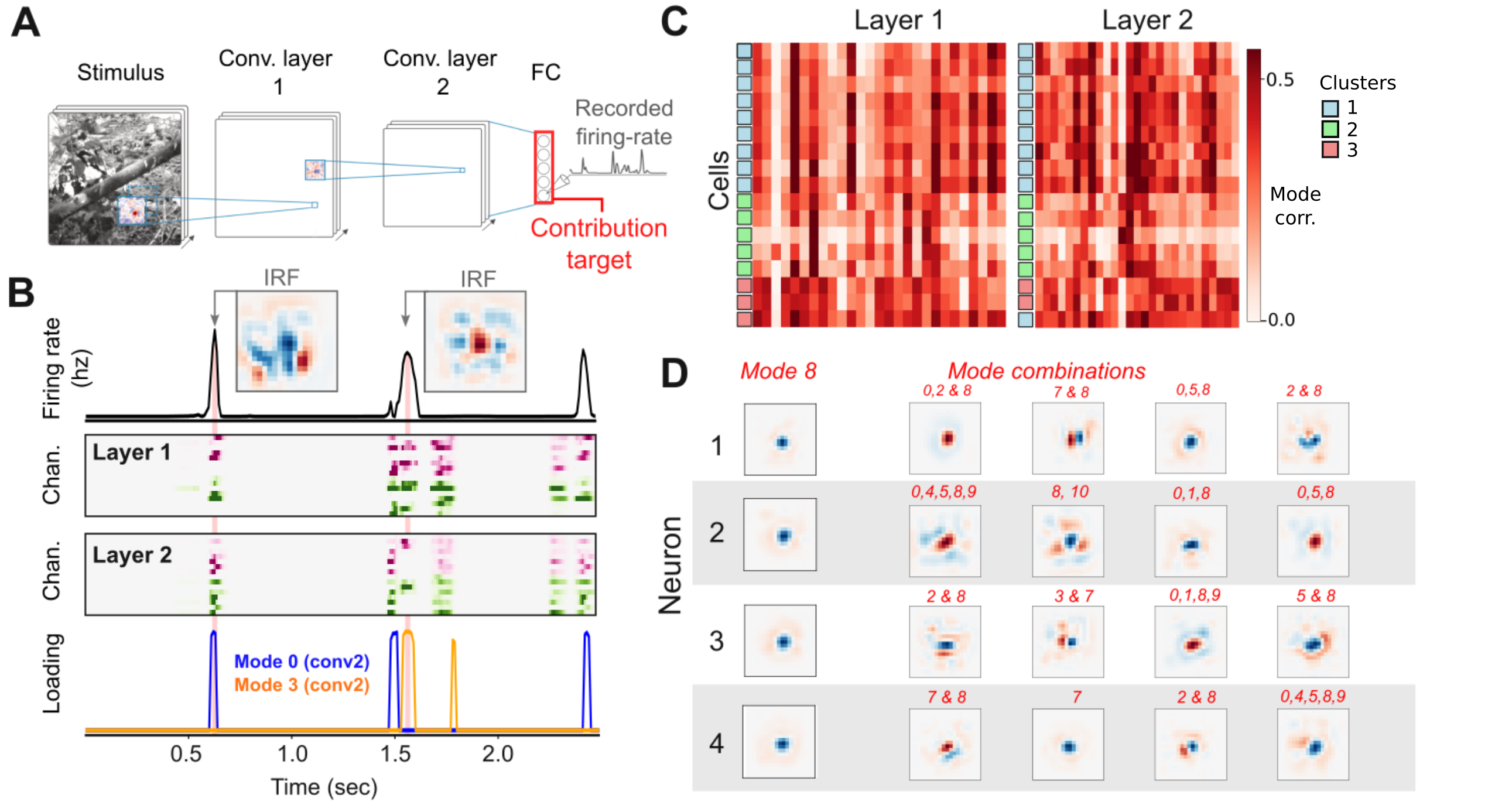
Figure 8: Decomposition of retinal CNN shows that sparse contribution modes generate dynamic receptive fields and drive cell clusters mirroring biological interneuron population functions.
Application to ViT-B demonstrates that contributions, not activations, remain sparse across token features, MLP, and attention layers. Contribution modes again yield greater specificity in output manipulation via ablation, despite computational strategy differences (lack of spatial equivariant bias). Attention head analysis finds minimal specialization, with causal contributions distributed micro-scale across heads.
Implications, Limitations, and Future Directions
CODEC establishes sparse, causally interpretable units—contribution modes—as foundational for network analysis, bridging the gap between human conceptual reasoning and network mechanistic function. The framework supports compositionally explicit manipulation in both artificial and biological systems, providing a pathway to principled explainable AI and neuroscientific hypothesis generation. It directly augments prior concept-based explainability [Kim et al., TCAV] and dictionary learning approaches for monosemantic decomposition [Bricken et al., 2023], but critically emphasizes causal necessity/sufficiency, not just representation.
Practically, the mechanism enables targeted control of model outputs (for safe AI design, robustness, and transfer), and theoretically, suggests that deep networks internally organize computation into sparse, high-dimensional motifs corresponding to output behaviors.
Limitations include restriction to certain architectures (primarily CNNs for full attribution completeness), partial analysis of sequence models and LLMs, and computational cost for contribution analysis in large-scale models. The framework is architecturally agnostic but further research is needed for optimal reduction strategies in transformer architectures. Extending CODEC to LLMs and multitask systems could facilitate modular compositionality in neural computation design.
Conclusion
Contribution Decomposition via CODEC represents a rigorous step toward mechanistic causal interpretability in neural networks. By focusing on contributions rather than activations and extracting sparse modes representing coordinated causal actions, the framework facilitates control, visualization, and biological relevance beyond what is accessible with standard representation-based interpretability. This approach lays the groundwork for principled manipulation and understanding of complex hierarchical neural computations across domains.