Multimodal Large Language Models as Image Classifiers
Abstract: Multimodal LLMs (MLLM) classification performance depends critically on evaluation protocol and ground truth quality. Studies comparing MLLMs with supervised and vision-LLMs report conflicting conclusions, and we show these conflicts stem from protocols that either inflate or underestimate performance. Across the most common evaluation protocols, we identify and fix key issues: model outputs that fall outside the provided class list and are discarded, inflated results from weak multiple-choice distractors, and an open-world setting that underperforms only due to poor output mapping. We additionally quantify the impact of commonly overlooked design choices - batch size, image ordering, and text encoder selection - showing they substantially affect accuracy. Evaluating on ReGT, our multilabel reannotation of 625 ImageNet-1k classes, reveals that MLLMs benefit most from corrected labels (up to +10.8%), substantially narrowing the perceived gap with supervised models. Much of the reported MLLMs underperformance on classification is thus an artifact of noisy ground truth and flawed evaluation protocol rather than genuine model deficiency. Models less reliant on supervised training signals prove most sensitive to annotation quality. Finally, we show that MLLMs can assist human annotators: in a controlled case study, annotators confirmed or integrated MLLMs predictions in approximately 50% of difficult cases, demonstrating their potential for large-scale dataset curation.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how well multimodal LLMs (MLLMs)—AI systems that can understand both pictures and text—can recognize what’s in images. The authors discover that the way we test these models, and how correct the “answer key” is, makes a huge difference. They also fix several testing problems and show that many past comparisons were unfair, which made MLLMs look worse than they really are.
What questions did the researchers ask?
In simple terms, they wanted to know:
- Are we testing image-recognition AIs in a fair and accurate way?
- How much do testing choices (like question style) change the results?
- Do mistakes in the “ground truth” (the official correct labels) make models look bad when they’re actually right?
- Can MLLMs help humans clean up and improve big image datasets?
How did they study it?
The team tested five well-known MLLMs (including GPT-4o and top open-source models) and compared them to traditional vision models. They ran the same image classification task in three different test styles, then improved the label quality and re-ran the tests.
Three ways to test image recognition
Think of testing like a quiz about what’s in a picture:
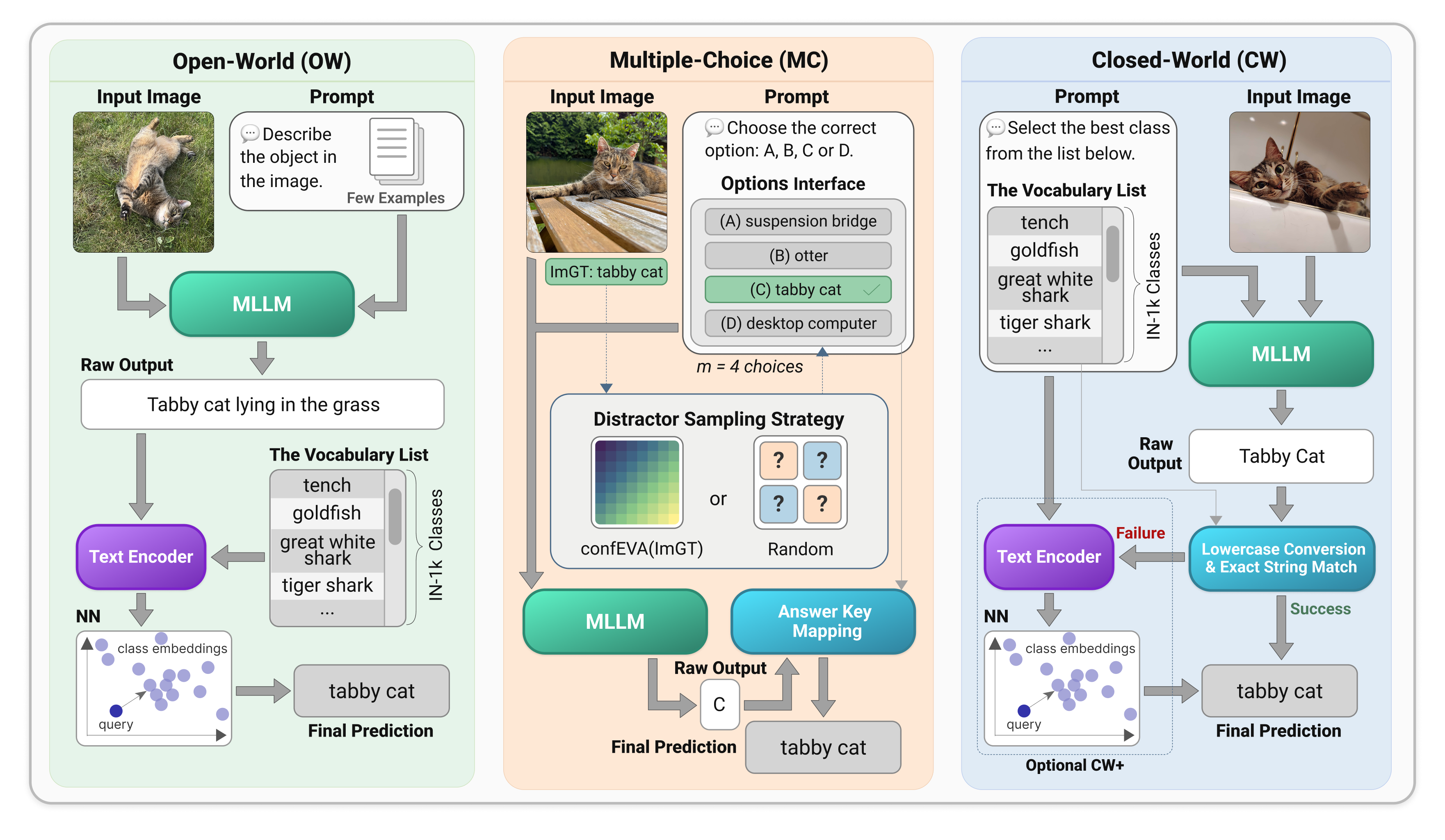
- Open-World (OW): The model gives any answer it wants (like a short description). Then, the system matches that answer to the closest official label by comparing the meaning of words. You can think of this like matching “notebook” to “laptop” because they mean almost the same thing.
- Multiple-Choice (MC): The model chooses from four options (one correct, three “distractors”). This is the classic school-style quiz.
- Closed-World (CW): The model must pick from the full list of 1,000 class names. That’s like giving it the entire answer list and saying “choose exactly one from here.” A common problem is that models sometimes ignore the list and write something else. The authors fix this with CW+, which automatically maps any “off-list” answer to the closest allowed class (using the same meaning-matching trick as in OW).
Fixing the answer key (better labels)
They noticed ImageNet, a famous picture dataset, often has:
- Wrong labels (about 1 in 5 in some studies),
- Images with multiple objects but only one label,
- Overlapping or confusing class names.
So the authors re-labeled a large part of ImageNet (625 out of 1,000 classes; 31,250 images total) to create a cleaner, more realistic “answer key” called ReGT. This allows fairer testing—especially on pictures that contain more than one object.
Other testing choices they examined
They also measured how much results change based on things people usually overlook, like:
- How many images are processed at once (batch size),
- The order of images,
- Which text encoder they use to compare meanings (important for OW and CW+),
- How distractor choices are picked in multiple choice.
These seemingly small choices can change accuracy a lot.
What did they find?
Here are the key findings, explained simply:
- The test format matters—a lot:
- Multiple-Choice (MC) can make models look better than they really are, especially if the wrong options (distractors) are easy or random. When the authors used harder, more realistic distractors, accuracy dropped by about 10–15%.
- Open-World (OW) can be very strong if you use a good meaning-matching step to map free-form answers to the official class names. For about half the models they tested, OW performed as well as or better than CW.
- Closed-World+ (CW+) fixes a big problem: when models answer with something not on the list (“off-list” or “hallucinated”), CW+ smartly maps that answer to the closest allowed class. This boosts accuracy and makes CW fairer.
- Better labels make MLLMs look much better:
- With the improved labels (ReGT), MLLMs gained up to +10.8% accuracy. That’s a big jump.
- The gap between MLLMs and top traditional models (trained specifically for image tasks) shrinks a lot when labels are cleaned up. In many “disputed” images where the original label was questionable, MLLMs and vision-LLMs actually did better than standard supervised models.
- Design choices change scores:
- Things like batch size, image order, output format, and which text encoder you use can noticeably change results. This means some past studies may have unintentionally given inflated or deflated scores.
- MLLMs can help humans fix datasets:
- In a focused study of tough cases, human annotators agreed with or used the MLLM’s suggestion about half the time. This shows MLLMs can be powerful assistants for cleaning and improving large image datasets.
Why does this matter?
- Fairer evaluations: The study shows that many “MLLMs are bad at classification” claims came from flawed tests or noisy labels—not necessarily weak models. With better testing and cleaner labels, MLLMs perform much closer to traditional top models.
- Better real-world reliability: If you’re using AI to recognize things in important settings (like nature safety, medicine, or everyday tools), you want tests that reflect reality. This paper shows how to set up those tests so they’re fair and trustworthy.
- Smarter data curation: Since MLLMs can help spot bad or missing labels, they can speed up the creation of better training data, which helps all future models.
- Practical takeaway: If you build or evaluate AI image classifiers, don’t just pick an easy multiple-choice setup with random distractors. Use careful mapping for free-form answers, consider CW+, and make sure your “answer key” is correct. Small choices can change the score—and the conclusions—by a lot.
In short, the paper argues that MLLMs are stronger image classifiers than many people think, as long as we test them the right way and use accurate labels.
Knowledge Gaps
Below is a concise, actionable list of the knowledge gaps, limitations, and open questions that remain unresolved by the paper.
- Limited scope of reannotation (ReGT): only 625/1000 ImageNet-1k classes were relabeled, deliberately excluding many fine-grained categories; it is unclear whether conclusions hold for the remaining 375 classes or for other fine-grained domains.
- ReGT availability and reproducibility: ReGT is “not yet public,” preventing independent verification, replication, and benchmarking; timelines and release protocols (including class-equivalence sets E, prompts, and code) are unspecified.
- Potential annotation bias: annotators were shown top-20 model predictions during labeling; the magnitude and direction of this bias (confirmation effects, class prevalence shifts) were not quantified via a blinded control or A/B design.
- Annotation reliability not reported: inter-annotator agreement (e.g., Cohen’s kappa, Krippendorff’s alpha), adjudication protocols, and second-pass QC procedures beyond the case study are not provided.
- Evaluation choice for “N” images: treating all predictions as correct when an image has no valid ImageNet label (N category) can inflate accuracy; alternative metrics (e.g., “none-of-the-above” detection, abstention-aware scoring) are not explored.
- Completeness of semantic equivalence sets (E): the coverage, construction criteria, and validation of E (class synonyms/aliases) are not detailed; their impact on accuracy and model rankings is unquantified.
- Closed-World mapping design (CW+): reliance on nearest-neighbor mapping in a chosen text-embedding space is under-specified; sensitivity to encoder choice, normalization, and distance metrics needs systematic analysis and standardization.
- Alternatives to CW+ mapping: constrained decoding (e.g., grammars, function-calling), logit-biasing, or vocabulary-constrained decoding were not compared to embedding-based mapping for reducing out-of-prompt (OOP) outputs.
- Encoder selection fairness: “best model-specific encoder” is used for mapping but selection criteria and potential cherry-picking risks are unclear; cross-encoder comparisons and a fixed, model-agnostic encoder baseline are needed.
- Prompt sensitivity and decoding parameters: the influence of system prompts, few-shot examples, temperature/top_p, and response format constraints on CW/OW performance and OOP rates is not systematically quantified.
- Batch/ordering effects: while noted to be significant, the mechanisms and generalizability of batch size, image order, and class-homogeneous vs. mixed batches across APIs and models remain underexplored and lack standardized controls.
- Multiple-choice (MC) protocol standardization: only 4-way MC is studied, with distractors from random or EVA-02 confusion; scaling to larger N, model-agnostic/human-curated/adversarial distractors, and super-class or synonym-aware hard negatives is left open.
- Distractor-source dependence: using EVA-02’s confusion matrix may bias hardness towards vision-only supervised errors; it is unknown whether MLLM-specific confusion-derived distractors would change conclusions.
- OW vs. CW behavior: OW outperforms CW for some models with embedding mapping, but the underlying reasons (e.g., generative priors vs. selection bias) and when to prefer OW vs. CW remain unclear.
- Multi-label evaluation: the study largely enforces single-label outputs for datasets with substantial multilabel images; explicit multi-label prediction objectives, metrics (mAP, F1), and instruction strategies are not investigated.
- Abstention and “unknown” handling: there is no evaluation of calibrated abstention or “none-of-the-above” options, despite frequent out-of-taxonomy content; methods to elicit calibrated uncertainty from MLLMs are absent.
- Cross-dataset generalization: results are restricted to ImageNet-1k (plus a niche biological subset in Supplementary); performance under distribution shift (ImageNet-V2, -R, -A, -Sketch, ObjectNet) is not reported.
- Fine-grained taxonomy coverage: many fine-grained animal categories were excluded from ReGT; how MLLMs fare on expert-verified fine-grained datasets and whether CW+/OW mapping scales to dense taxonomies is unaddressed.
- Class name quality and variants: dependence on a single hand-crafted class-name list (with known imperfections) is acknowledged, but the effect of alternative labels, paraphrases, hierarchical names, or learned templates is not quantified.
- OOP diagnostics and mitigation: beyond rate reporting, the causes of OOP (prompt ambiguity, token limits, training distribution) and robust mitigations (structured outputs, grammar constraints, self-checking) need deeper evaluation.
- Output calibration and confidence: no assessment of probability calibration, score-based ranking, or selective classification; top-k accuracy and confidence-accuracy alignment are not analyzed.
- Case-study limitations: the second-pass annotation examined only GPT-4o disagreements, focuses on single-label cases, and lacks sample-size details and inter-annotator agreement; generality to other MLLMs is unknown.
- Token-length constraints and scaling: some models cannot accommodate 1,000-class CW prompts; chunked prompting, retrieval-augmented class selection, or hierarchical narrowing strategies were not evaluated.
- Cost, latency, and practicality: throughput, API variability, rate-limiting, and monetary cost of large-scale MLLM classification (and sensitivity of results to these factors) are not reported.
- Risk of data leakage: while ReGT is claimed unseen, no explicit contamination checks (e.g., web-scale pretraining overlaps, near-duplicate detection) are presented for models trained on internet-scale corpora.
- Error taxonomy and per-class analysis: the paper highlights that ImGT vs. ReGT correct sets differ but does not provide a detailed error taxonomy (e.g., hypernym/hyponym confusions, context-induced errors) to guide targeted improvements.
- Multilinguality: all evaluations use English labels; MLLM/VLM performance with multilingual class names and cross-lingual mapping in CW+/OW remains unexplored.
- Beyond ImageNet label-space constraints: the paper notes issues when the dominant object is out-of-vocabulary; structured open-world protocols (e.g., hierarchical or expandable taxonomies) are not developed or benchmarked.
Practical Applications
Below is an overview of practical applications that follow from the paper’s findings, methods, and innovations. Items are grouped into immediate (deployable now) and longer-term (requiring further R&D, scaling, or standardization). Each item notes likely sectors, candidate tools/workflows, and key assumptions/dependencies.
Immediate Applications
- Bold: CW+ semantic mapping adapter for MLLMs
- What: Wrap any MLLM’s free-form output and map it to a fixed class list via nearest-neighbor search in a robust text-embedding space (model-specific encoder), reducing out-of-prompt (OOP) errors when using MLLMs as classifiers.
- Sectors: software, robotics, retail/e-commerce (catalog tagging), media/content moderation, manufacturing QA.
- Tools/workflows: lightweight library/API that takes (image, class list) → MLLM text → text-embedding → nearest label; synonym/equivalence tables; fallback “unknown” option; batch evaluation mode.
- Assumptions/dependencies: access to a strong text encoder (ideally model-specific); curated class lists and synonym groups; reliable prompting; compute budget for embedding.
- Bold: Open-World (OW) to taxonomy bridge for user-facing apps
- What: Use the OW setup plus embedding-based mapping to translate free-form descriptions to internal taxonomies/codes.
- Sectors: photo apps/DAM, e-commerce tagging, newsroom/media archiving.
- Tools/workflows: OW prompting templates; embedding-based mapper; thresholds for multi-label assignment and “no match.”
- Assumptions/dependencies: taxonomy coverage and maintenance; tuned thresholds; handling ambiguous/long-tail items.
- Bold: Evaluation harness that avoids inflated MC scores
- What: Replace MC tests with weak distractors by either CW+ or OW+mapping; if MC is unavoidable, generate hard distractors (confusion-matrix or semantically close distractors) and report confidence intervals.
- Sectors: enterprise AI procurement, benchmark providers, academic labs.
- Tools/workflows: MC-hard distractor generator; CW+/OW scripts; CI-ready evaluation configs; reporting templates with CIs.
- Assumptions/dependencies: access to a strong supervised model (e.g., EVA-02) to derive confusion-based distractors; standardized prompt templates.
- Bold: Reproducible evaluation checklists and configs
- What: Standardize batch size, image ordering, prompt design, and text-encoder choice—all shown to significantly affect accuracy.
- Sectors: academia, ML platform teams, model governance/compliance.
- Tools/workflows: versioned evaluation configs; MLOps pipelines with fixed seeds; automated variance reporting across runs.
- Assumptions/dependencies: organizational buy-in to standardize; stable model APIs.
- Bold: MLLM-in-the-loop dataset curation
- What: Deploy MLLMs to flag potential label errors, suggest added/missing labels, and assist annotators—shown to meaningfully improve labels in ~50% of difficult cases.
- Sectors: dataset providers, e-commerce, medical imaging research, biodiversity projects, AV/perception teams.
- Tools/workflows: integration with CVAT/Label Studio; reviewer UIs showing top-20 predictions; multilabel support; disagreement triage queues.
- Assumptions/dependencies: human oversight (“verify not replace”); privacy/compliance for images; domain-expert availability for fine-grained classes.
- Bold: Multilabel-aware metrics and synonym handling
- What: Adopt a ReaL-style metric that accepts any correct label in a multilabel set and incorporates synonym/equivalence groups to avoid penalizing naming variants.
- Sectors: benchmark design, search/retrieval systems, QA for content platforms.
- Tools/workflows: metrics library that supports S/M/N subsets (single/multi/no-label), synonyms E, and intersection-of-correctness analysis.
- Assumptions/dependencies: curated synonym/equivalence lists; taxonomy updates over time.
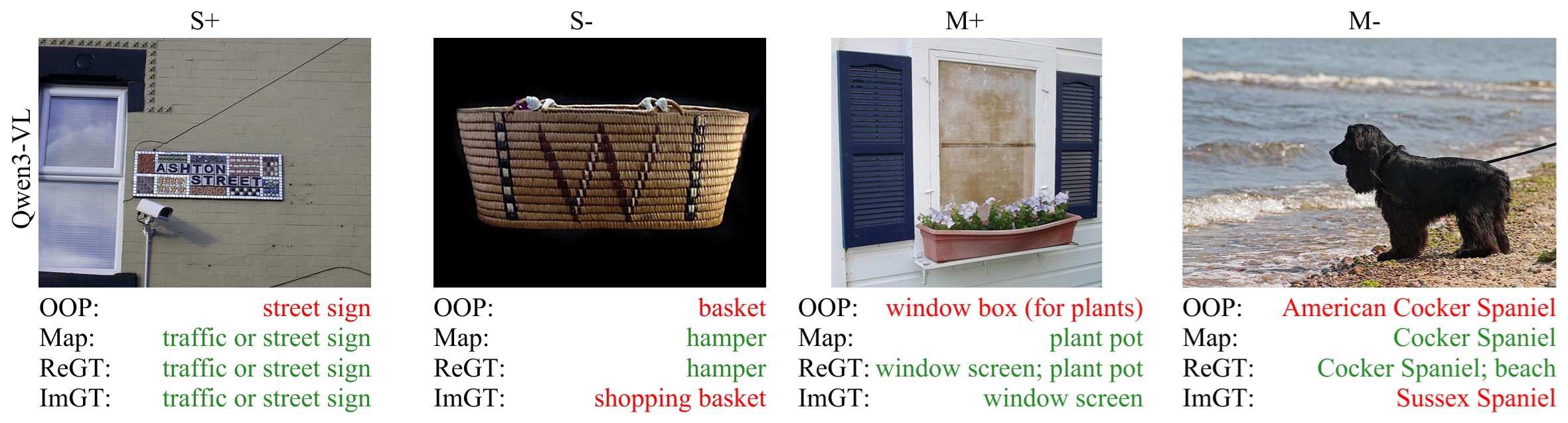
- Bold: Performance slicing dashboards using label categories
- What: Partition evaluation into S+, S−, M+, M−, N categories to diagnose failure modes (e.g., OOP spikes on multilabel or out-of-scope images).
- Sectors: MLOps, model risk teams, enterprise QA.
- Tools/workflows: dashboards that ingest predictions and labels, compute category-wise metrics, and visualize OOP rates and mapping corrections.
- Assumptions/dependencies: availability of multilabel ground truth and “no-label” flags; logging and governance.
- Bold: Safer deployment guidance for sensitive use-cases
- What: Apply conservative evaluation (CW+/OW), hard MC when required, and human verification gates before using MLLMs for safety-critical tasks (e.g., medical triage, dangerous species ID).
- Sectors: healthcare, conservation/ecology, industrial inspection.
- Tools/workflows: risk checklists; uncertainty thresholds; mandated human-in-the-loop for edge cases; audit trails.
- Assumptions/dependencies: risk appetite; regulatory constraints; qualified reviewers.
- Bold: Rapid relabeling playbook for in-house datasets
- What: Replicate the paper’s reannotation principles—multilabel, ambiguity-aware, and “no valid label” tagging—on internal datasets to reduce label noise and shift reported performance closer to reality.
- Sectors: enterprises with proprietary vision datasets (retail, manufacturing, logistics).
- Tools/workflows: annotation guidelines; class-equivalence catalog; sampling policies; dual-pass verification for disputed items.
- Assumptions/dependencies: annotation budget; acceptance of model-assisted labeling bias trade-offs; domain experts for fine-grained categories.
Long-Term Applications
- Bold: Public, multilabel reannotations for major benchmarks
- What: Scale ReGT-style efforts across datasets and domains to standardize multilabel, ambiguity-aware evaluation and reduce label noise.
- Sectors: academia, standards bodies, benchmark consortia.
- Tools/workflows: community curation pipelines; consensus-building on synonym sets; dataset versioning standards.
- Assumptions/dependencies: funding and coordination; licensing; broad community adoption.
- Bold: OOP-aware decoding and alignment for classification
- What: Train/fine-tune MLLMs to minimize OOP (e.g., constrained decoding against class lists, better instruction tuning) while retaining general utility.
- Sectors: model developers, embedded/edge AI, robotics.
- Tools/workflows: constrained decoders; alignment objectives penalizing OOP; evaluation suites validating both generalization and compliance.
- Assumptions/dependencies: access to model weights or adapter methods; token-length constraints; careful trade-offs between flexibility and faithfulness.
- Bold: Dynamic open-world classification with novelty detection
- What: Production systems that map free-form outputs to known classes, detect “unknowns,” and update taxonomies incrementally with human approval.
- Sectors: retail (new SKUs), media libraries, defense/security monitoring, scientific curation.
- Tools/workflows: thresholded embedding similarity; retrieval-augmented labeling; taxonomy lifecycle management; continuous evaluation.
- Assumptions/dependencies: robust calibration; human review queue; governance for adding classes.
- Bold: Automated dataset quality auditors
- What: MLLM-powered tools that scan datasets to surface likely mislabels, duplicates, overlap, or OOD images; produce relabel suggestions and confidence levels.
- Sectors: MLOps vendors, large data-owning enterprises.
- Tools/workflows: auditor dashboards; integration with data version control; active-learning hooks to prioritize human review.
- Assumptions/dependencies: scalable inference; access to data (privacy); acceptance of suggested-change workflows.
- Bold: Sector-specific synonym and taxonomy services
- What: Domain-tailored equivalence/thesaurus services (e.g., medical ontologies, retail catalogs, wildlife taxonomies) feeding evaluation and mapping pipelines.
- Sectors: healthcare, e-commerce, ecology, geospatial.
- Tools/workflows: APIs for equivalence sets and hierarchies; periodic updates with expert input; governance for changes.
- Assumptions/dependencies: expert curation; alignment with existing standards (e.g., SNOMED, GBIF).
- Bold: Benchmarking policy and certification standards
- What: Procurement and regulatory frameworks that discourage inflated MC protocols and require CW+/OW evaluations, hard distractors, and multilabel-aware metrics.
- Sectors: regulators, public sector procurement, large enterprises.
- Tools/workflows: certification checklists; compliance audits; disclosure of evaluation configs and seeds.
- Assumptions/dependencies: cross-institution consensus; incentives for vendors to comply.
- Bold: Training curricula and practitioner guides
- What: Incorporate findings on protocol sensitivity, label noise, and mapping methods into university courses and enterprise training for responsible deployment.
- Sectors: education, corporate L&D, professional organizations.
- Tools/workflows: modular teaching materials; lab assignments with CW+/OW and MC-hard; case studies of label noise impacts.
- Assumptions/dependencies: open-source teaching resources; dataset access.
- Bold: Video and streaming pipelines with multilabel semantics
- What: Extend CW+/OW mapping and multilabel metrics to streaming/video classification for surveillance, manufacturing lines, and sports/media tagging.
- Sectors: security, industrial automation, media analytics.
- Tools/workflows: batched temporal inference; segment-level mapping; per-frame uncertainty aggregation.
- Assumptions/dependencies: real-time constraints; temporal label definitions; edge deployment capabilities.
Notes on feasibility and transferability:
- The strongest immediate gains come from CW+/OW mapping, better distractor design, and multilabel-aware evaluation—these require no model retraining.
- Benefits depend on the availability and quality of text encoders and class/synonym catalogs; using model-specific encoders typically performs best.
- Label improvements materially change conclusions about model capability; investing in better labels can rival gains from model upgrades for MLLMs.
- For safety-critical domains, evaluation rigor and human oversight are non-negotiable; MC with random distractors should not be used to justify deployment.
Glossary
- Annotation noise: Incorrect or inconsistent labels in a dataset that can mislead training or evaluation. "greatly reducing annotation noise, ambiguities and other imperfections mentioned."
- Batch size: The number of samples processed together in one forward/backward pass, which can affect model behavior and reported accuracy. "batch size, image ordering, and text encoder selection"
- Closed-World (CW): A classification setting where the model must choose from an exhaustive, predefined list of classes. "The Closed-World (CW) task is designed to mimic classification with supervised models and \acp{vlm}."
- Confidence intervals (CI): Statistical ranges that quantify uncertainty around an estimate, such as accuracy. "with 95\,\% confidence intervals (CI)."
- Confusion matrix: A matrix summarizing how often each true class is predicted as each other class, used here to sample hard distractors. "based on the confusion matrix of the supervised EVA-02 model, denoted as confEVA()"
- Constrained decoding: Forcing a generative model to produce outputs that conform to a specified set of tokens or structures. "without costly constrained decoding"
- Distractors: Incorrect answer options included alongside the correct one in multiple-choice evaluation to test model discrimination. "Distractors are sampled per-image, ranging from random to more challenging alternatives semantically close to the ground-truth label."
- Distribution shift: A change between training and test data distributions that can degrade model performance. "distribution shifts between training and validation sets"
- Embedding-based post-processing: Mapping free-form model outputs to target classes via vector embeddings and nearest neighbors. "a lightweight embedding-based post-processing that resolves out-of-prompt predictions"
- Equivalence set: A predefined grouping of semantically interchangeable labels treated as the same during evaluation. "We treat each pair in a predefined equivalence set as interchangeable"
- Free-form outputs: Unconstrained natural language responses produced by a model, not limited to a fixed class list. "\acp{mllm} produce free-form outputs"
- Ground truth (GT): The reference labels used to evaluate predictions. "classification performance depends critically on evaluation protocol and ground truth quality."
- Hallucinations: Model outputs that are plausible but not allowed or not supported by the prompt/data, such as generating labels outside the provided list. "often referred to as hallucinations"
- ImGT: The original ImageNet-1k ground-truth label for an image. "ImGT: original single ImageNet label"
- Instruction following: The capability of models to adhere to user prompts and directions during multimodal tasks. "primarily assessing high-level multimodal reasoning and instruction following through multiple-choice question answering."
- Instruction tuning: Post-training on instruction–response pairs to improve following directions and task performance. "Progressive multimodal scaling + instruction tuning"
- k-NN classifier: A nonparametric method that classifies based on the labels of the k nearest neighbors in feature space. "as a -NN classifier using ImageNet-1k training set (ViT-7B, )"
- Label noise: Systematic or random inaccuracies in labels that can bias learning and evaluation. "Label Noise Sensitivity Across Learning Paradigms."
- Mixture-of-Experts (MoE): A neural architecture that routes inputs to specialized expert sub-networks for efficiency and capacity. "Qwen3 MoE"
- Multiple-Choice (MC): An evaluation setup where the model selects one answer from a small set of candidates including distractors. "Multiple-choice (MC) question answering is commonly used to benchmark \acp{mllm}"
- Multimodal LLM (MLLM): A LLM augmented with visual (and possibly other) modalities to process and reason over multiple input types. "\acp{mllm} performance has been extensively benchmarked"
- Nearest-neighbor search: Assigning labels by finding the closest vector (e.g., text embedding) in a predefined set. "or nearest-neighbor search in a text-embedding space"
- Open-World (OW): A setting where the model generates a free-form description that is later mapped to the closest class. "Open-World (OW) is closest to everyday \ac{mllm} use"
- Out-of-distribution (OOD): Data that do not come from the same distribution as the training or assumed evaluation set. "our non-OOD reannotated labels do not contain the ground-truth label"
- Out-of-prompt (OOP) predictions: Outputs that do not belong to the set of allowed classes specified in the prompt. "out-of-prompt (OOP) predictions become more frequent"
- ReaL accuracy: A multilabel-aware ImageNet metric where a prediction is correct if it matches any valid label for an image. "we adapt the top-1 ReaL accuracy"
- ReGT: The paper’s reannotated ground-truth labels for a subset of ImageNet-1k, used to reduce noise and ambiguity. "ReGT: our reannotations."
- Reinforcement learning from human feedback (RLHF): Post-training technique aligning model behavior using preferences or feedback from humans. "post-training alignment (RLHF)"
- Self-supervised: Training without human-provided labels, using pretext objectives to learn representations. "self-supervised \acp{vlm} and \acp{mllm} outperform them on images where ReGT disagrees with ImGT."
- Text encoder: A model that converts text into vector embeddings for comparison or mapping. "text encoder selection"
- Vision-LLM (VLM): A model trained jointly on images and text to align visual and textual representations. "both supervised and \acp{vlm}"
- Vision Transformer (ViT): A transformer-based architecture applied to image patches for vision tasks. "SigLIP-so400M denotes the shape-optimized Vision Transformer."
- Zero-shot: Performing a task without task-specific training on the target labels, typically via prompt-based or embedding methods. "this approach would no longer be zero-shot"
Collections
Sign up for free to add this paper to one or more collections.