The Coupling Within: Flow Matching via Distilled Normalizing Flows
Abstract: Flow models have rapidly become the go-to method for training and deploying large-scale generators, owing their success to inference-time flexibility via adjustable integration steps. A crucial ingredient in flow training is the choice of coupling measure for sampling noise/data pairs that define the flow matching (FM) regression loss. While FM training defaults usually to independent coupling, recent works show that adaptive couplings informed by noise/data distributions (e.g., via optimal transport, OT) improve both model training and inference. We radicalize this insight by shifting the paradigm: rather than computing adaptive couplings directly, we use distilled couplings from a different, pretrained model capable of placing noise and data spaces in bijection -- a property intrinsic to normalizing flows (NF) through their maximum likelihood and invertibility requirements. Leveraging recent advances in NF image generation via auto-regressive (AR) blocks, we propose Normalized Flow Matching (NFM), a new method that distills the quasi-deterministic coupling of pretrained NF models to train student flow models. These students achieve the best of both worlds: significantly outperforming flow models trained with independent or even OT couplings, while also improving on the teacher AR-NF model.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper shows a new way to train image generators so they make high‑quality pictures faster. It combines two popular ideas:
- Flow Matching (FM): a way to teach a model to gradually transform random noise into an image.
- Normalizing Flows (NF): a reversible model that can turn an image into “noise” and back again.
Their method, called Normalized Flow Matching (NFM), uses an NF “teacher” to guide an FM “student.” The result: the student learns better, makes images that look more like real ones, and does so much faster than the teacher.
Key questions the paper asks
- Can we train flow‑based generators better by giving them smarter pairings between noise and images?
- Instead of computing those pairings from scratch (like with optimal transport), can we “borrow” them from a pretrained normalizing flow that already knows how to match each image to a noise code?
- Will this “teacher‑to‑student” approach make training easier and speed up image generation without losing quality?
How the method works (in simple terms)
Think of image generation like turning TV static into a clear photo:
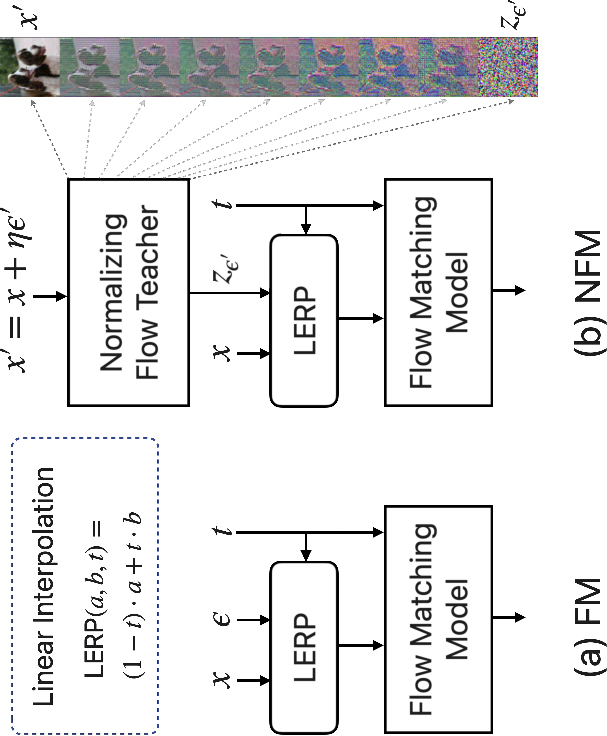
- Flow Matching trains a “guide” that tells you, at each tiny step, which way to move the static so it becomes a real image. To train this guide, you need pairs: a random noise sample and a real image. How you pair them (called “coupling”) really affects learning.
- Normalizing Flows are like reversible recipes. They can take an image and turn it into a noise code, and also go back from the noise code to the image.
Here’s the idea behind NFM:
- Train a normalizing flow (the teacher) that learns a one‑to‑one mapping between images and noise. For any image, the teacher gives you its “matching” noise code.
- Use those teacher‑made pairs (image ↔ noise code) to train a flow‑matching student. The student learns a simpler, faster way to go from noise to image by following a smoother path—because the pairs now make sense (they match!) rather than being random.
Why this helps:
- Smarter pairing: Instead of matching each image with a random noise sample, the teacher gives each image its own best‑matched noise code.
- Straighter paths: The student’s “route” from noise to image bends less, so it needs fewer steps to get a good result.
- Faster sampling: Unlike the teacher (which is slow because it builds images patch‑by‑patch), the student can generate in fewer steps and much faster.
Helpful mini‑glossary (everyday language):
- Coupling: how you match a noise sample with a real image during training (like pairing puzzle pieces).
- Optimal Transport (OT): a math method to find efficient pairings between two sets (here, noise and images).
- Normalizing Flow (NF): a reversible function that links each image to a unique noise code and back.
- Flow Matching (FM): training a model to follow a path from noise to image.
- Distillation: teaching a simpler/faster student model to imitate a stronger teacher model.
What they did in experiments
- Datasets: ImageNet at 64×64 and 256×256 resolutions (the 256×256 version uses a standard image‑to‑latent encoder).
- Teacher: a modern normalizing flow called TarFlow (auto‑regressive Transformers), which is accurate but slow because it generates sequentially.
- Students: flow‑matching models trained using teacher‑provided image↔noise pairings.
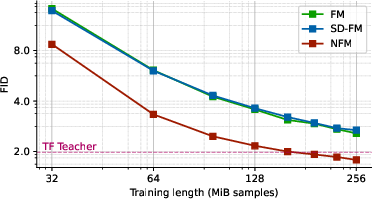
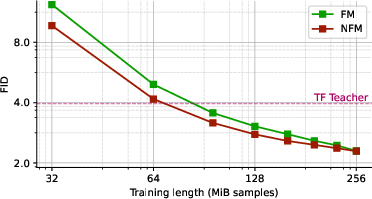
- Measuring quality: They used FID (Fréchet Inception Distance). Lower is better and means the generated images look more like real images.
- Measuring speed: They reported generation latency and the number of function evaluations (NFEs)—basically, how many steps it takes to make an image.
Main findings and why they matter
- Better image quality with fewer steps:
- Students trained with NFM had lower FID than standard FM (random pairings) and even OT‑style couplings in many cases.
- In several settings, the student also beat the teacher’s image quality (FID), which is surprising because teachers are usually stronger.
- Much faster generation:
- The student generated images up to about 32× faster than the teacher while achieving better FID; with even fewer steps, speedups were larger (with some quality trade‑off).
- Straighter, more stable generation paths:
- The student’s “route” from noise to image bent less (lower curvature), which makes ODE solvers more stable and reduces the number of steps needed.
- Works especially well with few steps:
- When you allow only a small number of generation steps, NFM’s smart pairings help a lot more than random or OT pairings.
- Interesting science note:
- In the teacher’s noise space (“z‑space”), nearby images in pixel space don’t necessarily stay neighbors. Even so, using these teacher‑made pairings still helps training a lot—suggesting you don’t need perfect neighborhood preservation to get better flows.
What this could mean going forward
- Faster, better generators: You can train a fast FM model that makes images quickly and well by distilling from a slower NF teacher.
- Reusable “noise encoders”: Just like we reuse pretrained autoencoders that turn images into compact features, we might reuse pretrained normalizing flows that turn images into well‑behaved “noise codes” to simplify training other generators.
- Flexible toolkit: This approach is compatible with many flow architectures and could be combined with OT methods for even better results.
- Broader impact: Beyond images, the idea—using a reversible teacher to supply smarter training pairs—could help train generative models in other domains (audio, 3D, etc.).
Simple takeaway
By letting a reversible “teacher” model tell us how each image matches to a specific noise code, we can train a “student” flow model that learns faster, makes higher‑quality images, and generates them much more quickly. This smart pairing step is the key that unlocks both better quality and speed.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that the paper leaves unresolved, structured for actionable follow-up work.
- Theory: Lack of formal guarantees that NF-induced couplings reduce conditional velocity variance, trajectory curvature, and ODE integration error in FM; no conditions specified under which NFM strictly dominates independent or OT-style couplings.
- Attribution: Insufficient disentanglement between two drivers of improvement—lower maximum noise (via ) vs. better endpoint coupling; needs controlled ablations that match maximum noise across methods while varying only coupling.
- Coupling fidelity: The distillation target is pairwise (teacher z given x), yet empirical outcomes are distributional; why does pairwise matching break, and can losses or regularizers enforce stronger pairwise alignment when desired?
- Teacher dependence: Sensitivity of NFM to teacher quality, capacity, and architecture is only partially probed (correlated with NLL at fixed ); more systematic study needed across diverse NF families (e.g., Glow, NSF, continuous-time flows), capacities, and training budgets.
- Cost–benefit: End-to-end compute/energy accounting (NF teacher training + NFM student training) vs. alternatives (e.g., SD-FM, rectified flows, direct few-step solvers) is missing; need standardized throughput/quality/compute comparisons.
- Robustness to suboptimal teachers: Behavior when the teacher is undertrained, miscalibrated, or overfits; how much degradation in the teacher (or label noise) can the student tolerate while retaining benefits?
- Generality beyond images: All experiments are ImageNet-only (64 and 256) and class-conditional; applicability to other modalities (audio, video, 3D), continuous or structured conditioning (e.g., text embeddings), and unconditional settings remains untested.
- Scaling: No evaluation beyond 256-resolution (other than via a VAE latent for 256); how does NFM perform at higher resolutions or with stronger autoencoding compression/quantization artifacts?
- Baselines breadth: Comparisons omit recent strong ODE/SDE solvers and schedulers (e.g., DPM-Solver, optimized logSNR schedules, consistency/mean-flow distillations); need Pareto curves vs. NFEs and quality across state-of-the-art methods.
- Solver/schedule sensitivity: Results reported for Euler/Heun with a specific schedule and logit-normal training-time sampling; sensitivity to step schedules, solver families, and adaptive step-size policies is not explored.
- Guidance dependence: Improvements are reported with classifier-free guidance (CFG) tuned by per-setup search; require fairness controls (fixed guidance, guidance-free) and study of sensitivity to label-drop probability p and guidance scale.
- Evaluation breadth: FID-only assessment (computed w.r.t. training data) limits insight; add precision/recall, density–coverage, CLIP scores, human evaluation, and OOD tests (e.g., different splits) to assess diversity, fidelity, and generalization.
- SD-FM comparisons at scale: SD-FM is only compared at 64×64; missing comparisons on 256 with the same latent pipeline and sampling budgets; also unexplored: combining SD-FM with NFM as proposed (true-Gaussian-to-pseudo-Gaussian mapping).
- z-space Gaussianity: The teacher’s z is “pseudo-Gaussian” and normalized by σ_f; quantify departures from Gaussianity (marginals, covariance, higher moments) and their impact on FM training and inference stability.
- Normalization choice: The definition and estimation of σ_f (per-dimension vs. global, dataset vs. batch statistics) is ambiguous; need to test normalization strategies and their effect on stability and quality.
- Noise injection role: Best teacher η values seem to transfer to best NFM outcomes, but the mechanism is unclear; characterize how η shapes z-geometry, coupling variance, and student performance; explore deterministic distillation (η=0) vs. stochastic (η>0).
- z-space geometry: Neighbor structure is not preserved (same-image z’s are farther apart than cross-image same-noise z’s); is this property intrinsic to AR-NF/TarFlow or to NF broadly? Can architectural or loss changes enforce partial neighborhood preservation, and does that help FM?
- Field smoothness and curvature: Curvature is measured, but the link between teacher z-geometry and the learned vector field’s Lipschitzness or curvature is not formalized; develop metrics connecting z-space structure to integration stability and step efficiency.
- Joint training: Only sequential training (NF teacher then FM student) is explored; investigate joint or alternating training (e.g., co-optimization of NF coupling and FM student) and whether that yields better couplings than a fixed teacher.
- Alternative distillation targets: Beyond endpoint vector regression, explore distilling intermediate vector fields, score functions, or trajectories (e.g., teacher-informed control variates) to reduce error accumulation and strengthen pairwise fidelity.
- Conditioning semantics: Claim that NFM benefits from label-aware coupling vs. SD-FM’s label penalty, but no studies with hierarchical labels, multi-labels, or continuous attributes; assess coupling under richer conditioning structures.
- Failure modes: No analysis of class-wise performance, mode coverage vs. collapse, or sensitivity to adversarial/corrupted conditions; need per-class FID/PR and robustness evaluations.
- Reproducibility and variability: Single-seed or limited-seed reporting; quantify variance across seeds, teacher initializations, and datasets; provide confidence intervals for FID and curvature.
- Memory/latency profiling: Latency improvements reported vs. AR-NF only; provide wall-clock and memory comparisons vs. competitive diffusion baselines under matched hardware and batch sizes; analyze student architecture trade-offs.
- Safety/privacy: Distilling couplings derived from data-trained NF might encode dataset-specific artifacts; assess memorization/privacy leakage risks and propose mitigation (e.g., DP training or coupling sanitization).
- Extension to text-to-image: Mentioned as future direction; concrete protocol needed: which NF teachers (e.g., StarFlow), how to handle high-dimensional text embeddings, and how guidance interacts with NFM in multi-modal settings.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases enabled by Normalized Flow Matching (NFM)—distilling a Normalizing Flow (NF) teacher into a fast Flow Matching student—together with sectors, candidate tools/workflows, and feasibility notes.
- Fast, high-quality image generation in creative tooling (Media, Entertainment, Gaming)
- What: Replace slow auto-regressive NF (e.g., TarFlow) decoders in asset pipelines with NFM students for 30×–140× faster sampling at equal or better FID for class-conditional image synthesis.
- Tools/workflows: Train TarFlow teacher (tune η), compute teacher output normalization σ_f, distill to FM student g via NFM; deploy few-step Heun/Euler ODE solvers; optional VAE for latent-space generation.
- Assumptions/dependencies: Availability of a competent NF teacher; compute for teacher pretraining; guidance tuning; integration with existing VAE/text-conditioning stacks.
- Latency and cost reduction for generative inference services (Software/Cloud, MLOps)
- What: Replace high-latency AR-NF endpoints with NFM students to cut GPU-hours per generated asset; maintain teacher for likelihood tasks while serving NFM for generation.
- Tools/workflows: Dual-model serving (NF for NLL; NFM for gen); NFE-optimized schedules; autoscaling based on steps; Golden Section Search to fix CFG per SKU.
- Assumptions/dependencies: Distillation performed per domain; KPI alignment (FID/latency/throughput); monitoring for sample quality drift.
- On-device generative features (Mobile, Edge AI, AR filters)
- What: Deploy few-step NFM image generators for mobile camera filters, stylization, or offline content creation where latency and energy budgets are tight.
- Tools/workflows: Quantized NFM student; mobile-friendly solvers (few NFE); distill in VAE latent space to reduce memory/compute.
- Assumptions/dependencies: Memory footprint constraints; hardware acceleration support; privacy policies for on-device generation.
- Rapid data augmentation for vision models (Education, Industry ML, Robotics)
- What: Use fast NFM generators to produce high-fidelity augmentations for classifier/detector training and domain randomization.
- Tools/workflows: Integrate NFM sampling into training dataloaders; class-conditional sampling for long-tail balancing; few-step inference for throughput.
- Assumptions/dependencies: Validate augmentation utility for target tasks; avoid distribution shift; licensing for synthetic data usage.
- Cheaper and faster FM training via teacher-induced couplings (Academia, AI Research)
- What: Use NF-derived couplings to reduce target/gradient variance and curvature, accelerating FM convergence and improving few-step FID in research prototypes.
- Tools/workflows: Swap independent/OT couplings for NF-based z; maintain existing FM code; reuse teacher across projects.
- Assumptions/dependencies: Teacher quality matters; η and schedule choices affect stability; benefits strongest in few-step regimes.
- Likelihood + generation pipelines (Quality control, Anomaly detection)
- What: Keep NF teacher for calibrated NLL and OOD scoring while using NFM student for fast reconstructions or counterfactual generation.
- Tools/workflows: Joint deployment; thresholds on teacher NLL; NFM for sampling-based diagnostics.
- Assumptions/dependencies: Calibration of NLL per dataset; governance around synthetic data in QA workflows.
- Benchmarking and coursework (Education, Academic labs)
- What: Provide students and researchers a practical baseline demonstrating how couplings impact training speed, curvature, and FID.
- Tools/workflows: Use released code/datasets; replicate ImageNet64/256 experiments; extend to new solvers and schedules.
- Assumptions/dependencies: GPU availability for teachers; clear documentation; reproducible seeds and CFG settings.
- Faster simulation asset generation (Robotics, Autonomous systems)
- What: Generate backgrounds/textures quickly for domain randomization and sim2real workflows without heavy AR-NF decoders.
- Tools/workflows: NFM students with few NFEs; sampling integrated into simulation asset pipelines; optional class conditions for scenario coverage.
- Assumptions/dependencies: Relevance of generated assets to target sensors/domains; validation against performance metrics.
- Privacy-preserving image synthesis (Healthcare preclinical prototyping, Enterprise data sharing)
- What: Use NFM for rapid generation of synthetic images to explore pipeline feasibility where direct use of sensitive data is constrained.
- Tools/workflows: Train NF/NFM on de-identified or approved datasets; limit scope to exploratory/auxiliary tasks.
- Assumptions/dependencies: Regulatory compliance; rigorous evaluation needed before downstream clinical or regulated use.
- Model compression and deployment workflow for flow-based generators (MLOps)
- What: Establish distillation as a standard step to translate invertible AR-NF research models into deployable FM students.
- Tools/workflows: CI/CD pipelines triggering NFM distill jobs after NF model milestones; automated CFG tuning; latency-FID dashboards.
- Assumptions/dependencies: Organizational buy-in for dual-model lifecycle; compute for distillation; monitoring for regressions.
Long-Term Applications
These opportunities require additional research, scaling, or domain adaptation before broad deployment.
- Multimodal, conditional generation at low latency (Text-to-image/video/audio; Creative suites)
- What: Extend NFM to teachers like StarFlow for text-conditioned image/video; approach diffusion-quality outputs with AR-NF-like likelihoods at reduced latency.
- Tools/workflows: Multimodal conditioning stacks; latent diffusion backbones; mixed teachers per modality.
- Assumptions/dependencies: Availability of strong multimodal NF teachers; scalable training data; robust CFG design.
- Near one-step or real-time generation (AR/VR, Gaming, UX)
- What: Combine NFM with Mean Flows and trajectory-curvature minimization to reach one- or few-step generation for interactive applications.
- Tools/workflows: Co-train for low curvature; schedule/solver co-design; hardware-aware optimizations.
- Assumptions/dependencies: Stability at extremely low NFEs; quality retention; solver robustness.
- Foundation “noise-encoder” models (AI Infrastructure)
- What: Publish reusable NF teachers as bijective data-to-noise encoders across domains, enabling plug-and-play NFM students for fast generation.
- Tools/workflows: Model zoos with metadata (η, σ_f, NLL); domain adapters; standard APIs for z-space access.
- Assumptions/dependencies: Community standards; licensing; sustained maintenance and evaluation suites.
- Hybrid coupling frameworks (NFM + Semi-Discrete OT) (Research, Tooling)
- What: Couple true Gaussian noise to NF’s pseudo-Gaussian z via OT, potentially improving robustness when teacher capacity is limited.
- Tools/workflows: SD-FM pre-processor to map ε→z; ablations across class-conditional setups; adaptive couplings by data regime.
- Assumptions/dependencies: Algorithmic complexity; stability under hybridization; empirical validation across datasets.
- Regulated synthetic data generation (Healthcare, Finance, Public sector)
- What: Use NF teacher’s likelihoods for traceability and risk assessment, with NFM for scalable generation in data-scarce domains (e.g., rare disease imaging).
- Tools/workflows: Compliance tooling for audit trails; bias/fairness testing; privacy risk quantification; clinical validation studies.
- Assumptions/dependencies: Regulatory approvals; rigorous external validation; domain-specific labeling and governance.
- Time-series and tabular generative modeling (Finance, Energy, IoT)
- What: Adapt NFM to non-image modalities to accelerate generation of realistic time-series/tabular data for simulation, stress testing, and missing data imputation.
- Tools/workflows: NF teachers specialized for sequences; solver designs for causal/temporal constraints.
- Assumptions/dependencies: Demonstrated generalization beyond images; suitable evaluation metrics; safeguarding against misuse.
- On-device assistants with generative capabilities (Consumer devices, Automotive)
- What: Support offline, privacy-preserving generative features (e.g., scene editing, UI asset generation) with NFM’s low-latency inference.
- Tools/workflows: Distill to compact students; mixed-precision/quantization; platform-specific accelerators.
- Assumptions/dependencies: Memory and power budgets; UX-quality thresholds; edge update/rollback strategies.
- Energy- and carbon-aware AI policies (Policy, Sustainability)
- What: Encourage adoption of low-NFE generative models (like NFM students) in procurement and sustainability benchmarks to reduce operational emissions.
- Tools/workflows: Measurement protocols linking NFEs to energy per sample; reporting standards; incentives.
- Assumptions/dependencies: Industry-wide agreement on metrics; verifiable measurement; alignment with product KPIs.
- Security and provenance tooling (Trust & Safety)
- What: Investigate whether path curvature or coupling signatures can serve as watermarks or provenance cues for distinguishing generators/edits.
- Tools/workflows: Statistical tests on ODE trajectories; classifier training on solver/coupling fingerprints.
- Assumptions/dependencies: Robustness against adversarial removal; generalization across models; low false positives.
- Automated teacher–student co-design (AutoML for generative pipelines)
- What: Auto-select teacher architectures/η and student solvers/steps to meet target FID-latency budgets under compute constraints.
- Tools/workflows: Bayesian optimization or bandit strategies; meta-evaluation on small proxies (e.g., 8k-sample FID); early stopping criteria.
- Assumptions/dependencies: Proxy-to-full correlation reliability; infrastructure for large search spaces; cost governance.
Glossary
- Auto-regressive (AR): A modeling pattern where variables are generated sequentially, each conditioned on previous outputs. "auto-regressive (AR) blocks"
- Auto-Regressive Normalizing Flows (AR-NF): Normalizing flows that generate outputs sequentially (autoregressively), typically with higher sampling latency. "while also improving on the teacher AR-NF model."
- Barycenter: A linear interpolation between two points (here, noise and data) used during training. "the velocity is trained to point from that noise towards data at any barycenter between the two."
- Bijection: A one-to-one, invertible mapping between two spaces. "they learn, by construction, a bijection between the data and a Gaussian noise source"
- Change of variable formula: The likelihood computation rule for invertible transforms using the Jacobian determinant. "NFs are likelihood based methods trained with the change of variable formula."
- Classifier-Free Guidance (CFG): A sampling technique that adjusts conditional generation by mixing conditional and unconditional model predictions. "With CFG"
- Conditional-mean field: The expected velocity (denoising direction) conditioned on the current state and time. "a smoother conditional-mean field "
- Coupling measure: A rule or distribution specifying how to pair noise samples with data samples during training. "A crucial ingredient in flow training is the choice of coupling measure for sampling noise/data pairs"
- Curvature: A measure of how much generated trajectories deviate from straight paths during ODE integration. "The curvature is computed as follows:"
- Diffusion Normalizing Flow (DiffFlow): A hybrid model that unifies diffusion processes and normalizing flows. "Diffusion Normalizing Flow (DiffFlow) \cite{zhang2021diffusion} unifies normalizing flows and diffusion models"
- Distillation: Training a smaller/faster “student” model to mimic a larger “teacher” model’s behavior. "distillation approaches~\citep{hinton2014dark,lu2025bidirectional} yield a more consistent and significant speedup for normalizing flows"
- Evidence Lower Bound (ELBO): A variational objective commonly optimized in generative modeling; in FM appears via a weighted regression interpretation. "FM remains the same weighted-ELBO/path-KL regression of a vector field along the linear interpolant."
- Euler solver: A first-order numerical integrator used to solve ODEs during sampling. "Sampling uses either Euler \cite{euler1768institutionum,song2021denoising} or Heun \cite{heun1900neue,karras2022elucidating} solvers: Euler when and Heun when "
- Fréchet Inception Distance (FID): A metric for sample quality comparing statistics of generated and real images in feature space. "Following commonly accepted practice, all reported Fréchet Inception Distance (FID) \cite{dowson1982frechet} results are measured between the training dataset distribution and randomly generated samples."
- Gaussian unit sphere: The set of normalized Gaussian latent vectors lying approximately on a sphere of unit radius. "the NF learns representations that are on the surface of a Gaussian unit sphere."
- Golden Section Search: A derivative-free optimization method used here to tune guidance strength. "by means of a Golden Section Search"
- Heun solver: A second-order ODE integrator (improved Euler) used for more accurate sampling. "Sampling uses either Euler \cite{euler1768institutionum,song2021denoising} or Heun \cite{heun1900neue,karras2022elucidating} solvers"
- Independent coupling: Pairing data and noise independently at random during FM training. "the independent coupling (sampling independently Gaussian noise and data uniformly at random in the dataset) is the most standard"
- Invertible function: A mapping with a well-defined inverse, required for normalizing flows. "it learns an invertible function "
- Jacobi iterations: An iterative numerical method used here to accelerate NF sampling without retraining. "iterative approaches such as Jacobi iterations and speculative sampling~\citep{wiggers2020predictive, song2021accelerating, chen2023accelerating, monea2023pass, teng2025accelerating, liu2025accelerate} provide a training-free strategy to accelerate decoding"
- Kullback–Leibler (KL) divergence: A measure of divergence between probability distributions used as an optimization objective. "minimizing the KL divergence between their trajectory distributions."
- Latent space: A transformed representation space (often lower-dimensional) used for modeling or generation. "to transform the data from pixel space to latent space."
- Logit-normal distribution: A distribution over (0,1) obtained by applying a sigmoid to a normal variable; used for sampling noise levels. "Noise levels are sampled from the logit-normal distribution \cite{aitchison1982statistical,esser2024scaling} "
- Maximum likelihood principle: Fitting models by maximizing the probability of observed data under the model. "and rely on the maximum likelihood principle to fit that bijection."
- Mean Flows: A one-step generative modeling approach proposed as future work to further reduce latency. "application to Mean Flows \cite{geng2025mean} look like an interesting line of research"
- Mean preserving (setting): A diffusion/noise parameterization where the mean of the signal is preserved across timesteps. "converting from the variance exploding setting to the mean preserving one."
- Neural ODE: A neural network parameterization of an ordinary differential equation used for continuous-time transformations. "Flow Matching (FM) ... learn Neural-ODE models~\citep{chen2018neural}"
- Normalized Flow Matching (NFM): The proposed method that trains FM models using couplings distilled from a normalizing flow teacher. "we propose Normalized Flow Matching (NFM), a new method"
- Normalizing Flows (NF): Invertible neural networks that map data to a simple base distribution (e.g., Gaussian) for exact likelihoods. "Normalizing Flows (NF) \cite{tabak2010density,dinh2014nonlinear,rezende2015variational} do not suffer from any ambiguity when it comes to coupling noise to data"
- Number of function evaluations (NFE): The count of model calls during ODE integration, used to quantify sampling cost. "where NFE denotes the number of function evaluations."
- ODE integrator: A numerical method used to integrate the learned velocity field during sampling. "that velocity is paired with an ODE integrator to recover outputs."
- Optimal Transport (OT): A framework for finding an optimal coupling between probability distributions. "using for instance ideas from optimal transport (OT)"
- Rectified flows: An iterative refinement approach for training flow models with improved coupling. "that deficiency has encouraged iterative approaches such as rectified flows~\citep{liu2022flow}."
- Semi-Discrete Optimal-Transport (SD-FM): An OT-based deterministic rule assigning each noise vector to a specific data point. "culminating with Semi-Discrete Optimal-Transport (SD-FM) - the semidiscrete deterministic rule proposed by \citep{mousavi2025flow}"
- Speculative sampling: A decoding-time acceleration technique that proposes multiple steps ahead and verifies them. "iterative approaches such as Jacobi iterations and speculative sampling~\citep{wiggers2020predictive, song2021accelerating, chen2023accelerating, monea2023pass, teng2025accelerating, liu2025accelerate}"
- Stochastic differential equations (SDEs): Differential equations with randomness, used to describe diffusion processes. "learning both the forward and backward stochastic differential equations jointly"
- TarFlow: Transformer Auto-Regressive Normalizing Flows, a recent NF variant achieving strong image modeling results. "Transformer Auto-Regressive Normalizing Flows, in short TarFlow \cite{zhai2025tarflow}, which achieved promising experimental results"
- Variational Auto-Encoder (VAE): A generative model that learns latent representations and reconstructs inputs via a probabilistic decoder. "we use a pretrained variational auto-encoder from Stable Diffusion \cite{rombach2022highresolution}"
- Vector field: A function assigning a velocity vector to each point in space-time, learned in FM to transport noise to data. "regression of a vector field along the linear interpolant."
- Variance exploding (setting): A diffusion/noise parameterization where variance increases with time. "converting from the variance exploding setting to the mean preserving one."
- z-space: The latent Gaussian space produced by a normalizing flow (often denoted z). "Normalizing Flows z-space structure"
Collections
Sign up for free to add this paper to one or more collections.