- The paper demonstrates that interleaving LLM-guided symbolic planning with RL grounding enhances compositional skill learning in sparse-reward tasks.
- It introduces frontier checkpointing and trajectory analysis to correct LLM-generated abstractions, boosting sample efficiency and success rates.
- Experimental results show SCALAR outperforms flat RL baselines, achieving 88.2% diamond collection and enabling deep tasks like Enter Gnomish Mines.
SCALAR: Compositional Skill Learning via LLM-Guided Symbolic Planning and RL Grounding
Introduction and Motivation
This paper introduces SCALAR, a framework for skill acquisition that interleaves LLM-guided symbolic planning with reinforcement learning (RL) to enable compositional mastery of long-horizon tasks in environments with sparse rewards and deep prerequisite structures. Existing LLM-based agents can synthesize high-level plans or code for structured APIs, but struggle in low-level control due to the lack of grounded feedback loops. Conversely, monolithic RL agents handle grounding but are impeded by intractable exploration in compositional environments. SCALAR bridges this gap by orchestrating a bidirectional cycle: LLMs generate candidate symbolic skills as STRIPS-style operators, RL policies ground each skill through direct interaction, and trajectory analysis iteratively corrects the LLM-generated abstractions based on environmental evidence.
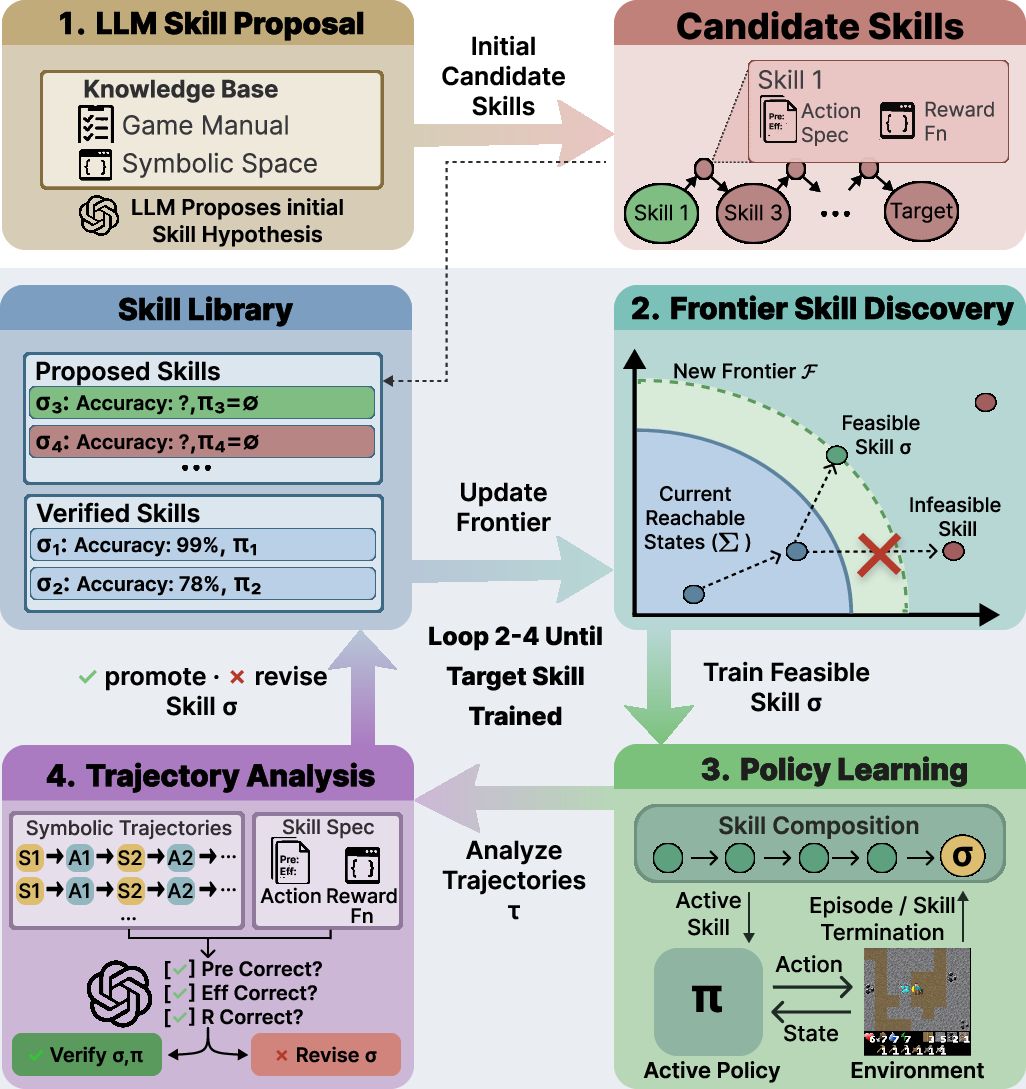
Figure 1: The SCALAR LLM-RL loop. Skills are specified as symbolic operators, grounded via RL training, and refined through bidirectional feedback from successful executions.
Methodology
Symbolic Skill Proposal and Graph Construction
LLMs ingest rich natural language sources (e.g., manuals) and output a set of symbolic operators. Each operator encapsulates preconditions (Pre), positive/negative effects (Eff+,Eff−), and is mapped to executable completion/reward code. The feasibility and novelty of each operator is checked by compositional planning: only skills whose preconditions are reachable from existing skills (plus the initial state) are considered for addition. Novelty filtering prunes redundant operators.
Hierarchical Skill Composition and RL Grounding
Given a target skill, a STRIPS planner composes feasible operator chains so that the RL agent can progress through prerequisite skills. RL policies (instantiated as options) are jointly trained for all active skills; prerequisite heads are updated throughout skill compositions preventing catastrophic forgetting.
Frontier checkpointing is introduced to ameliorate sample inefficiency in environments with long prerequisite chains. At each skill boundary, the environment state is checkpointed, enabling accelerated exploration by probabilistic restoration at episode start—maximizing training frames on the actual target skill while maintaining coverage diversity.
Pivotal Trajectory Analysis
Trajectory analysis—triggered after the first nonzero success on a skill—uses complete execution rollouts to verify or correct LLM-specified preconditions, effects, and resource estimates. This is critical in two cases: over-conservative LLM estimates (which bloat prerequisite chains, wasting frames) and failure modes where LLM priors omit contextual survival prerequisites not evident from documentation. Refinements detected by trajectory analysis trigger policy retraining with corrected specifications, ensuring skill library robustness.
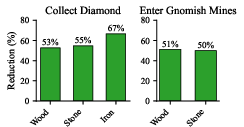
Figure 2: Resource usage before diamond collection: trajectory analysis sharply reduces unnecessary gathering versus uncorrected LLM priors.
Experimental Results
Craftax-Classic and Craftax Benchmarks
Evaluation centers on Craftax-Classic (single, 64×64 overworld with guaranteed diamond spawns) and Craftax (nine procedural floors, increased action set, scarce critical resources, and mandatory combat milestones). The key tasks span both resource collection (e.g., Collect Diamond) and mastery of multi-step compositional chains (e.g., Enter Gnomish Mines, which gated on prior dungeon entry and 8-orc combat).
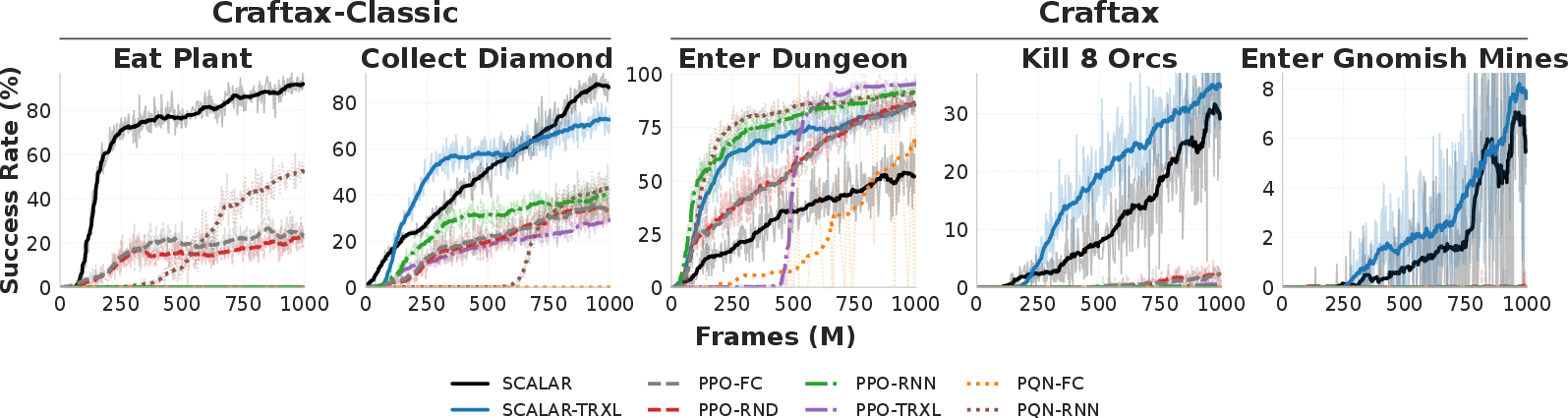
Figure 3: Training curves on both Craftax-Classic and Craftax: SCALAR delivers an 88.2% diamond collection rate and unlocks Gnomish Mines (9.1% success) where all monolithic RL baselines fail.
SCALAR vs. Flat RL Baselines
SCALAR-FC (feedforward) surpasses the best-performing baseline (PQN-RNN) by a factor of 1.9x on diamond collection (88.2% vs 46.9%). SCALAR exclusively targets task-relevant skills, with RL baselines diluting their capacity across a broad achievement signal spectrum.
Critically, on the deepest prerequisites (Enter Gnomish Mines), all monolithic baselines fail (0%), whereas SCALAR and SCALAR-TRXL achieve 9.1% and 8.2% respectively—demonstrating effective compositional chaining and exploration (Figure 3). The gap is further widened in ablations: removing trajectory analysis drops success from 88% to 67% on diamonds, and disables progress (0%) on deep tasks.
Mechanism Dissections
SCALAR's efficiency arises from:
- Pivotal trajectory analysis: Corrects gross resource overestimates (e.g., initial LLM suggests 19 wood, true requirement is 9), redirecting training frames from wasteful precursor skills to the true target.
- Frontier checkpointing: Without resetting, the majority of training is wasted re-executing prerequisites, especially with elongated chains (Figure 4). Moderate reset probabilities optimize the trade-off between diversity (generalization) and skill-targeting (variance reduction), whereas high reset rates risk overfitting to checkpoint states (see additional train-eval gap analyses in the appendix).
- Goal-directedness: SCALAR entirely prunes nonessential achievements (Figure 5, Figure 6), in contrast to RL baselines, thus avoiding redundant skills and focusing sample complexity.
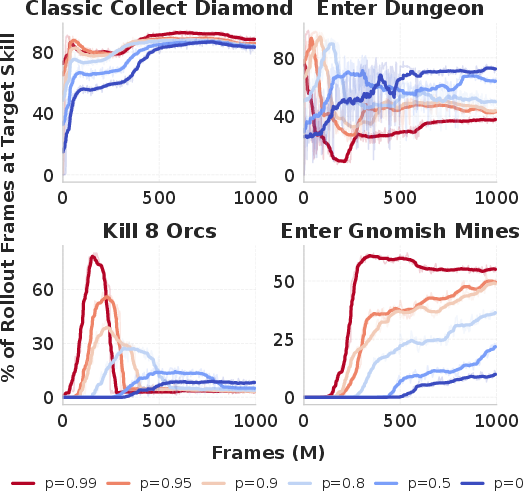
Figure 4: Fraction of training frames at the target skill, modulated by reset probability. Checkpointing is critical for non-trivial chain depths.
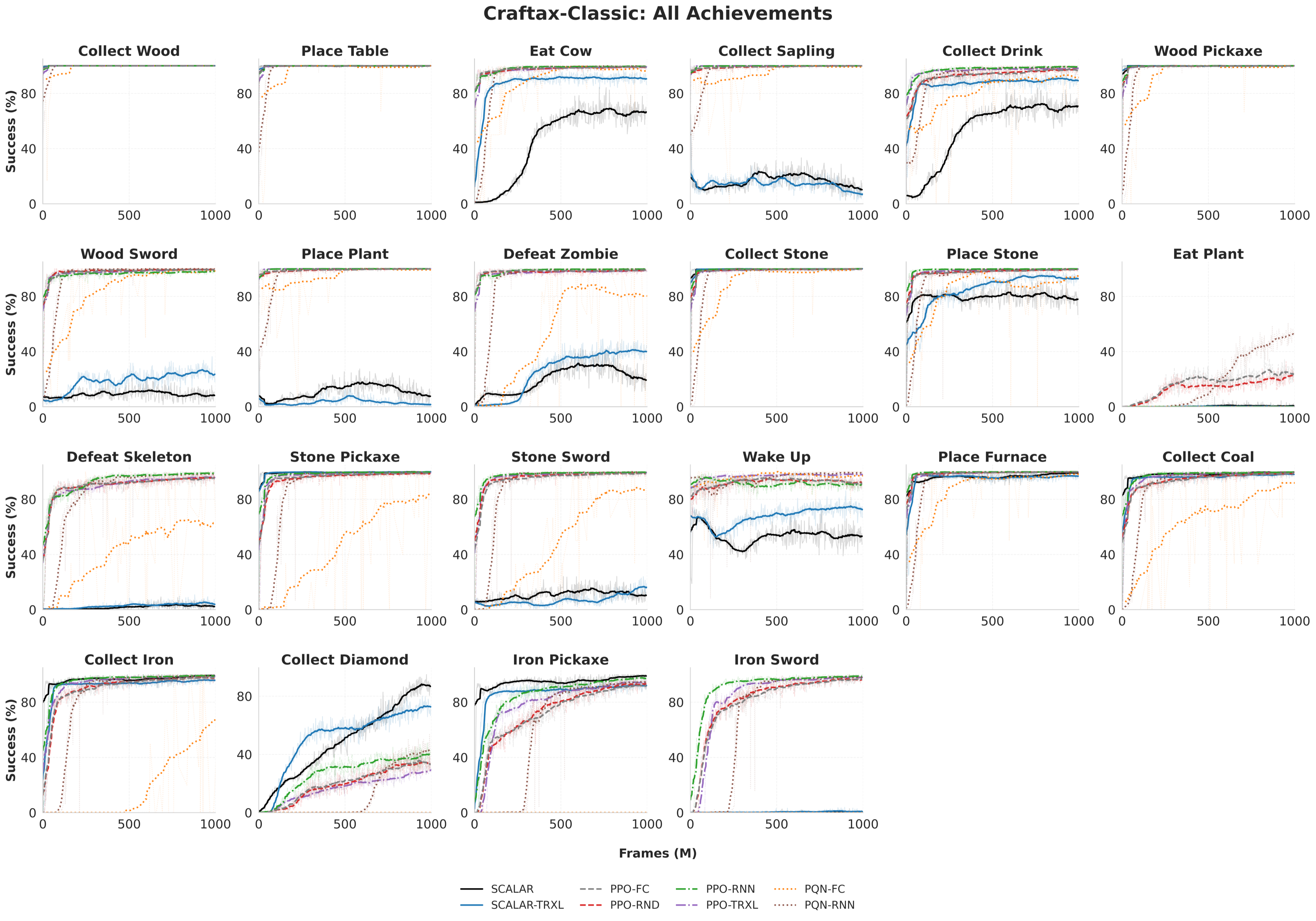
Figure 5: Achievement rates for Collect Diamond reveal SCALAR avoids irrelevant achievements prevalent among monolithic baselines.
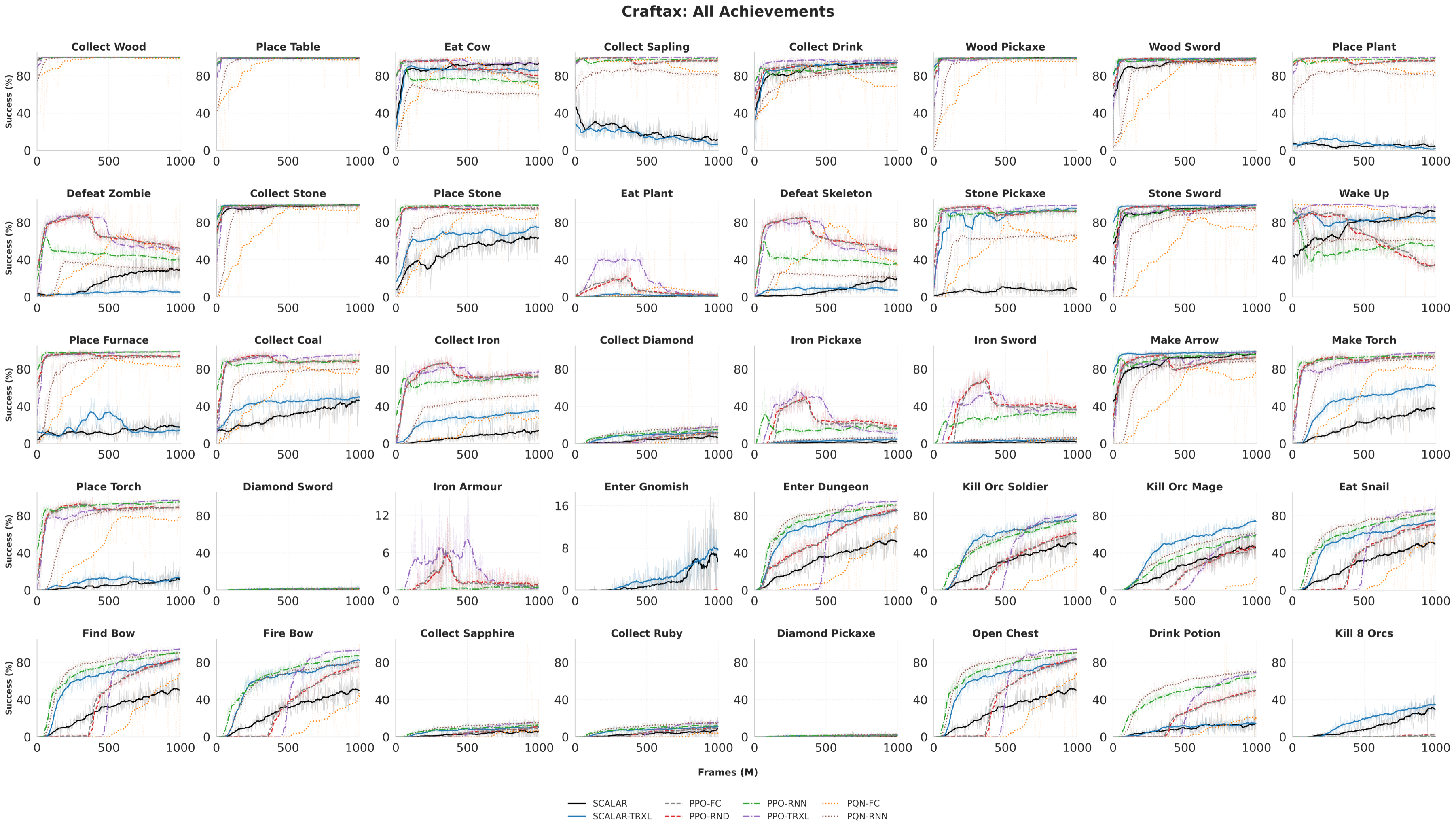
Figure 6: For Enter Gnomish Mines, SCALAR skips unnecessary iron tools, leveraging only essential skills as dictated by compositional planning.
Theoretical and Practical Implications
The SCALAR framework validates the utility of closed-loop symbolic planning and RL grounding underpinned by LLM priors, provided an automatic correction mechanism exists. The ability to synthesize abstract plans, ground them in complex perceptual domains, and robustly adapt plans when environment statistics (or task recipes) shift is essential for long-horizon generalization.
Practical implications include rapid skill reusability, improved sample efficiency in environments with state serialization (simulators), and amortization of LLM inference cost. Theoretically, SCALAR provides a path toward self-improving skill libraries that sidestep the manual bottleneck in reward/option engineering and adapt dynamically to OOD distributional shifts, as demonstrated in policy adaptation under recipe perturbation. However, the necessity for symbolic structure and factorizability in the environment restricts applicability outside structured simulation/robotics domains.
Discussion and Future Directions
Limitations remain: specification and manipulation of the symbolic abstraction restricts domains, and fixed skill ordering precludes opportunistic subtask interleaving. Although SCALAR's decomposition absorbs only LLM priors correctable via environmental feedback, domains where LLM priors qualitatively misalign with environment mechanics represent an unsolved problem. Real-world extensions will require symbol grounding beyond predefined state encodings and more flexible skill sequencing.
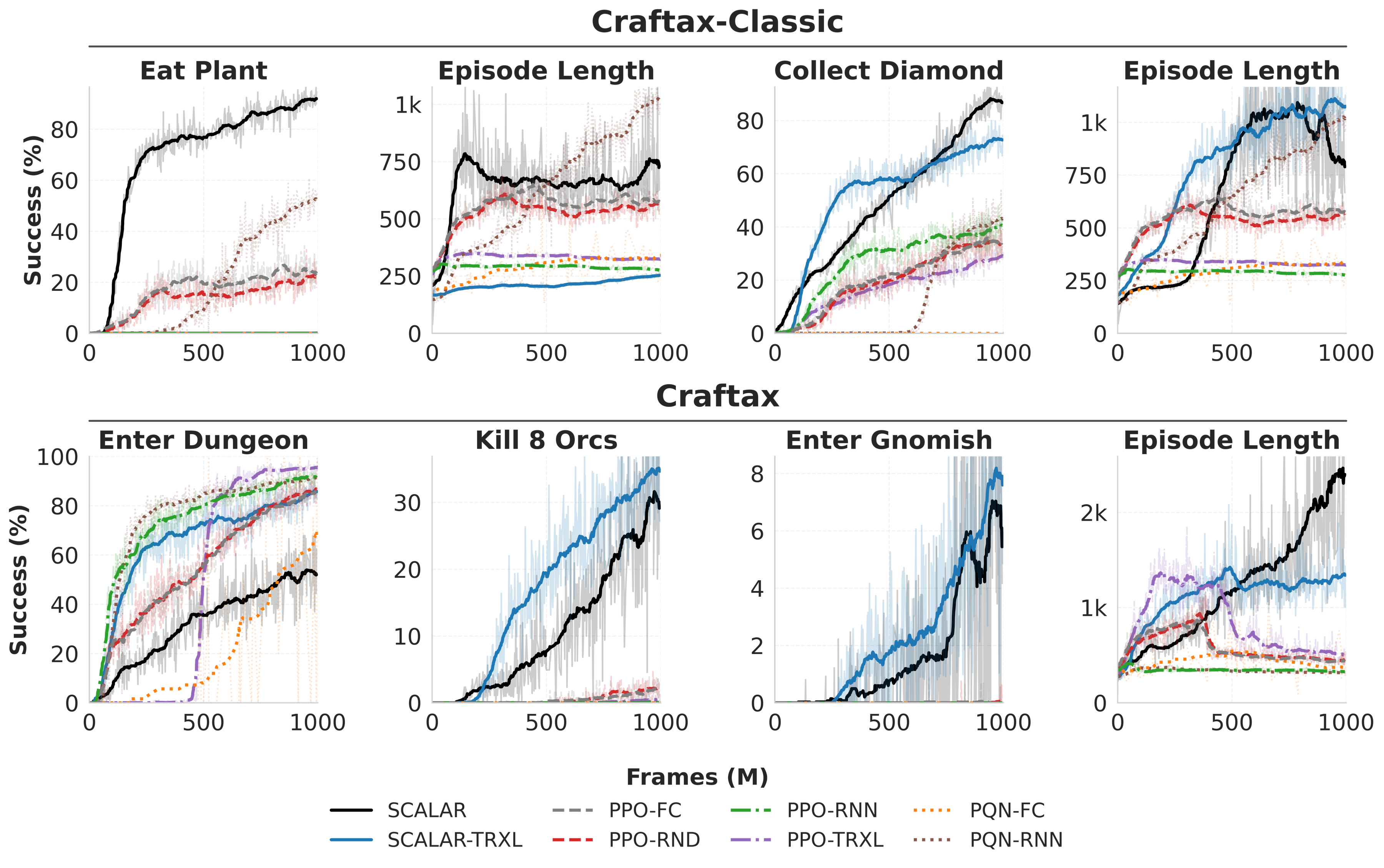
Figure 7: SCALAR’s longer episodes reflect successful compositional task completion, contrasting with the short (prematurely terminated) baseline episodes.
Conclusion
SCALAR represents a robust approach for hierarchical skill acquisition in compositional, sparse-reward settings by integrating LLM-generated STRIPS-like planning with deep RL grounding, enforced through systematic trajectory-based specification refinement. Its performance on Craftax benchmarks demonstrates meaningful progress toward scalable, interpretable, and continually-adapting RL agents with compositional skill libraries. Future advances should address symbol discovery, opportunistic skill execution, deployment in real-world domains lacking deterministic serialization, and further LLM-RL co-adaptation.
Reference: "SCALAR: Learning and Composing Skills through LLM Guided Symbolic Planning and Deep RL Grounding" (2603.09036)