Reading, Not Thinking: Understanding and Bridging the Modality Gap When Text Becomes Pixels in Multimodal LLMs
Abstract: Multimodal LLMs (MLLMs) can process text presented as images, yet they often perform worse than when the same content is provided as textual tokens. We systematically diagnose this "modality gap" by evaluating seven MLLMs across seven benchmarks in five input modes, spanning both synthetically rendered text and realistic document images from arXiv PDFs to Wikipedia pages. We find that the modality gap is task- and data-dependent. For example, math tasks degrade by over 60 points on synthetic renderings, while natural document images often match or exceed text-mode performance. Rendering choices such as font and resolution are strong confounds, with font alone swinging accuracy by up to 47 percentage points. To understand this, we conduct a grounded-theory error analysis of over 4,000 examples, revealing that image mode selectively amplifies reading errors (calculation and formatting failures) while leaving knowledge and reasoning errors largely unchanged, and that some models exhibit a chain-of-thought reasoning collapse under visual input. Motivated by these findings, we propose a self-distillation method that trains the model on its own pure text reasoning traces paired with image inputs, raising image-mode accuracy on GSM8K from 30.71% to 92.72% and transferring to unseen benchmarks without catastrophic forgetting. Overall, our study provides a systematic understanding of the modality gap and suggests a practical path toward improving visual text understanding in multimodal LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
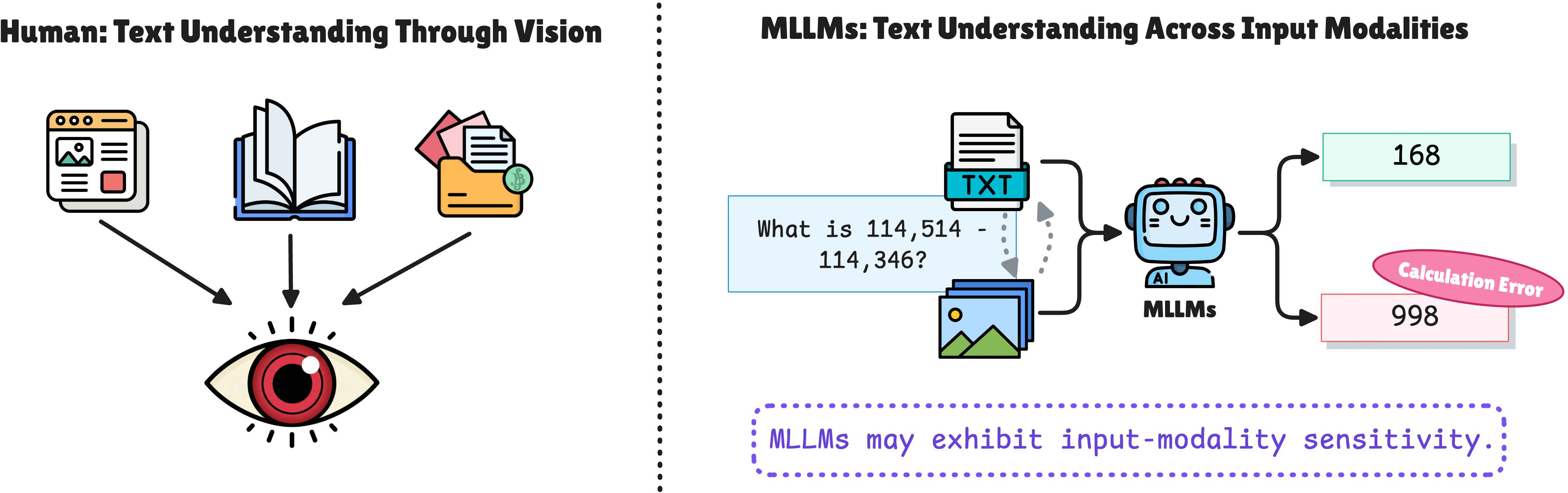
This paper looks at how AI models that can handle both pictures and text (called multimodal LLMs, or MLLMs) behave when the exact same words are shown in different ways. Sometimes the words are sent to the model as normal typed text. Other times, the words are shown as an image (like a screenshot or a photo of a page). The authors find that these models often do worse when they have to “read” the words from a picture. They call this drop in performance the “modality gap.”
Their big message: the problem isn’t that the models can’t think; it’s that they struggle to read when text turns into pixels. And they show a practical way to fix much of this problem.
What the researchers wanted to find out
- When and how much do models do worse if text is shown as an image instead of typed text?
- Is the problem about understanding and reasoning, or mostly about reading from images?
- Do details like font and image resolution matter?
- Can we train models, without rebuilding them, to read text-in-images almost as well as typed text?
How they studied it (explained simply)
To answer these questions, the team tested 7 different AI models on 7 different tasks. They tried five ways of feeding the same content to the models:
- Pure Text: normal typed words.
- Pure Image: the same words rendered as a picture (like a screenshot).
- Instruction + Image: a text instruction (e.g., “answer the question”) plus the picture of the content.
- OCR-1 Pass: ask the model to first read the picture and solve the problem in one go.
- OCR-2 Passes: ask the model to read the picture first (turn it back into text), and then solve the problem from that text.
They used both:
- Synthetic images: artificially rendered text (e.g., clean black text on a white background).
- Natural images: realistic screenshots or pages from Wikipedia and scientific PDFs (more like what the internet actually looks like).
They also:
- Ran a careful error analysis of over 4,000 mistakes to see what kinds of errors go up when text becomes an image.
- Tested how changing fonts and image resolution affects results.
- Tried a simple training fix called “self‑distillation,” where the model learns from its own step-by-step text answers and applies that same reasoning to images.
Note on terms:
- OCR means “Optical Character Recognition,” like asking a computer to read text from a picture.
- Chain‑of‑thought means “show your work” step by step.
- Self‑distillation here means: the model uses its own good text answers to teach itself how to answer when given images.
What they found (and why it matters)
Here are the most important takeaways, with brief explanations of why they matter:
- The “modality gap” depends on the task and the data.
- Math problems (like GSM8K) dropped a lot when text was shown as images—sometimes by over 60 percentage points.
- Knowledge-heavy questions (like general facts) dropped less.
- Real-world document images (like screenshots from Wikipedia or pages from scientific PDFs) often matched or even beat typed text.
- Why it matters: the gap isn’t universal. It’s especially big in tasks that are sensitive to small reading mistakes (like misreading digits in math), and smaller when images look like what the models saw during pretraining.
- Small rendering choices cause big swings.
- Changing the font alone could change accuracy by up to 47 percentage points. Handwriting-style fonts hurt the most; common digital fonts were fine. Resolution also mattered: too low makes reading harder, but smarter compression can help.
- Why it matters: fair evaluation needs to control font, size, and resolution. Otherwise, you might be measuring how weird the font is—not how good the model is.
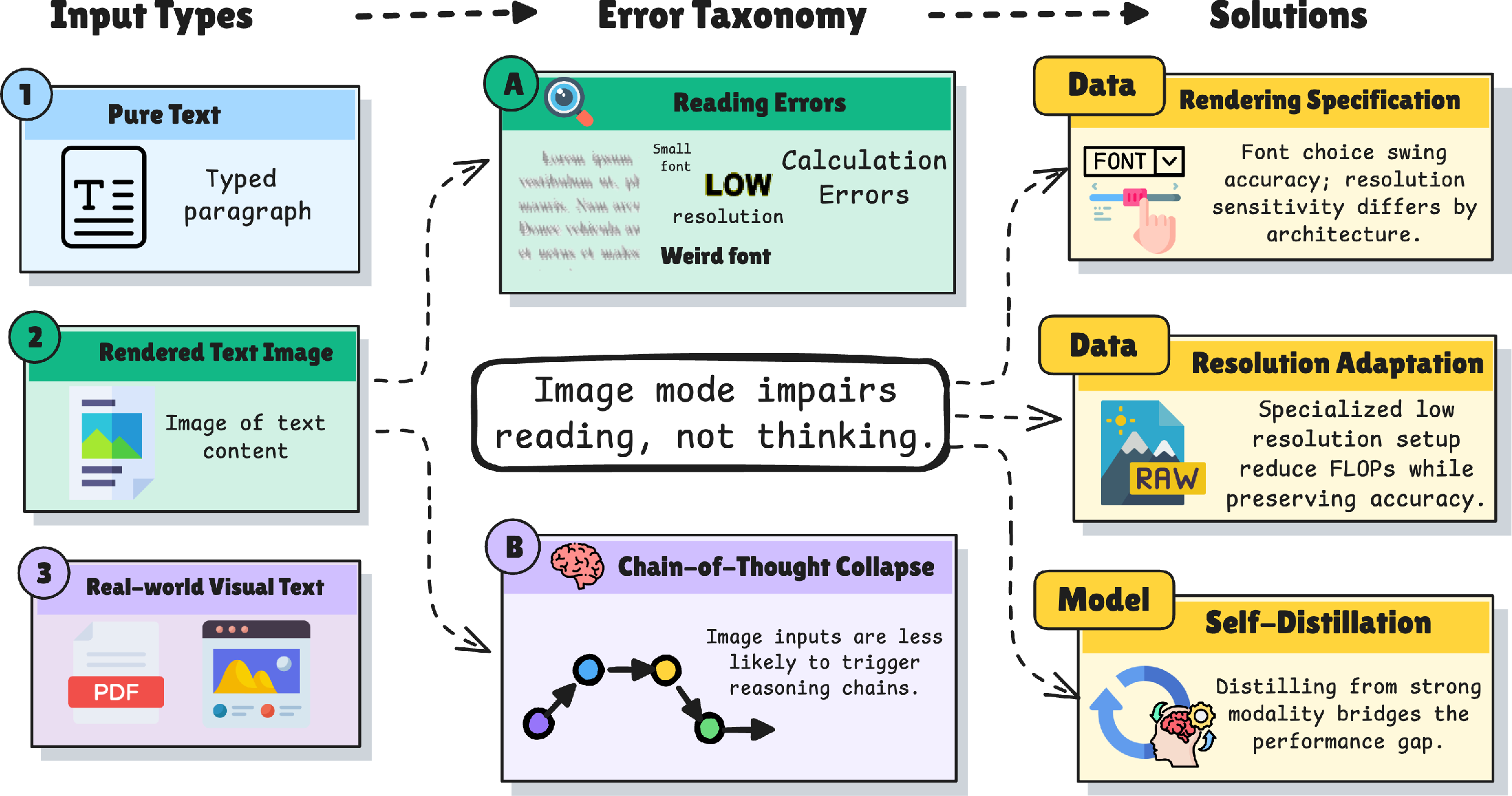
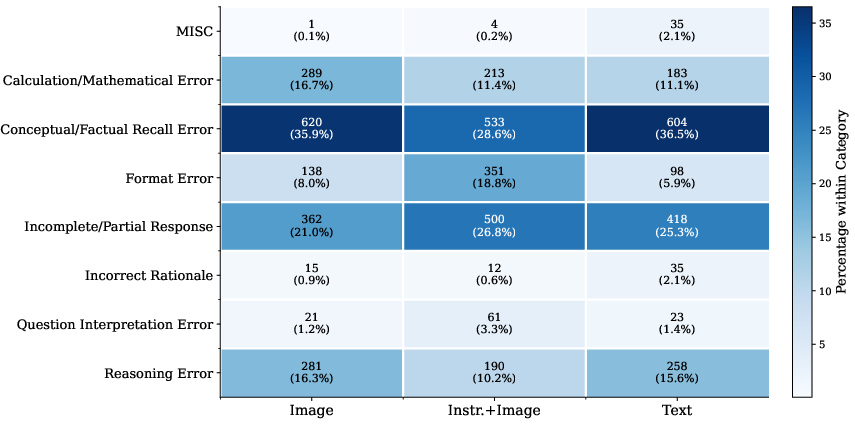
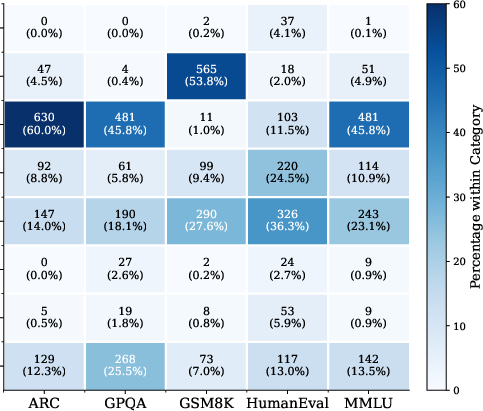
- The main failures are reading errors, not thinking errors.
- When text became images, “reading mistakes” went up: misreading numbers or symbols, and formatting/output mistakes.
- “Knowledge and reasoning” errors stayed about the same.
- Why it matters: the model’s thinking ability is mostly intact. The trouble starts when it must read from pixels.
- Some models stop showing their work with images.
- In image mode, certain models produced much shorter answers and skipped the step-by-step reasoning (“chain‑of‑thought”), jumping straight to final answers—often wrong.
- Why it matters: if the model doesn’t “show its work,” it misses chances to catch and fix reading mistakes.
- OCR helps sometimes but doesn’t fully solve it.
- Doing OCR in two steps (read first, then solve) recovered a lot of math performance, but it broke code generation for many models (because important spacing/formatting got lost).
- Why it matters: turning images back into text is helpful in some tasks, but can throw away subtle structure needed for others (like code).
- A simple training fix closes most of the gap on math.
- Using self‑distillation—training the model on its own step-by-step text answers, paired with the same content as images—boosted image-mode accuracy on GSM8K from about 31% to about 93%, nearly matching typed text.
- This improvement carried over to other tasks without “forgetting” what it already knew.
- Updating just the language part of the model (not only the vision part) was especially effective.
- Why it matters: you don’t need to rebuild the model. With targeted training, the model can learn to read and reason from images almost as well as from text.
What this means going forward
- Better reading from images is within reach. The problem is mostly about perception (reading) rather than intelligence (thinking). Targeted training that encourages “show your work” on images can make a huge difference.
- Test fairly and realistically. Benchmarks should say what fonts, sizes, and resolutions they use, and include real-world document images, not only clean synthetic renderings.
- Design choices matter. If an app shows an AI model screenshots, using clear, common fonts and sufficient resolution will make the model more reliable. For code or math, preserving layout and spacing is crucial.
- Simple training strategies can help many tasks. Self‑distillation is practical: it uses the model’s own good text answers to teach itself to handle images, and it doesn’t wipe out what the model already knows.
- Bigger picture: As AI systems interact more with screens, documents, and photos, helping them “read” robustly will unlock better performance in tutoring, document search, data extraction, and coding assistants that work from screenshots or PDFs.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and can guide future research.
- Generalization of self-distillation:
- Does the proposed self-distillation approach transfer beyond GSM8K to tasks that are formatting- and structure-sensitive (e.g., code generation), knowledge-heavy (e.g., MMLU/GPQA), and natural-document QA (e.g., SQuAD/QASPER)?
- Does it generalize across architectures (e.g., non-Qwen backbones, different ViT variants, unified decoder-only models), model sizes, and proprietary/open-source models?
- CoT (chain-of-thought) collapse:
- What mechanistically causes the CoT suppression in image mode (prompting, decoding configuration, visual-token salience, or encoder–decoder fusion dynamics)?
- Does self-distillation explicitly restore CoT behavior in image mode (e.g., longer step-by-step traces, higher intermediate-step correctness), and under what conditions?
- Can training-free interventions (e.g., “let’s think step by step” prompts, output-format constraints, or decoding strategies) reliably mitigate CoT collapse without fine-tuning?
- Scope of rendering confounds:
- Beyond the four tested styles, how do more diverse typographical factors (kerning, ligatures, hyphenation, italics/bold, small caps, superscripts/subscripts, fraction layouts, bullet/numbered lists, hyperlinks, footnotes) affect performance?
- How do equation-heavy layouts (LaTeX-rendered math, matrices, fractions), code blocks with indentation/whitespace, and specialized math/code fonts impact the modality gap?
- How do real-world visual artifacts (JPEG/WebP compression levels, scanning noise, blur, low contrast, lighting, rotation, cropping, watermarking) change robustness?
- Handwriting and non-Latin scripts:
- The “handwriting” condition used a single handwriting-like font; how do real handwritten samples with human variability influence errors?
- How do models handle other writing systems (right-to-left scripts, CJK, complex scripts), mixed-language pages, and transliteration—both in synthetic and natural images?
- Resolution vs. efficiency trade-offs:
- What are the precise latency, memory, and energy trade-offs across resolutions and tokenization schemes (including image tiling and patch sizes), and how do these compare to text-mode baselines under equal compute budgets?
- Can region-adaptive resolution routing (e.g., ViR-like modules) be generalized or improved to deliver consistent accuracy at lower FLOPs across tasks and models?
- Natural-document setup and confounds:
- For SQuAD and QASPER, how does the placement and modality of the instruction (rendered into the image vs. provided as text) impact results? Can a fully controlled, matched setup remove this confound?
- The QASPER evaluation excluded table/figure-dependent questions; how does the modality gap behave on the full dataset with tables, figures, and complex layouts?
- Multi-page/long-document reading remains underexplored: how do MLLMs perform on multi-image sequences, page navigation, and reading order in natural PDFs/webpages?
- OCR-based diagnostics:
- OCR-2P was omitted on long documents due to cost; what scalable alternatives (chunking, adaptive cropping, learned attention windows) can make two-pass pipelines feasible for long contexts?
- The study used the same MLLM for OCR; would state-of-the-art external OCR or structure-preserving parsers (e.g., code-aware OCR that retains indentation/whitespace) narrow the gap, especially on code tasks?
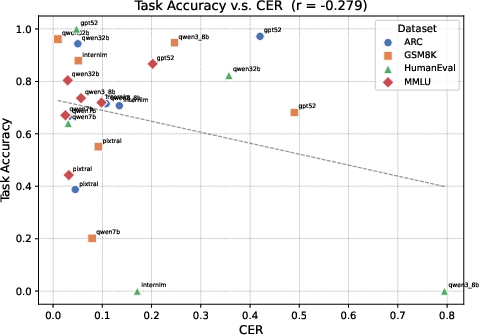
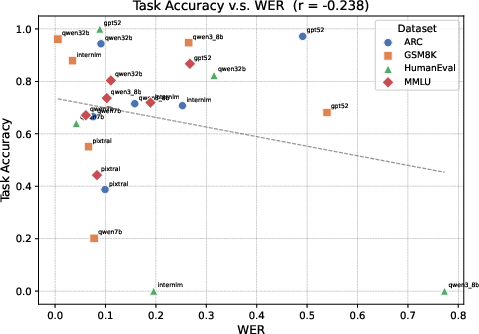
- Aggregate OCR WER correlated weakly with performance; can token-critical metrics (e.g., digits, operators, variable names, punctuation) better predict failures?
- Error taxonomy validity and reproducibility:
- What is the inter-annotator agreement among humans on the taxonomy? How stable are the categories when coded by different LLMs or human coders?
- Are the category distributions statistically robust across sampling seeds, decoding parameters, and prompts? Confidence intervals and significance tests are not reported.
- Mechanistic understanding:
- What are the internal representation differences between text- and image-mode inputs (e.g., attention over visual tokens for numerals/operators, cross-modal alignment quality, positional encoding interactions)?
- Do particular vision-token patterns (e.g., numerals/operators in math, braces/indentation in code) systematically degrade during visual encoding?
- Pretraining distribution mismatch:
- The paper hypothesizes mismatch between synthetic renderings and pretraining data; can this be quantified (e.g., measuring font/layout coverage in pretraining corpora) and corrected via targeted pretraining or data augmentation?
- Which specific rendering features (font families, glyph shapes, density) most strongly mediate mismatch effects, and how much augmentation is needed to eliminate the gap?
- Alternative gap-closing strategies:
- How do other alignment techniques compare to self-distillation (e.g., cross-modal consistency regularization, contrastive learning between text and rendered images, policy distillation of CoT across modalities)?
- Can modular approaches (better visual encoders, improved tokenizers, or layout-aware fusion) close the gap without model-wide fine-tuning?
- Structure- and format-sensitive outputs:
- Why does OCR-2P “destroy” code generation in several models, and can structure-preserving extraction or constrained decoding recover indentation and alignment?
- Can fine-tuning specifically on formatting-critical tasks (code, tabular outputs, strict schemas) reduce format and incomplete-response errors in image mode?
- Evaluation methodology:
- LLM-as-judge was used for QASPER/SQuAD; what is the sensitivity to the choice of judge model, judge prompt, and scoring rubric? Are results consistent across judges and with human assessments?
- Reproducibility details (temperature, seeds, prompt templates) and run-to-run variance are not reported; how stable are the reported gaps across runs?
- Broader robustness and safety:
- How susceptible are models to adversarial or obfuscated renderings (e.g., homoglyphs, font perturbations) that selectively target numerals/operators?
- Do font/style sensitivities pose fairness or accessibility risks (e.g., dyslexia-friendly fonts, high-contrast modes), and can robust training mitigate these disparities?
- Scope of “reading, not thinking” claim:
- The claim is supported by error categories and CoT length on GSM8K; does this pattern hold across more tasks, especially those requiring deep reasoning over visual layouts (e.g., chart/table QA)?
- Can controlled perturbation studies (e.g., minimal token flips in images vs. in text) isolate reading-induced vs. reasoning-induced errors more causally?
- Data and artifact transparency:
- Release of rendering pipelines, fonts, prompts, and evaluation scripts would enable replication and further probing of confounds; are these artifacts available?
- How do different instruction templates and few-shot exemplars impact the modality gap across tasks and models?
Practical Applications
Immediate Applications
Below are actionable applications that can be deployed now, derived from the paper’s findings and methods.
- Rendering-aware evaluation and deployment checklist (industry, academia, policy)
- Use case: Standardize reporting and testing of MLLMs with explicit rendering specs (font, resolution, color scheme) to avoid confounds that can swing accuracy by tens of percentage points.
- Tools/workflows: Evaluation harness that runs each task under Pure Text, Pure Image, Instr.+Image, OCR-1P, OCR-2P; automated ablations over fonts (e.g., NotoSans, monospaced, handwriting-like), resolutions, and compression.
- Assumptions/dependencies: Access to the model’s visual input pipeline; consistent rendering libraries; governance buy-in to include modality reporting in model cards and benchmark papers.
- Screenshot/document QA with natural images (enterprise KM, legal, research; software; healthcare)
- Use case: Build QA over PDFs/webpages using natural screenshots or PDF page images, which often match or exceed text-mode performance (e.g., QASPER).
- Tools/products: “Document QA” microservice that accepts PDF pages/screenshots plus a textual instruction (Instr.+Image) to answer queries; RAG pipelines that index both text and key page images.
- Assumptions/dependencies: Model is pretrained on document-like visuals (as many current MLLMs are); context window adequate for long documents; privacy/PII handling for sensitive PDFs.
- Resolution- and font-aware preprocessing for screenshot ingestion (software, education, developer tools)
- Use case: Improve reliability by enforcing minimum resolution thresholds (avoid sharp drops below ~0.5×), use monospaced fonts for code, and avoid handwriting-like fonts that severely degrade accuracy.
- Tools/workflows: Preprocessors that auto-detect content type (code/math/body text), apply compact 10pt rendering where appropriate, and normalize color schemes; UI/style linting for AI-readability.
- Assumptions/dependencies: Control over rendering pipeline or UI; compatibility with the model’s visual encoder; QA to verify no loss of critical details.
- OCR pipeline design guidance by task (software, coding assistants, math solvers)
- Use case: Prefer OCR-2P to separate reading and reasoning for math/word problems; avoid OCR-2P for code (it destroys indentation/whitespace); use hybrid modes that preserve layout tokens.
- Tools/workflows: Task-aware router that chooses Pure Image, Instr.+Image, OCR-2P, or text mode; structured OCR that preserves whitespace and alignment for code.
- Assumptions/dependencies: High-quality OCR that emits layout/format tokens; routing logic tied to content classification.
- LM-only self-distillation for image-mode robustness (software, finance, healthcare, legal)
- Use case: Quickly close the modality gap by fine-tuning with the paper’s workflow—collect text-mode chain-of-thought (CoT) traces, pair with image inputs, and apply LoRA to the LLM only—raising image-mode accuracy dramatically (e.g., 30.71% → 92.72% on GSM8K) without catastrophic forgetting.
- Tools/products: “Visual CoT Adapter” training kit (scripts to harvest text-mode CoT, render images, and run LM-only LoRA with r≈64); reusable checkpoints per domain.
- Assumptions/dependencies: Model permits finetuning and CoT extraction; compute for brief LoRA training; minimal safety risks from CoT exposure in the deployment context.
- Prompting and output-format controls to counter CoT collapse (education, data entry, math tutoring)
- Use case: Reduce image-mode “reasoning collapse” by enforcing step-by-step outputs and format constraints (e.g., “show intermediate steps,” “final answer in <ans> tags”).
- Tools/workflows: Prompt templates with explicit reasoning scaffolds; validators that reject incomplete/partial outputs; function-calling or schema-enforced outputs.
- Assumptions/dependencies: Models support instruction adherence; guardrails/validators in the serving stack.
- Model selection and procurement guidance for visual text workloads (industry, public sector)
- Use case: Choose modality-robust models (e.g., InternVL3.5-8B, Qwen2.5-VL-7B) for screenshot-heavy use; verify resilience to font/resolution/color variations before deployment.
- Tools/workflows: Modality robustness scorecard; pre-procurement bake-offs across the five input modes on target tasks.
- Assumptions/dependencies: Comparable inference budgets (FLOPs/tokens) across modes; access to representative data.
- Token/computation budgeting for screenshot contexts (software, ops, energy-aware compute)
- Use case: Balance token savings from image contexts against higher FLOPs of vision encoding; prefer compact rendering (e.g., 10pt content bounding box) to recover performance at lower computational cost.
- Tools/workflows: Cost/performance profiler that estimates FLOPs vs. accuracy by resolution; autoscaling policies to adjust resolution per query complexity.
- Assumptions/dependencies: Visibility into model FLOPs; controllable rendering; service-level objectives defined per use case.
- EdTech and automated grading hygiene (education, publishers)
- Use case: For AI-graded assignments, avoid handwriting-like fonts and low-resolution scans; provide typed math/code or high-quality scans to reduce reading/calculation/format errors.
- Tools/workflows: Submission guidelines and pre-checkers for student uploads; auto-normalization of scans prior to grading.
- Assumptions/dependencies: Institutional policies allow AI-assisted grading; students/teachers can follow submission specs.
- Red-teaming for modality abuse and robustness (security, trust & safety)
- Use case: Test systems against adversarial changes in font, resolution, and color to induce errors; build detectors and fallbacks (e.g., re-render or switch modes) when risk signatures appear.
- Tools/workflows: Fuzzers for visual rendering; risk-triggered routing to OCR-2P or text mode; anomaly detection on unusually short outputs indicative of CoT collapse.
- Assumptions/dependencies: Red-team resources; routing infrastructure; acceptance of dynamic modality switching.
Long-Term Applications
The following applications need further research, scaling, or ecosystem development before wide deployment.
- Standardized modality-robust benchmarking and disclosure (policy, academia, standards bodies)
- Use case: Require benchmarks and vendors to report rendering specs, text–image gaps, and modality consistency; include natural document images alongside synthetic ones in evaluations.
- Tools/products: NIST/ISO-style standards; certification suites for “visual text robustness.”
- Assumptions/dependencies: Multi-stakeholder consensus; public datasets with licensing for natural documents.
- Visual CoT objectives and adapters baked into foundation models (software, research)
- Use case: Training-time objectives that preserve chain-of-thought under visual input to prevent reasoning collapse across tasks, not just math.
- Tools/products: Multi-modal CoT distillation at scale, curriculum that mixes text and image presentations.
- Assumptions/dependencies: Access to large-scale CoT data; techniques to avoid overexposure of reasoning traces and maintain safety.
- Handwriting-robust visual text understanding (healthcare, education, logistics, field ops)
- Use case: Close the large gap on handwriting-like inputs (largest degradation in study) to handle clinical notes, classroom notebooks, forms, and labels captured in the wild.
- Tools/products: Pretraining/finetuning with handwritten corpora; augmentation for allographic diversity; layout-aware recognition.
- Assumptions/dependencies: Curated, privacy-compliant handwriting datasets; robust layout models; device capture quality control.
- Structure-preserving OCR and layout tokenization (software, coding, legal/financial analysis)
- Use case: OCR that encodes indentation, whitespace, and alignment as first-class tokens to support code reasoning and tabular/legal document parsing.
- Tools/products: Layout tokenizers, WYSIWYG-aware encoders, Markdown/PDF structural bridges.
- Assumptions/dependencies: Model architectures that exploit structural tokens; co-training with code and document layout tasks.
- Dynamic resolution routers and compute-efficient vision (software, energy, hardware co-design)
- Use case: Adaptive visual processing that preserves accuracy at lower compute (e.g., Visual Resolution Router), with per-task resolution control for energy savings.
- Tools/products: Routers integrated into VLMs; patch-level adaptive sampling; accelerator kernels optimized for multi-scale vision.
- Assumptions/dependencies: Model support for multi-resolution pathways; hardware/runtime support for dynamic compute.
- Screenshot-native desktop/web agents (software automation, IT support, RPA)
- Use case: Agents that robustly read and act on GUIs from screenshots, improving reliability by resisting font/resolution variances and preserving CoT.
- Tools/products: GUI agents with modality-aware perception, self-distillation seeds for enterprise UIs, fallback OCR-2P when needed.
- Assumptions/dependencies: Access to diverse UI screenshots for training; safe action policies; organizational integration.
- AI-readable document standards (publishing, government, legal)
- Use case: An “AI-Readable PDF”/PDF-A++ profile that embeds rendering metadata and ensures fonts/resolutions that MLLMs handle reliably, improving retrieval, QA, and compliance workflows.
- Tools/products: Validators and converters for AI readability; publisher toolchain plugins.
- Assumptions/dependencies: Standards adoption by publishers/agencies; compatibility with archival requirements.
- Regulatory guidance for modality robustness and fairness (policy, compliance)
- Use case: Require vendors to demonstrate robustness across modality and rendering variations; evaluate fairness across typography, scripts, and visual conditions.
- Tools/products: Audit protocols; procurement checklists; risk tiers for image-based reasoning systems.
- Assumptions/dependencies: Policy frameworks for AI evaluations; access to diverse multilingual visual datasets.
- Cross-modal distillation platforms (platforms, MLOps)
- Use case: Managed services that continuously align models’ text and image pathways via self-distillation across domains (finance reports, legal contracts, medical records).
- Tools/products: Data pipelines that auto-harvest text-mode CoT, render training images, and finetune with LM-only or joint adapters; monitoring of text–image gap drift.
- Assumptions/dependencies: Ongoing data access; cost controls for periodic finetuning; governance of CoT artifacts.
- Security hardening against visual adversaries (security)
- Use case: Defenses against font/resolution/contrast-based prompt injections or error-inducing perturbations in screenshots and documents.
- Tools/products: Robust training with adversarial renderings, watermarking of safe fonts, detectors for suspicious visual patterns, policy-driven fallbacks to text-only modes.
- Assumptions/dependencies: Threat intelligence on emerging attacks; safe augmentation strategies; acceptance of accuracy–robustness trade-offs.
- Math/science tutoring from photographed work (education, consumer apps)
- Use case: Reliable reasoning over student-written steps on paper by overcoming reading errors and CoT suppression in image mode.
- Tools/products: Mobile capture with automatic deblurring/denoising, handwriting-robust models, CoT-preserving prompts.
- Assumptions/dependencies: Advances in handwriting robustness and reasoning stabilization; on-device or privacy-preserving processing.
- End-to-end medical/law document understanding from scans (healthcare, legal)
- Use case: High-fidelity reasoning over scanned forms and records without brittle OCR pipelines; better extraction of terms, dates, dosages, and clause logic.
- Tools/products: Domain-adapted self-distilled models; structure-preserving OCR hybrids; validation with human-in-the-loop.
- Assumptions/dependencies: De-identification/privacy compliance; domain-licensed datasets; rigorous validation for safety and liability.
Glossary
- 2D positional embeddings: A technique that encodes two-dimensional position information (e.g., x and y coordinates) to help vision models understand spatial layout. "visual priors alone (2D positional embeddings, canvas augmentation) can achieve competitive performance on ARC"
- Allographic shift: A change in the visual shape or style of characters (allographs) that alters their appearance without changing underlying identity, often challenging recognition models. "introducing a large allographic shift unlikely to appear in standard pretraining corpora"
- Autoregressive LLM decoder: A LLM component that generates outputs token by token, each conditioned on previously generated tokens. "a ViT-based visual encoder converts input images into visual tokens that are fed into an autoregressive LLM decoder"
- Axial coding: In grounded theory, the phase that organizes and relates codes into higher-level categories and relationships. "axial coding, which groups related codes into higher-level categories and maps their relationships"
- Canvas augmentation: A visual augmentation strategy that alters properties of the input canvas (e.g., layout, spacing) to improve model robustness. "visual priors alone (2D positional embeddings, canvas augmentation) can achieve competitive performance on ARC"
- Chain-of-thought (CoT) reasoning: An approach where the model explicitly generates step-by-step intermediate reasoning before an answer. "much less likely to output chain-of-thought (CoT) reasoning on GSM8K in image mode"
- Chain-of-thought reasoning collapse: A failure mode where, under certain inputs (e.g., images), the model stops producing step-by-step reasoning and jumps to (often incorrect) answers. "we also identify a chain-of-thought reasoning collapse under visual input"
- Compositional encoder--LLM architectures: Systems composed of a visual encoder feeding into a separate LLM, forming a two-part multimodal pipeline. "can match compositional encoder--LLM architectures"
- Constant comparison: A grounded-theory method of iteratively comparing new data with existing codes to refine categories. "constant comparison, which refines codes by classifying new data against existing categories"
- Context compression: Reducing the number of tokens (or input length) needed to represent content while retaining essential information. "3--4 context compression via continual pre-training with rendering search"
- Cross-modal consistency: The property that a model gives the same answer regardless of whether input is text or image. "the REST benchmarks to measure cross-modal consistency, i.e., whether models produce the same answer regardless of input modality"
- Distributional mismatch: A discrepancy between the data distributions seen during training and those used during evaluation, which can hurt performance. "suggesting the gap partly reflects distributional mismatch between synthetic renderings and pretraining data"
- FLOPs: Floating-point operations; a measure of computational cost for processing an input. "Even at 25\% of the original resolution, image mode consumes more FLOPs than text mode"
- Grounded theory: An inductive qualitative research methodology that derives theories from data via systematic coding. "Grounded theory is an inductive qualitative research method that derives a theoretical framework directly from data rather than testing pre-existing hypotheses"
- Information-seeking benchmarks: Evaluations that assess a model’s ability to retrieve and use information to answer questions. "Following recent information-seeking benchmarks~\cite{wei2025browsecompsimplechallengingbenchmark, pham2025sealqaraisingbarreasoning}, we adopt an LLM-as-judge protocol"
- LLM-as-judge protocol: An evaluation method where a LLM assesses the correctness of another model’s answers. "we adopt an LLM-as-judge protocol, where we use GPT-5 (gpt-5-2025-08-07) to compare the model prediction with the gold answer and report accuracy"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects low-rank adapters into model layers. "All experiments use LoRA~\citep{hu2022lora} with rank "
- Masked patch prediction: A pretraining objective for vision models where patches of an image are masked and the model learns to predict them. "train vision transformers on rendered text with masked patch prediction"
- Modality gap: The performance difference when identical content is presented in different modalities (e.g., text vs. image). "We systematically diagnose this ``modality gap'' by evaluating seven MLLMs across seven benchmarks"
- Modality robustness: A model’s ability to maintain performance across different input modalities. "InternVL3.5-8B is the most modality-robust model, maintaining near-zero or positive differences on nearly all benchmarks"
- OCR-1P: A one-pass setting where the model is prompted to extract text from an image and solve the task in a single inference. "OCR-1P (one pass)."
- OCR-2P: A two-pass setting where text is first extracted from the image, then the model solves the task from the extracted text. "OCR-2P (two passes)."
- pass@k: A code-generation evaluation metric: the probability that at least one of k sampled outputs is correct. "using pass@k for HumanEval"
- Screenshot LLMs: Vision-LLMs trained directly on screenshots or rendered text images. "Screenshot LLMs~\citep{rust2023language, gao2024improvinglanguageunderstandingscreenshots} train vision transformers on rendered text with masked patch prediction"
- Self-distillation: Training a model using its own outputs as supervision, often to transfer knowledge across settings or modalities. "we propose a self-distillation method that trains the model on its own pure text reasoning traces paired with image inputs"
- Span-based F1: An evaluation metric for extractive QA that measures overlap between predicted and gold answer spans. "Results using span-based F1 are provided in the appendix"
- Unified multimodal architectures: Models that handle multiple modalities within a unified framework rather than separate encoders/decoders. "and unified multimodal architectures~\citep{wang2026emu3}"
- Visual Resolution Router (ViR): A component that adapts processing to different image resolutions to improve robustness. "InternVL3.5, the only model with a Visual Resolution Router (ViR)~\cite{wang2025internvl3}, is remarkably resolution-invariant"
- Vision-centric tokenization: Encoding approaches that render text as images to reduce token counts and increase efficiency. "vision-centric tokenization methods render text as images to reduce token counts"
- Vision Transformer (ViT): A transformer architecture for images that operates on sequences of image patches. "a ViT-based visual encoder converts input images into visual tokens"
- Visual pipeline: The sequence of processing steps that transform raw images into representations for reasoning. "Two OCR-based modes decompose the visual pipeline into reading and reasoning stages"
- Visual tokens: Token-like representations produced from images by a vision encoder for input to a LLM. "converts input images into visual tokens"
- Word error rate (WER): A metric for recognition quality measuring errors relative to the number of words. "we compute the correlation between OCR-2P word error rate and Pure Image accuracy"
Collections
Sign up for free to add this paper to one or more collections.

