- The paper introduces DEO, a training-free method that decomposes queries using LLMs and applies contrastive embedding optimization to handle negation in retrieval.
- It avoids full-model retraining by optimizing query embeddings at inference, significantly boosting MAP and nDCG performance metrics.
- The framework is robust across modalities, demonstrating efficiency and applicability in both text retrieval and vision-language tasks.
Training-Free Negation-Aware Retrieval via Direct Embedding Optimization
Introduction
Negation and exclusion are prevalent in real-world information retrieval scenarios, posing significant challenges for dense retrievers that rely solely on pre-trained or fine-tuned embedding spaces. Most prior approaches attempt to adapt to this challenge through full-model fine-tuning or embedding adaptation, resulting in substantial computational overhead, the need for large auxiliary datasets, or limited generalization. The "DEO: Training-Free Direct Embedding Optimization for Negation-Aware Retrieval" (2603.09185) paper proposes a training-free, model-agnostic framework—Direct Embedding Optimization (DEO)—that addresses the retrieval of negation and exclusion queries by combining LLM-based query decomposition with contrastive embedding optimization. This approach avoids model updates and additional data, providing substantial advantages in deployment efficiency and controllability.
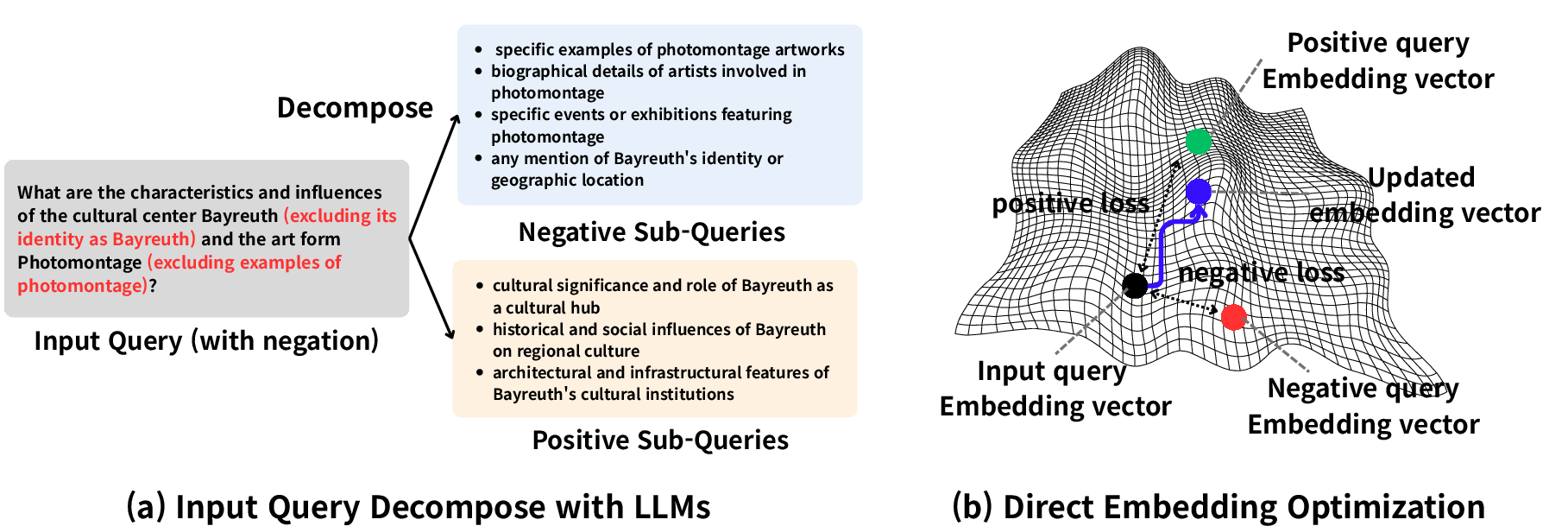
Figure 1: Overview of the DEO framework: (a) LLM-driven decomposition of queries into positive and negative sub-queries. (b) Query embedding is optimized with a contrastive objective for negation-aware retrieval.
Methodology
DEO leverages LLMs for prompt-based semantic decomposition of user queries, separating inclusionary (positive) and exclusionary (negative) intent. This results in two structured sets of sub-queries, each capturing distinct aspects of user intent. Unlike prior methods that retrain embeddings or employ auxiliary adaptors, DEO performs inference-time, per-query optimization of the query's embedding in the representation space of a frozen encoder.
Let q be the input query with original embedding eo=E(q) (for encoder E), and let P={pi}i=1K, N={nj}j=1M be the positive and negative sub-queries and their embeddings, respectively. A learnable embedding eu is initialized to eo and optimized via gradient descent over the following loss:
L(eu)=λp⋅K1i∑∥eu−epi∥2−λn⋅M1j∑∥eu−enj∥2+λo⋅∥eu−eo∥2
where λp,λn,λo control attraction to positives, repulsion from negatives, and regularization toward the original query embedding, respectively. Optimization (typically 20–50 steps) is performed at inference, keeping E frozen. The resulting eu yields a negation- and exclusion-aware retrieval representation.
This approach is entirely training-free: it does not require labeled data, model retraining, or additional external resources; it depends only on the frozen encoder and an LLM for decomposition.
Experimental Results
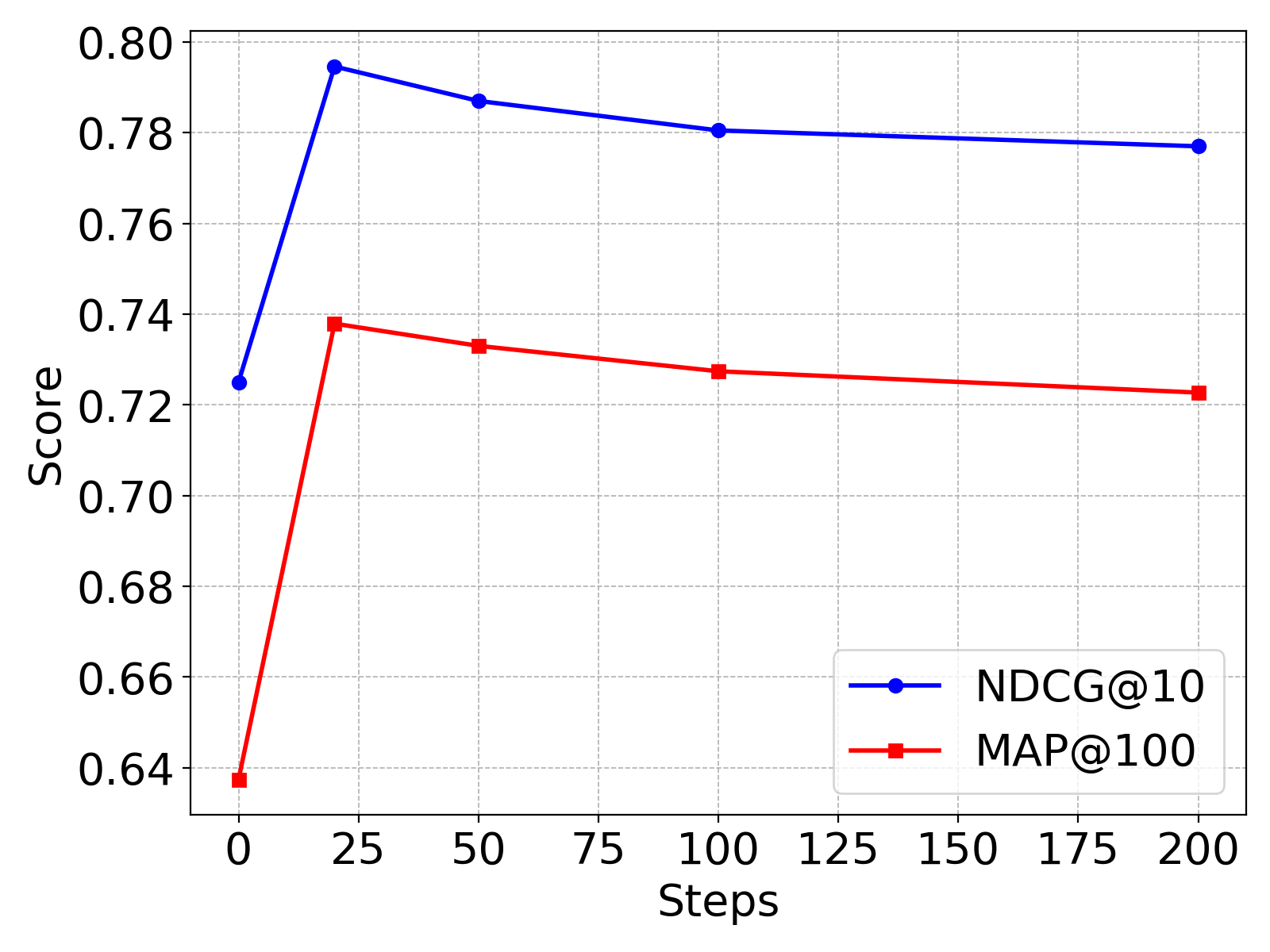
Figure 2: Retrieval performance (nDCG@10, MAP@100) vs. number of optimization steps on NegConstraint.
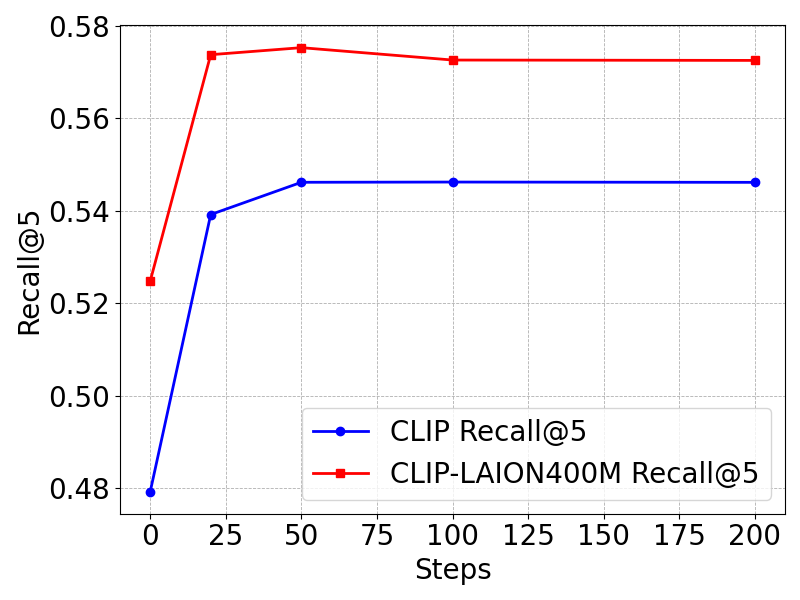
Figure 3: Retrieval performance (Recall@5) vs. optimization steps on COCO-Neg (text-to-image retrieval).
On the NegConstraint benchmark for negation-intensive text retrieval, DEO provides clear gains with BGE-large-en-v1.5: MAP increases from 0.6299 to 0.7327 and nDCG@10 from 0.7139 to 0.7877—representing +0.1028 MAP and +0.0738 nDCG@10 improvements. Performance is robust across multiple embedding models (BGE-small, BGE-M3), with consistent lifts in pairwise negation discrimination on the NevIR dataset. When applied to CLIP-based models for text-to-image retrieval (COCO-Neg), DEO improves Recall@5 by up to 6% (e.g., 0.4792 → 0.5392 on OpenAI CLIP; 0.6715 → 0.6980 on NegCLIP).
Ablation studies confirm:
- LLM decomposition quality is significant: Larger LLMs (GPT-4.1-nano) yield better decompositions and retrieval.
- Query decomposition is insufficient: While decomposition alone helps, most performance gains derive from direct embedding optimization.
- DEO is robust to hyperparameters: Retrieval benefits persist across a variety of λ settings, with the best configuration for text retrieval at λo=0.2; for vision-language settings, higher λo is necessary to retain alignment in multimodal spaces.
- Optimization steps: 20–50 steps suffice; excessive optimization leads to performance decline due to overfitting.

Figure 4: Example LLM-driven query decomposition: positives (desired elements) and negatives (excluded elements) for both text and multimodal retrieval tasks.
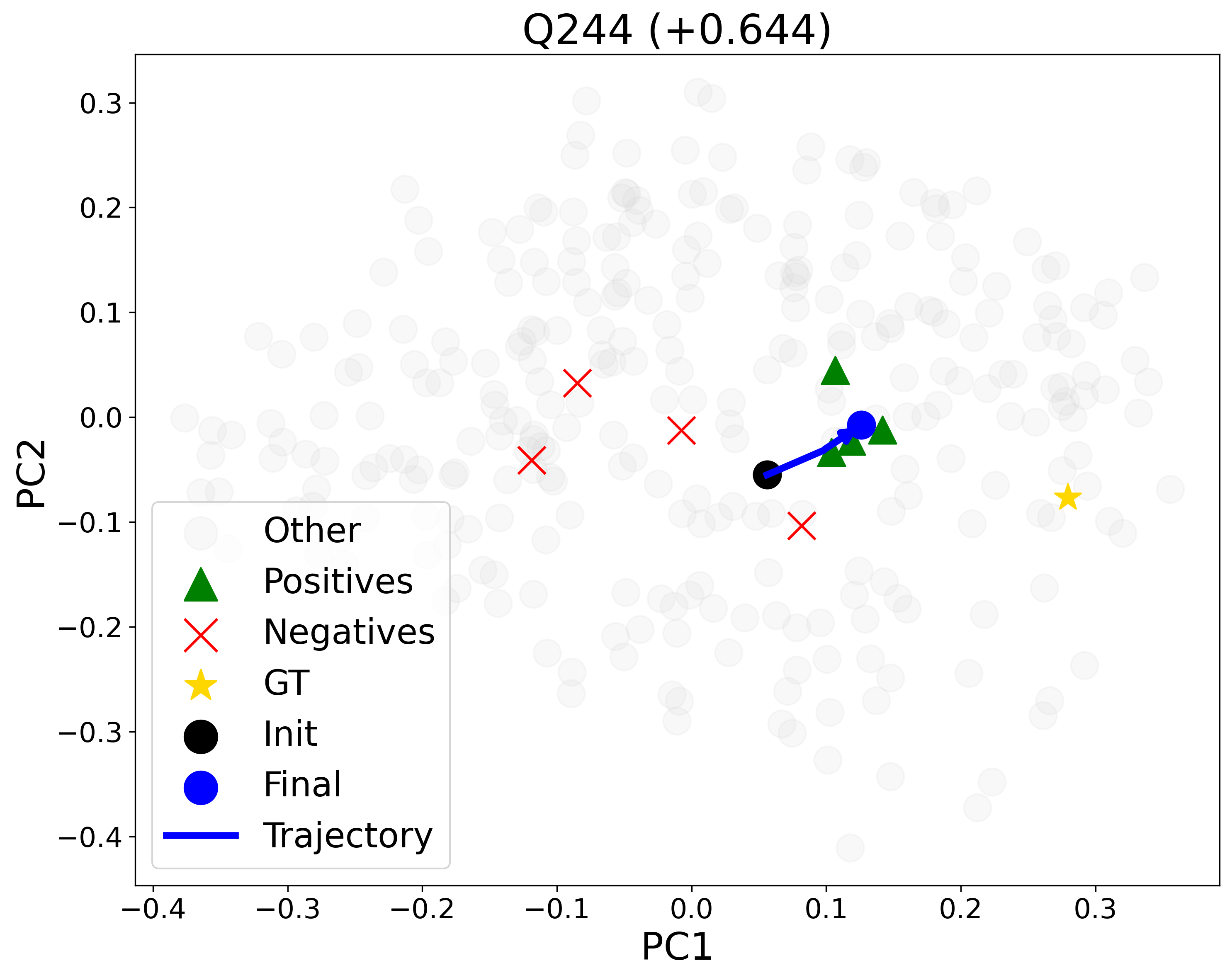
Figure 5: PCA-projected query embedding trajectory: optimized embedding (black to blue) moves toward positives/ground-truth (green/yellow) and away from negatives (red).
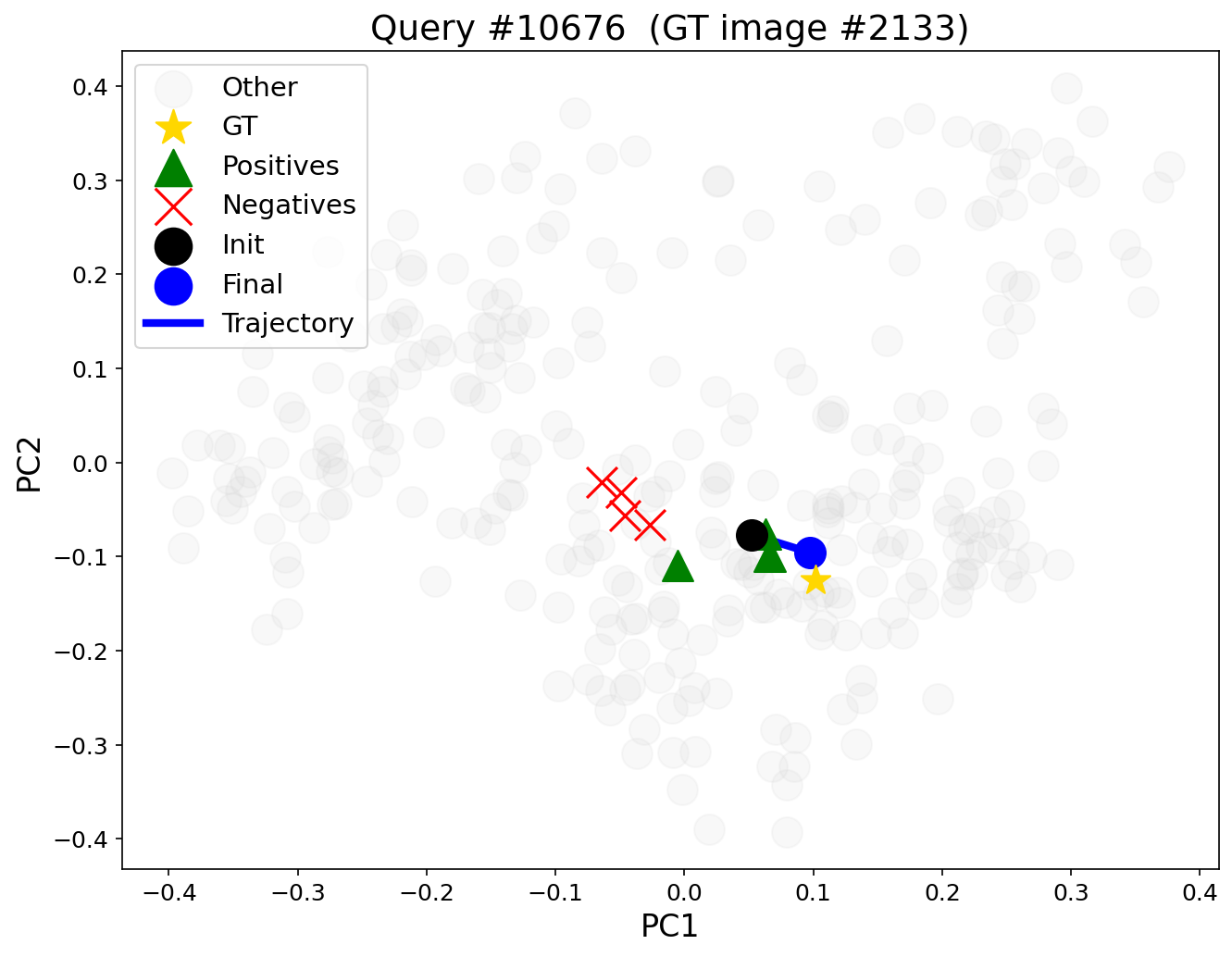
Figure 6: Query embedding trajectory in CLIP space for text-to-image negated retrieval—movement toward desired target and away from negated semantics.
Embedding Space Analysis
DEO's contrastive optimization results in systematic, interpretable reconfiguration of the query embedding in the corpus representation space. PCA visualizations show the optimized query drifting toward ground-truth and positive sub-queries, while repelled from negatives, allowing suppressed ranking of excluded concepts. Notably, ground-truth documents can move from outside the top-5 or beyond rank 30 into the top positions after optimization, substantially boosting ranking metrics (e.g., NDCG@10 improvements of +0.63 in representative queries).
This effect is consistently observed in both text and vision-language embedding spaces, confirming DEO's modality-agnostic applicability.
Practical and Theoretical Implications
Practically, DEO offers a lightweight, resource-efficient means to enable negation- and exclusion-aware retrieval for both unimodal and multimodal settings. Its training-free nature directly addresses deployment challenges in environments with limited compute resources or stringent latency requirements, where full retraining or fine-tuning is infeasible or undesirable. The efficiency of inference-time embedding optimization (<0.02s per query on CPU for 20 steps) ensures its suitability for real-world, interactive retrieval systems.
Theoretically, DEO challenges the common paradigm of retriever adaptation via supervised learning, demonstrating that explicit decomposition of semantic components and isolated optimization of query embeddings can overcome core semantic deficits—such as negation insensitivity—without model retraining. The framework also suggests promising directions for structured, compositional query representations and dynamic, context-sensitive embedding adaptation using learned or prompt-driven semantic operations, with potentially broad applicability outside of negation handling.
Limitations and Future Directions
A key limitation of DEO is its dependence on LLM quality for accurate, faithful query decomposition. Poor negative/positive query generation introduces failure modes for downstream retrieval. Reliance on prompt engineering and access to high-quality LLMs may also impact consistency across domains and languages. In future developments, incorporating uncertainty estimation, incorporating LLM output calibration, or automating loss balancing per-query could further enhance robustness. Extending DEO to retrieval involving more complex modalities (e.g., audio, video) or integrating with large-scale, production RAG systems is a promising avenue for further research.
Conclusion
DEO presents a simple yet effective paradigm for addressing negation- and exclusion-aware retrieval. By decomposing queries and optimizing embeddings at inference via a contrastive objective, it provides strong, consistent improvements over established baselines in both text and multimodal settings—without retraining or fine-tuning. The method is robust, computationally efficient, and broadly applicable, offering a compelling alternative for enhancing semantic controllability and intent alignment in modern retrieval systems.