Reward Prediction with Factorized World States
Abstract: Agents must infer action outcomes and select actions that maximize a reward signal indicating how close the goal is to being reached. Supervised learning of reward models could introduce biases inherent to training data, limiting generalization to novel goals and environments. In this paper, we investigate whether well-defined world state representations alone can enable accurate reward prediction across domains. To address this, we introduce StateFactory, a factorized representation method that transforms unstructured observations into a hierarchical object-attribute structure using LLMs. This structured representation allows rewards to be estimated naturally as the semantic similarity between the current state and the goal state under hierarchical constraint. Overall, the compact representation structure induced by StateFactory enables strong reward generalization capabilities. We evaluate on RewardPrediction, a new benchmark dataset spanning five diverse domains and comprising 2,454 unique action-observation trajectories with step-wise ground-truth rewards. Our method shows promising zero-shot results against both VLWM-critic and LLM-as-a-Judge reward models, achieving 60% and 8% lower EPIC distance, respectively. Furthermore, this superior reward quality successfully translates into improved agent planning performance, yielding success rate gains of +21.64% on AlfWorld and +12.40% on ScienceWorld over reactive system-1 policies and enhancing system-2 agent planning. Project Page: https://statefactory.github.io
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explain Like I’m 14: “Reward Prediction with Factorized World States”
What is this paper about?
This paper is about teaching computer agents (like smart robots or web-browsing helpers) to tell how close they are to finishing a task at every step—without needing lots of practice or human scoring. The authors build a new way, called StateFactory, to “understand” the world as neat, structured pieces and then use that understanding to score progress toward a goal.
What questions are the researchers asking?
The paper asks:
- Can an agent predict how close it is to finishing a goal (its “reward”) just by understanding the world clearly, instead of learning from tons of examples?
- Will this work across very different tasks and environments—without any extra training?
- If the progress scores are better, do agents actually plan and act better, too?
How did they try to solve it?
The authors introduce StateFactory, which is like organizing a messy room into labeled boxes so you can find things fast.
- In many tasks, agents read text descriptions of what they see and what they do (like “pick up the mug,” “open the cabinet”). That text is messy and long.
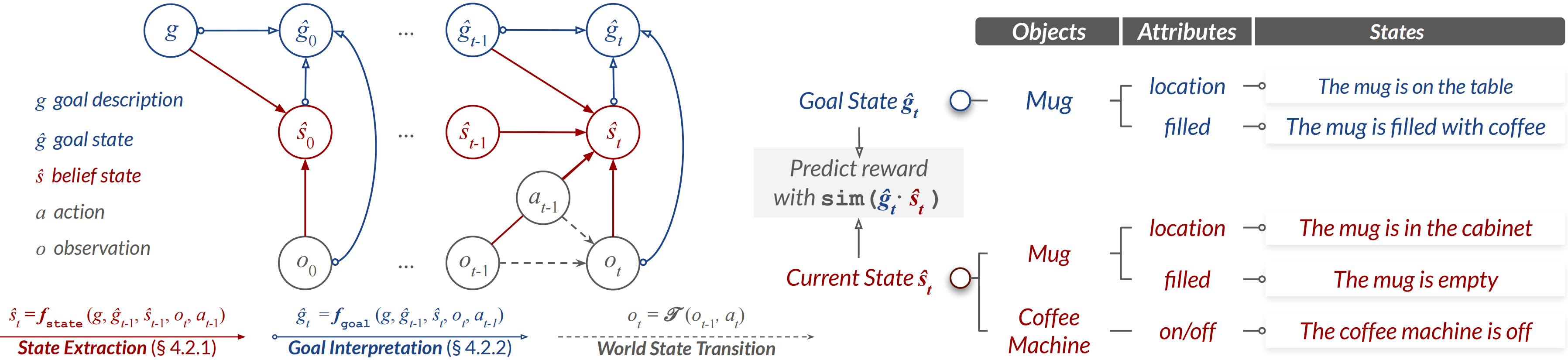
- StateFactory turns this mess into a tidy checklist of objects and their properties, for example:
- Object: “mug”
- Attributes: “color: blue,” “location: on the table,” “temperature: hot”
- It does this step-by-step using a LLM (an AI that understands text). It keeps updating the world state (what’s true right now) and the goal state (what we want to be true) as things change.
- To score progress, it compares the current state to the goal state. Think of it like comparing your Lego build-in-progress to the picture on the box: the closer the match, the higher the score.
In simple terms:
- “Factorized world states” means breaking the world into parts (objects) and details (attributes) instead of keeping one big blob of text.
- “Zero-shot” means it works on new tasks without extra training.
- “Reward” is just the progress score, from 0 (not close) to 1 (goal done).
Where did they test it?
They built a new benchmark called RewardPrediction with 2,454 step-by-step task runs across five very different text-based environments:
- AlfWorld (household robot tasks like “heat a mug, then put it in a cabinet”)
- ScienceWorld (hands-on science experiments with multi-step cause-and-effect)
- TextWorld (text-adventure puzzles with keys, safes, and objects)
- WebShop (finding and buying products on a website with specific features)
- BlocksWorld (stacking and moving blocks to match a target arrangement)
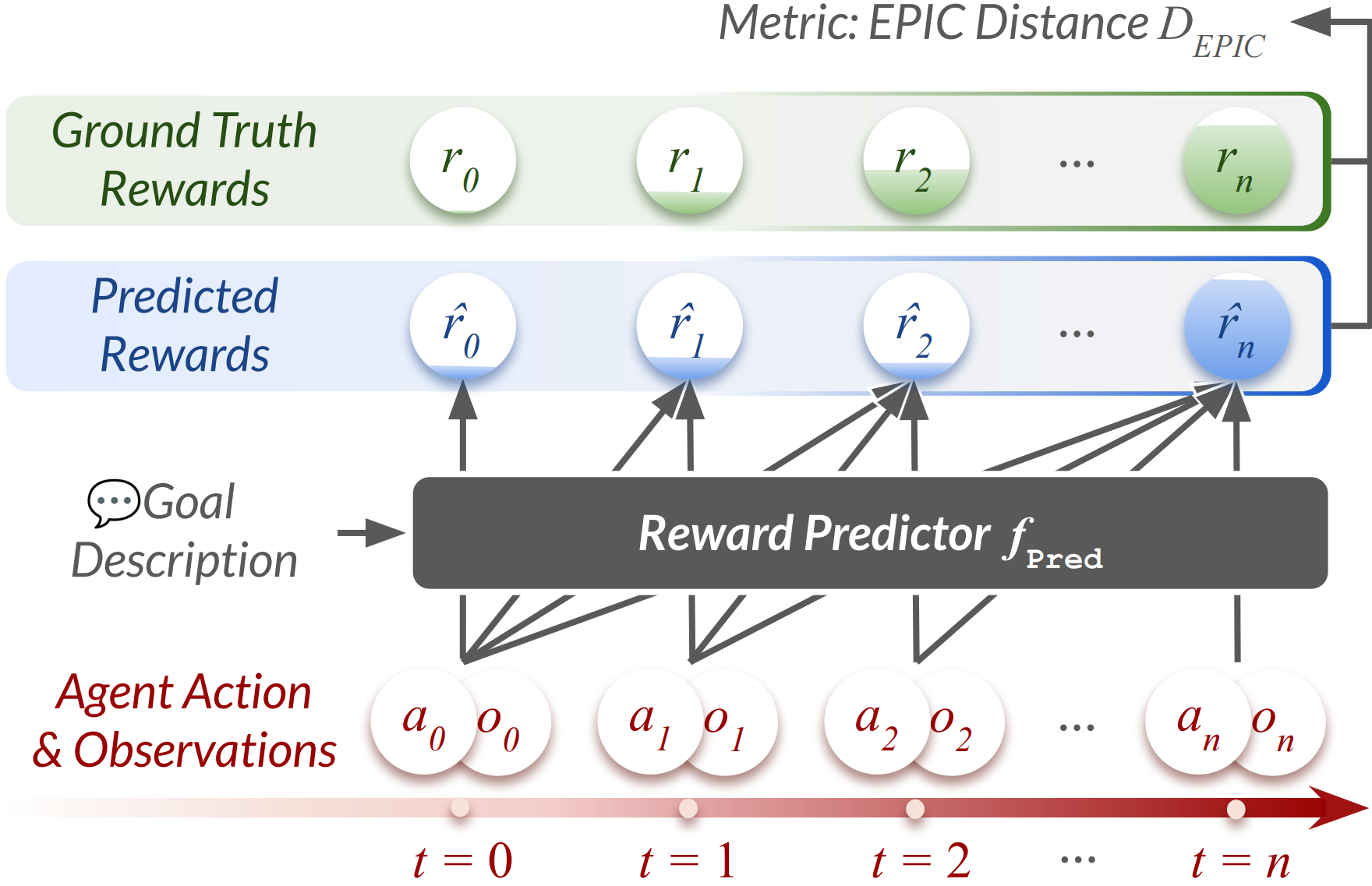
They judged how well predicted progress matches the true progress using a metric called EPIC distance. You can think of EPIC as “how different are your predicted scores from the real scores” (lower is better).
What did they find?
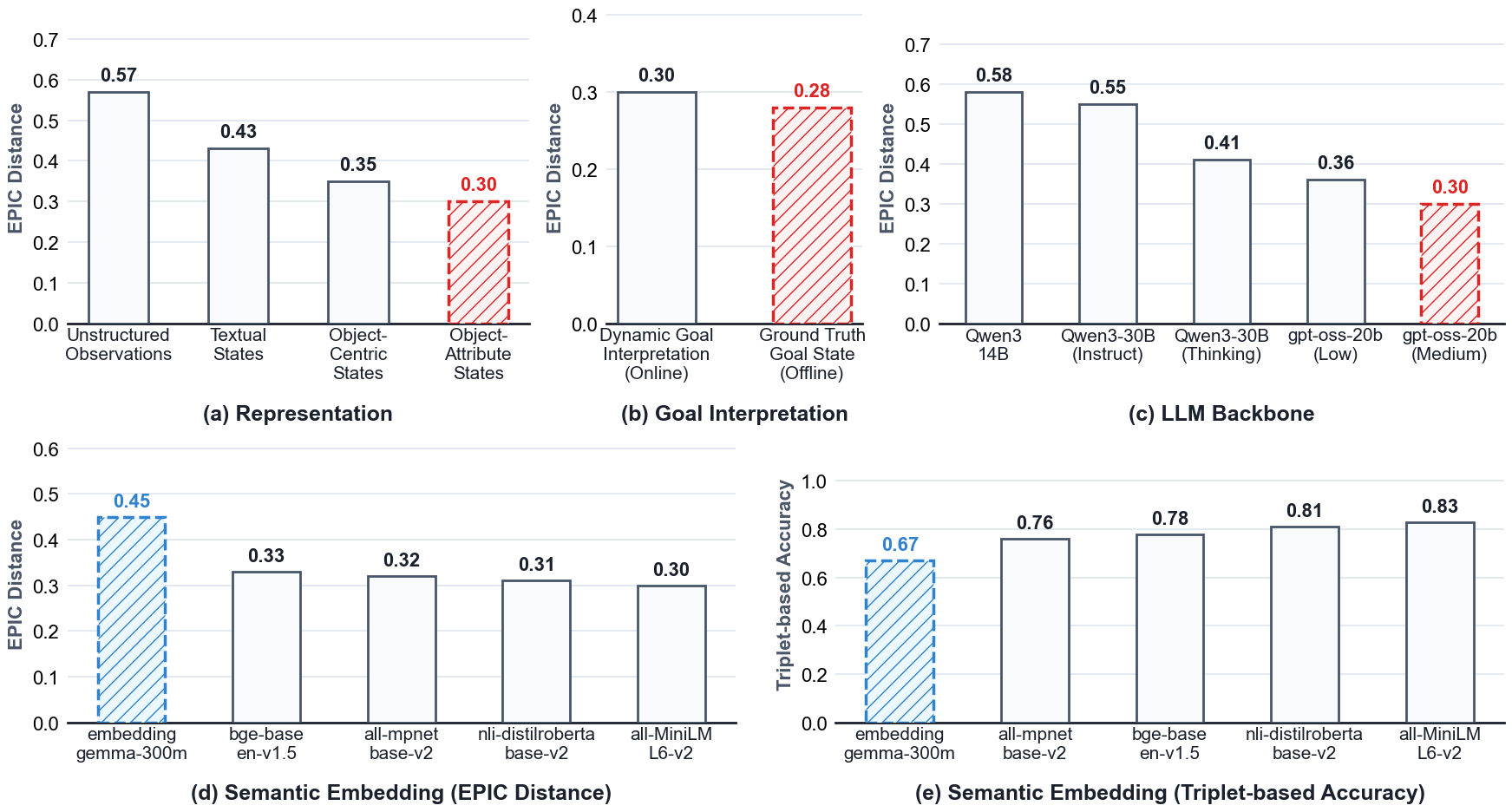
- StateFactory gave better progress scores, even without training on those tasks:
- About 60% lower EPIC distance than a vision-language critic baseline.
- About 8% lower than a strong “LLM-as-a-judge” approach (where a LLM just guesses a score from the text).
- Models trained specifically on one domain often “overfit” (they do great where they trained but stumble elsewhere). StateFactory generalized better because it relies on clear world understanding instead of memorizing patterns.
- Better progress scores led to better planning:
- AlfWorld success rate improved by about +21.6 percentage points.
- ScienceWorld improved by about +12.4 percentage points.
They also showed:
- Breaking states into object + attribute pieces (rather than just objects or raw text) matters a lot for accuracy.
- Continuously updating the goal interpretation as the agent proceeds avoids “fake progress.”
- Using better LLMs and better text embeddings (for comparing meanings) improves results further.
Why is this important?
- Many real tasks don’t give easy feedback or rewards at every step. If an agent can “self-score” by comparing what’s true now to what the goal says should be true, it can plan smarter without lots of trial-and-error.
- A clean, structured view of the world (objects and their attributes) helps agents understand changes and measure progress consistently across different environments.
- This approach could make future assistants—whether in homes, labs, or on the web—more reliable and adaptable without needing tons of new training.
Bottom line
The paper shows that clear, structured understanding of the world (StateFactory) helps agents predict how close they are to success, even on new tasks. Those better predictions lead to better decisions and higher success rates. It’s a step toward building smarter, more flexible agents that can plan and act well with minimal extra training.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up research.
- Dependence on large LLMs for state extraction and goal interpretation: no analysis of latency, token cost, memory footprint, or throughput under realistic online planning budgets (especially for search-based planning with many rollouts).
- Lack of uncertainty modeling: state and goal representations are point estimates; no confidence scores, belief-state distributions, or mechanisms to propagate/manage uncertainty under partial observability (POMDP) or to defer decisions when confidence is low.
- Error accumulation and recovery: the recurrent state updater has no explicit mechanisms for detecting, correcting, or backtracking from extraction errors; robustness to injected noise, hallucinations, and contradictory observations is untested.
- Ontology/schema gaps: there is no canonical, cross-domain object–attribute schema, unit normalization, or ontology alignment; open issues include synonym/alias handling, unit conversion (e.g., Fahrenheit vs Celsius), and normalization of categorical/numeric attribute values.
- Identity and coreference tracking: handling ambiguous references, multiple instances of the same type, anaphora (e.g., “it”), object creation/destruction, and long-term identity persistence is not evaluated or formalized.
- Relational and temporal constraints: averaging attribute-level similarities cannot express inter-object relations (e.g., “inside/next to”), global constraints, or temporal ordering; no support for temporal logic goals, causality, or irreversible action costs.
- Matching algorithm suboptimality: object matching uses a greedy per-goal-object maximum; no global bipartite assignment with constraints (e.g., uniqueness, many-to-many, relational consistency), which can fail with duplicate or similar objects.
- Similarity metric design: rewards rely on off-the-shelf text embeddings and cosine similarity without learning/calibration; sensitivity to embedding drift across domains, alignment with grounded semantics, and calibration to a goal-conditional [0, 1] scale remain open.
- Reward-shaping and optimality: no theoretical analysis of when semantic-similarity–based rewards preserve the optimal policy or approximate the true distance-to-goal; conditions for safe shaping are unspecified.
- Calibration across tasks/goals: uniform averaging over goal objects/attributes can misweight critical subgoals; no goal-conditional weighting, learned importance, or calibration to compare reward magnitudes across tasks for shared planning heuristics.
- Negations, constraints, and prohibitions: the framework does not natively handle goals like “do not X,” soft constraints, safety constraints, or conditional goals (if-then), which require constraint-aware or logical reward models.
- Long-horizon robustness: no analysis of performance as horizon length grows (state drift, memory limits, compounding errors) or of strategies like summarization, pruning, or periodic consistency checks.
- Benchmark realism and difficulty: positive trajectories assume linear progress (r_t = t/T), which may not reflect non-monotonic real progress; negatives are all-zero random failures—hard negatives (near-misses, regressions, detours) are missing and could change conclusions.
- Metric validity: EPIC (Pearson-based) is the sole metric; no assessment of how well EPIC correlates with human judgments or downstream planning success across domains; alternative policy-invariant or calibration-sensitive metrics are not explored.
- Distributional robustness: evaluation is limited to five text-based environments; generalization to multilingual settings, noisy/colloquial language, domain shifts in style or vocabulary, and out-of-distribution tasks is untested.
- Multimodal extension: the approach has not been validated on vision or vision–language environments where object–attribute extraction and grounding are more challenging (e.g., occlusions, visual ambiguity).
- Adversarial robustness and reward hacking: no tests for agents gaming the representation (e.g., steering the extractor/goal interpreter toward high similarity without true progress) or for adversarial prompt attacks.
- Computational scalability: complexity of object–attribute extraction and matching is not analyzed with respect to the number of entities/attributes; no reported runtime scaling curves or optimizations (e.g., caching, approximate nearest neighbors, pruning).
- Reproducibility of LLM components: reliance on specific “thinking” modes and model variants raises reproducibility concerns; prompts, decoding settings, seeds, and model drift across versions are not systematically controlled or released.
- Symbolic integration: the paper discusses PDDL grounding but does not systematically integrate the factorized states with symbolic planners or bidirectional conversions (symbolic <-> natural language) with guarantees.
- Comparative baselines for structure learning: there is no comparison to trainable structured extractors/parsers (e.g., neural semantic parsers, constrained IE systems) that might offer better efficiency, determinism, or robustness than LLM prompting.
- Comprehensive planning evaluation: planning gains are shown for three domains (ReAct, plus one MCTS case study); evaluations are missing for WebShop and TextWorld, and a systematic correlation between reward accuracy (e.g., EPIC) and success rate is not reported.
- Continual and dynamic goals: handling mid-trajectory goal changes, multi-goal sequences, and reconciliation of conflicting goals/subgoals is not addressed.
- Theoretical understanding of factorization: no analysis of how representation granularity (object vs object–attribute vs relational) impacts generalization, sample complexity, or error bounds in reward prediction and planning.
Practical Applications
Below are practical, real-world applications that follow from the paper’s findings and methods (StateFactory and the RewardPrediction benchmark). Each item includes example sectors, likely tools/products/workflows, and key assumptions or dependencies.
Immediate Applications
- Software/web automation (software, e-commerce, customer support)
- Use case: Web agents that reliably complete multi-step tasks (e.g., shopping, booking, form-filling) by tracking page state as object–attribute graphs and scoring progress toward goals to rank/choose actions.
- Potential tools/products/workflows:
- “StateFactory for Web” library that converts DOM/text into object–attribute state graphs and computes semantic goal similarity.
- ReAct + StateFactory or MCTS + StateFactory agent stacks for higher success rates in web navigation.
- Plug-ins for browser automation frameworks (e.g., Playwright/Selenium) that expose a reward API for action ranking.
- Assumptions/dependencies:
- Accurate text extraction from UIs/DOM; stable mapping from UI elements to semantic objects/attributes.
- Quality of embeddings and LLM “thinking” modes directly affects reward fidelity and stability.
- Acceptable latency and cost for real-time inference.
- Enterprise RPA and workflow orchestration (software, finance, operations)
- Use case: Monitoring and guiding bots through multi-application SOPs using dense, zero-shot progress signals instead of brittle, hand-crafted rules.
- Potential tools/products/workflows:
- Reward plug-in for RPA suites to evaluate step-wise completion, prioritize next actions, or flag stalled flows.
- SOP-to-goal interpreters that auto-generate object–attribute targets from textual procedures.
- Assumptions/dependencies:
- Access/connectors to enterprise apps and logs; robust text grounding for app states.
- Privacy/PII/compliance handling for logs and LLM usage.
- E-commerce assistants and product discovery (retail, marketing)
- Use case: Assistants that track how well a candidate product matches a multi-attribute query (e.g., color, size, price) and guide narrowing/buy decisions with a smooth progress score.
- Potential tools/products/workflows:
- Semantic attribute extractors for product pages; “match-to-goal” reward API for ranking search/browse steps.
- Assumptions/dependencies:
- Reliable product attribute extraction (structured or via LLM); high-quality embeddings for fine-grained attribute similarity.
- Text-based simulation and robotics training environments (robotics, education)
- Use case: Improved instruction-following in simulated environments (e.g., AlfWorld, BlocksWorld, TextWorld) using StateFactory to provide dense rewards without per-task reward engineering.
- Potential tools/products/workflows:
- Drop-in reward module for existing simulated environments; curriculum design based on RewardPrediction.
- Assumptions/dependencies:
- Text-based or reliably text-grounded observations; domain coverage similar to benchmark domains.
- Intelligent tutoring and automated feedback (education)
- Use case: Tutors that decompose learning goals into object–attribute targets (concepts, steps, correctness states) and provide step-wise, rubric-aligned feedback.
- Potential tools/products/workflows:
- Rubric-to-goal interpreters; “progress-to-goal” scoring for problem-solving traces.
- Assumptions/dependencies:
- Domain ontologies to stabilize object/attribute schemas; human oversight to prevent misleading feedback.
- Research and benchmarking for reward models (academia, toolmakers)
- Use case: Evaluating and comparing reward models with EPIC distance using the RewardPrediction dataset; ablations on representation granularity or embeddings.
- Potential tools/products/workflows:
- Open benchmark harness with EPIC calculators; baseline implementations of StateFactory vs. LLM-as-a-Judge vs. supervised critics.
- Assumptions/dependencies:
- Correct EPIC implementation and consistent trajectory formatting; clarity on domain splits for fair generalization tests.
- Agent safety and evaluation (policy, alignment, QA)
- Use case: Auditing agent reward quality and progress estimates to reduce reward hacking risks; establishing invariance checks across tasks/domains.
- Potential tools/products/workflows:
- Reward auditing dashboards that visualize EPIC distance and step-wise reward trajectories; scenario suites for stress-testing.
- Assumptions/dependencies:
- Availability of ground-truth or reference trajectories; standardization of schemas for comparability across domains.
- Personal productivity and task management (daily life, prosumer software)
- Use case: Assistants that track checklist-style goals (e.g., trip planning, home projects) with object–attribute states (who/what/where/status) and provide dense progress feedback.
- Potential tools/products/workflows:
- “Goal-to-state” trackers integrated into task apps; semantic progress bars that reflect precise sub-goal satisfaction.
- Assumptions/dependencies:
- Users’ tasks can be described reliably in text; minimal hallucination in state extraction; acceptable latency/cost on consumer devices.
Long-Term Applications
- Real-world robotics with multimodal perception (robotics, smart homes, manufacturing)
- Use case: Household or industrial robots that translate goals into structured state targets and compute dense progress from perceptual streams (vision/audio) to guide planning and RL without hand-engineered rewards.
- Potential tools/products/workflows:
- Multimodal StateFactory (vision–language) to convert scene graphs into object–attribute states; reward heads for model-based RL and MCTS.
- Assumptions/dependencies:
- Robust grounding from sensors to text/graphs; safety and real-time constraints; domain-specific schemas (e.g., household vs. factory).
- Universal desktop/OS agents (software, productivity)
- Use case: Cross-application agents that track GUI objects (windows, buttons, files) and attributes (state, permissions) to plan and execute multi-step goals on a desktop/enterprise OS.
- Potential tools/products/workflows:
- OS-level “state graph” services; reward and planning APIs integrated into agent frameworks; permission-aware goal interpreters.
- Assumptions/dependencies:
- Stable GUI-to-semantics mapping; security and privacy controls; low-latency inference and caching.
- Clinical workflow and decision support (healthcare)
- Use case: Agents that monitor progress toward care plans (e.g., workups, pre-op checklists) with step-wise, interpretable reward signals; training simulators with dense progress feedback.
- Potential tools/products/workflows:
- EHR-to-state adapters; policy-compliant goal interpreters for clinical guidelines; supervisory review tools for reward traces.
- Assumptions/dependencies:
- Strict safety, validation, and regulatory approvals; bias control; domain-specific ontologies and high-precision extraction.
- Scientific and lab automation (education, R&D, biotech)
- Use case: Autonomous lab agents that plan experiments, track instrument/object states, and evaluate progress toward experimental goals with dense, interpretable rewards.
- Potential tools/products/workflows:
- Instrument log parsers to state graphs; goal interpreters from protocols; MCTS or model-based RL powered by dense rewards.
- Assumptions/dependencies:
- High-fidelity logging and grounding; lab safety and approval processes; integration with LIMS/ELN systems.
- Financial compliance and back-office operations (finance, enterprise ops)
- Use case: Agents that verify KYC/AML workflows and audit trails by aligning document/process states to policy goals and issuing progress/completeness scores.
- Potential tools/products/workflows:
- Document-to-state graph pipelines; compliance goal interpreters; dashboards showing EPIC-like stability over case lifecycles.
- Assumptions/dependencies:
- Accurate document extraction; privacy/compliance; explainability requirements; handling long-horizon, sparse signals.
- Energy operations and maintenance (energy, industry)
- Use case: Procedure adherence and fault-resolution assistants for plants/grids, using object–attribute states (equipment, status, environmental conditions) to guide and score multi-step procedures.
- Potential tools/products/workflows:
- SCADA/log-to-state adapters; goal interpreters from SOPs and safety manuals; planning aids with dense reward guidance.
- Assumptions/dependencies:
- Reliable multimodal grounding from telemetry; safety-critical validation; domain-specific vocabularies.
- Standardization and certification of AI reward quality (policy, standards bodies)
- Use case: Regulatory or procurement frameworks that assess reward generalization and robustness using benchmarks like RewardPrediction and policy-invariant metrics (e.g., EPIC).
- Potential tools/products/workflows:
- Test suites that certify agents’ reward stability across domains; reference implementations and reporting standards.
- Assumptions/dependencies:
- Community consensus on metrics and schemas; curated, representative multi-domain datasets; governance for updates.
- Training pipelines without hand-engineered rewards (industry/academia ML)
- Use case: Model-based RL or offline RL that leverages StateFactory-derived dense rewards to train generalist agents, reducing dependence on domain-specific reward functions.
- Potential tools/products/workflows:
- Agent training loops where StateFactory supplies progress signals; self-play/experience replay with structured reward shaping.
- Assumptions/dependencies:
- Stable reward estimates across exploration; avoidance of reward hacking; efficient, scalable inference.
- Open standards and SDKs for object–attribute state tracking (ecosystem tooling)
- Use case: Interoperable schemas and APIs for hierarchical state extraction, dynamic goal interpretation, and reward computation across modalities and domains.
- Potential tools/products/workflows:
- StateFactory SDKs; embedding evaluation suites; memory stores and vector DB integrations for state persistence.
- Assumptions/dependencies:
- Agreement on schemas and versioning; performance benchmarks; modular plug-in architecture.
Notes across applications:
- Core dependencies include a capable LLM for state factorization and goal interpretation, a discriminative embedding model for similarity, and a reliable way to ground observations into text. The paper’s results suggest better performance with stronger “thinking” modes and higher-quality embeddings, but real-world feasibility hinges on latency, cost, privacy, and safety validation—especially in regulated or safety-critical sectors.
Glossary
- attentional prior: A contextual bias that focuses processing on task-relevant information while filtering out distractors. "the goal context () acts as an attentional prior to filter task irrelevant details."
- belief state: An internal representation of the agent’s inferred world state under partial observability. "stateful), e.g., allowing them to maintain a memory of belief states for more efficient prediction."
- contrastive ranking loss: A learning objective that pushes positive examples to score higher than negatives, used for preference-based reward training. "We then train the LLM with a contrastive ranking loss \citep{chen2025planning} with a reward centering term \citep{naik2024reward}."
- distance-to-goal reward: A reward defined by the (negative) distance between current and goal states, providing dense progress feedback. "we adopt the distance-to-goal reward \citep{trott2019keeping, liu2022goal}:"
- Equivalent Policy-Invariant Comparison (EPIC) distance: A policy-invariant metric for comparing reward functions, derived from correlations between predicted and ground-truth rewards. "We adopt the Equivalent Policy-Invariant Comparison (EPIC) distance \citep{gleave2020quantifying, frick2024evaluate} between ground truth rewards and predicted rewards as the metric."
- Goal-Augmented Markov Decision Process (GA-MDP): An MDP formulation explicitly conditioning on goals, used to model goal-reaching tasks. "we consider a Goal-Augmented Markov Decision Process (GA-MDP) \citep{liu2022goal} with Partial Observation \citep{kaelbling1998planning} constraints"
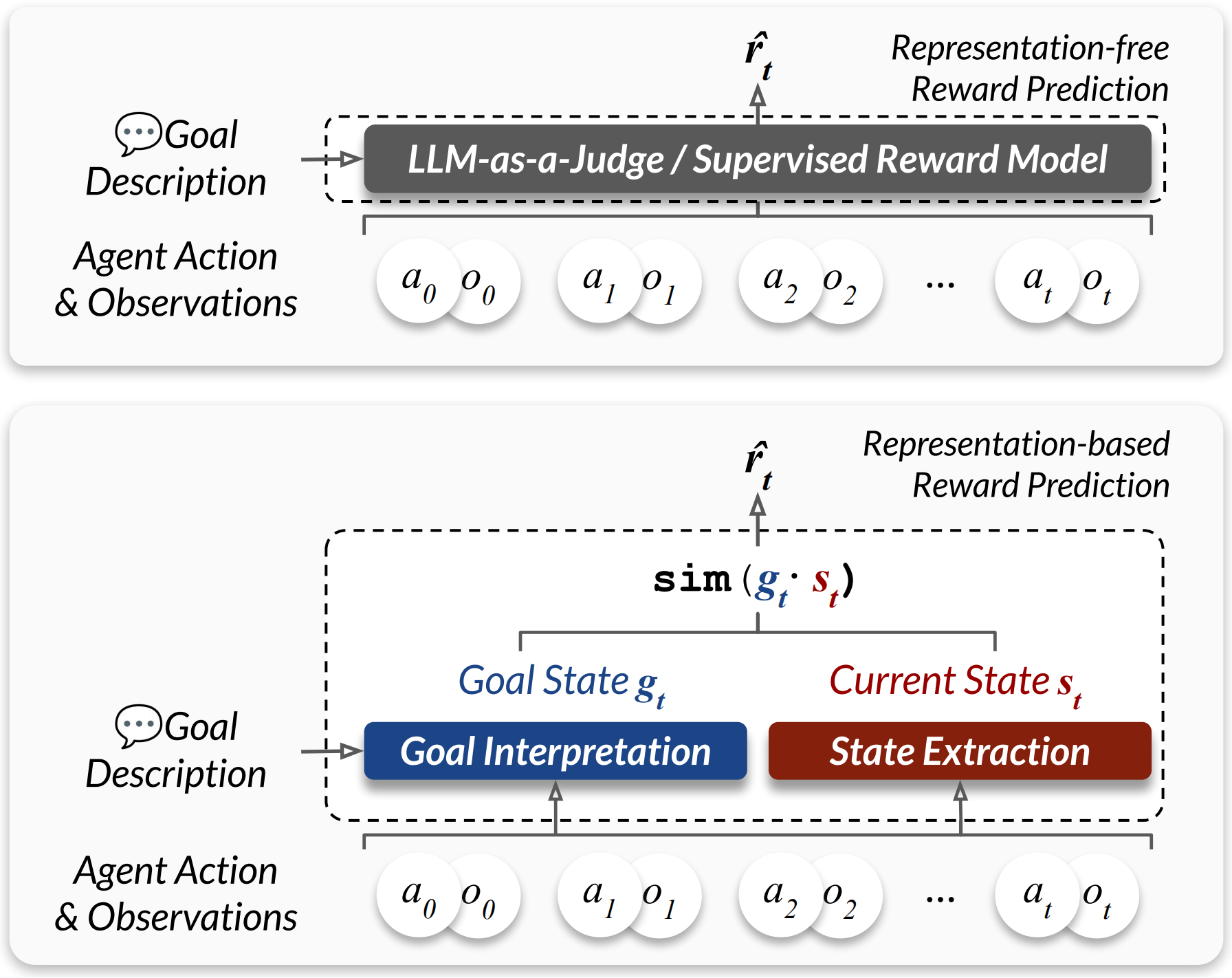
- goal interpretation: The process of grounding a textual goal into a structured, evolving representation aligned with the current context. "StateFactory treats goal interpretation as an iterative, state-aware process."
- hierarchical routing: A staged evaluation mechanism that aggregates fine-grained matches (e.g., attributes) into higher-level progress signals. "The reward signals are then naturally estimated by measuring semantic similarity between the current and goal states through the hierarchical routing."
- LLM-as-a-Judge: A prompting paradigm where a LLM directly evaluates and scores outputs (e.g., rewards) given instructions and context. "Our method shows promising zero-shot results against both VLWM-critic and LLM-as-a-Judge reward models"
- Monte Carlo Tree Search (MCTS): A search algorithm that explores action sequences via stochastic rollouts and value estimates to guide planning. "integrating LLM-based action proposals, a learned world model~\citep{li2025word}, and StateFactory into Monte Carlo Tree Search (MCTS)."
- object-attribute states: A structured representation that factorizes entities (objects) into identities and explicit attribute-value pairs. "StateFactory overcomes this by refining the granularity to explicit object-attribute states."
- object-centric: A modeling approach that represents the environment primarily through discrete objects, often without disentangled attributes. "or simple object-centric approaches that fail to capture fine-grained attribute dynamics"
- Partial Observation: A constraint where the agent’s observations do not fully reveal the underlying environment state. "with Partial Observation \citep{kaelbling1998planning} constraints"
- PDDL (Planning Domain Definition Language): A formal language for specifying planning domains and problems used in classical planning. "utilized a PDDL-to-text translator"
- policy-invariant measure: A metric whose conclusions about reward similarity remain unchanged across policies, robust to certain reward transformations. "EPIC distance is an approach to quantify the difference between reward functions, providing a policy-invariant measure that preserves the fine-grained magnitude information essential for robust planning."
- ReAct: A prompting framework that interleaves reasoning (think) and acting (act) steps within language-agent trajectories. "we evaluate the ReAct + StateFactory agent, which integrates our reward signals into the standard ReAct baseline."
- reward centering term: A normalization component in reward-model training that re-centers predicted rewards to stabilize learning. "We then train the LLM with a contrastive ranking loss \citep{chen2025planning} with a reward centering term \citep{naik2024reward}."
- reward hacking: The exploitation of flaws in a reward specification or metric to achieve high scores without genuine task progress. "To mitigate heuristic reward hacking, we employ a paired data construction strategy."
- semantic factorization: Decomposing unstructured observations into structured, semantically meaningful components for downstream evaluation. "we propose StateFactory, a semantic factorization framework that factorizes world states into hierarchical objectâattribute structures."
- semantic similarity: A measure of meaning-level closeness between two representations (e.g., texts), used here to compare states and goals. "This structured representation allows rewards to be estimated naturally as the semantic similarity between the current state and the goal state under hierarchical constraint."
- system-1: Fast, reactive decision-making processes with minimal deliberation. "over reactive system-1 policies"
- system-2: Deliberate, structured reasoning and planning processes. "enhancing system-2 agent planning."
- triplet-based accuracy: An embedding evaluation metric that checks whether an anchor is closer to a positive than to a negative example. "This discriminative power is measured by the triplet-based accuracy~\citep{dumpala2024sugarcrepe++},"
- Vision Language World Model (VLWM): A generative or predictive model that jointly handles visual and textual inputs to model environment dynamics. "the self-supervised critic used in the Vision Language World Model (VLWM) \citep{chen2025planning}"
- VLWM-critic: A self-supervised critic associated with a Vision-Language World Model, used to predict or assess rewards. "Our method shows promising zero-shot results against both VLWM-critic and LLM-as-a-Judge reward models"
- world model: A predictive model that simulates how the environment evolves in response to actions, producing future states. "This limitation necessitates world models \citep{ha2018world, richens2025general} that predict the consequences of actions as future world states to guide policy learning \citep{hafner2023mastering} or plan search \citep{lecun2022path, hansen2023td}."
- zero-shot: Performing on new tasks or domains without any task-specific training or fine-tuning. "We are interested in building agents with planning capabilities that generalize across different goals and environments in zero-shot."
Collections
Sign up for free to add this paper to one or more collections.