- The paper introduces a dynamic, tool-augmented framework that iteratively applies multi-step reasoning to overcome data sparsity in recommendation tasks.
- It employs specialized user-side, item-side, and collaborative tools to systematically identify and fill evidence gaps for more accurate ranking.
- Using a two-stage training protocol with SFT and RL, RecThinker achieves up to a 14% NDCG@10 improvement over state-of-the-art baselines, especially in sparse settings.
Introduction and Agentic Paradigms
Recent advances in LLMs have enabled agent-based models to systematically reason over recommendation tasks. However, conventional agentic approaches leverage mainly static, workflow-constrained, or passively acquired information—fundamentally restricting their ability to close critical knowledge gaps when user profiles are sparse or item metadata incomplete. The "RecThinker: An Agentic Framework for Tool-Augmented Reasoning in Recommendation" (2603.09843) introduces a shift toward more autonomous, investigative recommendation agents that dynamically plan, analyze sufficiency, and proactively invoke external tools to bridge the information gaps inherent in high-stakes, sparse-data settings.
The paper situates RecThinker at the intersection of three agentic paradigms (Simulator, Assistant, Investigator), clarifying its position as an investigator agent that, unlike prior work, analyzes what evidence is lacking, dynamically plans multi-step reasoning, and acquires external knowledge using specialized, recommendation-oriented tools.
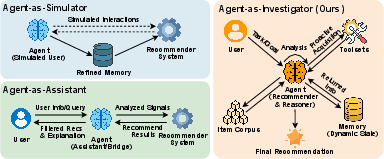
Figure 1: Illustration of agentic recommendation paradigms.
RecThinker Architecture and the Analyze-Plan-Act Paradigm
RecThinker formalizes the agentic recommendation task as iterated multi-step reasoning over user u and candidate item set C, embedding the agent's workflow in an Analyze-Plan-Act paradigm. The agent iteratively assesses information sufficiency by analyzing user-centric and item-centric knowledge, identifying missing evidence, and invoking flexible, recommendation-tailored tools to close these information gaps. Internal trajectories consist of reasoning steps, tool calls, and tool-response integration, with subsequent planning dependent on dynamically updated sufficiency assessment.
Central to this architecture is the policy π that governs thought generation and action/tool selection, parameterized for explicit sufficiency checking and knowledge gap analysis. The agent's ultimate ranking decision is issued only after the system determines that further evidence acquisition would yield no marginal utility.
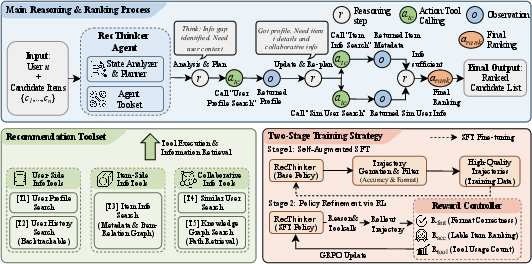
Figure 2: The overall architecture of the RecThinker model.
RecThinker deploys a suite of specialized tools, each constructed to support critical axes of evidence acquisition:
- User-side tools: User Profile Search (for static long-term/preference summarization) and User History Search (for interaction sequences and feedback signals).
- Item-side tool: Item Info Search, leveraging an Item-Relation Graph for semantic/contextual expansion of candidate and historical item attributes, further codifying co-occurrence and content-based similarity.
- Collaborative tools: Similar Users Search (blending sparse interaction overlaps and dense embedding similarity), and Knowledge Graph Search (providing high-order collaborative evidence via multi-hop user-item relations).
Rather than resorting to exhaustive querying or indiscriminate information gathering, RecThinker uses a progressive, sufficiency-driven approach, iteratively refining its evidence base, minimizing redundant tool use, and targeting supplementary signals only when the current context reveals uncertainty or insufficient knowledge for reliable ranking.
Self-Augmented Supervised Fine-Tuning and RL Policy Optimization
A two-stage training protocol underpins the policy refinement in RecThinker. The first stage generates and filters high-quality reasoning trajectories—those achieving ranking optimality and correct agent format—for self-augmented supervised fine-tuning (SFT). Supervision is provided only on agent-produced tokens, with tool outputs masked from gradient updates, stabilizing the learning of reasoning and invocation policies.
The second stage leverages RL, specifically the GRPO algorithm, with a composite reward that balances ranking accuracy (NDCG@10), agentic format correctness, and efficient tool utilization. Hard instances are sampled based on rollout performance, with the design of the tool utilization reward explicitly regularizing against both over- and under-use—penalizing both insufficient and excessive external knowledge queries. This architecture ensures that RecThinker’s investigation behavior remains evidence-driven and resource-efficient, with empirically constrained exploration maximizing sample efficiency and recommendation quality.
Empirical Evaluation and Analysis
Experimental evaluation spans both low-density (sparse) and high-density (dense) subsets of Amazon CD and MovieLens-1M datasets. RecThinker demonstrates consistent, statistically significant improvements over classical, LLM-based, and state-of-the-art agentic baselines (e.g., PersonaX, AgentCF, R2Rec). For NDCG@10, RecThinker’s improvement margins reach up to 14% over the strongest baselines, particularly in sparse data regimes where information sufficiency and evidence acquisition are most challenging.
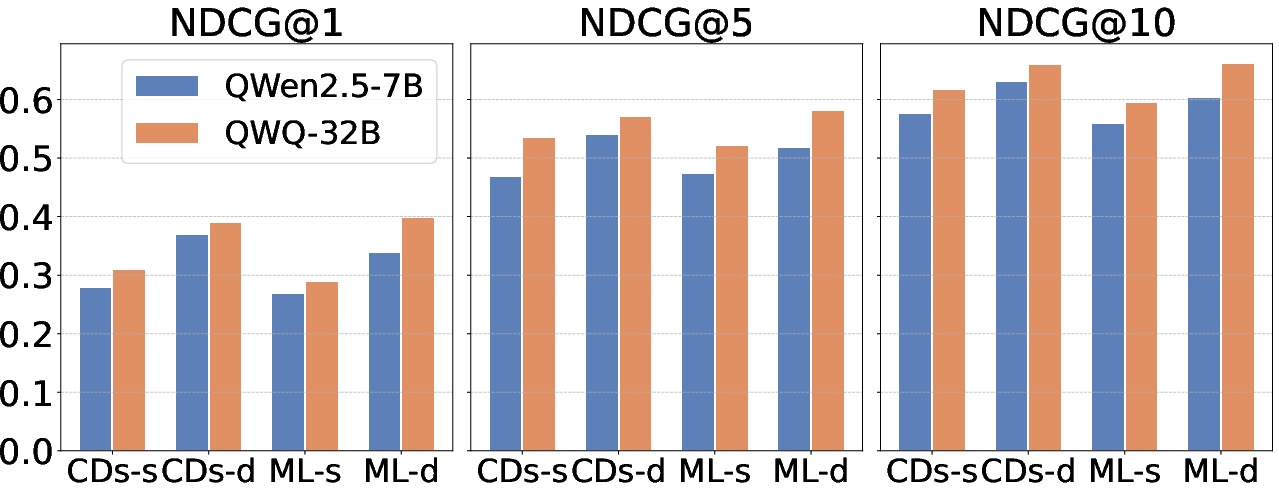
Figure 3: NDCG@1, 5, 10 results for RecThinker with QWQ-32B and QWen2.5-7B backbone models across four datasets, demonstrating consistent performance leadership and transferability.
Ablation experiments indicate that both SFT and RL are crucial; omitting SFT yields substantial drops in stability and output format adherence, whereas the absence of RL reduces the system's ability to optimize exploration and exploit the information acquisition strategies. Further, removing any single specialized tool degrades global effectiveness, with user- and item-history tools particularly critical. Backbone experiments suggest that the architecture generalizes well, maintaining high efficacy even with smaller models and in varying sequence length/data density regimes.
Implications and Future Directions
RecThinker establishes a strong empirical and methodological baseline for agentic, tool-augmented recommendation. The explicit modeling inline of information gap analysis and the intertwining of rigorous sufficiency checks with dynamic tool invocation extends prior agentic paradigms ([RecMind 2024], [PersonaX 2025]) and paves the way for future architectures with:
- Adaptive reasoning granularity dependent on the hardness of the candidate set or user modeling confidence.
- Integration of further external and dynamic knowledge sources (event-based knowledge, temporal trends).
- Fine-grained reward function design for RL stages, incorporating explainability and diversity, not just ranking metrics and tool economy.
- Enhanced policies for multi-user, multi-agent, or multi-task collaborative recommendation, extending the investigator paradigm to collaborative or competitive agent settings.
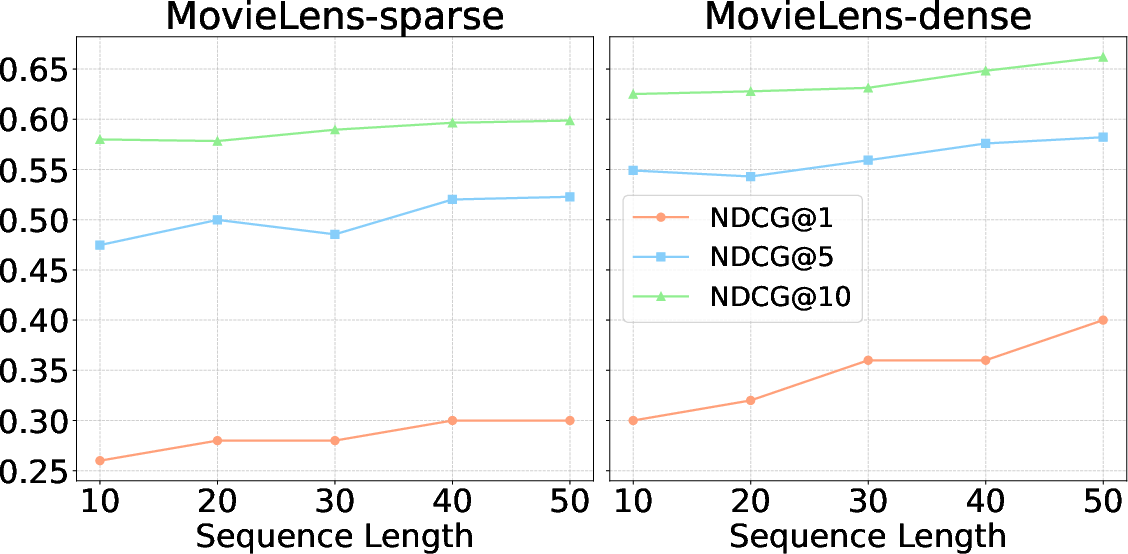
Figure 4: NDCG@1, 5, 10 for RecThinker as a function of sequence length on MovieLens-1M, illustrating increased model benefit with richer historical evidence.
Conclusion
RecThinker advances the agentic recommendation field by establishing a rigorous, tool-augmented, and evidence-driven reasoning framework that autonomously analyzes recommendation tasks, detects information insufficiency, and strategically invokes external knowledge acquisition. The system's architecture achieves state-of-the-art performance across multiple benchmarks, with demonstrated generalizability and strong empirical gains in sparse information settings. These advances mark significant progress in the realization of autonomous investigator agents for high-performance, explainable recommendation systems.