- The paper introduces a novel Voronoi cell framework to precisely estimate retrieval error from token removal in late-interaction models.
- It details a greedy, iterative pruning algorithm using Monte Carlo error estimation, achieving 98% retention of retrieval quality at a 50% token budget.
- Experimental results highlight a 120-fold speedup over LP-based methods and robust retrieval effectiveness even at extreme compression levels.
A Voronoi Cell Framework for Principled Token Pruning in Late-Interaction Retrieval
Introduction
Late-interaction models, epitomized by ColBERT, have established themselves as standard practice in neural information retrieval, balancing retrieval effectiveness with low inference latency by decomposing document-query relevance into fine-grained token-level interactions. However, this expressivity is achieved at the expense of significant memory and storage overhead, as each document token is associated with a dedicated dense embedding vector. To address the index size bottleneck, a range of token pruning and index compression strategies have been explored; nevertheless, many such approaches rely on heuristic or weakly justified mechanisms that struggle under high compression or fail to provide theoretical guarantees.
This paper proposes a methodologically grounded alternative that formulates token pruning through the lens of hyperspace geometry, casting the task as estimation and minimization of retrieval error resulting from removal of token vectors. Each token’s “region of importance” is characterized via its Voronoi cell in embedding space, providing a geometric and analytical framework to guide pruning decisions.
The core insight is that, for late-interaction models with max-sim aggregation—such as ColBERT—the effect of removing a token embedding is captured by the structure of the high-dimensional Voronoi tessellation induced on the query vector space. Specifically, for each document token di, its Voronoi cell Vi comprises all query vectors for which di yields the maximum similarity. This provides a natural partitioning that allows precise computation of the expected retrieval decrement (“error”) induced by pruning.
The expected error associated with pruning di is given by the volumetric integral of the decrement in max-dot product across its Voronoi cell. This measure, concretized via Monte Carlo approximation, elegantly extends and subsumes prior formulations such as LP-based lossless pruning, generalizing them into a continuum that can accommodate both lossless and lossy objectives.
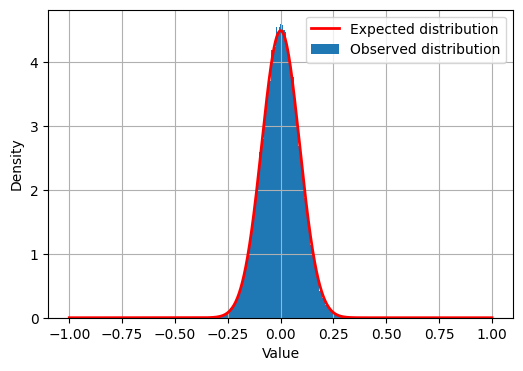
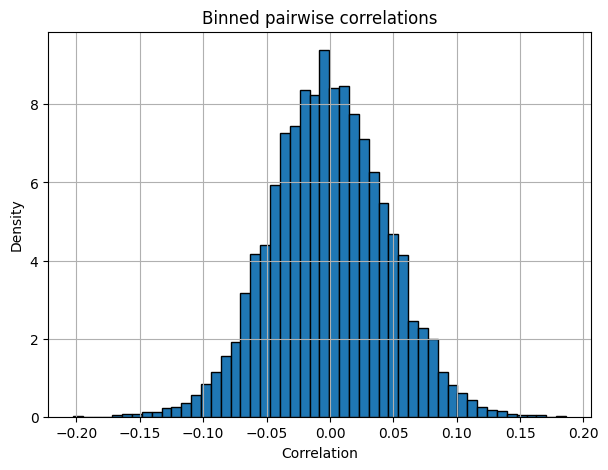
Figure 1: Observed distribution of the 104th embedding dimension over 100,000 queries, demonstrating empirical suitability of the uniform sampling assumption for geometric estimation of token importance.
This geometric perspective allows for approximating the distribution of query embeddings and substantiates the use of uniform sampling for error estimation, as confirmed by empirical analysis on large MS MARCO samples.
The Voronoi Pruning Algorithm
Token pruning is operationalized as a global optimization problem: select a subset of k document tokens whose removal, as assessed by the above error metric, minimizes the expected degradation in retrieval scores. The authors propose an iterative, greedy update strategy. At each step, the token whose removal produces the lowest incremental error is pruned, and error values for the affected token set are recomputed to account for changes in Voronoi cell partitioning.
This methodology delivers enhanced performance over static, single-pass heuristic methods and outperforms even learned token selection baselines under rigorous evaluation. Efficiency and tractability are further improved by parallelizing Monte Carlo estimation, batching vector computations, and exploiting the structure of the Voronoi diagram for localized error updates.
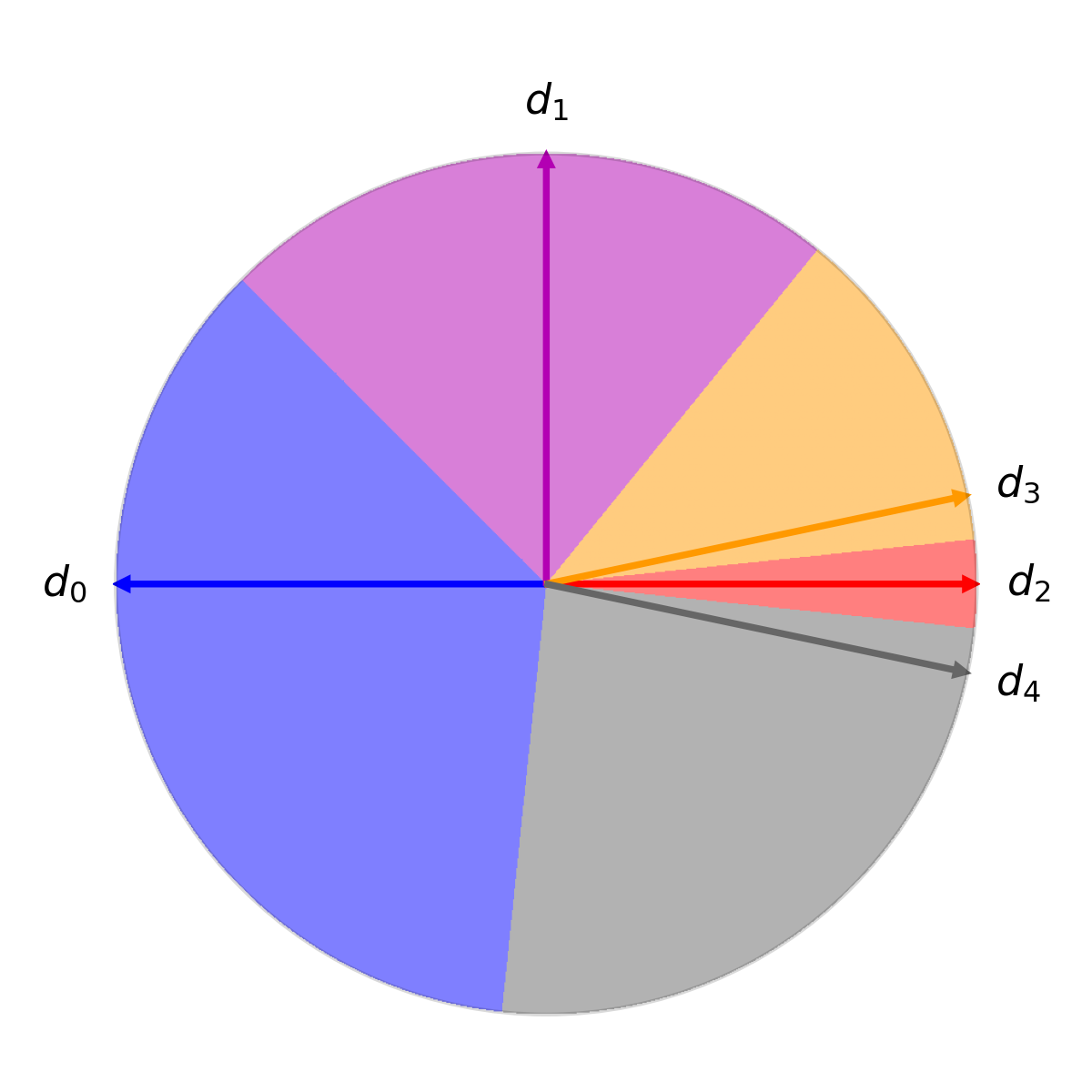
Figure 2: Initial configuration of 5 document vectors visualized in low-dimensional space as a reference for subsequent Voronoi diagrams and comparative pruning strategies.
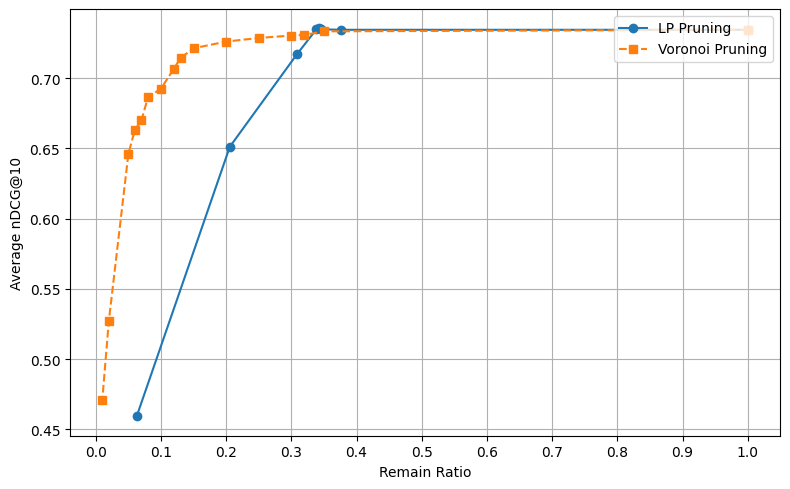
Figure 3: Comparative evaluation of LP Pruning and Voronoi Pruning on ColBERT vectors, illustrating superior retention of retrieval quality under aggressive budget constraints.
Experimental Results and Comparative Evaluation
The framework is evaluated on a spectrum of dense IR benchmarks. On MS MARCO, Voronoi Pruning preserves 98% of unpruned ColBERTv2 end-to-end MRR@10 at a 50% token budget, outperforming heuristic baselines (first-k, IDF, attention score) and achieving parity or superiority relative to learned pruning methods such as AligneR and ConstBERT.
Crucially, at high compression settings—retaining as little as 6% of tokens—Voronoi Pruning delivers significantly higher nDCG@10 compared to alternatives (0.67 versus 0.46), demonstrating robustness against extreme index reduction. Out-of-domain robustness is validated on BEIR, with the method matching or exceeding learned pruning efficacy across diverse corpora.
Furthermore, ablation studies confirm the necessity of iterative error recomputation; non-iterative or coarse step-size strategies lead to marked drops in retrieval quality.
Analytical Insights: Mean Error as an Effectiveness Proxy
Beyond its direct impact in pruning, the Voronoi framework provides analytical clarity on token-level contributions. Empirical investigation reveals that the mean error metric introduced here correlates highly linearly (R2≈0.99 on TREC-DL datasets) with retrieval quality metrics such as nDCG@10, enabling practitioners to set pruning thresholds using computationally efficient, model-agnostic criteria.
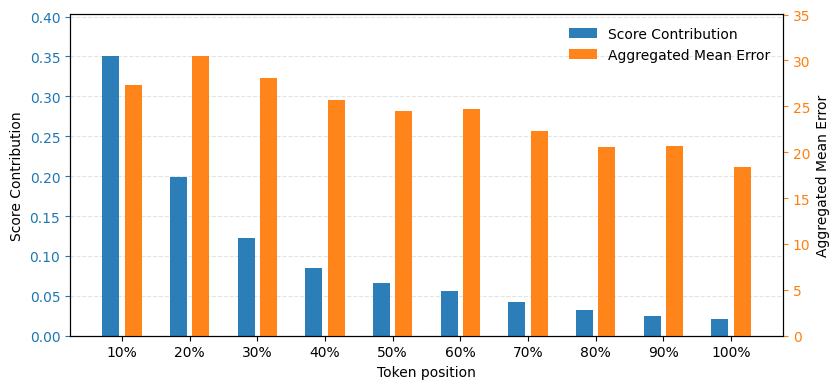
Figure 4: Distributional analysis of document token contributions to maximum dot-product scores and their corresponding aggregated mean errors by position.
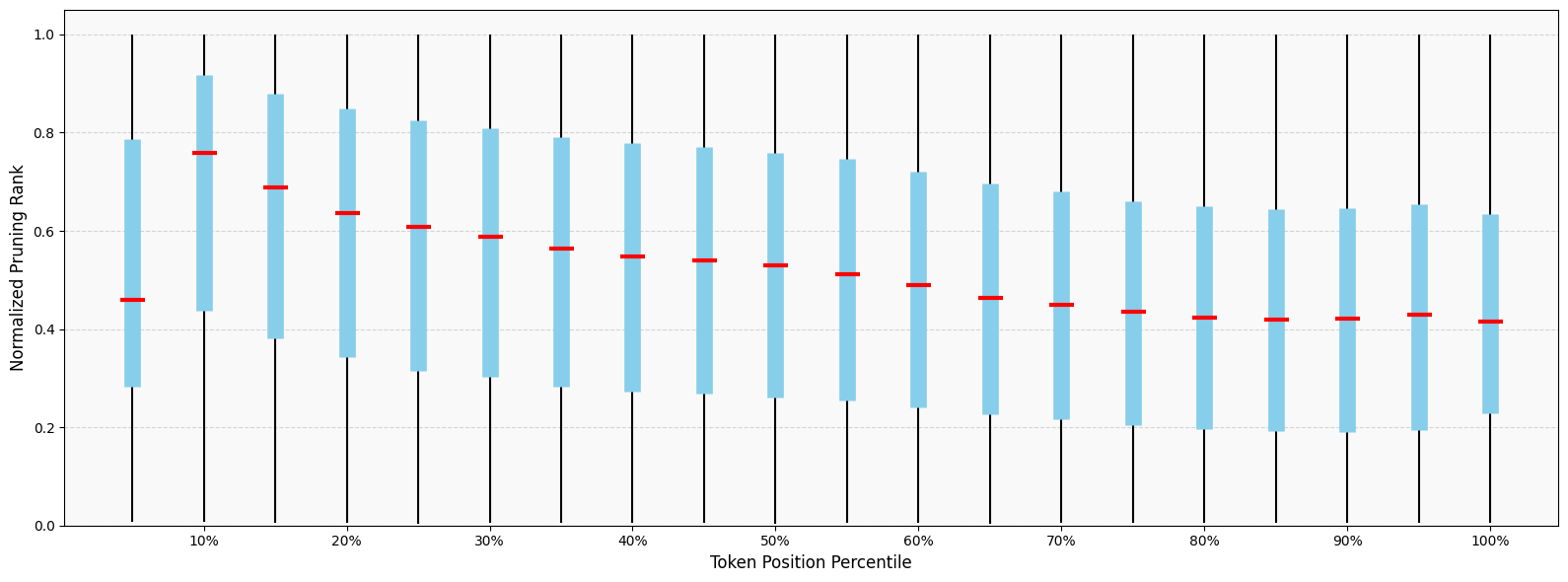
Figure 5: Distribution of pruning positions, where lower values indicate earlier removal, used to analyze heuristics such as first-k against the geometric mean-error-based orderings.
Notably, the Voronoi/mean error framework explains limitations of common heuristics, such as the myopic nature of first-k pruning, and provides means to probe and compare token selection strategies in a normalized and interpretable manner.
Efficiency, Generality, and Applicability
A salient advantage of the Voronoi pruning strategy is computational efficiency. When compared directly with LP-based lossless pruning, it achieves more than a 120-fold speedup, requiring only tens of seconds to process large document subcorpora via vectorized GPU operations. The method does not require retraining, auxiliary models, or access to fine-tuning data, and is equally applicable to token representations constrained to the unit sphere—the scenario for which many efficient search engines, such as PLAID, are optimized.
Finally, because the formulation depends only on the aggregation of max-similarity scores, the approach generalizes seamlessly beyond ColBERT to all late-interaction architectures deploying similar scoring functions.
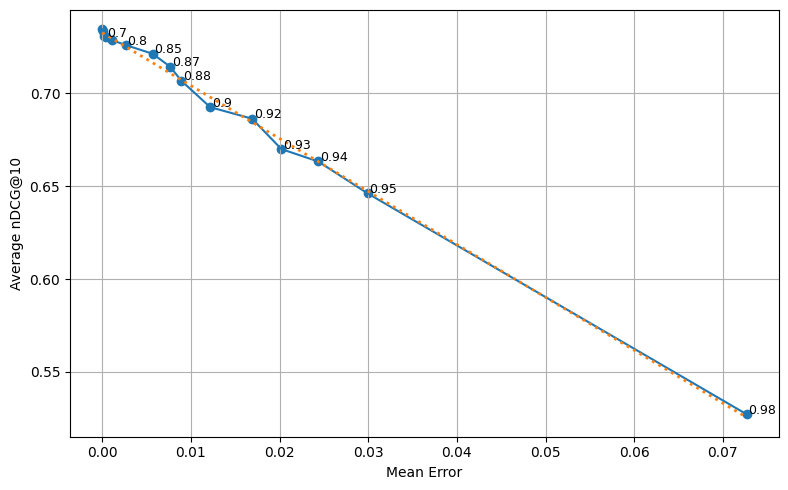
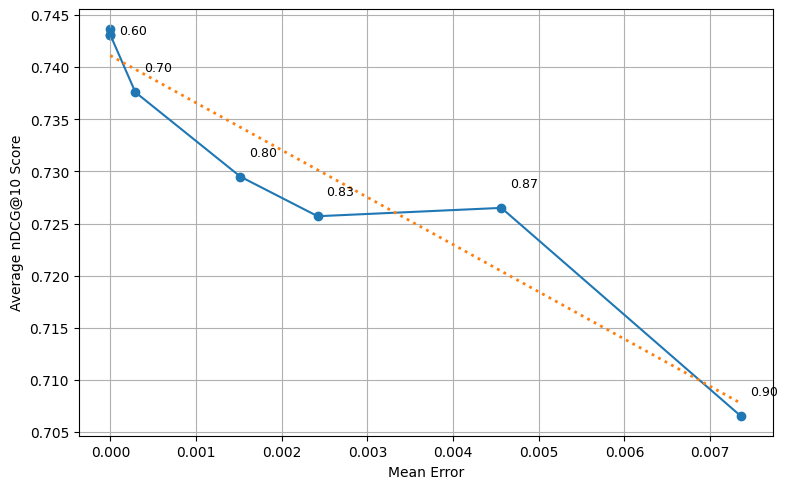
Figure 6: Visualization of the highly linear correlation between the introduced Mean Error and actual retrieval performance (nDCG@10) on TREC benchmarks.
Theoretical Implications and Future Directions
The proposed method demonstrates that geometric analysis can yield token selection mechanisms that are both theoretically principled and practically superior to heuristic or ad hoc alternatives. The Voronoi cell framework opens the way to more general, distribution-aware, or worst-case error minimization objectives and offers a bridge for future research connecting embedding geometry with end-task retrieval metrics.
Potential future directions include:
- Extension to incorporate distributionally robust or fairness-aware (worst-case) pruning objectives
- Joint optimization of embedding spaces to enhance inherent “prunability”
- Alignment with full retrieval loss functions, addressing cases where the mean error may mask heterogeneous or rare but critical score perturbations
Conclusion
The paper introduces a formal geometric framework for token pruning in late-interaction retrieval models grounded in Voronoi tessellation of the token embedding space. By directly optimizing mean retrieval error, the method provides strong theoretical motivation, empirical effectiveness, and computational efficiency, outperforming prior heuristic and learned pruning approaches, particularly in high-rate and cross-domain compression scenarios. The analysis further delivers actionable insights into token-level model behavior, establishes mean error as a robust surrogate for retrieval performance, and lays methodological groundwork for future exploration of geometry-aware retrieval systems.
Citation: "A Voronoi Cell Formulation for Principled Token Pruning in Late-Interaction Retrieval Models" (2603.09933)