- The paper introduces an autoregressive feed-forward Gaussian splatting pipeline that efficiently reconstructs 3D scenes from streaming image inputs.
- It leverages a transformer-based ViT encoder with a dual-pronged KV cache and a render-and-compare module to correct pose discrepancies and stabilize scene assembly.
- Experimental results demonstrate improved PSNR, SSIM, and memory efficiency, enabling real-time performance on commodity GPUs even with long sequences.
ReCoSplat: Autoregressive Feed-Forward Gaussian Splatting Using Render-and-Compare
Introduction and Motivation
Feed-forward 3D Gaussian Splatting (GS) approaches have recently gained traction for efficient novel view synthesis, providing real-time rendering by directly predicting scene representations from images without explicit optimization per scene. While offline GS models exhibit strong results when all views are accessible upfront, online autoregressive GS—where images arrive sequentially and poses may be unknown—remains underexplored but highly pertinent to embodied AI, AR/VR, and streaming video synthesis. Existing online GS pipelines are often limited by pose estimation instability, memory scalability, and distribution mismatch between training and test-time pose conditioning.
ReCoSplat specifically addresses online scene reconstruction and novel view synthesis in both posed and unposed, and calibrated and uncalibrated, settings. The method is instantiated as a feed-forward autoregressive pipeline that produces competitive reconstruction and synthesis quality even in long sequences and out-of-distribution scenarios.
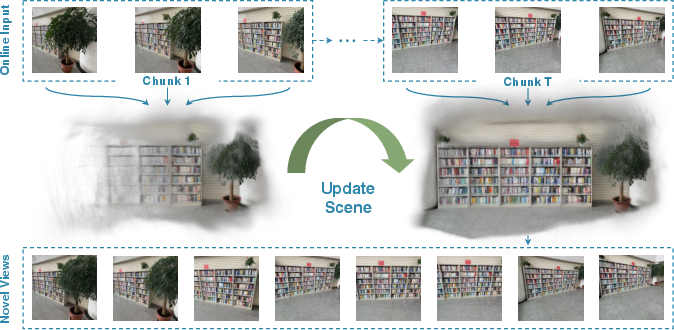
Figure 1: Autoregressive scene reconstruction from streaming image inputs with ReCoSplat.
Core Methodology
Model Overview
ReCoSplat’s architecture builds on a ViT encoder (initialized with DINOv2) for image representation, followed by an alternating-attention transformer backbone with a dedicated KV (Key-Value) cache to support autoregressive token processing. The network outputs both local Gaussian primitives (for scene representation) and pose estimates (extrinsics and intrinsics), enabling operation with or without provided camera parameters.
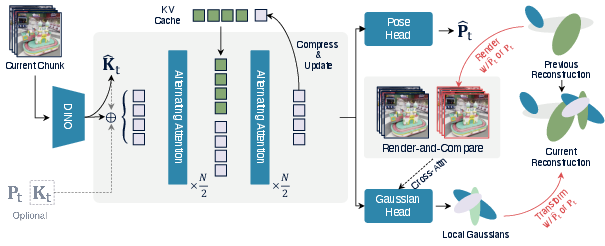
Figure 2: System overview. Each image chunk is encoded, processed autoregressively, and predicted Gaussians are conditioned via a cross-attentive Render-and-Compare signal.
Pose Handling and Assembly: The architecture supports both direct prediction and use of ground-truth camera parameters. Gaussians are predicted in camera space and mapped into a global scene using a pose (the assembly pose). Correct assembly is critical for accurate scene growth during the image stream.
KV Cache Efficiency: Approaches using transformer backbones suffer rapid VRAM growth as context accumulates. ReCoSplat employs a dual-pronged KV cache compression: (1) truncation of early layers where historical tokens are non-informative, and (2) chunk-based selective retention with a trainable register token, dramatically reducing retained entries by over 90% for longer sequences.
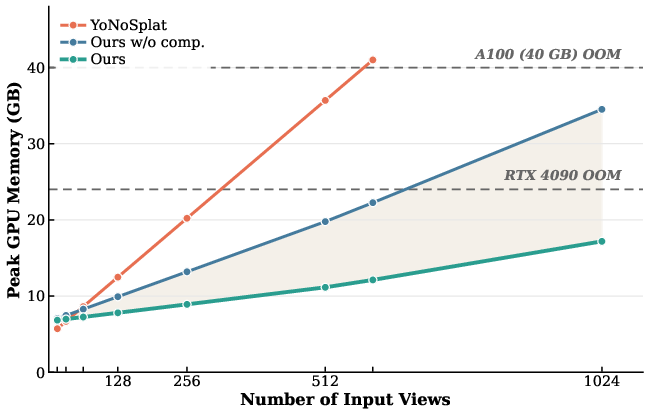

Figure 3: Memory usage for long sequences. With compression, ReCoSplat operates on consumer GPUs even where baselines fail.
Render-and-Compare Module
Pose Distribution Mismatch: A critical failure mode in online GS arises from a mismatch between training (typically using stable ground-truth camera poses) and inference (where poses must be predicted, possibly with large errors). This can introduce severe misalignments and artifacts in the reconstructed 3D scene.
Analysis-by-Synthesis Conditioning: To mitigate this, ReCoSplat’s Render-and-Compare module is introduced. For each incoming view, the current reconstructed scene is rendered from the candidate pose (assembly pose), and concatenated to the new observation. These combined signals are then patchified and injected (via cross-attention) as guidance into the Gaussian head. This conditioning rectifies geometric and visual pose discrepancies, stabilizes the assembly procedure, and encourages alignment of prediction and observation despite pose error at test time.

Figure 4: Qualitative results in the unposed setting. Additive input views yield more accurate geometry and reduced artifacts compared to autoregressive baselines.
Enrichment is further achieved by rendering not only RGB but also nine auxiliary learned feature dimensions for each Gaussian, providing additional gradients and context for the network to correct for mispredictions.

Figure 5: Visualization of auxiliary Gaussian feature channels projected to 3D, evidencing rich scene context beyond mere color.
Experimental Evaluation
Datasets and Protocols
Experiments span DL3DV and ScanNet++ for both in-distribution and out-of-distribution evaluations, and also include RealEstate10K and ACID for generalization. Input settings include posed/calibrated, unposed, and uncalibrated scenarios with variable sequence lengths.
Reconstruction and Synthesis Results
Across all considered metrics (PSNR, SSIM, LPIPS) and input scenarios, ReCoSplat demonstrates consistent, substantial improvements over autoregressive GS baselines. In the most challenging unposed settings, the method yields sharper edges, minimized artifacts, and improved geometric fidelity over non-ReCo variants and optimized baselines, such as S3PO-GS and FreeSplat.
Under fully posed and calibrated scenarios (with pose errors effectively removed), the analysis-by-synthesis Render-and-Compare module is capable of correcting for misprediction of local Gaussians, even outperforming offline methods (YoNoSplat) in certain numerical metrics such as PSNR.

Figure 6: In the posed setting, ReCoSplat achieves superior PSNR over both autoregressive and offline baselines, demonstrating robustness in local Gaussian prediction accuracy.
Robust Memory Handling
The chunk-wise, register-token-aided KV cache enables inference with over 200 input frames while suppressing memory use beneath critical hardware limits, thereby supporting real-time synthesis on commodity GPUs.
Ablations
Systematic ablation reveals:
- Use of predicted, ground-truth, or mixed assembly pose sources confirms the superiority of training with ground-truth poses and adopting Render-and-Compare for inference, as alternative strategies exhibit instability or offer negligible improvement.
- Removal of auxiliary Gaussian feature conditioning leads to performance degradations, emphasizing the importance of rich feature context for bridging assembly errors.
- The prompt register token is especially advantageous on datasets with irregular camera trajectories, bolstering its utility in realistic streaming scenarios (e.g., ScanNet++).
Implications and Future Directions
ReCoSplat makes explicit that marrying analysis-by-synthesis conditioning with memory-efficient transformers significantly advances the robustness and applicability of autoregressive GS for online 3D scene reconstruction. The architecture is hardware-efficient and generalizes convincingly across pose availability and dataset distributions. By bridging the gap between stable training and volatile inference poses, it enables high-fidelity streaming novel view synthesis, compelling for embodied perception, AR/VR, SLAM, and any sequential scene capture workflows.
While ReCoSplat effectively alleviates conditioning mismatch, inherent limits persist: final synthesis quality in the unposed setting remains coupled to camera pose estimation error. Thus, progress in online pose estimation and global scene anchoring will further unlock the ceiling of feed-forward GS performance. The Render-and-Compare paradigm, and its use of deep feature-based conditioning, also suggests broader application potential for streaming, analysis-by-synthesis vision architectures in other sequential generative tasks.

Figure 7: Out-of-distribution novel view synthesis on ScanNet, evidencing strong generalization under both posed and unposed protocols.

Figure 8: Comparative unposed novel view synthesis on DL3DV across growing context, highlighting ReCoSplat’s consistent improvements.
Conclusion
ReCoSplat delivers a technically rigorous, autoregressive feed-forward GS pipeline that is robust to both pose availability and memory constraints. The Render-and-Compare module effectively closes the distributional gap between training and test-time assembly, supporting high-quality online synthesis even under severe pose uncertainty. The hybrid chunk-based memory compression architecture permits practical application to long sequences on accessible hardware. These contributions collectively set a new state of the art for autoregressive GS and open productive avenues in online feed-forward 3D perception and synthesis (2603.09968).