- The paper introduces inference-time energy field guidance to refine pretrained VLA policies for robust robotic manipulation.
- It leverages collision avoidance, semantic grounding, and human demonstration cues as differentiable attractor and repeller forces.
- Empirical evaluations demonstrate significant gains in task success and safety across simulation and real-world deployments.
OmniGuide: Universal Guidance Fields for Enhancing Generalist Robot Policies
Motivation and Problem
Advancements in Vision-Language-Action (VLA) models have enabled broad generalization in robotic manipulation, but with severe limitations in constrained environments and tasks requiring nuanced spatial-semantic reasoning or safety-critical behaviors. Models like GR00T and π0.5, despite being trained on vast datasets, remain brittle under limited coverage and exhibit consistent failures in 3D collision avoidance, physical grounding, and manipulation involving articulated objects. Post-training finetuning can mitigate these issues, but incurs prohibitive data, compute, and engineering costs. OmniGuide directly addresses these deficiencies by introducing a test-time, foundation model-powered guidance protocol that refines pretrained VLA policies using external cues—such as 3D scene understanding, semantic targets, and human demonstration—not during training, but as differentiable constraints at inference time.
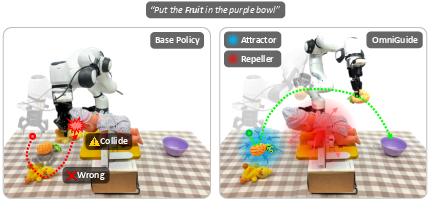
Figure 1: OmniGuide unifies different kinds of guidance via attractive and repulsive fields to improve the performance of generalist robot policies.
Methodology: Inference-Time Guidance via Energy Fields
OmniGuide formalizes guidance as differentiable, energy-based potentials over the robot's predicted Cartesian trajectories. Each source of guidance—whether obstacle avoidance, semantic targeting, or human demonstration—generates an energy function in 3D space. Strictly, these functions act as attractors (goal locations, demonstration subgoals) or repellers (collision avoidance, safety constraints). These guidance signals are injected during every denoising step in a flow-matching (or equivalently, diffusion-based) generative policy.
For a pretrained VLA, the generative process involving action chunks Aτ (at denoising time τ) is augmented with guidance by modifying the ODE integration as
Aτ+δ=Aτ+δ(vθ(Aτ,o)−λclip(∇AτLy(X),α))
where Ly is the sum of energy terms from multiple guidance sources evaluated on the decoded Cartesian trajectory X, and gradients are clipped for stability. This composite energy field naturally blends heterogeneous constraints, steering the policy toward feasible, safe, and semantically aligned behaviors while maintaining naturalness priors from the original VLA.
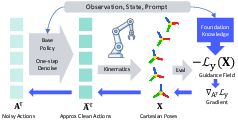
Figure 2: For each denoising step, OmniGuide estimates the clean action via the base VLA, decodes to joint space, computes energy-based guidance with differentiable models, then backpropagates to the latent space to steer next-step action generation.
Guidance Types: Collision, Semantic, and Demonstration
OmniGuide encapsulates a range of guidance sources with unified mathematical form:
- Collision Avoidance: Using environment point clouds (from RGBD or foundation 3D models such as VGGT), a discrete Signed Distance Function (SDF) yields a repulsive log-probability field. The resulting gradients push the trajectory away from obstacles with a magnitude inversely proportional to proximity, efficiently computable in discrete and dynamic environments.
- Semantic Grounding: High-capacity VLMs (e.g., Gemini-2.5-Flash) localize instruction-relevant targets in the scene. Pixel-wise CLIP similarities lift instructions to 3D points, forming attractor potentials centered on semantic goals. An additional orientation alignment minimization aligns gripper approach vector with goal.
- Human Demonstration: One-shot demonstrations are processed using state-of-the-art hand pose estimation (HaPTIC), producing sparse 3D reference trajectories. Monotonic matching aligns robot and human trajectories, with matched pose pairs forming trajectory-level attractor fields.
All energies are evaluated on decoded action predictions, leveraging differentiable kinematics for efficient gradient flow.
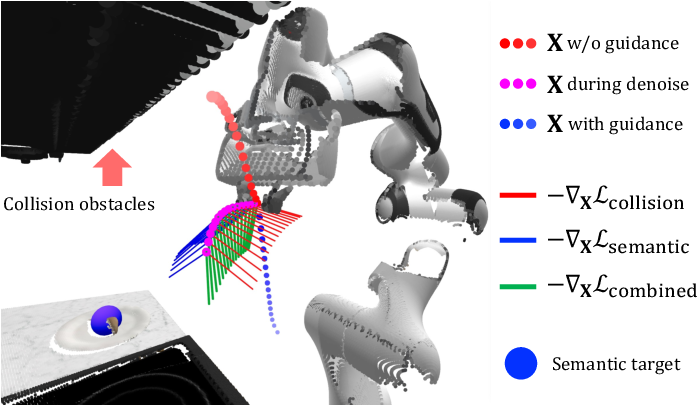
Figure 3: The guidance gradient lines act on the predicted Cartesian trajectory dots, blending repulsive collision avoidance and attractive semantic cues for smooth, grounded execution.
Empirical Evaluation
Simulation
Experiments with the RoboCasa benchmark using GR00T N1.6-3B demonstrate that OmniGuide significantly improves both task success and safety rates across a variety of manipulated environments and cluttered, semantic-rich tasks. Collision-aware guidance lifts safety rates while maintaining or improving success. Semantic grounding enables effective disambiguation and target-oriented manipulation, especially in multi-choice settings. Combining guidance modalities yields additive effects, with no destructive interference observed.
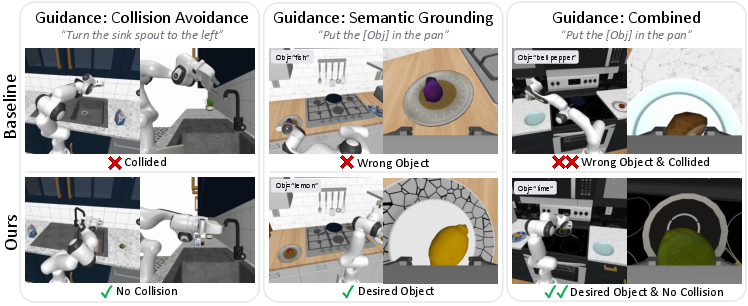
Figure 4: Qualitative examples in simulation highlight OmniGuide’s flexibility: single and joint effects of guidance on diverse tasks (collision, semantic, combination).
Strong ablation studies quantify the contribution of initialization guidance (prior reweighting) versus denoising guidance at each flow step, with the latter being more impactful yet both synergistic.
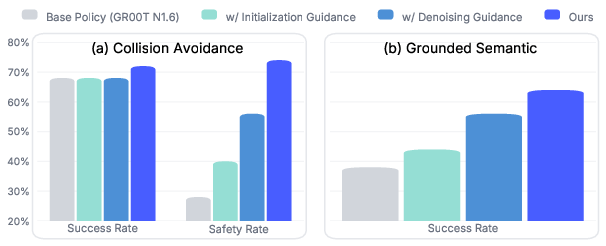
Figure 5: Quantitative results validate the effectiveness of each component, with denoising guidance yielding the largest performance increment, and full OmniGuide maximizing both success and safety.
Real-World Deployment
OmniGuide is validated on a 7-DOF Franka Emika Panda arm (DROID platform) across nine tasks and three guidance modalities. The system—integrating π0.5 as the VLA, Gemini-2.5-Flash for VLM guidance, and VGGT for 3D awareness—substantially outperforms both base policies and guidance-specific baselines (collision-aware cuRobo, CLIP-based F3RM, DemoDiffusion imitation).
Key results:
- Success rate increase (e.g., 24.2% → 92.4%)
- Collision rate decrease (7.0% → 93.5%)
- Real-time feasibility at 15 Hz (∼2× base VLA latency, but deployable for reactive control)

Figure 6: Qualitative real-world examples: Left—collision avoidance, Middle—semantic reasoning target, Right—human demonstration tracking; OmniGuide outperforms the base VLA.
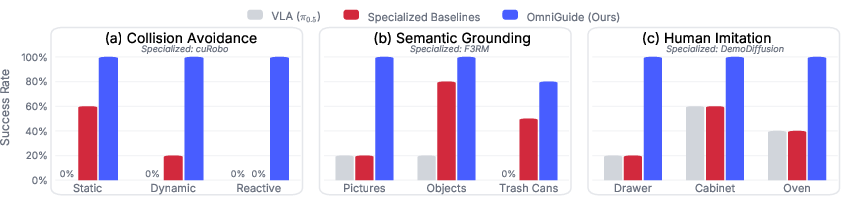
Figure 7: Across nine tasks and three guidance types, OmniGuide consistently surpasses both generalist and specialized approaches in empirical performance.
Latency overhead is primarily due to parallelized perception (KV-cache, CLIP, VGGT computation), with guidance induction itself contributing minor delay.
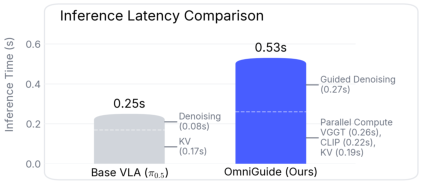
Figure 8: Comprehensive latency analysis shows OmniGuide remains suitable for real-time control despite ∼2× overhead compared to unguided VLA inference.
Ablative and Sensitivity Analyses
OmniGuide's guidance strength is tunable, with an empirically broad viable range balancing the base policy’s naturalness with constraint satisfaction. Excessive strength can degrade task performance by overwhelming the VLA prior. Importantly, concurrent guidance fields compose additively, yielding simultaneous gains in target success (semantic guidance) and safety (collision guidance).
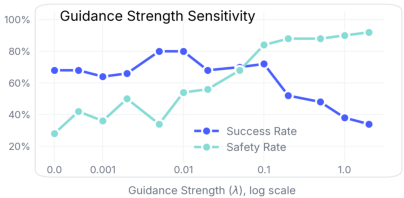
Figure 9: Increasing collision guidance strength improves safety up to a point, with overly high values reducing task success; a broad optimum spans both.
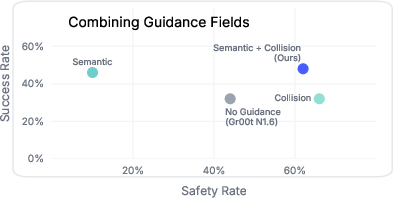
Figure 10: The joint composition of semantic and collision guidance fields enables concurrent enhancement of task and safety metrics.
Implications and Future Directions
OmniGuide establishes a general framework for plug-and-play policy refinement: it unifies external perception and reasoning modules with generalist generative robot control for compositional, constraint-aware action generation—without retraining or curated robot data. Its modularity enables integration of new foundation models (object-centric reasoning, articulated/kinematic inference, multi-modal foundation priors like video or force) and more sophisticated compositional energies. Theoretically, it further connects energy-based modeling, flow matching, and differentiable robotics, offering extensibility to broader embodied AI.
Limitations include dependence on external models' accuracy for scene understanding, possible local minima in potential field guidance, and persistent reliance on pretrained policy coverage for feasibility and diversity. Direction for future work includes richer, object-centric or contact-dynamics-aware guidance, real-time adaptation through additional sensor modalities, and scaling to multi-agent and long-horizon tasks.
Conclusion
OmniGuide delivers a universal, inference-time guidance protocol leveraging external foundation models as modular, differentiable energy fields, applied to pretrained VLA policies. It achieves state-of-the-art results in safety, semantic grounding, and imitation scenarios, consistently outperforming specialized post-processing and initialization-only methods. The framework's abstraction, empirical performance, and extensibility support broad application across future robotic learning and compositional control paradigms.