DiT4DiT: Jointly Modeling Video Dynamics and Actions for Generalizable Robot Control
Abstract: Vision-Language-Action (VLA) models have emerged as a promising paradigm for robot learning, but their representations are still largely inherited from static image-text pretraining, leaving physical dynamics to be learned from comparatively limited action data. Generative video models, by contrast, encode rich spatiotemporal structure and implicit physics, making them a compelling foundation for robotic manipulation. But their potentials are not fully explored in the literature. To bridge the gap, we introduce DiT4DiT, an end-to-end Video-Action Model that couples a video Diffusion Transformer with an action Diffusion Transformer in a unified cascaded framework. Instead of relying on reconstructed future frames, DiT4DiT extracts intermediate denoising features from the video generation process and uses them as temporally grounded conditions for action prediction. We further propose a dual flow-matching objective with decoupled timesteps and noise scales for video prediction, hidden-state extraction, and action inference, enabling coherent joint training of both modules. Across simulation and real-world benchmarks, DiT4DiT achieves state-of-the-art results, reaching average success rates of 98.6% on LIBERO and 50.8% on RoboCasa GR1 while using substantially less training data. On the Unitree G1 robot, it also delivers superior real-world performance and strong zero-shot generalization. Importantly, DiT4DiT improves sample efficiency by over 10x and speeds up convergence by up to 7x, demonstrating that video generation can serve as an effective scaling proxy for robot policy learning. We release code and models at https://dit4dit.github.io/.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
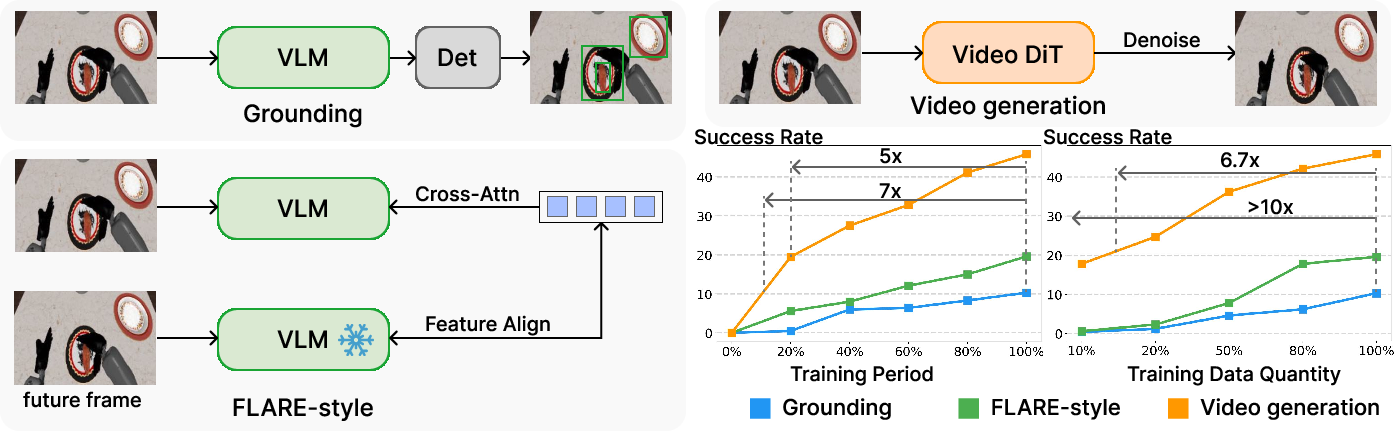
This paper shows a new way to teach robots to act by first learning how the world moves. Instead of only learning from single pictures and text, the method learns from videos that show how things change over time. The authors build a system called DiT4DiT that uses two “brains” working together:
- a video “planner” that imagines what the next moments will look like, and
- an action “controller” that decides what the robot should do next.
By connecting these two, the robot learns to use realistic motion and physics from videos to choose better actions.
What questions were the researchers trying to answer?
The team focused on two simple questions:
- Can getting good at predicting future video frames help a robot learn better and faster actions?
- How can we best connect what a video model learns (about motion and physics) to a robot’s action model so the actions are grounded in what will actually happen?
How did they do it? (with simple analogies)
Think of training a robot like teaching a student to play a sport:
- If you only show the student snapshots (single images), they might learn what the field looks like but not how the ball moves.
- If you show the student many short videos and ask them to predict what happens next, they start to “feel” the motion and timing—things like gravity, momentum, and cause-and-effect.
Here’s how their system works in everyday terms:
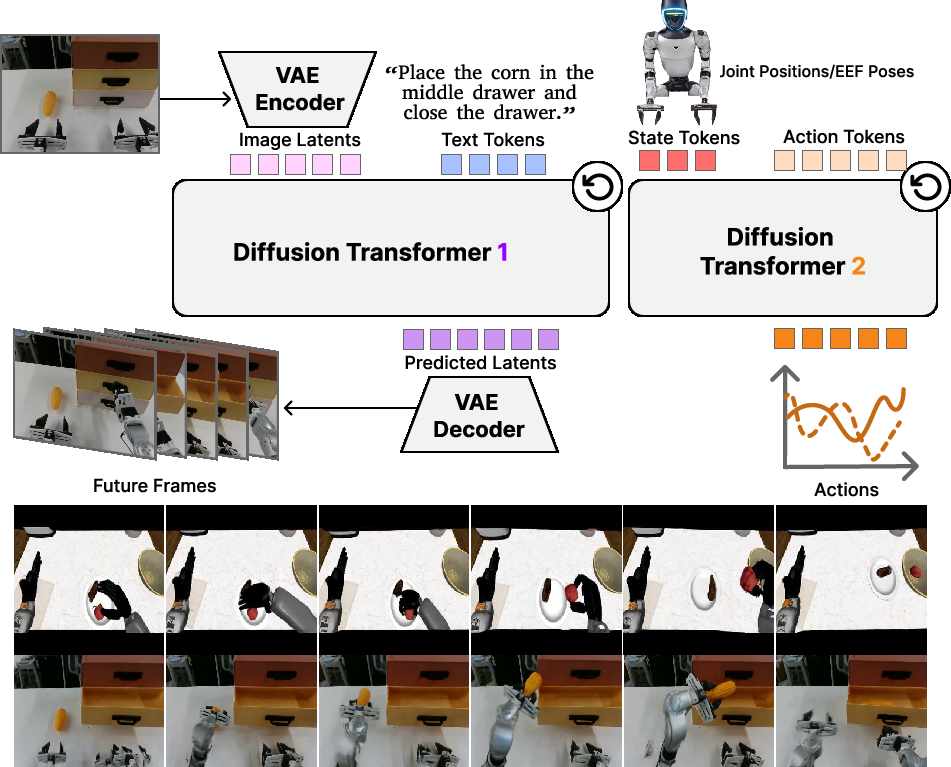
- Two teammates:
- Video teammate (the “planner”): A powerful video generator learns to turn static scenes into likely futures (what the next frames of a video look like). This is done using a technique called diffusion, which you can imagine as starting with a very blurry/noisy image and learning how to gradually un-blur it into a sharp, realistic future frame.
- Action teammate (the “controller”): A second model learns to turn that video teammate’s mid-process thoughts (not the final frames, but the useful hints while un-blurring) into actual robot actions like where to move a hand or how to grasp an object.
- Peeking mid-process:
- Instead of using fully produced future frames, the action model “peeks” at the video model’s intermediate features—like listening in on a coach’s mid-play notes rather than waiting for the final score. These in-between signals carry strong clues about motion and physics without wasting time on pretty pixels.
- Three clocks for stability and speed:
- The system uses three different “timers” to keep training stable and efficient:
- A video timer that trains across all levels of noise (so it learns the whole un-blurring path).
- A fixed “peek time” for grabbing those mid-process video features (so the action model always sees a consistent kind of signal).
- An action timer that focuses training on the most useful stages for control (so the controller learns where it matters most).
- One training loop:
- Both the video “planner” and the action “controller” are trained together using a method called flow matching. In simple terms, they both learn how to turn random noise into something meaningful: the video model learns to turn noise into plausible future frames, and the action model learns to turn noise into the right movement commands—while listening to the video model’s internal hints.
What did they find, and why is it important?
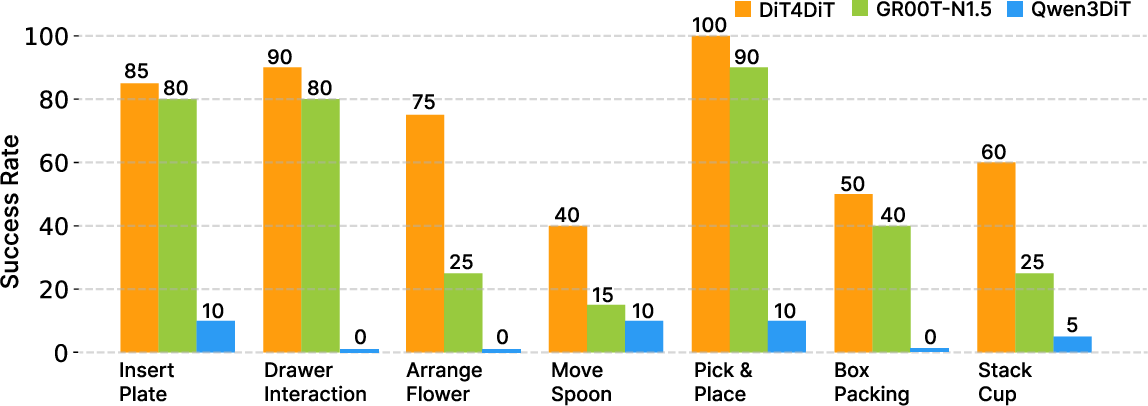
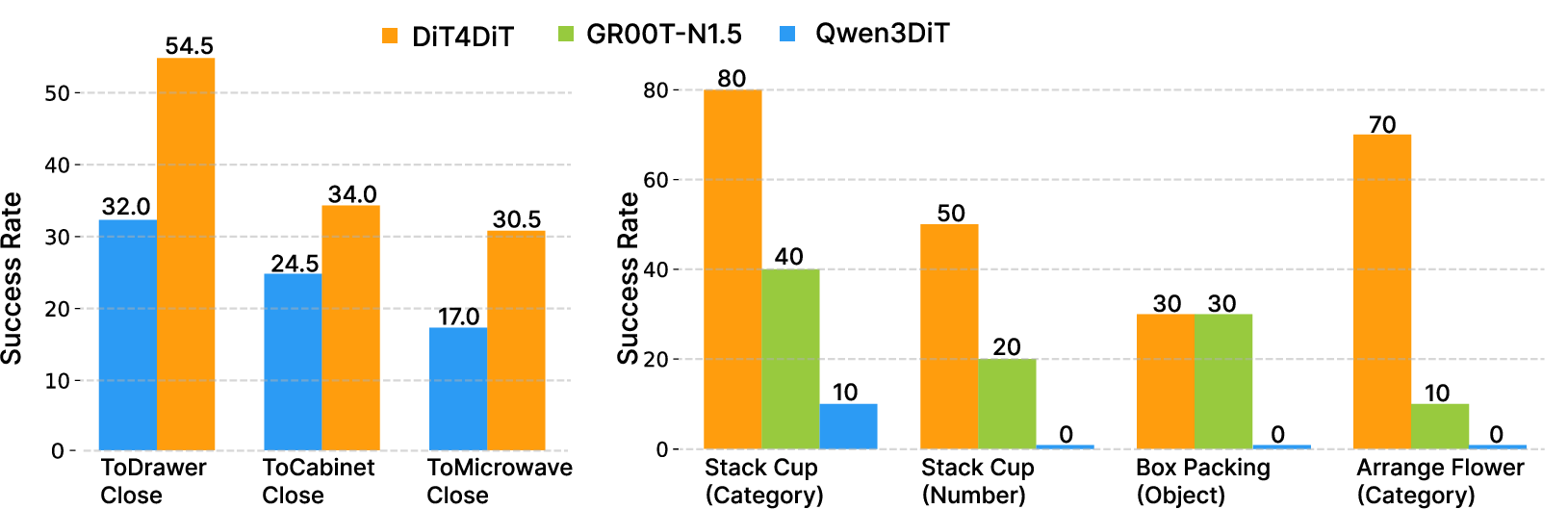
Across both simulated environments and a real humanoid robot, DiT4DiT performed exceptionally well:
- Top results with less data:
- In the LIBERO benchmark (robot arm tasks), DiT4DiT achieved a 98.6% average success rate.
- In the RoboCasa GR1 benchmark (24 challenging tabletop tasks with a humanoid robot), it reached 50.8% average success—state-of-the-art for this setting.
- Real-world success:
- On a Unitree G1 humanoid robot using just a single onboard camera, the system succeeded at precise tasks like arranging flowers and stacking cups—and outperformed strong baselines.
- Learns faster and needs fewer examples:
- Up to 10× better data efficiency (needs far fewer demonstrations to reach good performance).
- Up to 7× faster to reach strong performance.
- Better generalization:
- Strong “zero-shot” behavior: it can handle new objects or variations it hasn’t seen before more reliably than methods trained mainly on image-text.
Why this matters: Robots often struggle to learn reliable physical interactions (like pushing, stacking, opening, and placing) from static images alone. By letting a robot first learn how the world tends to move—through video prediction—the robot gains an internal feel for physics. That makes its actions more robust, precise, and adaptable.
What could this change in the future?
- Faster, cheaper robot training: Because predicting video is unsupervised (no labels needed), robots can pre-train on vast video data to learn general motion and physics, then quickly adapt to new tasks with much less action data.
- More reliable real-world robots: Better understanding of spatiotemporal dynamics should make robots safer and more dependable in messy, changing environments.
- A new foundation for robot learning: This work suggests that “video generation as a proxy task” (learning to imagine futures) is a powerful foundation for teaching robots what to do—potentially more scalable than relying mostly on image-text pretraining.
In short, DiT4DiT shows that having robots learn to “imagine” the near future gives them the physics sense they need to act smarter in the real world.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved by the paper. Each point is framed to facilitate actionable follow-up by future researchers.
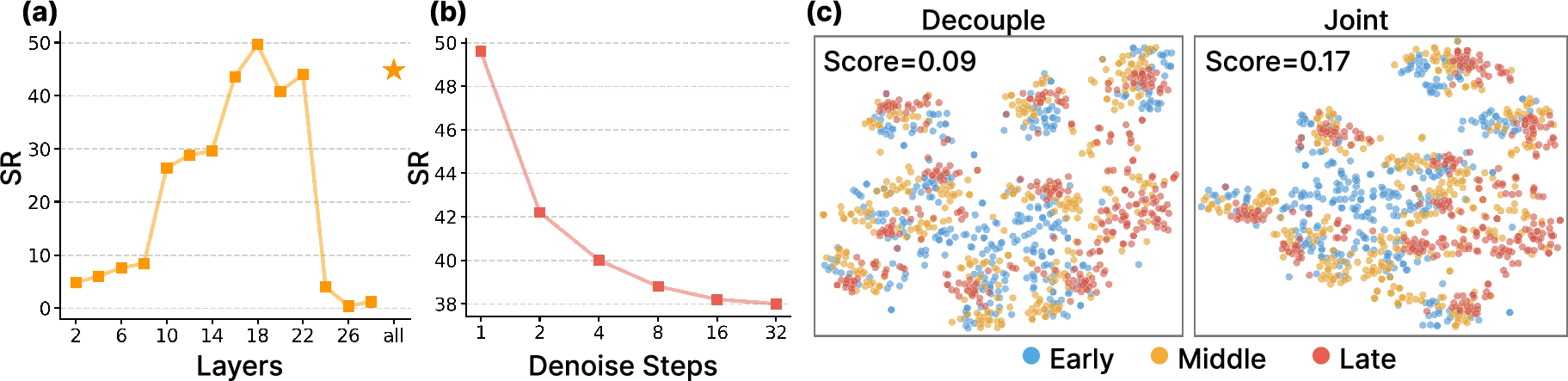
- Lack of ablations on the feature-extraction timestep τ_f:
- No systematic study of how τ_f (early vs. late denoising stage) affects action quality, stability, and sample efficiency.
- No analysis of per-layer vs. aggregated hidden-state hooks; unclear which layers contribute most to control.
- Stochasticity vs. “determinism” of conditioning features:
- Inference extracts features at a fixed τ_f but still samples fresh noise for the video DiT; the impact of this stochasticity on action repeatability and variance is not quantified.
- Open question: should feature extraction be noise-averaged, noise-free (DDIM-like), or ensemble-averaged for stability?
- Tri-timestep scheme design choices are underexplored:
- No ablations on the Beta distribution parameters for τ_a or comparison to uniform/other schedules.
- No sensitivity study of λ (the joint-loss weight), nor a curriculum schedule for λ over training.
- No analysis of coupling vs. decoupling τ_v, τ_f, τ_a under different task horizons.
- Unclear how much of the predicted temporal context is actually used for action:
- It is not specified whether the action DiT conditions on a single future latent, a window of predicted latents, or the full future sequence.
- Missing ablations on T_v (video horizon) and the number of future tokens used for action conditioning.
- Missing comparisons to closely related joint video–action frameworks under matched settings:
- No controlled head-to-head with mimic-video, Cosmos Policy, or other joint models using the same datasets, backbones, and training budgets.
- Freezing choices and representation bottlenecks:
- The VAE and text encoder are frozen; the trade-off between stability and adaptability is not studied.
- No ablations where the video VAE (or parts of it) are fine-tuned to close sim-to-real gaps or to better encode robotics-relevant details (contacts, small objects).
- Action mask M is used but not explained:
- The origin, semantics, and effect of the action mask M (e.g., for varying DoFs or gripper phases) are unspecified; no ablations on masked vs. unmasked training.
- Runtime performance and control latency are not characterized:
- No profiling of inference time per control step (with/without video generation), nor the effect of N_a, N_v on closed-loop control frequency.
- Unclear whether the method meets real-time constraints on resource-limited onboard compute.
- Robustness to sensory and environmental perturbations is not systematically tested:
- No stress tests for lighting changes, motion blur, camera pose drift, occlusions, or background clutter beyond qualitative examples.
- No analysis of robustness to calibration errors or latency in proprioception.
- Limited sensing modalities:
- Only an egocentric RGB camera and basic proprioception are used; the benefits of depth, stereo, multi-view, force/tactile sensing, or wrist cameras remain unexplored.
- Safety, constraint handling, and contact-aware control:
- No explicit handling of collisions, joint limits, force limits, or safety constraints.
- Open question: can the framework incorporate constraint-aware sampling or safety critics without hurting performance?
- Uncertainty, multimodality, and risk-aware decision-making:
- Actions are sampled via deterministic ODE integration; uncertainty quantification (e.g., ensembles, stochastic sampling) and risk-sensitive control are not examined.
- No evaluation of policy calibration or confidence metrics for safe deployment.
- Failure mode taxonomy and diagnostics:
- No systematic categorization of failure cases (e.g., planning vs. perception vs. actuation errors) or how video-generation inaccuracies propagate into control errors.
- Generalization breadth remains narrow:
- Tasks are tabletop-centric; no evaluation on mobile manipulation, locomotion + manipulation, deformable objects, tool use, or highly cluttered long-horizon assembly.
- Cross-embodiment transfer (train on one robot, test on another) is not demonstrated end-to-end without per-robot fine-tuning.
- Data-scaling and compute-scaling laws are missing:
- The claim of >10× sample efficiency is shown on RoboCasa-GR1; broader scaling analyses across varied datasets and tasks are absent.
- No study of backbone size vs. performance/compute trade-offs (e.g., 2B vs. smaller/larger DiTs).
- Sim-to-real transfer characterization is limited:
- Although strong real-world results are reported, there is no quantitative study of how much real data is minimally needed and how performance scales with real fine-tuning data.
- No explicit analysis of domain randomization strategies and their impact on transfer.
- Dependency on a specific pre-trained video backbone:
- The approach is instantiated with Cosmos-Predict2.5-2B; robustness to swapping in other video generators (e.g., HunyuanVideo, Open-Sora, etc.) is not tested.
- Theoretical understanding is limited:
- No formal justification for why intermediate denoising features should outperform final reconstructions for action conditioning.
- Open question: under what conditions does dual flow-matching learn a consistent joint distribution over video dynamics and actions?
- Long-horizon planning and credit assignment:
- While LIBERO-Long results are strong, it’s unclear if the policy explicitly leverages multi-step future predictions vs. reactive step-to-step conditioning.
- No investigation into hierarchical variants (e.g., using long-range visual plans to guide short-horizon action samplers).
- Language grounding and instruction robustness:
- The role of language is underexplored: no tests on ambiguity, compositional generalization, paraphrasing, multilingual instructions, or noisy ASR inputs.
- Evaluation fairness and optimization concerns:
- The real-world Qwen3DiT baseline collapses; it is unclear whether this is architectural or optimization-related (e.g., hyperparameters, augmentations, data curations).
- Missing controlled re-tunings to isolate where the performance gap truly comes from.
- Effect of curriculum and training schedules:
- No experiments on phased training (e.g., pre-train video, then joint fine-tune; or progressively unfreeze modules).
- Open question: can progressive coupling between video and action DiTs further stabilize or accelerate training?
- Horizon and compositionality limits:
- The maximum supported video horizon T_v and its effect on tasks with many subgoals is not quantified.
- No benchmarks on tasks requiring composition of many skills or re-planning under unexpected events.
- Dataset and metric coverage:
- Success rates are the primary metric; no reporting of time-to-success, energy use, smoothness, contact quality, or safety violations.
- No analysis of sensitivity to dataset biases, object textures, or camera intrinsics.
- Replanning and closed-loop adaptation:
- It is unclear how the policy handles unexpected disturbances mid-trajectory or whether online replanning with updated τ_f features recovers from errors.
- Integration with planners or model-predictive control:
- The method is purely generative; combining it with search/MPC or value models for better long-horizon reliability is not explored.
- Explainability and interpretability:
- The intermediate features are opaque; no tools or visualizations to understand what dynamics are captured and how they guide actions.
- Reproducibility and resource disclosure:
- Detailed compute budgets (GPU-days), training times, and memory footprints are not reported, hampering reproducibility and fair comparisons.
Practical Applications
Practical Applications Derived from DiT4DiT
Below are actionable applications that follow from the paper’s findings and design choices (dual DiTs, intermediate denoising features for action conditioning, dual flow-matching with tri-timestep training, and the demonstrated 10× data efficiency and 7× faster convergence). Each item lists sectors, potential tools/products/workflows, and assumptions/dependencies.
Immediate Applications
- General-purpose pick-and-place and articulated-object manipulation on factory floors and in warehouses
- Sectors: robotics, manufacturing, logistics, retail backroom
- Tools/products/workflows: fine-tune DiT4DiT on 100–500 teleop demos per task; deploy as a ROS2 node that takes a single egocentric RGB stream; integrate with existing controllers for grippers/arms; use pretrained video DiT as a frozen backbone to minimize data needs
- Assumptions/dependencies: access to a licensed, pretrained video DiT (e.g., Cosmos-Predict2.5-2B); GPU for inference; mapping between robot embodiment and the action space used during fine-tuning; safety interlocks for human-in-the-loop environments
- Rapid skill onboarding for new SKUs or fixtures with minimal demonstrations
- Sectors: logistics, e-commerce fulfillment, retail
- Tools/products/workflows: collect small datasets for new object categories; reuse fixed feature-extraction timestep (τf) to keep action conditioning stable; exploit tri-timestep training to concentrate learning on critical phases
- Assumptions/dependencies: representative demos covering key grasps/poses; camera placement with sufficient viewpoint; guardrails for zero-shot performance on unseen shapes
- Simulation-to-real transfer for embodied platforms (e.g., Unitree G1, Franka)
- Sectors: robotics R&D, prototyping labs, startups
- Tools/products/workflows: pretrain in RoboCasa/LIBERO, fine-tune on a limited number of real demos; use the same egocentric camera setup as in sim; export policy to on-robot inference or edge compute
- Assumptions/dependencies: sim fidelity; calibrated extrinsics/intrinsics; procedural variability in sim to cover real-world shifts
- Visual “plan” introspection and operator-facing debugging via predicted future frames
- Sectors: software tooling, robotics operations, QA
- Tools/products/workflows: expose video DiT rollouts in UI to preview likely futures before execution; enable step-by-step analysis of failure cases; compare plans across training checkpoints
- Assumptions/dependencies: UI integration; acceptable latency for optional preview; privacy handling if recording real video
- Safety pre-checks using predicted futures (collision and reachability gating)
- Sectors: industrial automation, collaborative robotics
- Tools/products/workflows: run short-horizon video predictions and block actions that lead to unsafe contacts; plug into existing safety layers as an anticipatory filter
- Assumptions/dependencies: tuned confidence thresholds; conservative gating policy; regulator-approved integration with primary safety systems
- Low-sensor-cost deployment using a single egocentric camera
- Sectors: SMEs, education, low-cost robotics
- Tools/products/workflows: deploy policies on arms/humanoids without depth/LiDAR; bundle with camera calibration and lighting checks; auto-monitor image quality
- Assumptions/dependencies: sufficient texture/lighting; tasks not requiring precise depth without secondary cues; fallback procedures for occlusions
- Curriculum learning and accelerated training in academic courses and labs
- Sectors: education, academia
- Tools/products/workflows: teach diffusion-based control with DiT4DiT as a template; assign students to ablate τv/τa/τf and observe convergence; run LIBERO/RoboCasa labs
- Assumptions/dependencies: GPU access; availability of the released code and checkpoints; institutional compute quotas
- Policy distillation and benchmarking baselines
- Sectors: academia, model evaluation platforms
- Tools/products/workflows: use DiT4DiT as a backbone for new benchmarks; distill to smaller models for edge deployment; adopt masked action loss for multi-phase tasks
- Assumptions/dependencies: clear metric definitions; standardized success criteria; data licenses for redistribution
- Developer platform for video-conditioned control plugins
- Sectors: software, MLOps, integrators
- Tools/products/workflows: package an “Action DiT” plugin that consumes hidden states from any compatible video DiT; provide adapters for popular VAEs/encoders; publish ROS2 bindings
- Assumptions/dependencies: stable API for hidden-state extraction; versioned model cards; performance/latency benchmarks per hardware tier
- Fast adaptation to clutter and novel arrangements in household-like environments
- Sectors: domestic robotics, services, hospitality
- Tools/products/workflows: fine-tune on a few in-situ demonstrations for tasks like drawer opening, shelf stocking, or table cleanup; show predicted rollouts to users for trust and transparency
- Assumptions/dependencies: robust handling of background clutter; household safety compliance; user consent and privacy protections
- Cost and energy savings through data/sample efficiency
- Sectors: R&D operations, robotics startups
- Tools/products/workflows: restructure data collection pipelines around video-generation pretraining as a scaling proxy; prioritize small, high-quality teleop sets; monitor convergence speedups
- Assumptions/dependencies: reliable measurement of “success per demo” ROI; access to pretrained video priors; consistent evaluation protocols
- Cross-robot policy reuse with minimal remapping
- Sectors: OEMs, system integrators
- Tools/products/workflows: reuse video backbone and retrain only the action DiT for new embodiments; use latent-space adapters to map different DoFs and grippers
- Assumptions/dependencies: alignment between observation spaces; kinematic/dynamics differences handled by adapters or small fine-tuning sets
Long-Term Applications
- Internet-scale learning from unlabeled video for robot policies
- Sectors: robotics, foundation models
- Tools/products/workflows: pretrain video DiTs on massive public video corpora, then pair with action DiTs trained on small, domain-specific datasets; continual learning from in-the-wild streams
- Assumptions/dependencies: legal and ethical sourcing of video; domain gap mitigation; scalable and safe data pipelines
- Home- and hospital-assistive generalist robots with transparent visual plans
- Sectors: healthcare, eldercare, domestic robotics
- Tools/products/workflows: language-instructed long-horizon tasks (e.g., tidy a kitchen, fetch-and-carry) with on-device preview of planned futures for human oversight
- Assumptions/dependencies: stringent safety and reliability guarantees; HIPAA/GDPR compliance where applicable; robust HRI design
- Hierarchical planning: video DiT as high-level planner, action DiT as low-level controller
- Sectors: industrial automation, mobile manipulation
- Tools/products/workflows: generate subgoal video waypoints; chain multiple horizons for complex sequences; plug into trajectory optimizers for constraint satisfaction
- Assumptions/dependencies: stable subgoal extraction; accurate mapping from visual subgoals to feasible robot states; latency control for long horizons
- Multimodal extensions (tactile, audio, force) for dexterous manipulation
- Sectors: advanced manufacturing, prosthetics, lab automation
- Tools/products/workflows: fuse tactile/force encoders into the action DiT; condition video features with tactile priors to handle contact-rich tasks like insertion and threading
- Assumptions/dependencies: synchronized multimodal sensing; robust sensor calibration; data collection for contact events
- Fleet-level learning and deployment with cloud/edge orchestration
- Sectors: cloud robotics, operations
- Tools/products/workflows: central server runs video-generation pretraining updates; robots receive lightweight action DiT updates; telemetry informs next training cycle
- Assumptions/dependencies: secure networking; versioned rollout and rollback mechanisms; privacy-preserving logging
- Regulatory safety testing via counterfactual visual rollouts
- Sectors: regulatory compliance, safety engineering
- Tools/products/workflows: use generative futures to stress-test policies in silico (near-collision, rare edge cases); certify policies by passing scenario libraries
- Assumptions/dependencies: validated correlation between predicted and real outcomes; formal verification hooks; standardized test suites
- Learning-from-video without action labels (inverse action inference at scale)
- Sectors: robotics research, autonomous systems
- Tools/products/workflows: combine self-supervised video DiTs with weak heuristics or small seed label sets to bootstrap action inference; scale via dual flow-matching
- Assumptions/dependencies: coverage of relevant dynamics in video; reliable self-supervision signals; guardrails against spurious correlations
- Multi-agent coordination with shared video-world priors
- Sectors: warehouses, construction, agriculture
- Tools/products/workflows: shared video generator models physical interactions among agents; action modules conditioned on common latent world states to coordinate tasks
- Assumptions/dependencies: communication protocols; latency budgets; collision avoidance policies
- On-device acceleration and distillation for real-time humanoid control
- Sectors: hardware, edge AI
- Tools/products/workflows: distill DiT4DiT into lighter architectures or sparse mixtures; hardware-aware quantization; FPGA/NPU kernels for diffusion steps
- Assumptions/dependencies: performance parity targets; acceptable accuracy/latency trade-offs; vendor toolchains
- Task programming via natural language plus visual plan validation
- Sectors: HRI, no-code/low-code robotics
- Tools/products/workflows: users specify tasks in natural language; system previews video plans; users approve/refine before execution; logs feed continual improvement
- Assumptions/dependencies: robust language grounding; UI/UX for non-experts; interpretability and fail-safe mechanisms
- Robustness to distribution shifts through adaptive feature-extraction timesteps
- Sectors: field robotics, outdoor logistics, agriculture
- Tools/products/workflows: adjust τf at runtime to favor coarse or fine features depending on scene conditions (e.g., lighting, occlusion); schedule adaptive action timesteps (τa) for stability
- Assumptions/dependencies: runtime monitors for scene quality; safe adaptation policies; validated switching criteria
- End-to-end generalist foundation for cross-sector workflows (retail shelf stocking, hospital logistics, farm picking)
- Sectors: retail, healthcare logistics, agriculture
- Tools/products/workflows: one backbone, many task heads; minimal per-task data; plug-and-play workflows for new environments
- Assumptions/dependencies: heterogeneous embodiments supported by adapters; comprehensive safety and compliance; standardized deployment pipelines
Notes on feasibility: Immediate applications are viable today with the released code/models, modest GPU resources, and small-to-moderate teleop datasets. Long-term applications depend on scaling pretraining to internet-scale video, integrating additional modalities, maturing safety/regulatory frameworks, and optimizing inference for real-time deployment on diverse hardware.
Glossary
- Adaptive Layer Normalization (AdaLN): A normalization layer that adapts its parameters based on conditioning inputs (e.g., timestep), often used in diffusion transformers to inject time information. Example: "Adaptive Layer Normalization (AdaLN)"
- Action DiT: A diffusion transformer specialized for generating action trajectories by denoising noisy action inputs under visual and state conditions. Example: "The action DiT relies on a third, independent timestep, ."
- Autoregressive backbones: Model architectures that generate outputs sequentially, conditioning each step on previous ones; common in language and some vision models. Example: "visual-language autoregressive backbones"
- Beta distribution: A continuous probability distribution on [0,1] used here to bias sampling of diffusion timesteps toward certain regions. Example: ""
- Bidirectional: A model property where information flows in both temporal directions, enabling conditioning on both past and future context during generation. Example: "a bidirectional Video Diffusion Transformer (DiT)"
- Cascaded framework: A design where multiple modules are arranged in sequence so outputs or features from one stage condition the next. Example: "in a unified cascaded framework."
- Causal video VAE: A video variational autoencoder that respects temporal causality, encoding/decoding sequences in a way that aligns with time order. Example: "a causal video VAE"
- Cross-attention: An attention mechanism where a query sequence attends to a separate context sequence to integrate external information. Example: "cross-attention layers to attend to the visual features"
- Denoising features: Intermediate representations extracted during the diffusion denoising process that encode partially reconstructed content. Example: "extracts intermediate denoising features from the video generation process"
- Dual flow-matching: A training objective that jointly learns two flow-matching processes (e.g., for video and action) with coordinated but decoupled timesteps and noise scales. Example: "a dual flow-matching objective"
- Egocentric camera: A first-person viewpoint camera mounted on the robot, capturing observations from the robot’s perspective. Example: "relying on only a single egocentric camera"
- Euler discretization: A first-order numerical method for solving differential equations by stepping along the derivative. Example: "We employ a first-order Euler discretization to perform the numerical integration."
- Extended-horizon: Tasks or evaluations that span many sequential steps, requiring long-term temporal reasoning and planning. Example: "extended-horizon capabilities"
- Flow matching: A generative modeling technique that learns a velocity field transporting noise to data along a probability path. Example: "Flow Matching (FM) aims to regress a time-dependent velocity field"
- Forward hook: A mechanism to intercept and extract intermediate activations from a neural network during the forward pass. Example: "a forward hook mechanism intercepts intermediate hidden activations"
- Generative video models (VGMs): Models that synthesize video sequences, learning spatiotemporal dynamics and implicit physics from data. Example: "video generation models (VGMs)"
- Hidden-state extraction: The process of retrieving internal activations from a generative model at a specific timestep to use as features. Example: "video prediction, hidden-state extraction, and action inference"
- Inverse dynamics: Predicting the actions required to achieve observed or predicted state transitions. Example: "train inverse dynamics models for action prediction"
- Latent space: A lower-dimensional representation where data are encoded for efficient modeling and generation. Example: "into a compact latent space"
- Numerical integration: Iteratively approximating solutions to differential equations via discrete steps. Example: "iterative numerical integration during inference"
- Ordinary Differential Equation (ODE): An equation involving a function and its derivatives with respect to a single variable; used to sample flows in diffusion/flow-matching models. Example: "solving the Ordinary Differential Equation (ODE)"
- Optimal transport displacement map: A mapping that transports one probability distribution to another with minimal cost, defining paths used in flow matching. Example: "constructed via an optimal transport displacement map."
- Probability path: A continuum of conditional distributions connecting noise and data used in flow-based generative training. Example: "conditional probability path"
- Probability flow: The continuous transformation of samples from noise to data along the learned velocity field. Example: "indicates the probability flow toward the clean future latent."
- Proprioceptive state: Internal sensor readings of a robot (e.g., joint positions/velocities) used for control. Example: "the robot's proprioceptive state "
- Scaling proxy: A surrogate training objective whose improvements correlate with better downstream task performance and data efficiency. Example: "video generation can serve as an effective scaling proxy"
- Spatiotemporal: Jointly relating to space and time, capturing how structures evolve over time in video. Example: "encode rich spatiotemporal structure"
- Teleoperated demonstrations: Human-controlled robot demonstrations collected for imitation learning. Example: "teleoperated demonstrations"
- Tri-timestep scheme: A design that decouples three timesteps for video prediction, feature extraction, and action inference to stabilize joint training. Example: "Tri-timestep scheme."
- Variational Autoencoder (VAE): A probabilistic encoder–decoder that learns latent representations for generative modeling. Example: "video VAE"
- Velocity field: A function specifying the instantaneous direction and speed for moving samples along a generative path. Example: "time-dependent velocity field"
- Velocity vector field: The vector-valued output of a model indicating how to update an entire action trajectory during denoising. Example: "predicts the velocity vector field of the action sequence"
- Video Diffusion Transformer (DiT): A transformer-based diffusion model for video generation that predicts velocities to denoise latent videos. Example: "Video Diffusion Transformer (DiT)"
- Visual foresight: Predicting future visual states to enable planning or control via imagined outcomes. Example: "visual foresight"
- Vision-Language-Action (VLA): Models that couple vision, language understanding, and action generation for robotic control. Example: "Vision-Language-Action (VLA) models"
- Vision-LLMs (VLMs): Models trained on paired images/videos and text to learn multimodal representations. Example: "Vision-LLMs (VLMs)"
- Zero-shot generalization: Successfully performing tasks in unseen conditions without task-specific training examples. Example: "strong zero-shot generalization."
Collections
Sign up for free to add this paper to one or more collections.