- The paper introduces a generative embedding paradigm that leverages LLM latent responses to transfer safety, reasoning, and alignment into the embedding space.
- The approach employs trainable special tokens and dual-objective optimization, yielding up to 9.3% MTEB score improvements over unsupervised baselines.
- Experiments demonstrate enhanced text retrieval, reduced harmful content retrieval, and decodable embeddings that support transparency and interpretability.
LLM2Vec-Gen: Generative Embeddings from LLMs
Introduction and Motivation
Embedding models are fundamental to modern NLP, serving as the backbone for semantic search, retrieval, clustering, and ranking tasks. Traditional approaches derive embeddings directly from the input text, but this paradigm exposes a representational gap: semantically diverse queries with overlapping meanings remain distant, while contrastive learning requires extensive labeled paired datasets. "LLM2Vec-Gen: Generative Embeddings from LLMs" (2603.10913) proposes a novel generative embedding paradigm—constructing embeddings not from the input, but from the latent representation of the LLM's response to the input. This enables transfer of LLM capabilities such as safety alignment and multi-step reasoning into the embedding space, with only minimal adaptation and unlabeled data requirements.

Figure 1: Illustration of the input-output gap. Semantically distinct queries q1 and q2 belong to the same category (anger). Input-centric encoders place them far apart (yellow), but their LLM responses are more similar, yielding closer representations (green). LLM2Vec-Gen encodes the response rather than the input.
Methodology
LLM2Vec-Gen augments a frozen LLM with trainable special tokens—partitioned into "thought" and "compression" roles—inserted as a suffix to the input. The methodology proceeds in several decoupled phases:
- Data Generation: Given only unlabeled queries, an LLM backbone produces candidate responses, simulating potential output texts for each input.
- Target Representation: The generated responses are fed into an unsupervised encoder teacher (LLM2Vec), generating distilled embedding targets without any contrastive supervision.
- Embedding Training: Special tokens are appended to the input. The output hidden states of the compression tokens are optimized with two objectives:
- Reconstruction (Lrecon): Decoding the compression tokens' states should reconstruct the LLM's actual response.
- Embedding Alignment (Lalign): The mean pooled, projected embeddings should match the teacher's embedding of the generated response.
Through this mechanism, the model learns to allocate the "embedding" space to capture the LLM's hypothetical response rather than the narrow semantics of the input text.
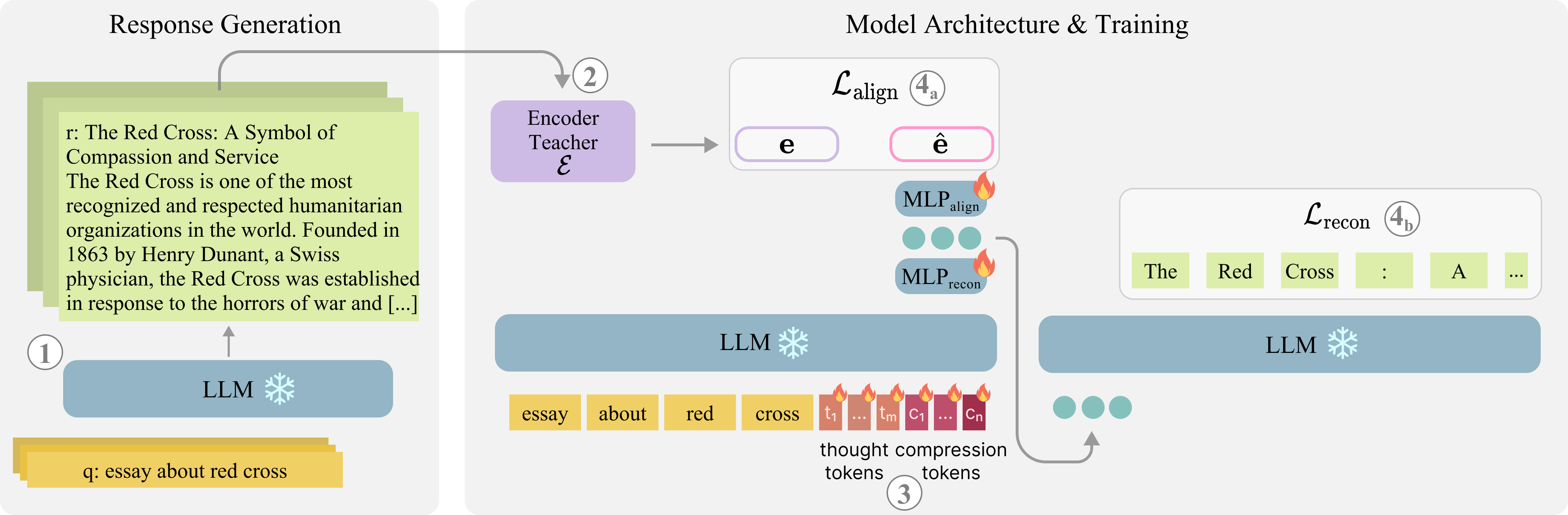
Figure 2: Overview of LLM2Vec-Gen: left—data generation and target embedding pipeline; right—append trainable tokens for dual-objective optimization with a frozen LLM backbone.
Empirical Evaluation
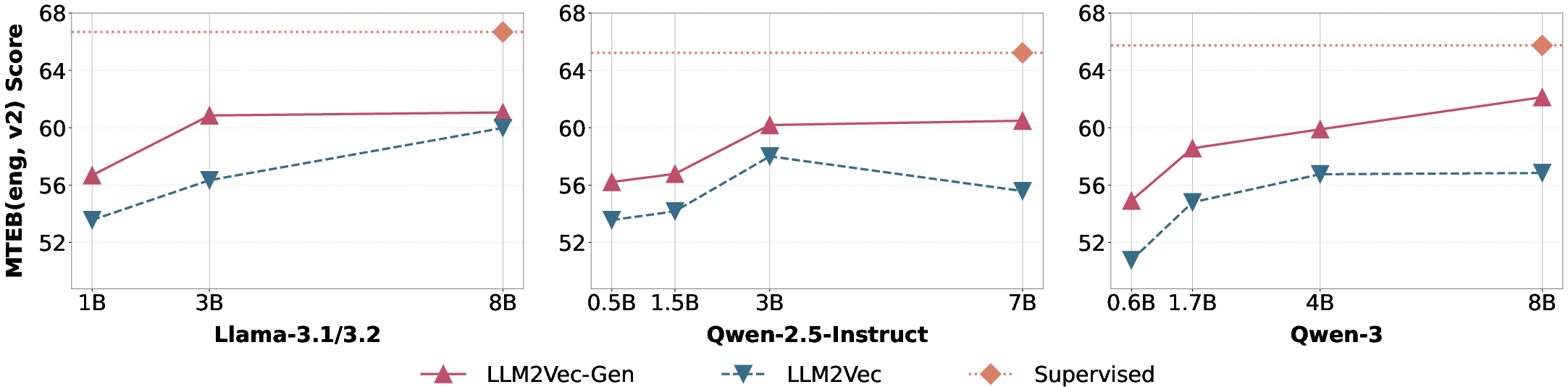
Experiments span multiple backbone families (Qwen-3, Qwen-2.5, Llama-3.x), model sizes (0.6B–8B), and target three core axes: general text embedding (MTEB v2), malicious content retrieval (AdvBench-IR), and reasoning-intensive retrieval (BRIGHT).
Key results:
An ablation study confirms both the necessity of dual-objective optimization and the importance of modeling both "thought" and "compression" token sets. Increasing the number of special tokens produces diminishing returns above 20, with optimal performance at the default split (10 thought, 10 compression).
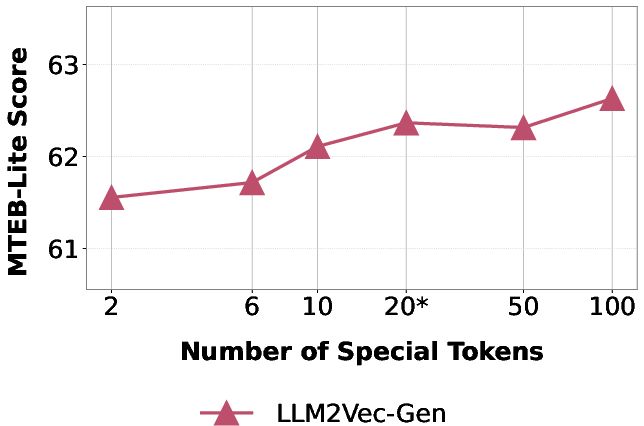
Figure 4: Impact of special token count on MTEB-Lite performance. Performance improves from 2 to 20 tokens (default setting), with marginal gains beyond.
Interpretability and Model Analysis
A salient aspect of LLM2Vec-Gen is that its latent embeddings remain decodable. Leveraging the reconstruction objective and the original LM tokens, the compression token representations can be mapped back to textual outputs that closely resemble or paraphrase the original LLM response. This enables fine-grained analysis via tools such as Logit Lens and LatentLens, confirming that the model embeds semantic content aligned with the LLM's actual answer rather than the underlying input. For potentially unsafe queries, the embeddings map to tokens expressing refusal or safety—explicitly demonstrating that the method internalizes safety alignment at the representational level.
Comparison to Prior Work and Theoretical Framing
LLM2Vec-Gen is orthogonal to contrastive or prompt-based unsupervised approaches (SimCSE, Echo, GenEOL), which operate exclusively on the input, and to retrieve-then-generate methods (HyDE, InBedder, GIRCSE), which incur inference-time generation cost or require labeled training data. LLM2Vec-Gen's distilled generative foresight is conceptually analogous to JEPA [sobal2022jointembeddingpredictivearchitectures], but uniquely applies a dual-objective with frozen backbone, and distills latent space representations, bypassing the need for paired or contrastive data.
Practical and Theoretical Implications
This work demonstrates that large-scale LLMs can be efficiently repurposed as state-of-the-art embedders in self-supervised settings, with a parameter-efficient adaptation (only special tokens/projections learned, backbone frozen). At inference, a single forward pass with appended special tokens suffices for fast embedding, eliminating the cost of explicit response sampling adopted in generation-first retrieval schemes.
The generative embedding formulation produces robust, safety-aligned, and reasoning-capable representations that are especially valuable for deployed, safety-critical retrieval and RAG scenarios. Furthermore, the interpretability introduced by the reconstruction channel enables transparency and model auditing, supporting deployment in regulated or high-stakes domains.
The JEPA link opens the possibility for JEPA-style self-prediction and latent chaining, while the decodable latent tokens suggest a future direction for high-bandwidth, interpretable communication protocols among LLM-based agents—potentially enabling latent message passing with semantic decoding and human oversight.
Conclusion
"LLM2Vec-Gen" (2603.10913) presents a rigorous and scalable approach to generative embeddings, re-founding self-supervised text encoding on latent output representations rather than input modeling. This bridges the classical input-output gap, transfers critical LLM characteristics (including safety, reasoning, and alignment), and achieves SOTA performance in the absence of supervision. The method's design—frozen backbone, efficient distillation, robust interpretability—positions generative embeddings as a practical and theoretically motivated foundation for the next generation of flexible, safe, and powerful text encoders.