A Systematic Study of Pseudo-Relevance Feedback with LLMs
Abstract: Pseudo-relevance feedback (PRF) methods built on LLMs can be organized along two key design dimensions: the feedback source, which is where the feedback text is derived from and the feedback model, which is how the given feedback text is used to refine the query representation. However, the independent role that each dimension plays is unclear, as both are often entangled in empirical evaluations. In this paper, we address this gap by systematically studying how the choice of feedback source and feedback model impact PRF effectiveness through controlled experimentation. Across 13 low-resource BEIR tasks with five LLM PRF methods, our results show: (1) the choice of feedback model can play a critical role in PRF effectiveness; (2) feedback derived solely from LLM-generated text provides the most cost-effective solution; and (3) feedback derived from the corpus is most beneficial when utilizing candidate documents from a strong first-stage retriever. Together, our findings provide a better understanding of which elements in the PRF design space are most important.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “A Systematic Study of Pseudo-Relevance Feedback with LLMs”
What is this paper about?
This paper looks at how to make search engines better by using LLMs like the ones behind chatbots. The authors focus on a technique called “pseudo‑relevance feedback” (PRF). That’s a fancy way of saying: after you type a search, the system uses some extra “hints” from documents or generated text to rewrite your question so the next search finds better results.
They ask: Where should those hints come from, and how should we combine them with the original question?
The main goal, in plain questions
The researchers explored four simple questions:
- If we get hints from a particular place, does the way we mix those hints into the question matter?
- Is it better to use hints from real documents in the library (the “corpus”) or from text made up by an LLM (like a make-believe answer)?
- If we mix both kinds of hints—real documents and LLM-made text—do we get even better results? What’s the best way to mix them?
- How fast are these different methods? (Speed matters in real systems.)
How did they study it?
Think of searching like asking a librarian for a book. You ask a question. The librarian finds some books. Then you refine your question using clues from those books, and ask again.
- Feedback source = where your clues come from:
- From the library’s books (the corpus)
- From an LLM that writes a pretend answer passage
- From both
- Feedback model = how you mix those clues into your question:
- For keyword-based search (BM25), they used classic methods (Rocchio and RM3) that decide how much to boost each word.
- For meaning-based search (dense retrievers like Contriever), they tried:
- Simple average: blend the original question and hint vectors like mixing smoothie ingredients evenly.
- Rocchio-style mix: give a chosen amount of weight to the original question and the hints, instead of averaging blindly.
They tested five popular PRF methods across 13 different search tasks (from the BEIR benchmark), including topics like news, science, and medical questions. They compared three types of search engines:
- BM25 (keyword matching—the classic way),
- Contriever (dense/meaning-based, unsupervised),
- Contriever MS-MARCO (dense/meaning-based, trained on a big dataset).
They kept things fair by controlling the number of hint documents and terms across methods.
Key methods they studied (with simple names):
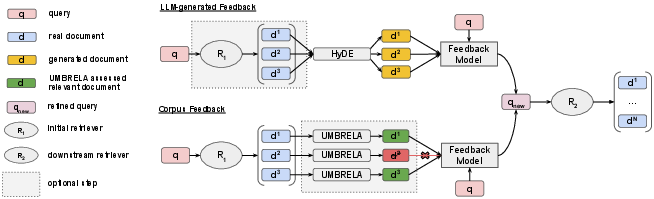
- Umbrela: The LLM reads the top documents and judges which ones are relevant (hints from real docs).
- HyDE: The LLM writes pretend answer passages (hints from LLM-generated text).
- PRF-HyDE: Like HyDE, but the LLM also sees some real documents as examples while writing.
They also tried combining hints from Umbrela and HyDE together.
What did they find, and why it matters?
Here are the main takeaways:
- The way you mix hints into the question really matters (especially for LLM-generated hints).
- For keyword search (BM25), the classic Rocchio method often beat RM3 when using LLM-generated hints.
- For dense/meaning search, Rocchio-style mixing beat simple averaging when using LLM-generated hints.
- Translation: don’t just throw hints in—combine them carefully.
- LLM-only hints are often the best “bang for your buck.”
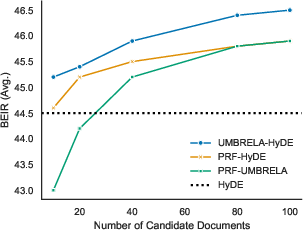
- Using only LLM-generated text (like HyDE) often beat using only corpus documents (like Umbrela), and it was typically faster and cheaper.
- Exception: If your first search engine is already very strong and you’re using BM25, then using real-doc hints can catch up or win.
- Mixing both sources of hints helps—especially for meaning-based (dense) search.
- For dense retrievers, combining LLM-made hints and real-doc hints (by simply adding them together) consistently improved results.
- For BM25, mixing can help too, but mostly when the real documents are good quality. The exact way you mix matters less—what matters is having strong documents.
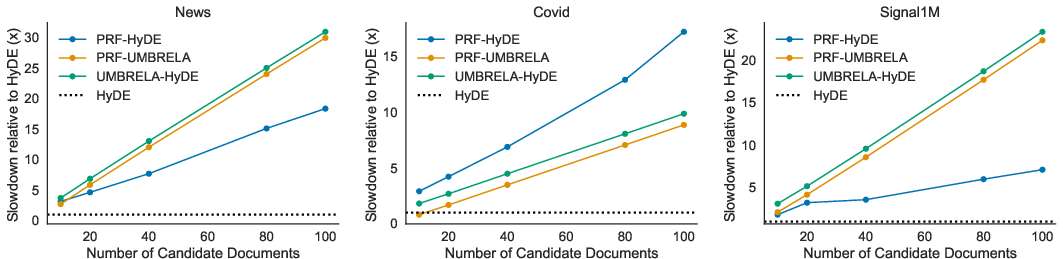
- Speed matters: LLM-only is faster.
- LLM-only hints were the most efficient.
- When you involve real documents, the system has to fetch, read, and judge more content, which slows things down. The more documents you judge, the slower it gets.
Bonus insights the paper noticed:
- A strong, simple baseline: BM25 + LLM-only hints is hard to beat. You can do better by scoring more real documents or using a stronger first search, but that costs time.
- A neat surprise: Real document terms retrieved using HyDE (i.e., documents found after using HyDE to search) were sometimes better than HyDE’s own generated terms. In other words, the LLM can help you find better real documents—and those documents give better clues than the LLM’s text alone.
- Dense retrievers didn’t benefit as much from PRF as expected. In some tests, BM25 with PRF beat a stronger dense model with PRF, even though BM25 started worse. This suggests dense models aren’t yet using feedback as effectively as they could.
Why does this matter in the real world?
- If you want a practical, fast boost to search quality, using LLM-generated hints (like HyDE) is a great default. It’s effective and efficient.
- If you can afford more time or have a strong first-step search, then adding real documents into the mix (or combining both sources) can deliver extra gains—especially for dense retrievers.
- Designers of search systems should pay attention to the feedback model (how they mix the hints), not just where the hints come from.
- The results suggest that dense/meaning-based search engines could be improved by better ways of using feedback. There’s room for future work here.
In short: this study helps researchers and engineers pick the right combination of “where hints come from” and “how to use them,” balancing accuracy and speed, to build better, smarter search.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps that remain unresolved, prioritized toward issues future researchers can directly act on:
- Generalization across LLMs is untested: all experiments use a single backbone (Qwen3-14B). It remains unknown how results change with different architectures, sizes, instruction-tuning levels, or proprietary models (e.g., GPT-4, Llama 3, Mistral, Claude).
- Prompt and generation sensitivity is not explored: HyDE uses one prompt, temperature 0.7, and length 512 without ablations. The effects of prompt templates, sampling strategies, number of generations, and decoding settings on PRF effectiveness are open.
- Only one round of PRF is evaluated: the impact of iterative/multi-turn PRF (with stopping criteria and budgets) on effectiveness and latency remains unquantified.
- Feedback document count and selection policy are fixed and simplistic: a hard cap of eight feedback docs and Umbrela’s “max-score only” heuristic are used. Threshold tuning, top-n selection, and diversity-aware selection strategies (and their interaction with k and latency) are not studied.
- Feedback content types are limited to hypothetical documents: the efficacy of LLM-generated keywords, entities, summaries, questions, or mixed granularities (sentence- vs passage-level) as feedback is not evaluated.
- Sparse feedback models are restricted to RM3 and Rocchio: newer or adaptive schemes (e.g., MuGI-style adaptive query weighting), alternative interpolation strategies, term pruning policies, and regularization are not systematically compared.
- Negative feedback is not used: Rocchio and vector updates include only positive feedback. Incorporating non-relevant docs (from Umbrela labels or LLM judgments) to subtract terms/vectors is unexplored.
- Dense PRF underperforms but cause is unclear: the paper observes BM25 benefits more from PRF than dense retrievers, even with better starting points. Root causes (e.g., centroid drift, embedding collapse, matching function limits) and remedies are not analyzed.
- Stronger or alternative dense retrievers are not tested: results are limited to Contriever and Contriever MSM. The finding that dense PRF lags may not hold for modern encoders (e.g., E5/BGE families, GTR, Jina, Voyage, OpenAI text-embedding-3, ColBERTv2, TAS-B, GTE).
- Hybrid pipelines are not considered: how LLM-based PRF interacts with sparse–dense fusion methods (e.g., SPLADE, uniCOIL, hybrid reranking) remains unknown.
- Dataset scope is limited: only 13 English, low-resource BEIR tasks are used. Generalization to high-resource benchmarks (e.g., MS MARCO), multilingual corpora, long-document settings, code/legal domains, or web-scale retrieval is untested.
- Metric coverage is narrow: only nDCG@20 is reported. Effects on recall@k, MAP, early precision, or calibration, and trade-offs across metrics are unmeasured.
- Latency and cost are only partially characterized: plots show relative latency, but absolute token usage, GPU/CPU time, memory, throughput, and dollar costs (including scaling with k and context length) are not reported. No Pareto analysis of effectiveness vs cost.
- LLM judging reliability is unverified: Umbrela’s 0–3 labels are taken as-is with a max-score selection rule. Calibration, threshold choice, inter-prompt consistency, and agreement with human relevance are not assessed.
- Per-query adaptivity is absent: there is no policy to decide whether/when to apply PRF, which source/model to use, how many docs to judge, or how many expansions to generate, given query type and budget.
- In-context example curation is simplistic: PRF-HyDE uses top-10 BM25 candidates (truncated to 256 tokens). The impact of example diversity, redundancy control, chunk size, selection heuristics, and ordering is not studied.
- Combination strategies are narrow: only independent concatenation (Umbrela) and in-context prompting (PRF-HyDE) are evaluated. Weighted/learned late fusion, gating, de-duplication, bias correction, and joint optimization are open.
- Hyperparameter robustness is unclear: α, β, λ and the 128-term cap are fixed. No sweeps or sensitivity analyses test stability across datasets, retrievers, or preprocessing/tokenization choices.
- Scalability with candidate set size is only examined for BM25: the k–effectiveness–latency trade-off for dense retrievers, as well as adaptive stopping rules for LLM judging, are unreported.
- Indexing granularity effects are not studied: the influence of document vs passage indexing, document length distributions, chunking strategies, and their latency consequences is open.
- Fairness of “information budgets” is not guaranteed: although the number of feedback docs is controlled, generated documents (512 tokens) and corpus passages have different lengths and pruning behaviors; the impact of equalizing token budgets is unknown.
- No error analysis is provided: there is no breakdown of which query types/datasets benefit or suffer under each source/model, nor a taxonomy to guide method selection.
- Interaction with cross-encoder rerankers is untested: combining LLM-PRF with reranking models (e.g., mono/duo-T5, ColBERT re-ranking) and measuring marginal benefits is left open.
- Data contamination risks are unaddressed: LLM parametric knowledge may include BEIR documents/queries; the extent to which this biases LLM-generated feedback (and comparisons to corpus-only feedback) is not assessed.
- Robustness and safety are not evaluated: hallucinations in expansions, domain shift, adversarial queries, and harmful content risks (and their effects on retrieval drift) are not analyzed.
- Real-world deployment aspects are missing: caching, batching, quantization, engine choice (vLLM vs others), and hardware variability are not studied; robustness of conclusions across production settings is unknown.
- Open question (explicit in paper): whether the observed gap—BM25 exploiting PRF better than dense retrievers—persists with stronger dense models and alternative PRF operators remains unanswered.
Practical Applications
Immediate Applications
Below are actionable, sector-linked uses you can deploy now by leveraging the paper’s findings on feedback source (LLM-only, corpus-only, combined) and feedback models (Rocchio/RM3 for sparse; Rocchio vs. average vector for dense). Each item includes suggested tools/workflows and feasibility notes.
- Enterprise and Workplace Search (Intranets, Document Management)
- What to do: Improve retrieval quality in low- or zero-training settings by adding LLM-based pseudo-relevance feedback (PRF).
- For BM25 backends (e.g., Lucene/Elasticsearch/OpenSearch): Prefer classic feedback models over string concatenation. Use RM3 or Rocchio to integrate up to ~128 feedback terms, and generate expansion text via LLM-only hypothetical documents (HyDE) when strong first-stage results aren’t available. If you have a strong first-stage retriever, add corpus feedback using LLM relevance judgments (Umbrela) or combine LLM and corpus feedback via independent concatenation (Umbrela).
- For dense systems (e.g., FAISS, Milvus, Vespa): Replace average vector updates with the Rocchio vector update when using LLM-generated feedback. Combine LLM-only and corpus-derived vectors by concatenation for best gains.
- Tools/workflows: Pyserini/Anserini for PRF; vLLM or other inference servers for LLMs; Qwen3-14B (as in the paper) or equivalent; integration with Elasticsearch via custom BM25/RM3/Rocchio query boosts.
- Assumptions/dependencies: Access to an LLM; compute budget for inference; index supports term-level boosts (BM25) or vector blending; data privacy constraints for LLM prompts.
- RAG Pipelines for Customer Support and Knowledge Bases (Software, SaaS)
- What to do: Insert an LLM-only PRF step before retrieval to boost recall in retrieval-augmented generation.
- Use HyDE to generate ~8 hypothetical passages per query, then update the query with Rocchio (dense) or RM3/Rocchio (BM25).
- If latency budget allows and a strong first-stage retriever exists, augment with corpus feedback via Umbrela (LLM document judgments) or combine LLM+corpus vectors for dense backends.
- Tools/workflows: LangChain/LlamaIndex pipelines; route queries to PRF module based on latency SLA; cache expansions for frequent queries.
- Assumptions/dependencies: Token limits and latency budgets; cost-effective LLM access; robust first-stage retriever if adding corpus feedback.
- Biomedical and Scientific Literature Search (Healthcare, Pharma, Academia)
- What to do: For low-resource or new domains, deploy LLM-only PRF (HyDE) with Rocchio to enhance recall on tasks similar to TREC-Covid and SciFact. If a strong retriever is available, add corpus feedback (Umbrela) or combine both sources.
- Tools/workflows: PubMed/PMC indices in Lucene/Elasticsearch; Pyserini BM25 + RM3/Rocchio; vLLM-based generation of hypothetical answer documents; optional Contriever MSM for candidate doc retrieval.
- Assumptions/dependencies: Regulatory/privacy concerns for LLM usage; domain adaptation may improve further but not strictly required; long documents may increase latency.
- Legal eDiscovery and Compliance Search (Legal, RegTech)
- What to do: Deploy LLM-only PRF with BM25 to raise recall for evidence retrieval; if you can afford higher latency, have LLM judge top-20–40 candidates (Umbrela) to surpass LLM-only gains, then use RM3/Rocchio for query reformulation.
- Tools/workflows: On-prem LLM inference for confidentiality; Lucene-based PRF; policy-driven toggles between HyDE and Umbrela based on case urgency.
- Assumptions/dependencies: Strict data governance; compute and cost constraints; longer corpora increase latency for corpus-based feedback.
- News, Fact-Checking, and Misinformation Tracking (Media, Nonprofits)
- What to do: Use LLM-only PRF to retrieve evidence passages for claims (e.g., Climate-FEVER, SciFact). If available, combine with corpus feedback judged by an LLM. For dense retrieval, use Rocchio vector update and combine independently derived vectors (LLM+corpus).
- Tools/workflows: Evidence retrieval modules for fact-checkers; scheduled batch processing of trending claims with cached expansions.
- Assumptions/dependencies: Access to current news corpora; LLM inference limits; latency sensitivity for real-time verification.
- Financial Research and QA (Finance)
- What to do: For FiQA-style queries, use LLM-only PRF for immediate improvements; if strong candidate documents exist (e.g., supervised dense retriever), prioritize combining LLM+corpus feedback with concatenation for dense, or RM3/Rocchio for BM25.
- Tools/workflows: Term-weighted query reformulation in Lucene/OpenSearch; budget-aware strategy to fall back to LLM-only in peak times.
- Assumptions/dependencies: Data confidentiality; cost-aware LLM selection; heterogeneity of financial documents.
- Academic Search and Library Portals (Higher Ed)
- What to do: Integrate PRF modules into existing search portals with BM25 baselines. Start with LLM-only expansions (HyDE) and RM3/Rocchio; add corpus feedback when you have high-quality initial retrieval or can judge more candidates.
- Tools/workflows: Pyserini/Anserini; open-source code from the paper; QueryGym for benchmarking.
- Assumptions/dependencies: Lightweight deployment preferred in campus IT; fair-use/terms of service for LLMs.
- Personal Knowledge Bases and Note Search (Daily Life)
- What to do: In tools like Obsidian/Notion or local wikis, generate short hypothetical “answer passages” from the query and use them to find better matches in your notes (BM25 or vector DB). Use Rocchio for vector queries; RM3/Rocchio for term-based search.
- Tools/workflows: Local LLM (e.g., small Qwen/Mistral) to preserve privacy; simple scripts to boost BM25 queries with expansion terms.
- Assumptions/dependencies: Local model performance; device compute constraints.
- Search Stack Hardening and A/B Testing (Software Engineering)
- What to do: Establish a PRF “switchboard” that selects among HyDE, Umbrela, or combined methods based on query class and latency budgets. Use findings: LLM-only is most efficient; corpus feedback helps when judging more candidates or with strong first-stage retrievers; dense retrievers benefit from Rocchio and combined sources.
- Tools/workflows: Feature flags and traffic splitting; monitoring nDCG/Recall@k; SLA-aware routing.
- Assumptions/dependencies: Observability and metrics infra; ops readiness for LLM inference.
- Latency-Aware Retrieval Policies (Ops/Platform)
- What to do: Implement dynamic policies: default to HyDE for low-latency queries; switch to Umbrela (k≈20–40) or combined feedback for high-stakes queries where extra latency is acceptable.
- Tools/workflows: Query classification; per-route latency budgets; autoscaling LLM inference.
- Assumptions/dependencies: Clear SLAs; autoscaling infrastructure; cost modeling.
Long-Term Applications
These directions require further research, scaling, or product development, building on the paper’s insights about feedback sources, feedback models, and efficiency-effectiveness trade-offs.
- Dense Retrievers Trained to Exploit PRF Better (Search, AI Platforms)
- What to build: New dense encoders or adapters explicitly trained to leverage PRF signals (vectors and terms), addressing the paper’s finding that dense retrievers underutilize PRF compared to BM25.
- Dependencies: Training data and infrastructure; benchmarking suites (e.g., BEIR, QueryGym); model distillation pipelines.
- Auto-Selection of PRF Strategy per Query (Enterprise, E-commerce)
- What to build: A controller that predicts when to use LLM-only, corpus-only, or combined PRF, how many candidates to judge, and which feedback model (Rocchio/RM3/avg) to apply, given query type and latency budget.
- Dependencies: Historical logs; model-based policy learning; latency/cost predictors.
- PRF for Multilingual and Low-Resource Languages (Gov, Global NGOs, Education)
- What to build: Language-agnostic PRF modules with LLMs fine-tuned for multilingual generation and relevance judgment; test across BEIR-like multilingual tasks.
- Dependencies: Multilingual LLMs; diverse corpora; tokenization and indexing support across languages.
- Offline or Hybrid PRF to Reduce Latency (Enterprise, Media)
- What to build: Precompute and cache LLM expansions for frequent queries or query templates, then update online with light-weight Umbrela judging when needed. For product catalogs, maintain catalog-informed hypothetical documents per category.
- Dependencies: Query distribution stability; cache invalidation strategies; incrementally updated indices.
- Privacy-First PRF in Sensitive Domains (Healthcare, Legal, Finance)
- What to build: On-prem LLM relevance labeling and expansion generation with secure logging; fine-tuned smaller models that approximate Umbrela/HyDE to minimize data egress.
- Dependencies: High-quality local models; compliance reviews; MLOps for secure deployments.
- Human-in-the-Loop PRF and Explainability (All Sectors)
- What to build: UI surfaces that expose expansion terms/documents to users for confirmation/edits; show the effect of PRF on ranking. Useful in regulated or high-stakes scenarios.
- Dependencies: UX research; interpretable scoring; audit trails.
- Stronger Retriever–PRF Synergies (Search, AI Research)
- What to build: Co-design PRF with state-of-the-art retrievers (e.g., late-interaction or modern dense models), given evidence that BM25 can outperform dense in PRF scenarios with identical feedback.
- Dependencies: Access to SOTA retrievers; unified evaluation harnesses; cost-effective experimentation.
- Structured Feedback Objects and Index-Time Augmentation (E-commerce, Catalogs)
- What to build: Instead of raw text, standardize feedback as structured facets/entities and integrate RM3/Rocchio-like updates with facet-aware indexing and ranking.
- Dependencies: Entity extraction; facet-aware indices; schema evolution.
- Model-Distilled PRF (Edge/Low-Compute Use)
- What to build: Distill LLM judgment and expansion behaviors (Umbrela/HyDE) into smaller models or rules that approximate PRF outcomes with lower latency and cost.
- Dependencies: Distillation datasets; evaluation for parity and bias; deployment on constrained hardware.
- Context Diversity Optimization for In-Context PRF (All Sectors)
- What to build: Selection strategies that maximize diversity (not just top-k relevance) of in-context examples for PRF-HyDE to avoid redundancy and improve gains with stronger initial retrievers.
- Dependencies: Diversity metrics; selection algorithms; LLM prompting research.
Cross-Cutting Assumptions and Dependencies
- LLM access and costs: LLM-only PRF (HyDE) is most efficient; adding corpus feedback increases latency in proportion to candidate count and document length.
- Infrastructure: Availability of Lucene/Elasticsearch/OpenSearch (for RM3/Rocchio) or vector DBs (for dense); GPU/CPU resources for vLLM or equivalent inference.
- Initial retriever quality: Corpus feedback shines when a strong first-stage retriever provides high-quality candidates or when judging more candidates (k≈20–40), at higher latency.
- Domain and privacy constraints: Sensitive domains may require on-prem or small LLMs; content length and language affect performance and costs.
- Hyperparameters and defaults (from the study): ~8 hypothetical documents; max 128 feedback terms; Rocchio often preferred for LLM-generated feedback; RM3 competitive for corpus-only BM25 PRF; temperature ≈0.7 and max LLM output length ≈512 tokens are reasonable starting points.
These applications translate the paper’s core insights into deployable practices and longer-range R&D roadmaps, with explicit consideration of feedback source, feedback model, retriever type, and latency-cost trade-offs.
Glossary
- Anserini: An open-source information retrieval toolkit built on Lucene, used to implement retrieval and PRF experiments. "our work directly builds on existing PRF infrastructure present in Anserini"
- average vector update: A dense PRF method that averages the query vector and feedback document vectors to form an updated query embedding. "have primarily utilized a simple average vector update"
- BEIR: A benchmark suite of information retrieval datasets used to evaluate retrieval systems. "Across 13 low-resource BEIR tasks"
- BM25: A classical sparse retrieval function based on term frequency and inverse document frequency with length normalization. "With BM25, various approaches have been proposed"
- Contriever: An unsupervised dense retriever model that encodes queries and documents into embeddings for similarity search. "BM25, Contriever, and Contriever MS-MARCO"
- Contriever MS-MARCO (Contriever MSM): A supervised fine-tuned variant of Contriever trained on MS MARCO to improve retrieval quality. "its supervised fine-tuned variant, Contriever MS-MARCO (Contriever MSM)"
- corpus: The document collection against which retrieval is performed and from which feedback may be drawn. "feedback derived from the corpus is most beneficial when utilizing candidate documents from a strong first-stage retriever"
- CSQE: A corpus-guided query expansion method combining corpus evidence with LLM-generated expansions. "motivated by the approach used in CSQE"
- dense retriever: A retriever that represents queries and documents as dense vectors and ranks via vector similarity. "with dense retrievers, LLM PRF methods have primarily utilized a simple average vector update"
- downstream retriever: The second-stage retriever (e.g., R2) that consumes the updated query after PRF. "it only has access to the downstream retriever ()"
- few-shot: A setting where an LLM is prompted or trained with a small number of examples to perform a task. "strong few-shot and zero-shot capabilities"
- feedback model: The algorithm that uses feedback text or vectors to update the query representation in PRF. "the feedback model is how this feedback is used to update the query representation"
- feedback source: The origin of the feedback (e.g., corpus documents, LLM-generated text, or both) used to refine the query. "the feedback source refers to where the feedback -- i.e., the terms or vectors used to improve the query -- comes from"
- GAR: An early LLM-based query expansion approach that generates helpful expansion text. "One of the initial methods in this space was GAR"
- HyDE: A method that generates hypothetical answer passages via LLM prompting and uses their vectors for PRF. "HyDE samples hypothetical answer documents"
- in-context examples: Reference passages included in the LLM prompt to guide generation. "as in-context examples"
- initial retriever: The first-stage retriever (e.g., R1) that produces candidate documents for PRF. "an initial retriever, , produces a ranked list of documents"
- LLMs: High-capacity neural LLMs used for generation and reasoning in PRF pipelines. "have increasingly begun to leverage LLMs"
- Lucene: A search library providing indexing and retrieval primitives used by Anserini/Pyserini. "custom Lucene queries are constructed in Pyserini"
- LLMF: A method that uses LLMs to select, rather than generate, documents for feedback in PRF. "ReDE-RF~\cite{jedidi2024zero} and LLMF~\cite{otero2026llm} instead leveraged LLMs as a tool for selecting"
- MuGI: A method that adaptively reweights query repetitions based on expansion length for BM25. "MuGI~\cite{zhang-etal-2024-exploring-best} then observed the importance of a proper amount of query repetitions"
- nDCG@20: Normalized Discounted Cumulative Gain at rank 20; a measure of ranking effectiveness. "For metrics, we report nDCG@20."
- parametric knowledge: Information stored within an LLM’s parameters, used to generate feedback without accessing a corpus. "based on the LLM's parametric knowledge"
- PRF-HyDE: A HyDE variant that prompts the LLM with corpus documents as in-context examples before generating feedback. "The second method, which we refer to as PRF-HyDE"
- pseudo-relevance feedback (PRF): A technique that assumes top-ranked documents are relevant and uses them to refine the query. "Pseudo-relevance feedback (PRF) methods built on LLMs"
- Pyserini: A Python IR toolkit built on Anserini for reproducible retrieval experiments. "custom Lucene queries are constructed in Pyserini"
- Query2Doc: A method that generates document-like expansions from queries using LLMs. "Approaches like HyDE and Query2Doc focused on hypothetical answer document generation"
- QueryGym: A standardized toolkit that implements and compares LLM-based PRF methods. "released QueryGym, which standardizes the implementation of these various methods into a singular Python toolkit"
- Qwen3-14B: A 14B-parameter LLM used as the backbone model for generation in the experiments. "Qwen3-14B~\cite{yang2025qwen3} served as the backbone LLM"
- ReDE-RF: A method that employs LLMs to select top-ranked documents from the initial retriever for feedback. "ReDE-RF~\cite{jedidi2024zero} and LLMF~\cite{otero2026llm} instead leveraged LLMs as a tool for selecting"
- RM3: A classical relevance model for PRF that interpolates the original query with a feedback term model. "The next feedback model we consider is RM3"
- Rocchio algorithm: A classic PRF algorithm that linearly combines the query and feedback document term weights. "The first is the Rocchio algorithm"
- Rocchio dense vector update: Applying Rocchio’s formulation in embedding space to update the query vector for dense retrieval. "we extend our evaluation to the Rocchio dense vector update"
- sparse retriever: A retriever that represents texts as sparse term vectors and relies on exact term matching (e.g., BM25). "with sparse retrievers like BM25"
- string concatenation: A heuristic PRF strategy that appends generated expansions (and possibly repeated queries) to form a longer query string. "via a simple string concatenation"
- ThinkQE: An approach where an LLM iteratively refines the query representation through multiple interactions with the corpus. "ThinkQE~\cite{lei-etal-2025-thinkqe} proposed an approach"
- top-k: The set of the k highest-ranked candidate documents considered for feedback. "top- candidate documents"
- Umbrela: An LLM-based assessor that labels candidate documents for relevance to select feedback from the corpus. "we utilize Umbrela to generate a relevance label"
- vLLM: A high-throughput inference engine for efficient LLM serving used during experiments. "LLM inference was performed using vLLM"
- zero-shot prompting: Prompting an LLM to perform a task without any task-specific examples. "zero-shot prompting an LLM"
Collections
Sign up for free to add this paper to one or more collections.