Understanding by Reconstruction: Reversing the Software Development Process for LLM Pretraining
Abstract: While LLMs have achieved remarkable success in code generation, they often struggle with the deep, long-horizon reasoning required for complex software engineering. We attribute this limitation to the nature of standard pre-training data: static software repositories represent only the terminal state of an intricate intellectual process, abstracting away the intermediate planning, debugging, and iterative refinement. To bridge this gap, we propose a novel paradigm: understanding via reconstruction. We hypothesize that reverse-engineering the latent agentic trajectories -- the planning, reasoning, and debugging steps -- behind static repositories provides a far richer supervision signal than raw code alone. To operationalize this, we introduce a framework that synthesizes these trajectories using a multi-agent simulation. This process is grounded in the structural realities of the source repositories (e.g., dependency graphs and file hierarchies) to ensure fidelity. Furthermore, to guarantee the logical rigor of the synthetic data, we employ a search-based optimization technique that iteratively refines the Chain-of-Thought (CoT) reasoning to maximize the likelihood of the ground-truth code. Empirical results demonstrate that continuous pre-training on these reconstructed trajectories significantly enhances Llama-3-8B's performance across diverse benchmarks, including long-context understanding, coding proficiency, and agentic capabilities.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Understanding by Reconstruction: A Simple Explanation
What is this paper about?
This paper is about teaching AI models to be better at real software development, not just writing short pieces of code. The authors say that most training data (finished code on GitHub) is like seeing only the final scene of a movie. You don’t see the planning, the mistakes, and the fixes that happened along the way. Their idea: if we can rebuild the “behind-the-scenes” steps that led to the final code, the AI will understand code much more deeply.
What questions did the researchers ask?
They focused on three simple questions:
- Can we turn a finished code project into a step-by-step story of how it might have been built (planning, reading files, writing code, debugging)?
- If we train a model on these step-by-step “build stories,” will it become better at long projects, reasoning, and coding?
- Can we improve these “build stories” so they’re logical and truly help the AI learn?
How did they do it?
The team built a system to “reverse” the software process—starting from a complete project and reconstructing how someone might have made it.
Here’s the idea in everyday terms:
- Imagine you see a completed LEGO model (the repository). You don’t have the instructions (the development process). The system tries to recreate those instructions: plan which parts to build first, check what pieces are already used, and then assemble step by step.
They did this in four main parts:
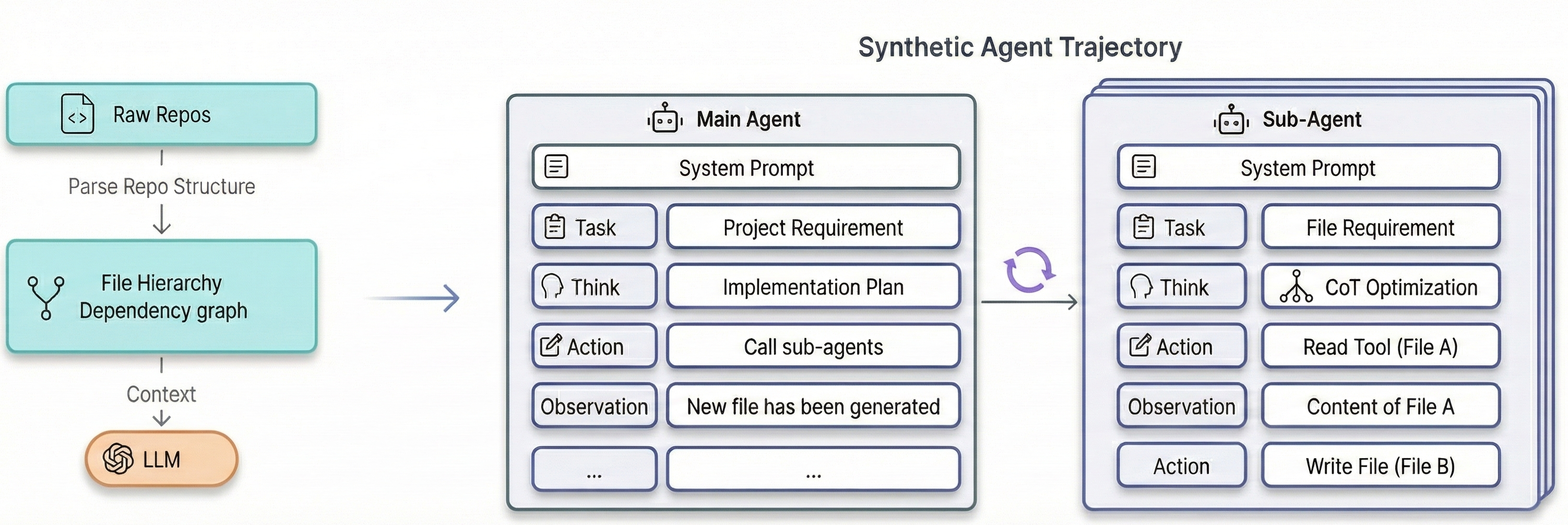
- Multi-agent simulation (a team of virtual developers)
- A Main Agent creates a high-level plan (what files to make and in what order).
- Several Sub-Agents each handle one file. They:
- “Read” other files to gather context (like checking the manual).
- “Write” the code for their assigned file.
- Grounding with real project facts
- To avoid make-believe steps (“hallucinations”), the system injects real data from the project:
- The true file and folder structure (like the project’s map).
- Which files depend on which (a dependency graph—like “who needs whom”).
- The important parts inside each file (classes/functions from the code’s blueprint).
- When an agent says “read this file,” the system swaps in the actual file content from the real project.
- When an agent “writes” a file, the final content is set to the real file from the project.
- Improving the “thinking” using search
- The system treats the agents’ reasoning like a draft plan. It tries multiple alternative versions of each reasoning step and keeps the ones that make the real code easier for the model to predict.
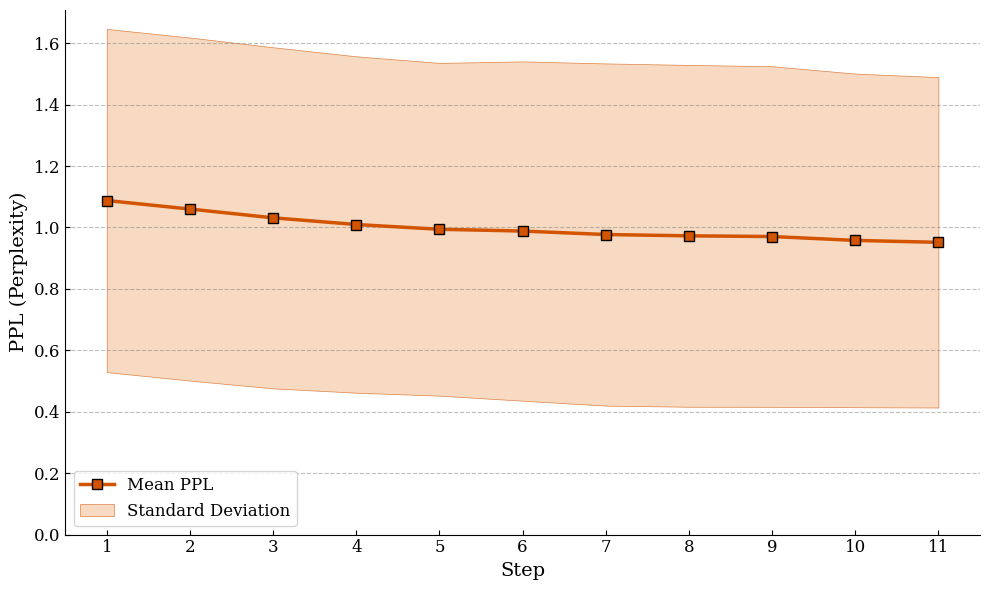
- A simple way to think about this: the model measures how “surprised” it is by the code after reading the reasoning. Less surprise means the reasoning is better. This surprise score is called perplexity—lower is better.
- Training with smart formatting
- They flatten the whole process into one long, readable sequence (so the model can read it start to finish).
- They only train the model to predict the agents’ thoughts and actions—not the tool feedback—so the model learns to think and decide, rather than memorizing answers.
What did they find?
Training on these reconstructed “how it was built” stories helped a lot:
- Better at long documents and big contexts
- The model got stronger at tasks that need remembering and using information across very long inputs (like reading a long manual and finding the right detail).
- Better at coding
- On coding tests (like HumanEval and long-context coding tasks), the model did better than models trained on raw code only. Learning the process (planning + writing) beats just reading finished code.
- Better reasoning skills transfer
- Even on general reasoning and math puzzles, the model saw some gains. This suggests that step-by-step logical training helps beyond just code.
- Better “agent” abilities for software work
- On tests that check planning, environment setup, locating bugs, and making fixes, the reconstructed training improved the model’s basic “developer agent” skills.
- The search-improved reasoning was especially good for careful tasks like error diagnosis.
Why this matters: the model didn’t just get better at writing code—it got better at thinking like a developer.
Why does this matter?
- Trains AIs to think, not just copy
- Teaching the process (plans, reads, writes, fixes) helps models understand why code is written a certain way, not just what the final code looks like.
- Makes future coding assistants more reliable
- By grounding the steps in real project structures, the model is less likely to hallucinate and more likely to follow realistic workflows.
- Scales to complex tasks
- This “reconstruct the steps” idea could help in other fields with long projects: science, engineering, research, and more.
- Practical improvements today
- The approach already boosted performance across long-context reading, coding, reasoning, and agent-like tasks—all from turning static code into step-by-step build stories.
In short: Instead of training on just the final result, this paper shows that teaching AI the story of how the result was created—plan, read, write, check—makes it smarter, more reliable, and better at real-world software development.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of the key uncertainties and omissions in the paper that future work could address:
- Generalizability across programming languages and ecosystems: the pipeline relies on import-based dependency parsing and AST extraction but does not specify support beyond Python-like projects; assess coverage for multi-language repositories (e.g., JS/TS, Java, C/C++, Rust) and complex build systems (Bazel, CMake, Maven, Gradle).
- Robust dependency and structure extraction: quantify failure rates of dependency graph and AST extraction on real-world repos (dynamic imports, reflection, generated code, monorepos, polyglot repos) and their impact on trajectory fidelity.
- Realistic iteration and backtracking: the synthesized workflow appears mostly linear (create files once); add and evaluate iterative edits, refactoring, and backtracking cycles that characterize real development.
- Execution-grounded feedback: the agent only “reads” files and “writes” ground-truth code; incorporate and measure benefits of compiler errors, test runs, linting, benchmarks, and runtime logs in the observation loop.
- Use of real development traces: compare reconstructed trajectories against actual commit histories, pull requests, issues, and code review comments to validate realism and measure relative gains.
- Contamination controls: detail and enforce deduplication against evaluation sets (e.g., HumanEval, LongCodeBench, GSM8K/MATH prompts); release hash-based filters and report contamination audits.
- Licensing and data governance: clarify repository license filtering, attribution, and redistribution terms for the synthesized dataset; provide compliance workflow.
- Scoring model and reward hacking: specify which model computes ; test whether optimizing CoT for lower perplexity induces verbose, stylistic, or model-specific “rationales” that do not generalize, and evaluate with independent scorers.
- Search hyperparameters and compute: ablate number of candidates per step (k), iteration count, and selection strategies; report compute costs and identify diminishing returns on CoT length vs. performance.
- Component-wise ablations: isolate contributions of Main-Agent planning, Sub-Agent thinking, Read/Write tools, grounding signals, trajectory flattening, and observation masking to identify which elements drive gains.
- Observation masking effects: evaluate with and without masking of tool responses; test alternative masking schemes (partial masking, delayed masking) to balance realism and causal learning.
- Trajectory flattening vs. hierarchical representations: compare linearized logs to structure-preserving encodings (e.g., tree- or thread-aware tokenization) for long-context modeling and memory utilization.
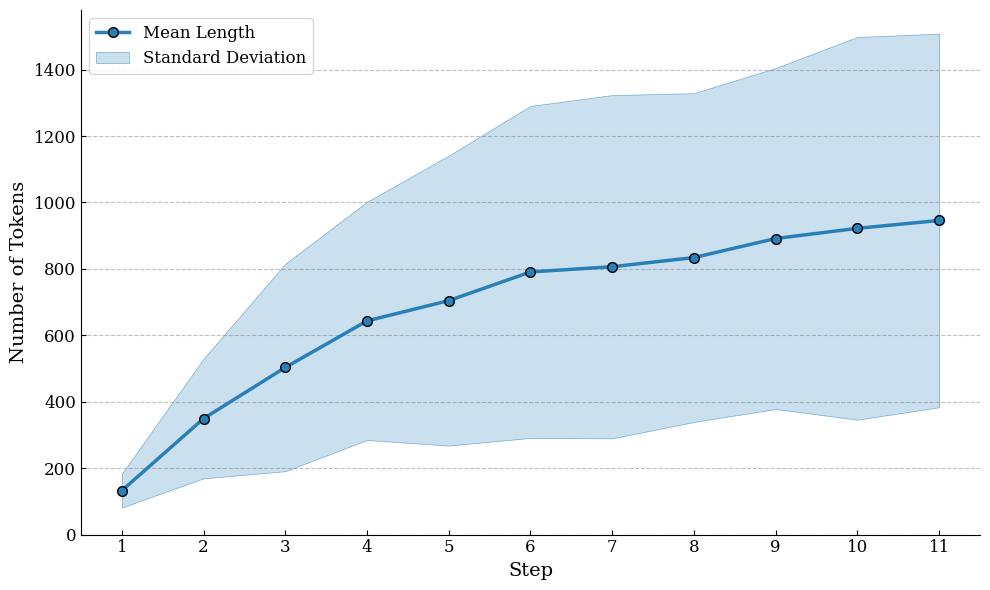
- Token-budget trade-offs: with fixed tokens, longer trajectories reduce the number of covered repos; quantify the optimal reasoning-to-code token ratio for pretraining efficiency across tasks.
- Scaling behavior: test across model sizes (e.g., 2B/8B/34B) and architectures (base vs. instruct vs. code-centric) to establish scaling laws for “understanding via reconstruction.”
- Downstream agent performance: measure end-to-end gains in real tool-use agents (shell, git, package manager, editor, tests) on SWE-Bench, SWE-agent tasks, and web research beyond proxy metrics like APTBench.
- Task-level error analysis: provide fine-grained analyses of where improvements occur (e.g., planning vs. code synthesis vs. retrieval) and where regressions appear (e.g., LongCodeBench-64k drops); link gains to specific trajectory features.
- Long-context limits: extend evaluation beyond 64k (e.g., 128k, 1M) to validate the claimed advantages for ultra-long contexts and examine stability/robustness under extreme lengths.
- General reasoning transfer: run broader non-code evaluations (e.g., commonsense, reading comprehension, multi-step planning) to assess whether coding-centric CoT improves or hurts other domains.
- Data quality auditing: report quantitative noise metrics (logical contradictions, hallucinated dependencies, inconsistency between “Think” and ground truth), inter-annotator or human audits, and automatic filters.
- Realism of “Think” content: ensure “Think” steps do not leak ground-truth code verbatim; measure and mitigate code-token leakage in rationales to avoid trivializing learning.
- Diversity and representativeness: document repo selection criteria (language mix, domain, size thresholds), and analyze coverage bias (libraries vs. applications, mature vs. toy projects) and its impact.
- Effect on inference behavior: assess whether models overproduce long CoT at inference, its latency/compute implications, and strategies to control thinking length without sacrificing accuracy.
- Alternative objectives: compare perplexity-based CoT optimization with RL, verification-guided search, or minimum description length objectives; evaluate correlation of PPL reductions with functional correctness (pass@k, test coverage).
- Integration of natural language artifacts: incorporate and ablate the value of READMEs, design docs, issues, and commit messages in reconstruction to better reflect end-to-end software reasoning.
- Reproducibility: release code, prompts, and seeds (or detailed recipes) for trajectory synthesis and search to enable independent replication and robustness checks.
- Negative side effects: investigate whether gains in coding/long-context come at the expense of other capabilities (e.g., instruction following, safety, calibration), and devise mitigation strategies.
- Cross-lingual considerations: evaluate trajectory generation and benefits for repositories and documentation in multiple human languages; test multilingual codebases and non-English comments/docstrings.
Practical Applications
Immediate Applications
The paper introduces a grounded multi-agent pipeline that reverse-engineers “how” a repository was built and uses search to optimize the reasoning. These innovations enable the following deployable use cases across sectors.
- Software: Repository-to-trajectory data pipeline for LLM pretraining
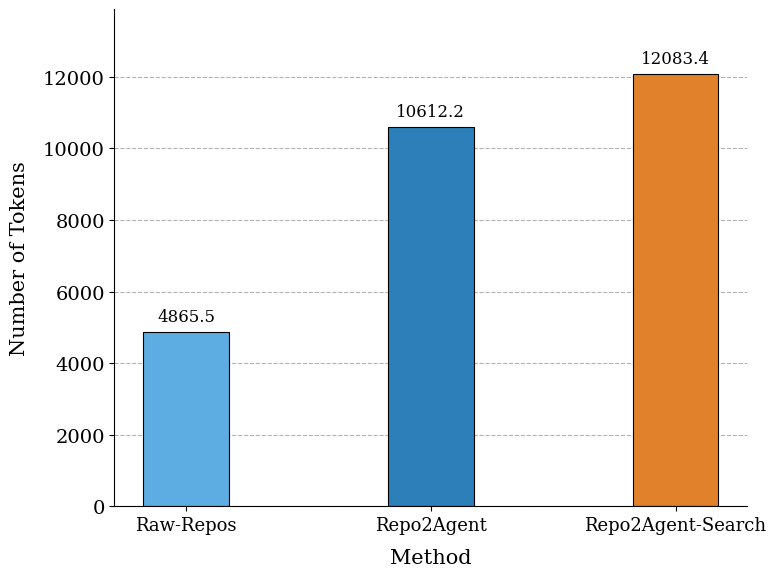
- What: Run the multi-agent “Repo2Agent” workflow on internal/open-source repos to synthesize planning/thinking/tool-use traces, then continue-pretrain in-house code LLMs.
- Why: Shown to improve long-context understanding, coding, and agentic capabilities versus raw code pretraining.
- Tools/Workflow: File tree/dependency/AST extraction → LLM-simulated main/sub-agents with Read/Write tools → trajectory flattening → targeted loss masking → continual pretraining.
- Assumptions/Dependencies: Access to licensed repos; a capable base LLM to simulate trajectories; compute for 10B–20B token pretraining; data quality controls for hallucinations.
- Software/Developer Tools: Documentation and design-recovery from existing repos
- What: Generate high-level requirements, implementation plans, module dependencies, and per-file rationale to augment or bootstrap missing docs.
- Why: Improves onboarding, maintenance, and knowledge transfer for large codebases.
- Tools/Workflow: Run the main-agent planning + sub-agent file-level reasoning with ground-truth injection to produce project briefs and per-module design notes.
- Assumptions: Reasoning is synthetic (not historical); requires human review for accuracy.
- Software: IDE copilots with process-aware suggestions
- What: Integrate plan-first “think–then–code” prompts trained on reconstructed trajectories into IDEs to produce stepwise plans, dependency-aware refactors, and rationale-backed edits.
- Why: Enhances reliability for long-horizon coding tasks and improves explainability for developers.
- Tools/Workflow: Fine-tune inference prompts and retrieval to surface plan/rationale templates learned in pretraining.
- Assumptions: Model access with long-context; prompt/runtime latency budgets.
- Software QA/SRE: Test and CI pipeline generation informed by dependency graphs
- What: Use extracted dependency graphs + AST structures to propose test scaffolds, CI steps, and build scripts aligned with repo topology.
- Why: Speeds bootstrapping of tests and CI for legacy or minimally tested projects.
- Tools/Workflow: Dependency analysis + sub-agent “Write” templates for tests/CI.
- Assumptions: Language/ecosystem-specific adapters (e.g., Python, Java, JS).
- Education: Worked “development process” examples for teaching programming
- What: Create step-by-step build logs (requirements → design → implementation) for open-source projects to teach software engineering thinking, not just end-code.
- Why: Aligns learning with authentic planning/debugging practices.
- Tools/Workflow: Run the simulation on curated teaching repos; package trajectories as course materials.
- Assumptions: Instructor vetting; pedagogical alignment.
- Enterprise IT/Governance: Software change-trace drafts for audits
- What: Produce traceable, structured narratives (plans, dependencies, rationale) for internal audits and ISO/IEC-style process documentation.
- Why: Helps satisfy traceability/documentation requirements when human-authored docs are sparse.
- Tools/Workflow: Batch run on internal services/libs; export narratives to internal wikis.
- Assumptions: Non-authoritative; must be marked as reconstructed and reviewed.
- Research (Academia/Industry): Better pretraining corpora for code LLMs
- What: Release/curate datasets akin to “Repo2Agent-Search” to study long-context, reasoning, and agentic capabilities.
- Why: Offers a reproducible path to long-context gains without expensive tool-execution environments.
- Tools/Workflow: Public pipelines/scripts; license-compliant repo filtering.
- Assumptions: Dataset licensing; reproducibility across base models.
- AI Evaluation: Planning/agentic benchmark augmentation
- What: Use decomposed trajectories (plan, file actions, tool calls) to create fine-grained evals of planning, dependency handling, and logical rigor.
- Why: More diagnostic than pass/fail task metrics; complements APTBench-like assessments.
- Tools/Workflow: Convert curated trajectories to eval tasks with per-step scoring.
- Assumptions: Careful design to avoid training–test contamination.
- Consulting/Services: Repository comprehension and modernization
- What: Provide services that reconstruct architecture and rationales to support migrations, refactors, or dependency upgrades.
- Why: Reduces discovery time in complex estates.
- Tools/Workflow: Run pipeline on client repos; surface plans and hotspots.
- Assumptions: Security reviews; data residency constraints.
- Daily Life/Makers: Guided project scaffolding for hobby apps
- What: For small projects, a “coach mode” that plans modules and explains decisions while generating boilerplate.
- Why: Improves learning curve and code quality for non-experts.
- Tools/Workflow: Lightweight hosted models with plan-first prompting.
- Assumptions: Smaller contexts; reliance on public templates.
- Open-Source Ecosystem: Automated READMEs and architecture overviews
- What: Enrich community repos with dependency diagrams, component roles, and usage pathways derived from reconstructed plans.
- Why: Improves discoverability and contributor onboarding.
- Tools/Workflow: GitHub Actions that run the planner and update docs.
- Assumptions: Maintainer opt-in; guard against hallucinated claims.
- Data Engineering: PPL-guided CoT selection for synthetic corpora
- What: Adopt the paper’s perplexity-based search to filter/refine synthetic rationales that best predict ground-truth artifacts in any domain where “answer” is known.
- Why: Simple, stable alternative to RL for rationale quality control.
- Tools/Workflow: Candidate generation → PPL evaluation → replace-if-better.
- Assumptions: Requires a scoring model and compute for candidate evaluation.
Long-Term Applications
The paradigm can generalize beyond code and scale toward more autonomous, verifiable, and cross-domain systems. These applications require further research, tooling, or scaling.
- Software: End-to-end autonomous repo builders with verifiable thought
- What: Agents that plan, implement, and refine full repositories with continuous CoT optimization tied to ground-truth tests and builds.
- Impact: Continuous maintenance, feature addition, and bug fixes with transparent reasoning.
- Dependencies: Robust tool-execution environments; program synthesis safety; test or spec oracles; cost-effective long-context execution.
- Secure Software Supply Chain: SBOMs and provenance with reconstructed rationale
- What: Augment SBOMs with dependency-aware plans and change rationales for compliance and incident response.
- Impact: Faster root-cause analysis and license/security audits.
- Dependencies: Standards for “rationale SBOMs”; acceptance by regulators/customers; accurate reconstruction at scale.
- Education: Interactive tutors that “replay” the development process of complex systems
- What: Students explore branching design decisions and see how different plans affect outcomes on real repos.
- Impact: Higher-fidelity training in architecture, trade-offs, and debugging.
- Dependencies: Curriculum integration; validated pedagogical efficacy.
- Cross-Domain Data Synthesis: Reconstruction for non-code artifacts
- What: Apply repository-to-trajectory ideas to hardware design (HDL/CAD), data science pipelines (notebooks), legal drafting (contract version histories), or scientific workflows.
- Impact: Pretraining data with richer process supervision in many knowledge-work domains.
- Dependencies: Domain parsers/graphs (e.g., netlists, pipeline DAGs); ground-truth endpoints; domain LLMs.
- Robotics/Autonomy: From ROS repos to agent trajectories
- What: Reconstruct planning and module dependencies in robot stacks to pretrain task-planning and tool-use behaviors.
- Impact: Better long-horizon planning and modular tool chaining for embodied agents.
- Dependencies: Accurate ROS/package graphs; sim-to-real transfer; safe execution.
- Healthcare (Software Quality in Clinical Systems): Process-traceable updates
- What: For regulated medical software, generate human-auditable rationales for code changes and safety-relevant logic.
- Impact: Supports validation and regulatory submissions.
- Dependencies: Domain validation; strict QA; PHI-safe pipelines; regulator acceptance.
- Finance/Energy (Critical Infrastructure Software): Change-control with explainable agent traces
- What: Pair code changes with optimized thought traces to pass internal reviews and compliance audits.
- Impact: Faster approvals, higher confidence in modifications to critical systems.
- Dependencies: Strong verification (tests/formal methods); governance buy-in.
- Policy & Governance: Standards for synthetic reasoning in training corpora
- What: Guidelines and audits on how synthetic CoT is created, grounded, and optimized (e.g., PPL-based acceptance criteria).
- Impact: Increases transparency, comparability, and safety in model training practices.
- Dependencies: Community consensus; measurement tools; disclosure norms.
- Model Inference: Runtime “search-refine” thought optimization for difficult tasks
- What: Adapt the paper’s PPL-guided search to refine in-context plans during inference for high-stakes generation.
- Impact: More reliable outputs without full RLHF cycles.
- Dependencies: Latency/compute budget; calibrated PPL proxies for task success.
- Tool Ecosystem: Standardized “Read/Write + Grounding” agent APIs
- What: Build open interfaces where agents request structured repo facts (file trees, deps, AST nodes) and commit writes with transactional checks.
- Impact: Safer and more reproducible agent tool-use across organizations and IDEs.
- Dependencies: API standards; security sandboxes; multi-language support.
- Knowledge Management: Enterprise-wide process reconstruction for legacy systems
- What: Apply at portfolio scale to expose architectural maps and historical rationales for thousands of services.
- Impact: Accelerates modernization and reduces key-person risk.
- Dependencies: Scalable pipelines; deduplication; access control and privacy.
- Safety Research: Causally rigorous CoT corpora to study reasoning failures
- What: Use PPL-optimized, grounded thought traces to analyze when/why LLMs deviate from causally correct reasoning.
- Impact: Better interpretability and safer reasoning behaviors.
- Dependencies: Benchmarks linking thought quality to outcome reliability; tooling for causal analysis.
Notes on Feasibility and Risks (common across applications)
- Licensing and IP: Only use repositories with compatible licenses; respect contributor agreements.
- Hallucination risk: Even grounded trajectories contain synthetic reasoning; human-in-the-loop review is recommended for docs, audits, and regulated domains.
- Compute and cost: Search-based CoT optimization and long-context pretraining/inference require significant compute budgets.
- Domain adapters: Dependency/AST extraction and grounding must be adapted per language/ecosystem; cross-domain extensions require new parsers/graphs.
- Evaluation leakage: When using reconstructed data for both training and evaluation, guard against contamination; build held-out evals.
Glossary
- Ablation: A controlled baseline variant used to isolate the effect of a component by removing or altering it. "the official Prolong baseline and the Raw-Repo ablation show significant degradation"
- Abstract Syntax Tree (AST): A tree-structured representation of source code that captures its syntactic structure. "we parse its Abstract Syntax Tree (AST) to extract key structural elements like class and function definitions."
- Agent exploration: Letting an agent interact with a real environment to collect trajectories of actions and outcomes. "generating trajectories through agent exploration in real-world environments"
- Agentic capabilities: A model’s abilities to plan, act with tools, and execute multi-step tasks autonomously. "including long-context understanding, coding proficiency, and agentic capabilities."
- Agentic trajectory: A sequence of thoughts, plans, tool uses, and actions executed by an agent to accomplish a task. "This entire sequence of thoughts, tool calls (Read, Write), and tool responses constitutes a single, coherent agentic trajectory"
- Causally complete: Containing sufficient intermediate reasoning and steps so outcomes follow logically from prior states. "yielding a dataset that is not only causally complete but also logically rigorous."
- Chain-of-Thought (CoT) reasoning: Explicit intermediate reasoning steps generated to solve a problem or guide generation. "Chain-of-Thought (CoT) reasoning"
- Continuous pre-training: Further training a model on large-scale data after initial pre-training to extend capabilities. "continuous pre-training on these reconstructed trajectories"
- Context window: The maximum number of tokens a model can condition on at once. "with a 64k context window"
- File Structure Tree: A full directory and file layout of a repository used to guide reconstruction or analysis. "File Structure Tree: A complete directory and file layout of the repository."
- Ground-truth code: The correct reference implementation from the original repository used as the target. "maximize the likelihood of the ground-truth code."
- Grounding: Anchoring a simulation or generation process to factual, extracted information to reduce hallucinations. "This grounding process ensures that while the reasoning is generated by the LLM, the actions and outcomes are anchored to reality."
- Hallucinations: Fabricated or incorrect outputs produced by an LLM that are not supported by source data. "may suffer from extensive hallucinations generated by the LLM"
- Inference-time search strategy: A search procedure applied during generation (not training) to improve outputs. "we therefore opt for a simpler yet effective inference-time search strategy"
- Inter-File Dependency Graph: A graph capturing how files in a codebase depend on each other (e.g., imports). "Inter-File Dependency Graph: We analyze import statements to build a graph representing how files depend on one another."
- Intra-File Structure: Structural elements within a single file (e.g., classes, functions) used for analysis or prompts. "Intra-File Structure: For each file, we parse its Abstract Syntax Tree (AST) to extract key structural elements like class and function definitions."
- Latent space: The internal representation space of a model where abstract features or “thoughts” are encoded. "embedding an ``internal monologue'' within the model's latent space."
- Long-context understanding: The ability to retrieve and reason over information spread across very long inputs. "including long-context understanding, coding proficiency, and agentic capabilities."
- Long-horizon reasoning: Planning and reasoning across many steps to reach distant goals or outputs. "deep, long-horizon reasoning required for complex software engineering"
- Long-range causal dependencies: Dependencies where information early in a long context affects much later outcomes. "it introduces long-range causal dependencies."
- Logical scaffolding: The underlying structured reasoning that supports a final answer or artifact. "reconstruct the logical scaffolding behind high-quality reference answers."
- Multi-agent simulation: Simulating multiple coordinated agents with distinct roles to generate trajectories. "a framework that synthesizes these trajectories using a multi-agent simulation."
- Next-token prediction objective: The training goal of predicting the next token given a context. "aligning the training data more effectively with the model's next-token prediction objective."
- Open-ended generation: Generating free-form outputs without a single fixed target, often requiring complex reasoning. "introduced a reverse-engineering approach for open-ended generation"
- Perplexity (PPL): A measure of how well a model predicts a sequence; lower PPL indicates better predictive fit. "measure the Perplexity (PPL) of the ground-truth code"
- Perplexity-driven path searching: Selecting or refining reasoning paths by minimizing the perplexity of the target output. "utilizing perplexity-driven path searching to reconstruct the logical scaffolding behind high-quality reference answers."
- Reinforcement learning (RL): A training paradigm where policies are optimized to maximize expected rewards. "this objective could be optimized using RL (with log p(x|z) as the reward)"
- Reverse-engineering: Inferring the process or steps that produced a final artifact from its end state. "reverse-engineering the latent agentic trajectories"
- Search-based optimization: Improving outputs by exploring candidate solutions and selecting those that optimize a criterion. "we employ a search-based optimization technique"
- Self-instruct methodology: Generating instruction data automatically from models to create instruction-following datasets. "the self-instruct methodology"
- Supervised fine-tuning (SFT): Training a model on labeled input–output pairs after pre-training. "rather than SFT or post-training"
- Targeted Loss Masking: Excluding specific tokens from contributing to the loss so the model focuses on desired signals. "Targeted Loss Masking"
- Tool invocation costs: The computational or monetary costs of calling external tools during agent execution. "including potentially expensive tool invocation costs"
- Tool-use: The act of an agent invoking external tools (e.g., read/write) as part of its reasoning process. "iterative tool-use"
- Trajectory curation: Constructing and organizing high-quality trajectories for training or evaluation. "The initial trajectory curation stage leverages an LLM's ability to simulate agentic behavior."
- Trajectory Flattening: Converting hierarchical multi-agent interactions into a single linear sequence. "Trajectory Flattening"
- “Read” tool: A tool interface allowing an agent to retrieve or inspect existing content for context. "These agents utilize a ``Read'' tool to gather context"
- “Write” tool: A tool interface enabling an agent to output or modify code/content. "and a ``Write'' tool to generate code."
Collections
Sign up for free to add this paper to one or more collections.