MV-SAM3D: Adaptive Multi-View Fusion for Layout-Aware 3D Generation
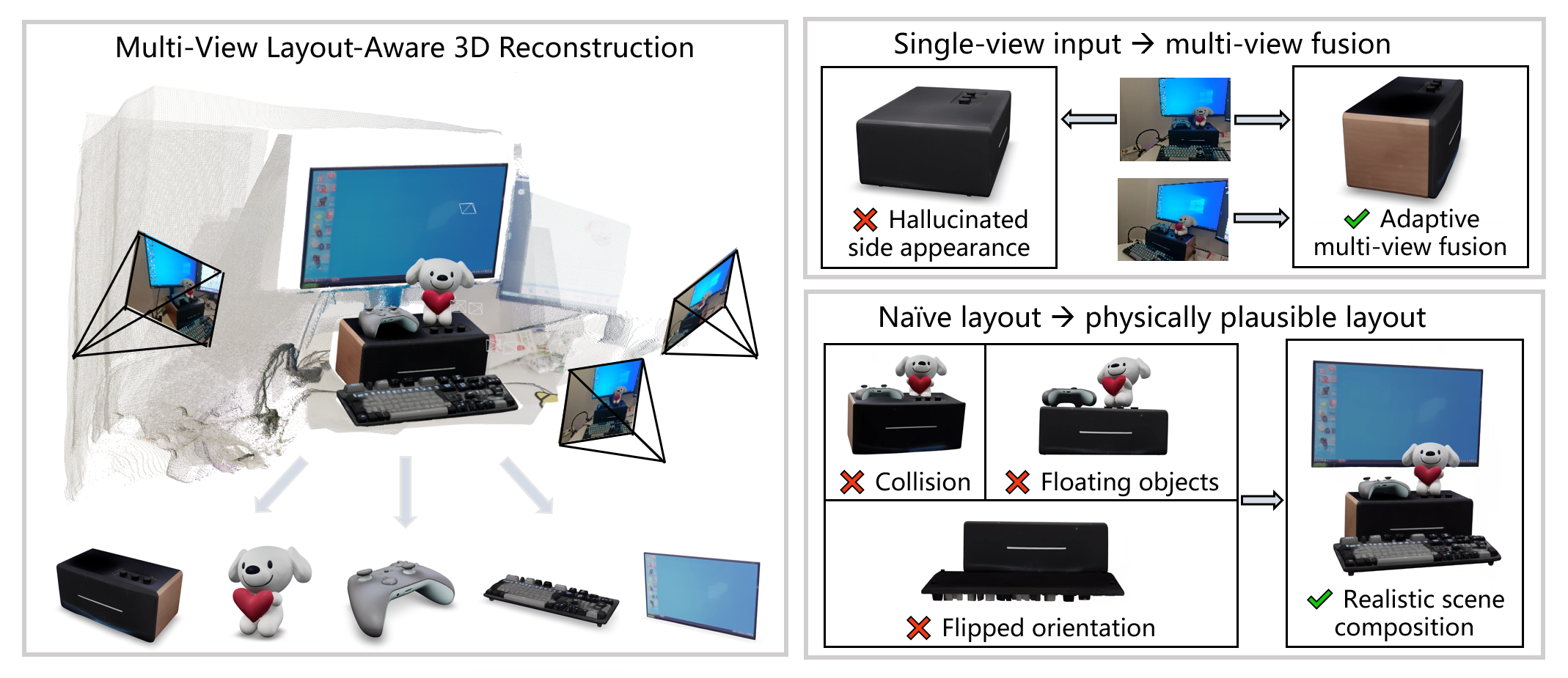
Abstract: Recent unified 3D generation models have made remarkable progress in producing high-quality 3D assets from a single image. Notably, layout-aware approaches such as SAM3D can reconstruct multiple objects while preserving their spatial arrangement, opening the door to practical scene-level 3D generation. However, current methods are limited to single-view input and cannot leverage complementary multi-view observations, while independently estimated object poses often lead to physically implausible layouts such as interpenetration and floating artifacts. We present MV-SAM3D, a training-free framework that extends layout-aware 3D generation with multi-view consistency and physical plausibility. We formulate multi-view fusion as a Multi-Diffusion process in 3D latent space and propose two adaptive weighting strategies -- attention-entropy weighting and visibility weighting -- that enable confidence-aware fusion, ensuring each viewpoint contributes according to its local observation reliability. For multi-object composition, we introduce physics-aware optimization that injects collision and contact constraints both during and after generation, yielding physically plausible object arrangements. Experiments on standard benchmarks and real-world multi-object scenes demonstrate significant improvements in reconstruction fidelity and layout plausibility, all without any additional training. Code is available at https://github.com/devinli123/MV-SAM3D.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MV-SAM3D: A simple explanation
What’s this paper about?
This paper is about turning several photos of a scene (like a desk with books, a cup, and a toy) into a 3D model where each object looks right and is placed in the correct spot. The authors extend a previous system called SAM3D, which worked with just one photo, so it can now use multiple photos taken from different angles and also arrange objects in ways that obey basic physics (no objects floating or passing through each other).
What questions are the researchers trying to answer?
- How can we combine information from many photos so the 3D model doesn’t “make up” details incorrectly for parts we can’t see in a single view?
- How can we place multiple objects together so they don’t overlap, float, or sit at impossible angles?
- Can we do this without retraining a big AI model from scratch?
How does their method work (in everyday language)?
Think of building a 3D model as putting together a sculpture using clues from your photos.
- Using all the views without confusion
- Imagine friends describing an object from different sides. If you simply average their stories, the side no one clearly saw might end up wrong.
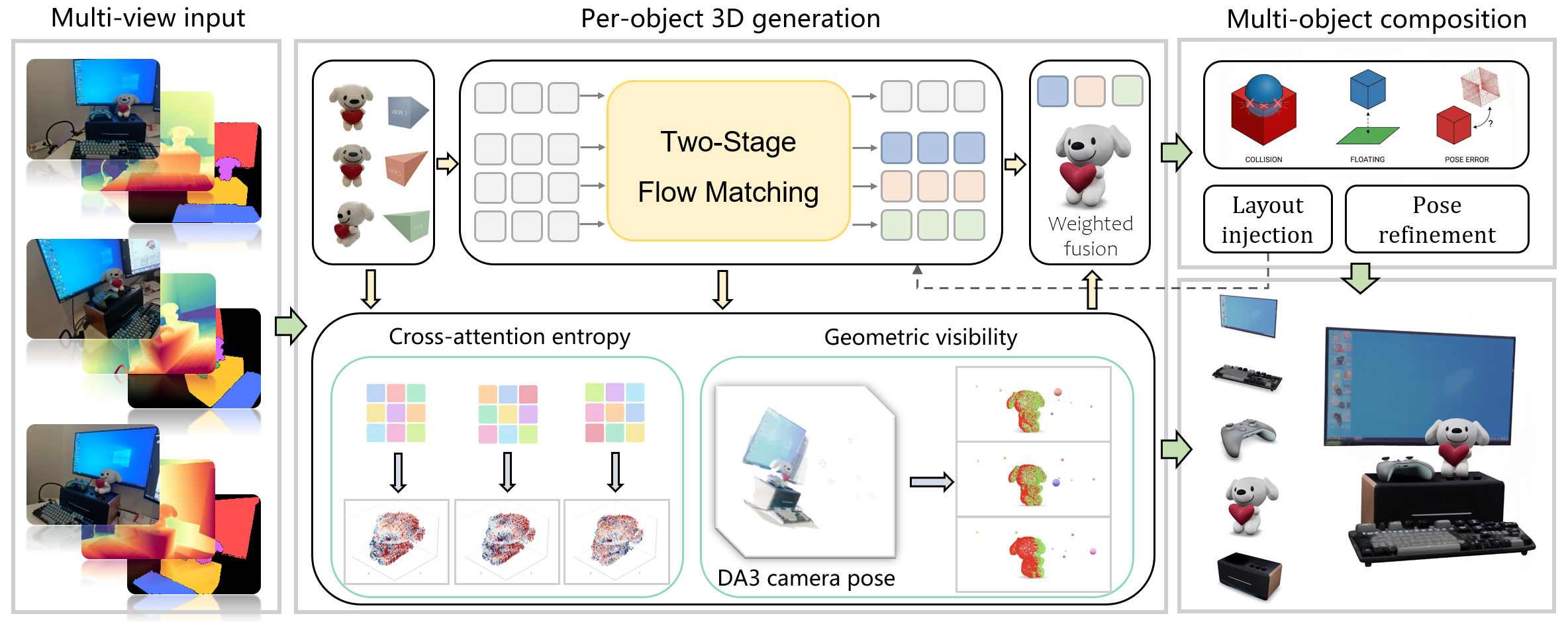
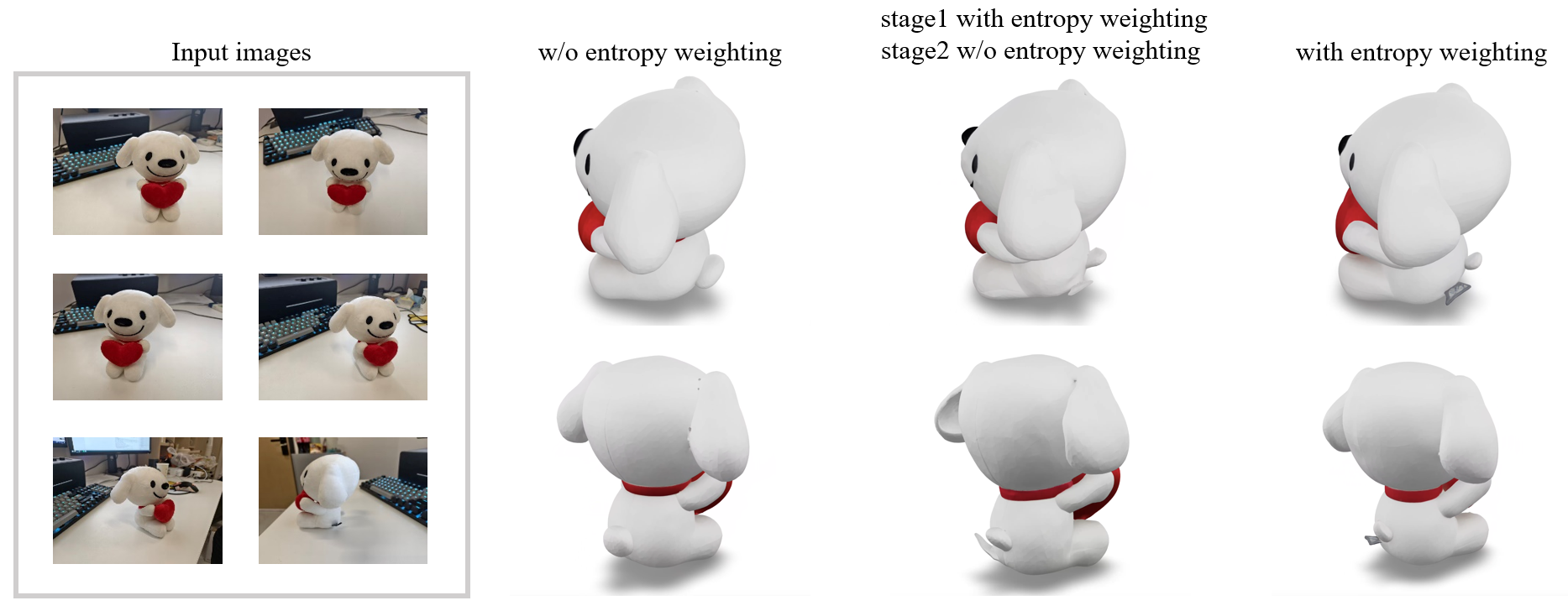
- The authors combine “opinions” from each view at every step of the 3D creation process, but they don’t treat all views equally everywhere. They give more weight to the view that is most trustworthy for each spot on the object.
They do this with two smart “weighing” tricks:
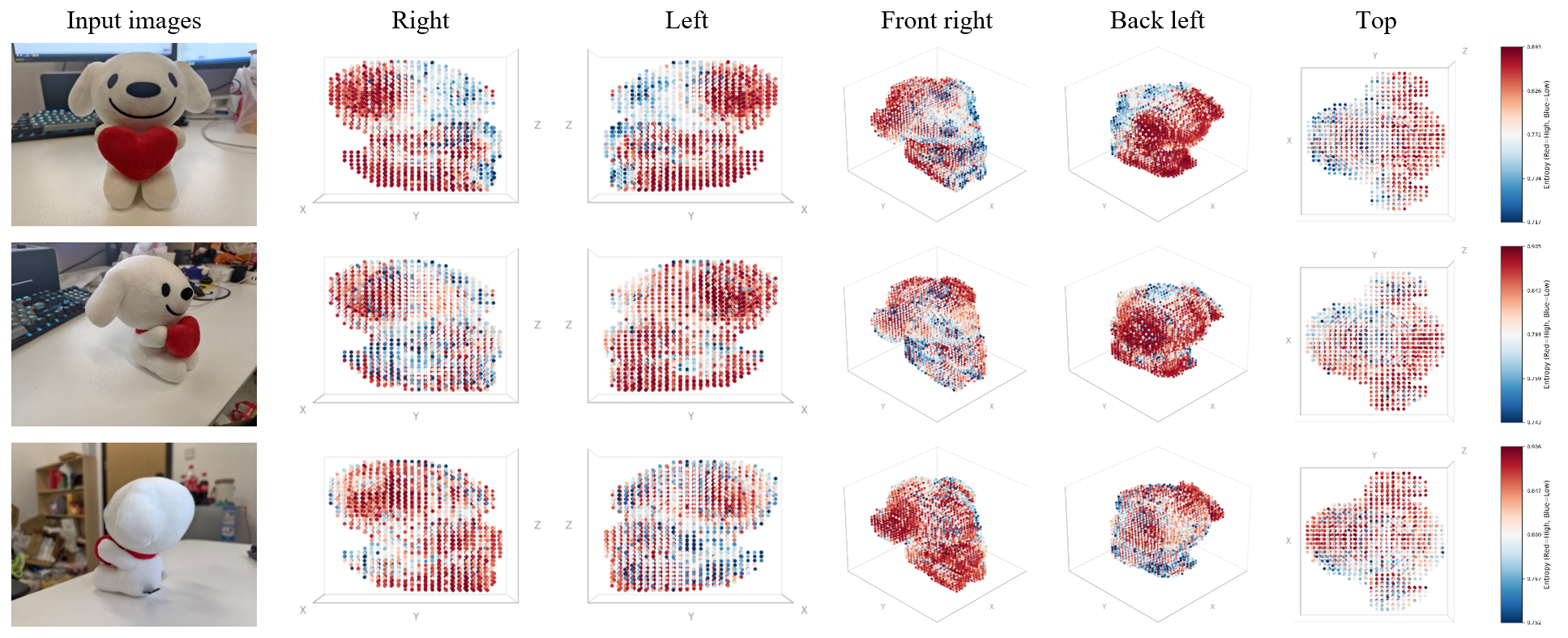
- Attention-entropy weighting (how confident a view is): Inside the model, each 3D point “looks” at parts of an image. If its attention is very focused (low “entropy”), that usually means the point is clearly visible in that photo and the model feels confident. If attention is spread out (high entropy), the model is guessing. The system trusts focused views more.
- Visibility weighting (is it even visible?): After getting a rough 3D shape, the system checks which parts are actually in line of sight for each camera (like asking: “Can this camera see that spot, or is it hidden?”). If a part is not visible from a certain photo, that photo’s opinion gets down-weighted for that part.
These two signals are blended so each tiny region of the 3D object listens most to the view that’s both confident and actually sees it.
- Making multi-object scenes physically believable
- During generation: The system gently nudges objects so they don’t collide and so surfaces that should touch actually make contact—like adjusting items on a table as you place them.
- After generation: It fine-tunes object positions so they line up better with the scene’s depth (how far things are) and remove any remaining overlaps. Think of this as a final tidy-up pass to make the arrangement look and feel real.
- No retraining needed
- “Training-free” means they plug these steps into the existing pipeline without having to teach the AI a whole new set of weights. It’s like adding smart rules and checks on top of a skilled artist’s workflow, rather than sending the artist back to art school.
What did they actually do under the hood?
- They use a two-stage generator (from SAM3D) that first builds a coarse structure (like a blocky version of the object) and then fills in details (shape and texture).
- At every step where the model “updates” the 3D representation (you can imagine it slowly carving from rough to fine), they fuse predictions from each view using the adaptive weights described above.
- They compute visibility using the rough 3D structure and known camera positions, and they read the model’s internal attention to estimate confidence.
- For physics, they add small guidance during generation to avoid collisions/encourage contact, then optimize the final positions of objects to align with the scene geometry and remove any residual overlaps.
What did they find, and why does it matter?
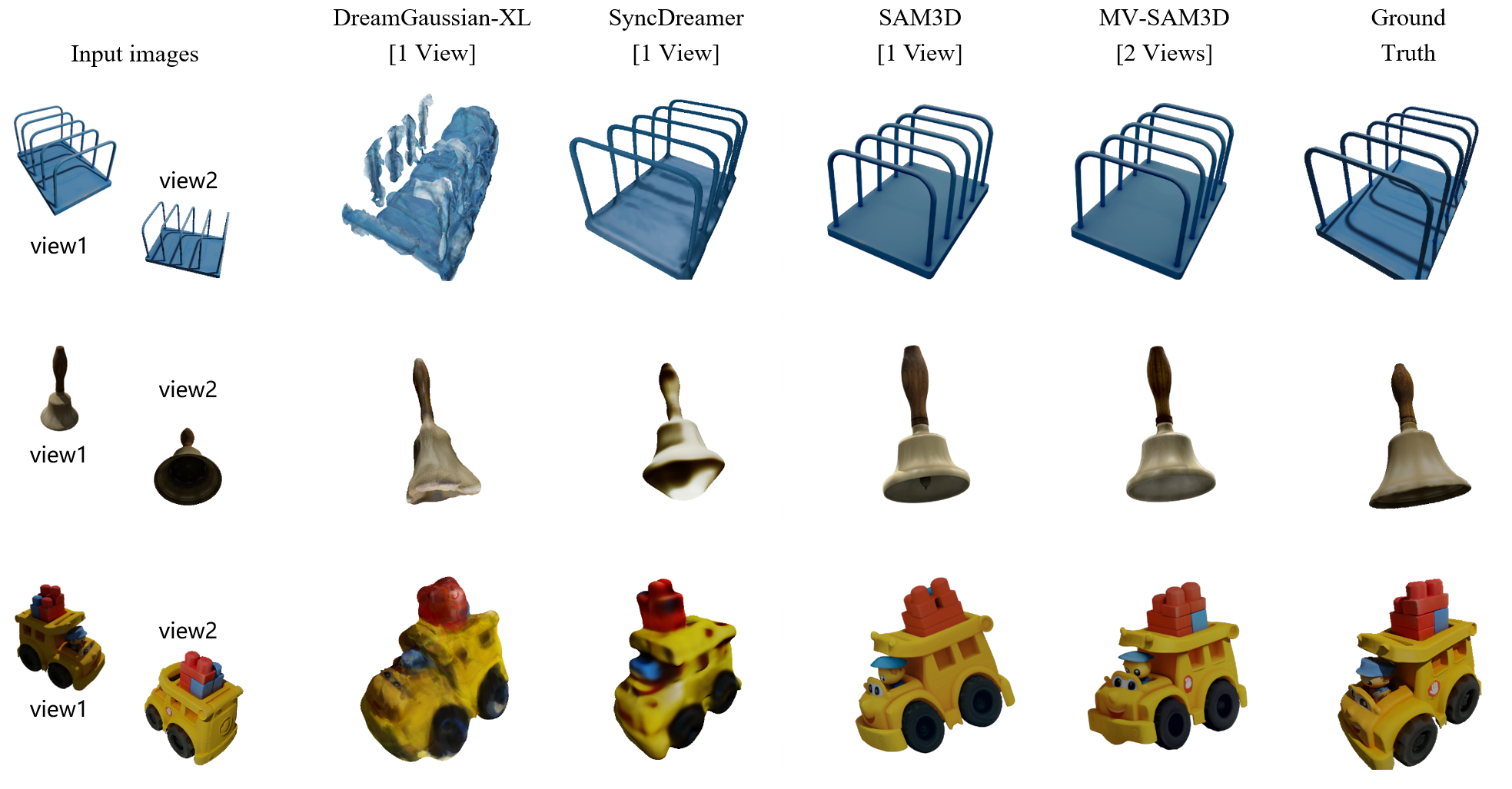
- Better 3D from multiple photos: Their method makes more accurate shapes and textures than single-photo methods, especially on parts only visible in some views (like the back of a box or the tail of a toy).
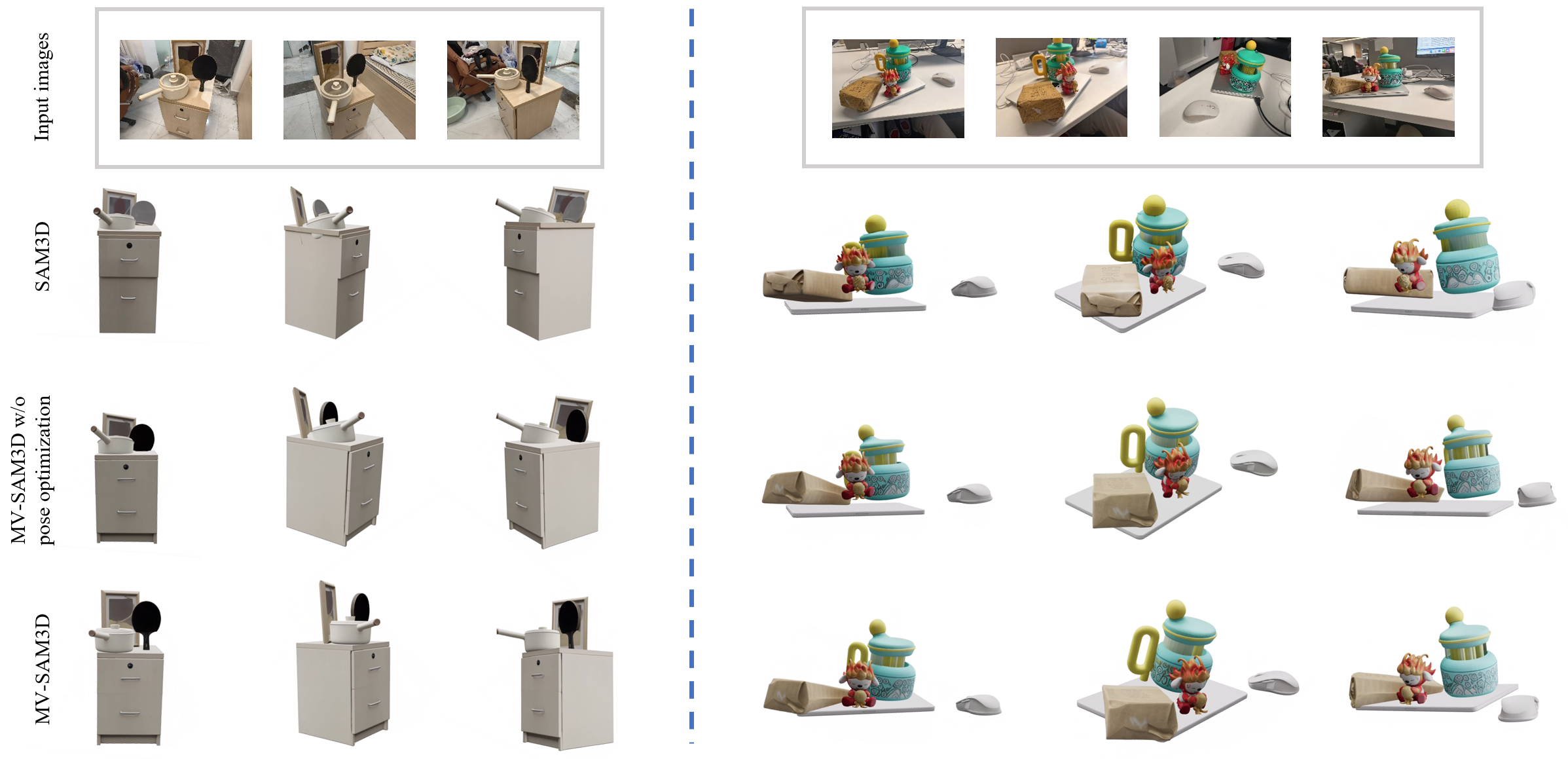
- More realistic scenes: In multi-object scenes, objects no longer float or intersect unrealistically. After physics-aware optimization, collisions drop dramatically, and contact (like a cup resting on a table) looks natural.
- Fewer views still help a lot: Going from 1 to 2 photos gives a big boost in quality. More photos help too, but after a point the improvements are smaller.
- Works without retraining: They achieved these gains by adding smart fusion and physics steps to the existing system, saving time and computation.
Why is this important?
- Faster, more reliable 3D creation: Useful for games, movies, AR/VR, and online shopping—anywhere you need quick, faithful 3D models from a few photos.
- Better for robots and planning: Realistic object placement (no collisions, proper contact) helps robots or simulation systems understand and interact with the real world.
- Scene-level understanding: This isn’t just about single objects—it preserves the layout of multiple objects together, which makes the 3D results more useful in real environments.
In short, MV-SAM3D makes 3D models from multiple photos that are accurate, consistent, and physically sensible—without needing to retrain the entire AI model.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps and open questions that remain unresolved and could guide future research:
- Dependence on upstream multi-view reconstruction: the method relies on DA3 for metrically consistent pointmaps and camera poses, but provides no sensitivity analysis to pose/depth errors or miscalibration; joint pose–geometry refinement with the generative model or uncertainty-aware fusion is unexplored.
- Requirement of accurate segmentation masks across views: robustness to mask noise, inter-object occlusions, and imperfect instance boundaries is not evaluated; joint segmentation-and-generation or mask refinement within the pipeline remains open.
- Attention-entropy weighting calibration: the choice of transformer layer, tokenization granularity, and temperature α is fixed and unstudied; how entropy correlates with true visibility in low-texture, specular, or repetitive regions is not quantified; alternatives (e.g., attention sharpness, feature similarity, or learned confidence predictors) are not explored.
- Visibility weighting trustworthiness: visibility is computed from Stage-1 coarse voxels and can be wrong if coarse geometry is inaccurate; iterative visibility recalculation, soft/probabilistic visibility (e.g., depth margins, grazing-angle weighting), or multi-pass corrections are not investigated.
- Self- versus scene-level occlusion: the current visibility only accounts for self-occlusion per object; occlusions by other scene objects or the environment are ignored during fusion, leading to potential texture bleeding; scene-level visibility reasoning is absent.
- Fusion scheduling over the flow trajectory: the method uses entropy in Stage 1 and entropy+visibility in Stage 2, but lacks a principled annealing/scheduling strategy over time steps; how weight dynamics affect ODE stability and sample quality remains unstudied.
- Theoretical properties of weighted Multi-Diffusion: using non-uniform, data-dependent weights within the flow-matching ODE lacks an analysis of stability, convergence, or bias relative to the learned transport; conditions guaranteeing well-behaved integration are open.
- Photometric/illumination inconsistencies: no color calibration, exposure matching, or reflectance/lighting modeling is used across views; handling varying lighting to avoid seams or appearance drift is not addressed.
- Unobserved-region completion: the approach still hallucinates unobserved areas without uncertainty quantification; mechanisms to represent, propagate, or visualize uncertainty, or to defer uncertain regions for later capture/editing, are missing.
- Physics model simplifications: collision/contact penalties omit gravity, friction, support/stability, and torque balance; topple-prone or physically unstable arrangements are not penalized; integrating differentiable physics or support relations remains future work.
- Post-generation refinement scope: refinement optimizes only similarity transforms (scale, rotation, translation) and cannot fix geometric errors that cause penetrations or poor contacts; joint pose-and-shape adjustment or localized mesh deformation under physics constraints is unexplored.
- Scalability and efficiency: runtime and memory costs with increasing views and object counts are not reported; strategies for view selection, token sparsification, or hierarchical fusion to maintain tractability are open.
- Incremental/online operation: the framework does not support streaming multi-view inputs or interactive updates; enabling fast incremental fusion as new views arrive is unresolved.
- Generalization beyond rigid, opaque objects: performance on articulated, deformable, thin, transparent, or highly reflective objects is untested; visibility/entropy cues and fusion behavior under such materials are unknown.
- Robustness to real-world degradations: sensitivity to camera pose noise, intrinsic errors, rolling shutter, motion blur, and lens distortion is not evaluated; incorporating pose/depth uncertainty into fusion and refinement is open.
- Benchmarking and ground truth: the self-captured MV-SAM3D-Scenes lacks ground-truth meshes; standardized scene-level benchmarks, broader environments, human studies, and statistical significance across runs are missing.
- Dynamic scenes and temporal consistency: the method assumes static scenes; extending to moving objects, temporal sequences, and time-consistent physics is an open direction.
- Semantic priors and ambiguity resolution: the training-free design does not leverage category priors or scene semantics that could disambiguate symmetric/repetitive structures; integrating semantic-conditioned confidence or priors remains unexplored.
- Hyperparameter sensitivity: numerous fixed hyperparameters (α, β, γ, η, collision/contact weights) are not analyzed; automatic or adaptive tuning schemes would improve robustness across scenes.
- Handling extreme view imbalance/outliers: although addressed partially, detection and down-weighting of contradictory or low-quality views (e.g., motion-blurred, occluded) via robust statistics or outlier modeling is not developed.
- Hybrid generative–reconstruction constraints: no explicit multi-view photometric/reprojection consistency is used alongside the generative prior; evaluating hybrid objectives to further reduce hallucination is an open question.
- Ground-plane and support reasoning: contact constraints exist but there is no explicit detection of ground/support surfaces or global scene layout priors; support-aware placement could reduce floating and improve stability.
- Visibility computation fidelity: binary DDA-based visibility is coarse and non-differentiable; sub-voxel, angle-aware, or differentiable rasterization-based visibility could yield smoother, more accurate weights.
- Cross-attention signal design: entropy is extracted from a “designated” layer without justification; multi-layer aggregation, ensembling, or learned fusion of attention diagnostics may improve reliability.
- Failure modes and edge cases: beyond symmetric textures, other challenging cases (thin structures, glossy/transparent materials, heavy clutter) and their characteristic errors are not cataloged; constructing targeted stress tests would aid progress.
- Partial/occluded instances: robustness when objects are heavily truncated or partially outside the view frusta is unclear; strategies for partial object completion and layout recovery are unaddressed.
- Reproducibility and variance: the stochasticity or determinism of the generation (e.g., seeding, ODE vs. stochastic solvers) and variance across runs are not reported; guidelines for reproducible evaluation are missing.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that follow directly from MV-SAM3D’s training-free, multi-view fusion and physics-aware layout optimization.
- 3D asset capture from a few photos for media and games — software, media/entertainment, AR/VR
- What: Turn 5–15 smartphone photos + masks into high-fidelity, layout-aware meshes with plausible object arrangements for games, VFX, and XR.
- Tools/workflows: Blender/Unreal/Unity plug-ins; a “Capture-to-Asset” desktop or mobile app exporting glTF/USDZ; batch processing for art pipelines.
- Dependencies/assumptions: Reasonable multi-view coverage; good masks (auto-segmentation or human-in-the-loop); DA3 (or equivalent) for poses/metric depth; consumer GPU/CPU time budget.
- E-commerce product twins from customer or studio photos — retail/e-commerce
- What: Generate accurate, all-sides product models that reflect observed surfaces, reducing hallucinated textures and improving try-on/AR previews.
- Tools/workflows: Product digitization service + QA that flags low-coverage with entropy/visibility cues; integration with web viewers.
- Dependencies/assumptions: Consistent lighting/background or robust segmentation; metrics from DA3 provide approximate scale; reflective/transparent items may still be challenging.
- Shelf/planogram compliance and digital twin creation — retail/operations
- What: Reconstruct multi-object shelf scenes from photos, preserving object positions and resolving collisions, to compare with planograms.
- Tools/workflows: In-store capture app (guided angles), MV-SAM3D batch reconstruction, automatic compliance checker.
- Dependencies/assumptions: Adequate views per shelf section; reliable per-product segmentation; stable SKUs/textures.
- Rapid object libraries for robots — robotics
- What: Build robot-ready 3D object libraries and simple scene replicas from a few camera views, with contact-aware placement for planning and simulation.
- Tools/workflows: Perception pipeline module that ingests multi-view snapshots and outputs meshes + poses for simulation or manipulation planners.
- Dependencies/assumptions: Calibrated or DA3-estimated camera poses; metric scale needed for planning; not suited for deformable/transparent objects.
- Scene-level AR staging and interior mockups — real estate, AEC, interior design
- What: Capture furniture and decor with spatial layout and collision-free placement to power AR staging, clearance checks, and walkthroughs.
- Tools/workflows: MR app that reconstructs objects from multiple phone views, exports room-scale scenes for design tools.
- Dependencies/assumptions: Sufficient coverage; accurate masks for furniture; DA3 metric scale for reliable measurements.
- Damage evidence reconstruction for claims — insurance
- What: From multi-angle photos of small scenes (e.g., fender benders, interior incidents), produce 3D scenes with realistic contact to aid adjusters.
- Tools/workflows: Claims portal with photo capture guidance and automated 3D scene reconstruction for review.
- Dependencies/assumptions: Limited to static scenes; visibility gaps induce generative completion (must be disclosed); legal/forensic standards may require audit trails.
- Shop-floor workcell snapshot and collision checks — manufacturing/QA
- What: Reconstruct small clusters of tools/fixtures to check clearances and contacts, spotting interpenetrations pre-assembly.
- Tools/workflows: Tablet capture + MV-SAM3D + automated collision/contact reports.
- Dependencies/assumptions: Static setups; good segmentation; approximate metric accuracy acceptable for preliminary checks.
- Classroom and museum digitization (small object sets) — education/cultural heritage
- What: Quickly digitize lab setups or artifacts with coherent object layouts for teaching, archiving, or interactive exploration.
- Tools/workflows: Educator-facing capture tool with segmentation assistance; export to web viewers.
- Dependencies/assumptions: Limited scene size and object count; matte surfaces preferred.
- Synthetic data generation with fewer artifacts — AI/ML, computer vision
- What: Produce multi-view-consistent images and meshes with reduced texture bleed, improving training sets for 6D pose, NVS, or grasping.
- Tools/workflows: Data factory that uses adaptive fusion weights for fidelity; labels auto-derived from metric depth and poses.
- Dependencies/assumptions: Curate objects/materials to avoid failure modes; document generative completion for unobserved areas.
- Consumer “My Things in 3D” — daily life
- What: Users capture personal items or small vignettes (desk setups) as 3D for resale listings, sharing, or AR visualization.
- Tools/workflows: Mobile app that auto-segments, captures recommended views, and exports models for marketplaces.
- Dependencies/assumptions: User-friendly segmentation; clear capture guidance; privacy around background content.
- Layout-aware 3D scene thumbnails for catalogs — publishing/marketing
- What: Turn multi-angle product scene photos into interactive 3D previews that preserve arrangements (e.g., tableware sets).
- Tools/workflows: Pipeline for scene curation and export to 3D viewers embedded in web pages.
- Dependencies/assumptions: Stable scenes; distinct textures; lighting variations handled by segmentation.
- Benchmarking and methods research — academia
- What: Use attention-entropy and visibility weighting as baselines for confidence-aware view fusion; study physics-guided rectified-flow generation.
- Tools/workflows: Reproducible experiments with the released code; new datasets of multi-view, multi-object scenes with physics scores.
- Dependencies/assumptions: Access to SAM3D/MV-SAM3D code and DA3; compute for ablations.
Long-Term Applications
These uses likely require further research, scaling, domain adaptation, or integration beyond the current system.
- Real-time, on-device multi-view scanning — software/mobile, AR
- What: Near-instant reconstruction on phones/AR glasses for in-situ authoring and navigation.
- Gaps: Model compression, sparse-view robustness, efficient DA3 alternatives; on-device memory/compute constraints.
- Whole-room and building-scale digital twins with object semantics — AEC, facilities, smart homes
- What: Reconstruct dozens to hundreds of objects with globally consistent layout and contact, suitable for BIM alignment.
- Gaps: Scalable pose/layout optimization, loop-closure with SLAM, automatic scene-wide segmentation; handling clutter/occlusions.
- Online robotics perception: closed-loop capture-plan-act — robotics
- What: Continuous scene updates from robot cameras feeding manipulation and navigation with stable, contact-aware geometry.
- Gaps: Dynamic-object handling, uncertainty tracking, integration with motion planners, robustness to specular/transparent items.
- Physically grounded scene validation (stability, support, friction) — engineering, simulation
- What: Extend beyond collision/contact to predict and enforce stability and support constraints in generated scenes.
- Gaps: Differentiable physics with friction/compliance; reliable material/weight estimates; tighter simulation–generation coupling.
- Advanced retail digital twins and autonomy — retail/operations
- What: Store-wide reconstructions powering autonomous restocking, inventory, and shopper analytics with accurate object placements.
- Gaps: Full-store segmentation at scale; real-time updates; identity tracking over time; privacy-compliant capture.
- Construction progress and safety compliance — AEC, policy
- What: Automated detection of clearance violations, missing supports, or hazardous placements from site photos with 3D recon + physics checks.
- Gaps: Harsh lighting/dust robustness; integration with BIM and regulatory schemas; certification standards for automated assessments.
- Healthcare instrument and tray layout capture — healthcare
- What: Digitize surgical trays or lab setups with precise placements for inventory and procedural checks.
- Gaps: Domain adaptation to metallic/reflective tools; sterile workflow compliance; high-precision metric requirements.
- Insurance and forensics-grade 3D evidence — insurance, legal/policy
- What: Standardized 3D reports from incident photos with uncertainty annotations and audit trails accepted in adjudication.
- Gaps: Provenance tracking, explainability for generative completion, standards/guidelines for admissibility.
- Energy/utilities asset rooms and substation twins — energy/utility
- What: Capture switchgear or panel rooms; verify clearances and access pathways using contact-aware reconstructions.
- Gaps: Low-light/high-voltage environments, tight tolerances, integration with maintenance CMMS systems.
- Finance/asset valuation via 3D inventories — finance
- What: Rapid 3D inventories for collateral assessment or leasing, with approximate metric scale and layout plausibility.
- Gaps: Reliability guarantees, bias mitigation for unseen surfaces, standardized uncertainty reporting.
- Multi-modal fusion (RGB + depth/LiDAR/IMU) for robust capture — cross-sector
- What: Combine cameras with commodity depth/LiDAR to improve visibility estimation and scale accuracy.
- Gaps: Calibration and synchronization; fusion models and uncertainty handling.
- Content authenticity and watermarking for generated twins — policy, platforms
- What: Signatures and logs that mark generated vs. observed geometry and textures for transparency.
- Gaps: Standardized metadata, platform adoption, user education.
Key Assumptions and Dependencies (affecting feasibility)
- Multi-view inputs: The method benefits most from 2–5+ well-distributed views; low coverage increases reliance on learned completion.
- Segmentation quality: Accurate per-object masks (auto or manual) are required; failure cases propagate to geometry/textures.
- Camera poses and metric depth: DA3 (or similar) is needed for robust pose/scale and explicit visibility checks.
- Materials and lighting: Highly reflective/transparent objects and extreme lighting remain challenging.
- Compute: Authors report A100-class runs; practical deployments may need optimization or cloud execution.
- Physics model scope: Current constraints focus on non-penetration/contact; stability/friction are not enforced unless extended.
- Static scenes: Dynamic objects and non-rigid/deformable items are out of scope without further research.
Glossary
- 3D latent space: A learned space where 3D representations are encoded and manipulated during generation. Example: "Multi-Diffusion process in 3D latent space"
- Acc@5cm: A spatial alignment metric measuring the percentage of points within 5 cm of ground truth. Example: "Acc@5cm"
- adaptive multi-view fusion: Combining information from multiple camera views with data-driven weights to improve reconstruction. Example: "per-object 3D generation with adaptive multi-view fusion"
- attention-entropy weighting: A fusion strategy that uses the entropy of cross-attention to weight per-view contributions based on confidence. Example: "attention-entropy weighting and visibility weighting"
- binary visibility matrix: A per-view, per-point 0/1 matrix indicating whether each 3D point is visible from a given camera. Example: "compute a binary visibility matrix "
- bundle adjustment: An optimization in multi-view geometry that refines camera poses and 3D structure jointly. Example: "feature matching and bundle adjustment"
- Chamfer Distance: A geometric distance between point sets used to measure alignment or reconstruction quality. Example: "measures Chamfer Distance"
- Classifier guidance: A technique to steer diffusion models using gradients from an external objective. Example: "Classifier guidance and its training-free variants"
- collision and contact constraints: Physical constraints enforcing non-penetration and realistic surface contact between objects. Example: "collision and contact constraints"
- confidence-aware fusion: A fusion scheme that weights each view’s contribution according to its reliability. Example: "confidence-aware fusion"
- Cov.: Coverage metric indicating the portion of the scene or objects that are correctly reconstructed/aligned. Example: "Cov."
- cross-attention: An attention mechanism that links latent tokens to conditioning image features. Example: "cross-attention between the latent tokens and the conditioning features"
- DDA ray tracing: A grid traversal algorithm (Digital Differential Analyzer) used here to compute per-view visibility. Example: "we perform DDA ray tracing"
- DiT (Diffusion Transformer): A transformer architecture adapted for diffusion-based generative modeling. Example: "DiT architecture"
- flow matching: A generative training and sampling framework that learns a velocity field to transport noise to data. Example: "Both stages employ flow matching"
- floating artifacts: Physically implausible configurations where objects appear to float with no support/contact. Example: "floating artifacts"
- Gaussian splatting: A rendering/representation technique that models scenes with Gaussian primitives. Example: "Gaussian splatting scenes"
- geometric visibility weighting: Weighting views based on explicit geometric visibility of points from each camera. Example: "geometric visibility weighting"
- heterogeneity-aware optimization: An optimization strategy that accounts for varied data or component characteristics to speed up generation. Example: "heterogeneity-aware optimization"
- interpenetration: Physically impossible overlap of objects where one’s volume intrudes into another. Example: "interpenetration"
- latent tokens: Discrete units in the latent representation that a transformer processes and attends to. Example: "latent tokens"
- layout-aware 3D generation: Generating 3D objects together with their spatial arrangement within a scene. Example: "extends layout-aware 3D generation with multi-view consistency"
- layout injection: Injecting physical/layout guidance during generation to avoid implausible placements. Example: "Layout injection nearly eliminates inter-object collisions during generation"
- LPIPS: A perceptual image similarity metric used to evaluate visual fidelity. Example: "LPIPS "
- metric-scale pointmaps: Depth-derived 3D correspondences with consistent, real-world scale. Example: "metric-scale pointmaps serve as the geometric input"
- MM-DiT (Multi-Modal Diffusion Transformer): A diffusion transformer conditioned on multiple modalities (e.g., images, masks). Example: "Multi-Modal Diffusion Transformer (MM-DiT)"
- Multi-Diffusion: A method to fuse multiple conditional predictions during diffusion by averaging or weighting predicted updates. Example: "Multi-Diffusion"
- multi-view consistency: Ensuring that predictions agree across multiple camera viewpoints. Example: "multi-view consistency"
- multi-view fusion: Aggregating information across multiple views to improve reconstruction fidelity. Example: "multi-view fusion"
- neural implicit surfaces: Continuous neural representations of geometry that define surfaces implicitly (e.g., via signed distance). Example: "per-object neural implicit surfaces"
- non-penetration constraints: Constraints preventing objects from occupying the same physical space. Example: "respect non-penetration and surface contact constraints"
- novel view synthesis: Rendering images of an object/scene from camera viewpoints not seen during input. Example: "Novel view synthesis on GSO-30."
- ODE (Ordinary Differential Equation): The differential equation integrated during flow matching to generate samples. Example: "integrating the ODE"
- pointmap: A per-pixel mapping to 3D coordinates or correspondences used for conditioning. Example: "pointmap encoding spatial correspondence"
- post-generation pose refinement: An optimization step after generation to adjust object poses for better alignment and plausibility. Example: "Post-Generation Pose Refinement"
- proximity threshold: A distance threshold used for deciding contact/collision/nearness during optimization. Example: "proximity threshold "
- PSNR: Peak Signal-to-Noise Ratio, a pixel-wise fidelity metric for image quality. Example: "PSNR "
- RelAcc@5%: Relative accuracy metric measuring pose/geometry agreement within a 5% tolerance. Example: "RelAcc@5\%"
- Score Distillation Sampling: An optimization-based technique that distills 2D diffusion priors into 3D representations. Example: "Score Distillation Sampling"
- self-occluded: A point on an object that is hidden from a camera due to occlusion by the object itself. Example: "self-occluded"
- similarity transform: A transformation composed of scale, rotation, and translation. Example: "optimize its similarity transform"
- SLAT (Structured Latent) Generation: The stage that produces high-resolution structured latent codes for detailed geometry/texture. Example: "Structured Latent (SLAT) Generation."
- sparse voxel structure: A coarse volumetric representation where only a subset of voxel locations is populated. Example: "sparse voxel structure"
- SSIM: Structural Similarity Index Measure, assessing perceptual image similarity. Example: "SSIM "
- Structure-from-Motion (SfM): A pipeline that reconstructs 3D structure and camera poses from multiple images. Example: "Structure-from-Motion (SfM)"
- surface contact constraints: Constraints encouraging touching surfaces to be in contact without gaps. Example: "surface contact constraints"
- velocity field: The vector field learned in flow matching that transports noise samples toward data. Example: "learns a velocity field"
- visibility weighting: A fusion strategy that down-weights views where a point is not visible. Example: "visibility weighting"
- visual SLAM: Simultaneous Localization and Mapping using visual inputs to estimate camera trajectory and scene structure. Example: "visual SLAM"
- volumetric overlap: The intersecting volume between objects used to quantify collisions. Example: "penalizes volumetric overlap"
Collections
Sign up for free to add this paper to one or more collections.