- The paper presents CTI-REALM, a benchmark that evaluates AI agents in generating security detection rules within a realistic blue team workflow.
- It employs a methodology that integrates CTI ingestion, telemetry exploration, iterative query refinement, and MITRE mapping, with performance quantified by F1-score and normalized rewards.
- Key findings reveal significant performance gaps among language models, highlighting the benefits of memory augmentation and tool integration in enhancing detection rule accuracy.
CTI-REALM: A Benchmark for Evaluating Security Agent Detection Rule Generation
Motivation and Benchmark Design
The CTI-REALM (Cyber Threat Real World Evaluation and LLM Benchmarking) benchmark is designed to rigorously evaluate AI agents’ proficiency in the end-to-end workflow of security detection engineering—a task central to blue team operations. In contrast to prior benchmarks focusing on parametric knowledge, isolated rule synthesis, or TTP classification, CTI-REALM targets the realistic analyst workflow: ingesting CTI reports, exploring complex and heterogeneous telemetry, identifying relevant MITRE ATT&CK techniques, iteratively constructing and validating queries, and ultimately generating detection rules in both Sigma and KQL formats. It features authentic telemetry from emulated attacks (Linux, Azure Kubernetes Service, and Azure cloud), and deterministically scored intermediate checkpoints, producing a robust reinforcement learning environment for both benchmarking and model development.
Evaluation within CTI-REALM utilizes two benchmark sets: CTI-REALM-25 (covering 25 tasks for rapid iteration) and CTI-REALM-50 (a superset with 50 tasks offering greater diversity and complexity), spanning three difficulty levels—atomic (easy), multi-step (medium), and sophisticated, multi-source chain attacks (hard, predominantly in cloud scenarios). Agents operate in Docker-isolated environments with access only to provided APIs and telemetry, ensuring reproducibility and security isolation. Each agent’s trajectory is evaluated via a multi-checkpoint reward system, decomposing the analytical workflow into CTI comprehension, MITRE mapping, telemetry data exploration, iterative query refinement, and final detection quality (informed by F1-score and Sigma rule LLM-as-judge scoring).
Experimental Setup
Sixteen state-of-the-art LLMs and agents were systematically evaluated using a ReAct agentic harness, implemented on top of the Inspect AI platform. These include Anthropic's Claude Opus/Sonnet variants (notably Opus 4.6 High, Opus 4.5), OpenAI's suite across the GPT-5 family with variable reasoning-effort settings, as well as distinct reasoning-enhanced models (O3, O4-Mini). Models were assessed both at their maximum and lower/medium computational budgets to investigate the effect of reasoning depth in this application domain.
The evaluation was structured into four phases: (1) model ranking on CTI-REALM-50 for general capability assessment; (2) variance analysis on repeated runs over CTI-REALM-25 to assess reliability and reproducibility; (3) ablation studies—removing CTI-specific tools to quantify non-parametric knowledge gain; and (4) an analysis of memory-augmented agents leveraging expert-crafted workflow guidance files to probe the extent to which augmentation can compensate for model scale.
The overall model ranking (on CTI-REALM-50) demonstrates a nontrivial spread in normalized reward performance (0.637–0.419), with Anthropic’s Claude Opus 4.6 (High) leading and OpenAI’s best-performing GPT-5 models trailing by 10–15% absolute reward. The strongest performance is observed on Linux endpoints (mean reward 0.585), moderate on AKS (0.517), and weakest on complex Cloud multi-source attacks (0.282). This performance hierarchy is robust across models, highlighting the escalated difficulty of threat hunting in cloud-native, multi-step APT engagements.
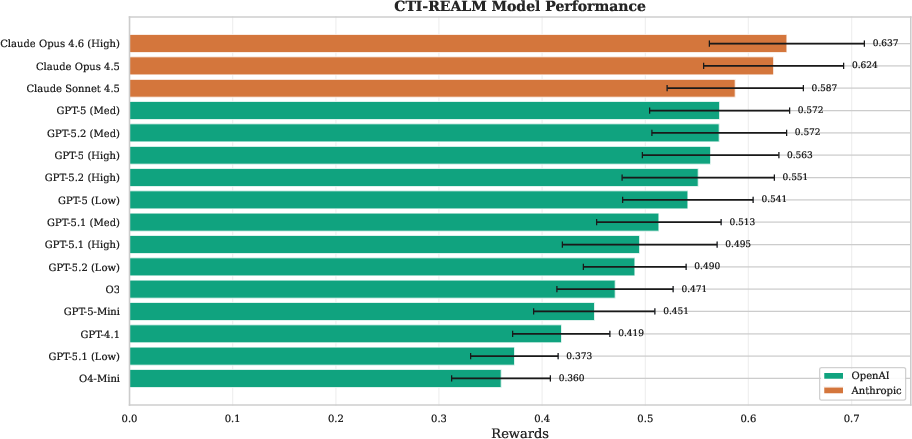
Figure 2: Model performance on CTI-REALM-50, sorted by normalized reward with Anthropic Claude models dominating the upper tier.
The multi-stage reward structure reveals that the most discriminative bottleneck is query execution (C3): top Anthropic models consistently achieve >0.85 (normalized), whereas OpenAI models frequently dip below 0.5, and legacy GPT-4.1 approaches 0.0. CTI comprehension and MITRE mapping (C0/C1) are also notably stronger for Anthropic agents. This suggests that despite large parametric knowledge, query composition and execution remain a major gap for even frontier OpenAI models.
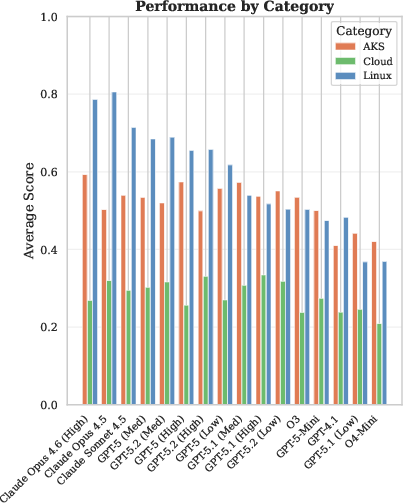
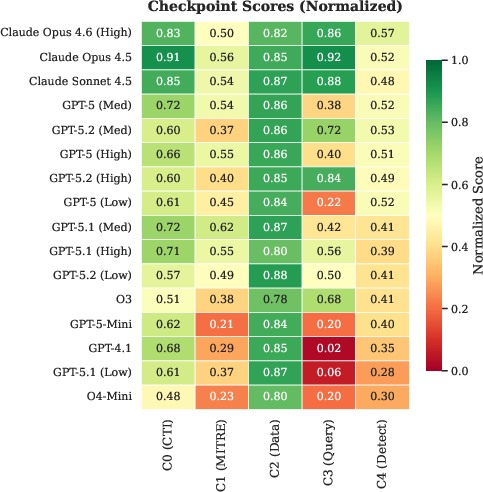
Figure 4: Performance breakdown by environment category—Linux tasks are consistently easier than AKS, with cloud scenarios presenting substantial modeling and reasoning challenges.
An analysis of cost-reward Pareto optimality demonstrates that Claude Opus models deliver higher reward per token, albeit at a higher absolute token count, while OpenAI GPT-5 (Low) provides maximum efficiency at a modest performance reduction.
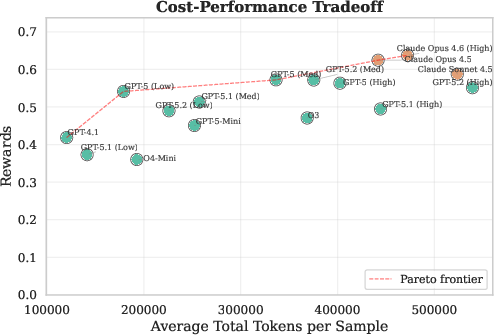
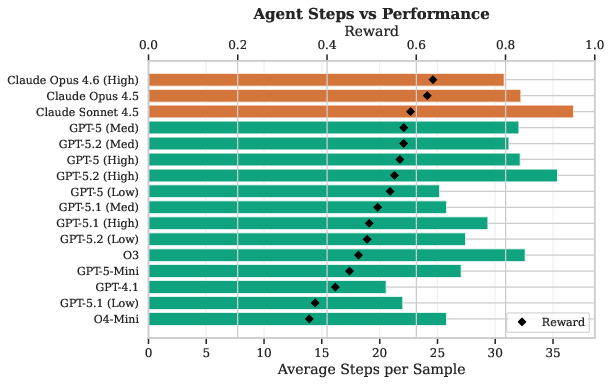
Figure 1: Tradeoff between token consumption and reward across models, highlighting Pareto-optimal configurations.
Variance analysis across repeated trials indicates that task difficulty, not model stochasticity, is the primary source of outcome variance. Opus models demonstrate occasional failures (zero reward) primarily on the most complex cloud scenarios, reflecting willingness to attempt riskier analytical strategies.
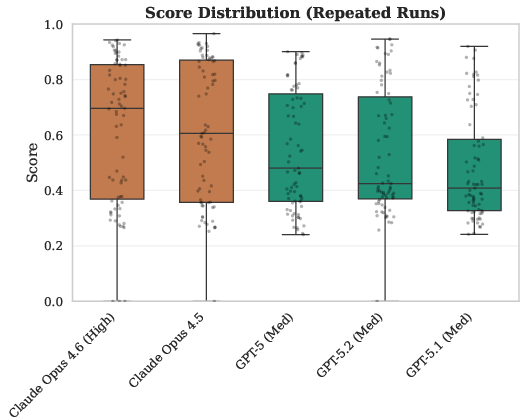
Figure 3: Distribution of reward across three trial runs on CTI-REALM-25, illustrating both typical outcome consistency and outlier failure events.
Ablation studies removing CTI-augmented tools consistently degrade model performance by 7.7–15.0 percentage points. The bulk of the performance drop is attributed to poorer endpoint and cloud detection quality, not simply intermediary reasoning steps. This supports the necessity of specialized external knowledge and domain tools to achieve high-fidelity detection engineering.
Memory augmentation (using expert-written workflow/scripts/templates and investigation strategies) enables smaller models (GPT-5-Mini) to close up to 33% of the reward gap to their larger counterparts. Performance gains are realized mainly in MITRE mapping (C1) and final detection rule specificity, whereas query construction (C3) remains primarily dependent on base model capability rather than auxiliary knowledge.
Theoretical and Practical Implications
CTI-REALM advances the study of LLM-based security automation by moving beyond one-shot evaluation of rule-synthesis into full reinforcement learning-compatible, trajectory-centric evaluation that mirrors real blue team workflows. The empirical results demonstrate that:
- Current LLM agents are not yet reliable for autonomous or weakly supervised detection rule engineering, especially in cloud environments requiring multi-step, cross-source correlation.
- Tool augmentation and structured prompt memory can meaningfully improve baseline agent capabilities, but cannot substitute for base reasoning and iterative investigation skill—even large models rely heavily on interaction with well-designed tool APIs and workflow constraints.
- There are substantial differences in agent performance attributable to model family and reasoning budget, with increased reasoning effort above medium resulting in diminishing or negative returns.
From a practical standpoint, CTI-REALM provides a standardized harness for model selection, tool/augmentation assessment, and as a policy optimization training ground for RL-based agent research. The structured reward schema enables fine-grained gap analysis (e.g., identifying whether novel models would benefit more from improved CTI knowledge or query execution policy).
Future Directions
There are several directions for further research and benchmark extension:
- Generalization to broader platforms: Expansion to AWS/GCP telemetry and queries (beyond Azure/KQL) is necessary for evaluation of cross-cloud operationalization.
- Integration with human-in-the-loop and adaptive agent architectures: The marriage of strong base models with active retrieval, agent reasoning trees, or cooperative analyst feedback in CTI-REALM could reveal synergistic gains currently inaccessible to monolithic agents.
- Tool and augmentation innovation: As memory and tool augmentation proved effective, further research into the design of memory retrieval, context distillation, and augmentation strategies is strongly motivated.
Conclusion
CTI-REALM establishes a rigorous, reproducible benchmarking standard for evaluating LLM and agent capabilities in realistic security detection engineering. The evaluation demonstrates nontrivial limitations in autonomous detection rule generation, especially in cloud and multi-step threat scenarios. The benchmark’s structure, tools, and datasets will enable both incremental improvement of agentic LLMs for security engineering and principled comparison of future modeling advancements.