EnterpriseOps-Gym: Environments and Evaluations for Stateful Agentic Planning and Tool Use in Enterprise Settings
Abstract: LLMs are shifting from passive information providers to active agents intended for complex workflows. However, their deployment as reliable AI workers in enterprise is stalled by benchmarks that fail to capture the intricacies of professional environments, specifically, the need for long-horizon planning amidst persistent state changes and strict access protocols. In this work, we introduce EnterpriseOps-Gym, a benchmark designed to evaluate agentic planning in realistic enterprise settings. Specifically, EnterpriseOps-Gym features a containerized sandbox with 164 database tables and 512 functional tools to mimic real-world search friction. Within this environment, agents are evaluated on 1,150 expert-curated tasks across eight mission-critical verticals (including Customer Service, HR, and IT). Our evaluation of 14 frontier models reveals critical limitations in state-of-the-art models: the top-performing Claude Opus 4.5 achieves only 37.4% success. Further analysis shows that providing oracle human plans improves performance by 14-35 percentage points, pinpointing strategic reasoning as the primary bottleneck. Additionally, agents frequently fail to refuse infeasible tasks (best model achieves 53.9%), leading to unintended and potentially harmful side effects. Our findings underscore that current agents are not yet ready for autonomous enterprise deployment. More broadly, EnterpriseOps-Gym provides a concrete testbed to advance the robustness of agentic planning in professional workflows.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces EnterpriseOps‑Gym, a “practice office” for testing AI assistants. Think of it like a realistic, safe, fake company where AI “workers” try to do office tasks: send emails, manage calendars, handle HR records, fix IT tickets, help customers, and move files. The gym checks whether AI can:
- Plan long, multi‑step tasks
- Keep track of what’s already changed (the “state” of the system)
- Use many different tools safely and correctly
- Follow strict company rules and permissions
- Stop and say “no” when a request is impossible or against policy
What questions were they trying to answer?
The researchers focused on simple, practical questions:
- Can today’s AI assistants plan and complete longer, real‑world office tasks without messing things up?
- Can they follow company rules (like permissions and procedures) while using different apps together?
- Do they know when to refuse tasks that are impossible or unsafe?
- Which AI models work best, and how much do they cost to run?
- What’s the main thing holding AIs back: choosing tools, planning, or something else?
How did they study it?
They built a realistic, contained playground (a “sandbox”) that works like a company’s systems:
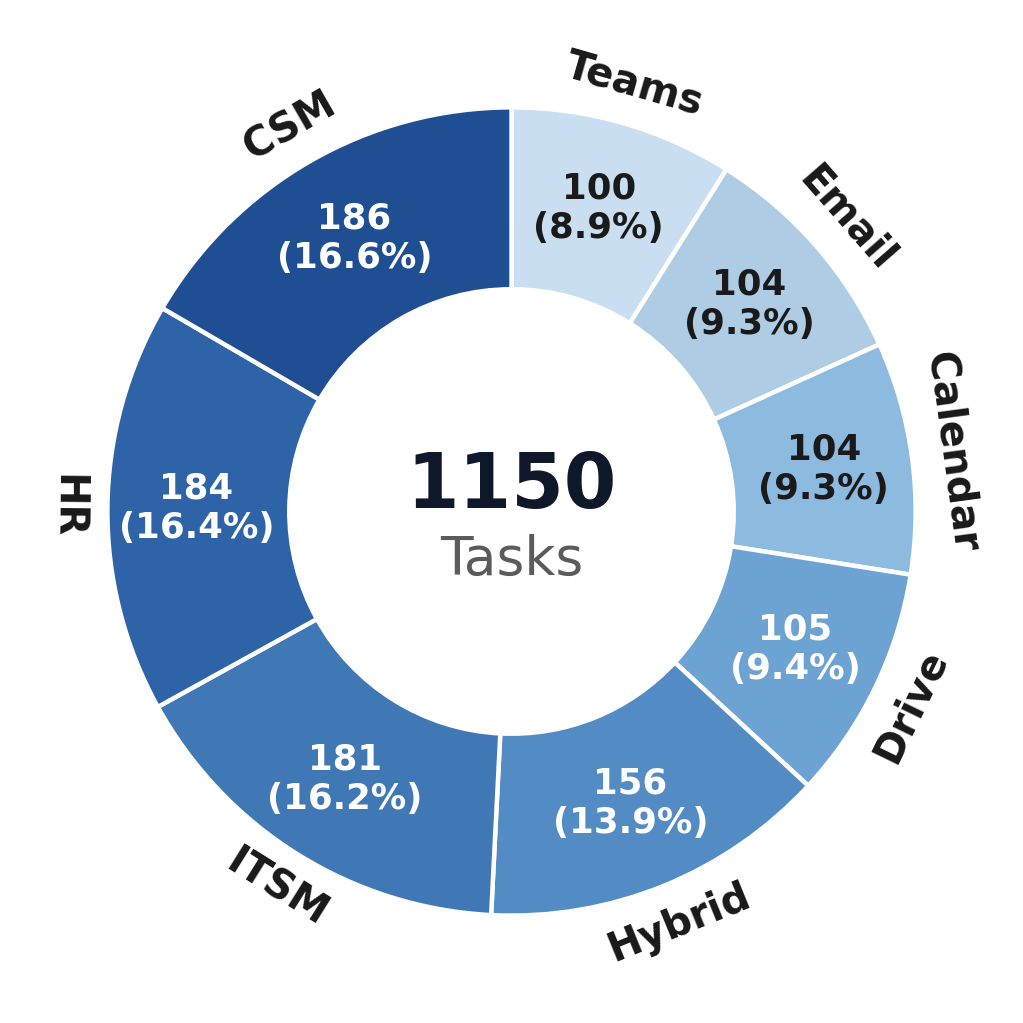
- 8 areas (or “domains”): Email, Calendar, Teams (chat), Drive (files), Human Resources, IT Service Management, Customer Service, and a Hybrid category that mixes several together.
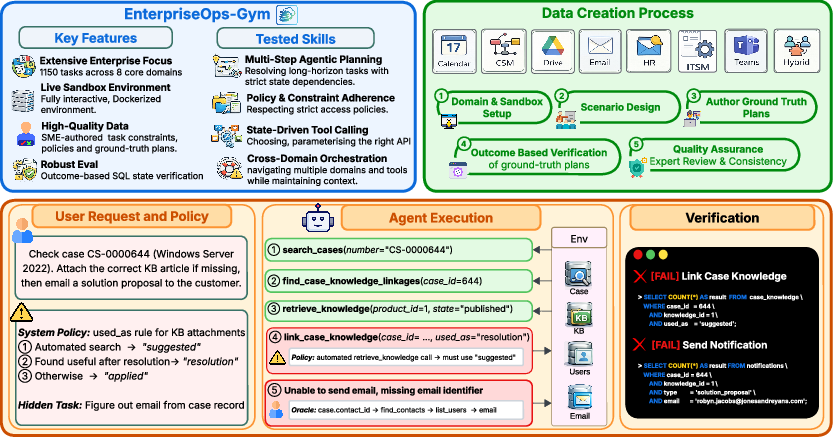
- 1,150 tasks written by experts (like: find a customer’s case, attach a knowledge article, email the customer, and follow policy X).
- 512 tools (like mini‑apps) and 164 linked database tables (imagine many spreadsheets with connections between them). “Linked” means if you add or change something in one place, it must match correctly in other places—just like real company records.
- 30 tasks are intentionally impossible (e.g., the person doesn’t have access, or a user is inactive, or a rule forbids it). This checks if the AI refuses cleanly instead of breaking things.
How tasks are checked:
- Instead of judging each step, the gym checks the end result using automatic scripts (like a checklist for the system). It asks: Did the goal get done? Are the rules followed? Are permissions respected? Were there any unwanted changes?
How AIs were tested:
- 14 different AI models tried the tasks.
- To focus on planning (not tool search), the AIs were given the right tools up front (“oracle tools”).
- The AIs ran in a think‑and‑act loop: think about the next step, use a tool, look at the result, repeat.
- The team also tested harder setups: longer tasks, extra distracting tools, and more “thinking time.”
Key idea translations:
- “Stateful”: Remembering and managing the current situation as it changes across steps.
- “Policies”: Company rules that must be followed (like who can see what, or what settings must be used).
- “Foreign keys”/links: The way pieces of data in different tables must match each other.
- “Side effects”: Unintended changes (like creating wrong records or breaking links).
What did they find, and why is it important?
Here are the main takeaways, explained simply:
- Overall success is low:
- Even the best model completed only about 37% of tasks correctly. Open‑source models were lower (around 24% at best).
- AIs did better on simpler teamwork tools (Email, Drive, Teams) and struggled more with rule‑heavy areas like IT and cross‑app tasks.
- Planning is the main bottleneck:
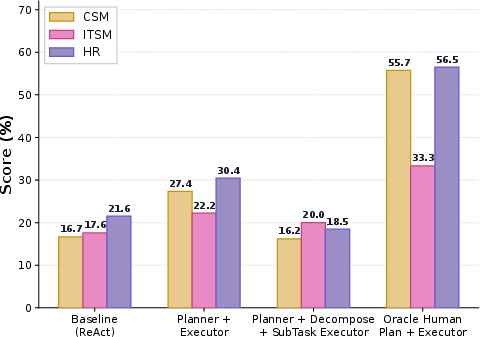
- When AIs were given human‑written step‑by‑step plans, performance jumped by 14–35 percentage points.
- Adding extra “distractor” tools barely hurt performance, suggesting the real problem isn’t choosing tools—it’s deciding the right multi‑step strategy.
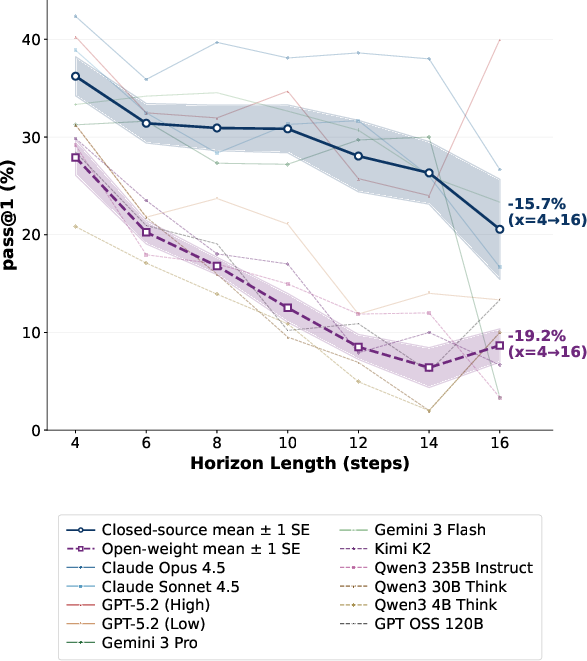
- Long tasks are hard:
- Performance drops as the number of steps grows. The longer the “to‑do list,” the more mistakes pile up.
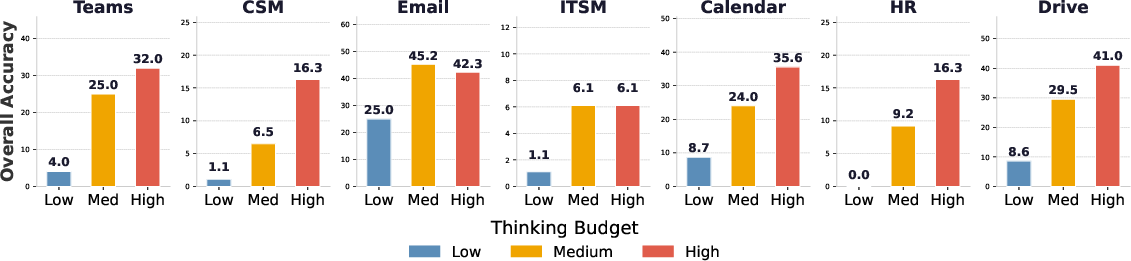
- More “thinking time” helps—but only sometimes:
- Giving models more time to reason improved results in many areas, but some tasks plateaued early, meaning extra thinking couldn’t fix deeper weaknesses.
- Refusing bad requests is unreliable:
- When tasks were impossible, the best model safely refused them only about 54% of the time. That means AIs often try and make unwanted changes, which is risky in real systems.
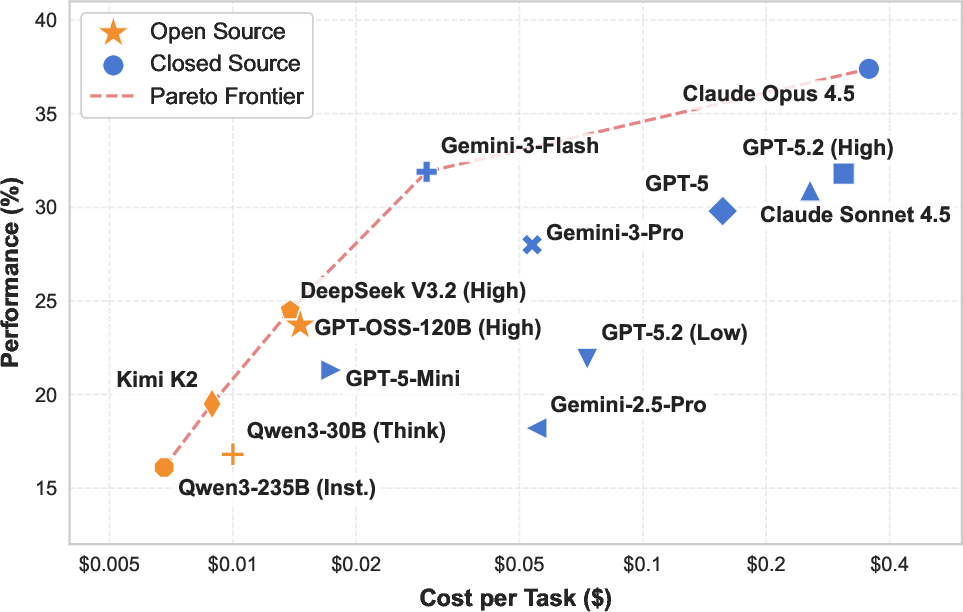
- Cost vs. performance:
- Some models give decent results for low cost; the very best results cost more per task. Since success rates are still far from perfect, none are ready to run on their own in real offices.
- Fancy multi‑agent setups didn’t fix it:
- Breaking tasks into subtasks and assigning “sub‑agents” often didn’t help and sometimes made things worse, likely because many tasks depend on doing steps in the exact right order.
- Common mistakes:
- Creating records without first looking up the necessary IDs (like adding a topic without checking its category), breaking links between tables
- Missing follow‑up steps required by policies (e.g., not setting a required option)
- Using guessed or wrong identifiers instead of verifying them
- Failing to send notifications correctly because needed info (like an email address) wasn’t resolved
Why this matters:
- In a real company, these errors can corrupt data, break workflows, or cause security problems. The results show that today’s AIs are not yet safe to run complex office systems by themselves.
Why this matters for the future
EnterpriseOps‑Gym gives researchers and builders a tough, realistic testbed to improve AI office “workers.” The biggest improvement areas are:
- Better long‑term planning and strategy, not just tool usage
- Stronger rule‑following and permission checks
- Reliable detection and refusal of unsafe or impossible tasks
- Safer behavior to avoid unintended changes
If progress continues, this kind of benchmark can guide the creation of AI assistants that are trustworthy, efficient, and safe to use in real companies—helping people with complex, multi‑step work while respecting policies and protecting data.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps and open questions that remain unresolved by the paper, intended to guide follow-on research.
- Bold theme: Oracle tool retrieval assumption hides end-to-end failure modes
- The benchmark primarily evaluates planning/execution with a perfect (oracle) tool set. It does not measure:
- Tool discovery from large, noisy catalogs (thousands of APIs) using documentation and schemas.
- Retrieval over heterogeneous sources (API docs, changelogs, UI affordances, KBs).
- Mis-retrieval and ambiguity resolution across similarly named tools or overlapping capabilities.
- Open questions: How do agents perform without oracles when APIs must be discovered, disambiguated, and parameterized from documentation? What retrieval strategies and representations (e.g., structured schemas, embeddings, plan-conditioned retrieval) reduce catastrophic miscalls?
- Bold theme: Limited modeling of real-world system dynamics and failures
- The sandbox appears largely deterministic and synchronous, omitting:
- Partial failures, timeouts, retries, rate limits, non-deterministic responses, and eventual consistency.
- Long-running workflows, background jobs, and asynchronous callbacks/notifications.
- Transactionality concerns (rollback, idempotency, compensating actions) and failure recovery.
- Open questions: How does error-handling competence (retry policies, backoff, transactional reasoning) affect performance? Can benchmarks inject stochastic failures and measure safe recovery?
- Bold theme: Narrow evaluation of safety/refusal behavior
- Only 30 infeasible tasks are provided; refusal scenarios do not appear to include:
- Adversarial inputs (prompt injections in tool outputs), conflicting policy directives, or ambiguous/underspecified tasks requiring clarification.
- Multi-constraint traps blending data unavailability with policy conflicts and temporal constraints at scale.
- Measurement of “refusal” seems to hinge on “no side effects” plus success/failure tags; it is unclear whether explicit, policy-grounded refusals are distinguished from silent non-action.
- Open questions: What taxonomy of refusal scenarios (policy, security, compliance, ethics, ambiguity) should be covered? How to score safe halting with justification and minimal probing? How to penalize side effects by severity?
- Bold theme: Policy and access control realism may be limited
- While policy constraints exist, it is unclear if they fully model:
- Rich RBAC/ABAC, impersonation/delegation, multi-tenant boundaries, approval workflows, and audit trails.
- Dynamic/temporal policies (e.g., time-bound access, emergency overrides) that change mid-trajectory.
- Open questions: How do agent policies interact with multi-user role hierarchies and approvals? Can agents proactively seek approvals, escalate, or switch personas safely?
- Bold theme: Lack of concurrency, collaboration, and multi-user state conflicts
- The environment does not appear to simulate concurrent edits, conflicting locks, or coordination with other agents/users.
- Open questions: How do agents maintain consistency under concurrent updates? Can they detect conflicts, negotiate locks, or roll back/merge changes?
- Bold theme: Limited assessment of interactive dialogues and requirement elicitation
- Tasks are primarily single-instruction with no simulated users providing evolving/implicit preferences or clarifications.
- Open questions: How do agents decide when to ask clarifying questions vs. proceed? Can user-simulator tasks be added to assess intent elicitation, consent, and confirmation behaviors?
- Bold theme: Restricted orchestration and planning approaches evaluated
- Experiments focus on ReAct, a single planner-executor, and one decomposition variant. Missing:
- Search-based planning (symbolic planners, partial-order planning), program synthesis/planning-as-code, or state-estimation with explicit world models.
- Memory architectures (episodic/working memory), plan repair, and self-verification/critique loops with guardrails (e.g., policy checkers).
- Open questions: Which planning paradigms (search vs. LLM-only) better handle long horizons and constraints? How to integrate verifiers/policy engines in-the-loop to prevent violations?
- Bold theme: Generalization and distribution shift are untested
- No reported splits for unseen tools, unseen tables/schemas, or entirely new domains; unclear how agents generalize beyond curated tasks.
- Open questions: How do models transfer to new APIs/schemas with similar semantics (e.g., different vendor HR/ITSM systems)? Can compositional generalization be measured with systematic schema perturbations?
- Bold theme: External validity to production systems is not established
- The paper does not quantify how benchmark performance correlates with outcomes in real ServiceNow/Salesforce/M365 instances involving auth flows, network variability, and vendor idiosyncrasies.
- Open questions: Does success on EnterpriseOps-Gym predict field performance? What calibration or domain-adaptation is needed for deployment?
- Bold theme: Tool semantics and documentation comprehension not evaluated
- Agents receive tool definitions; it is unclear whether they must parse long-form API docs, changelogs, or examples to infer preconditions/postconditions.
- Open questions: How to evaluate doc-grounded tool use—extracting preconditions, defaults, error codes, and side effects from unstructured documentation?
- Bold theme: Limited temporal and event-driven reasoning
- Although a Calendar domain exists, broader temporal challenges (deadlines, SLAs, reminders, chaining time-triggered automations) and event subscriptions are not emphasized.
- Open questions: Can agents reason over time-triggered workflows, pending states, and SLAs, and adapt plans as time-dependent constraints change?
- Bold theme: Security and adversarial robustness are underexplored
- Absent evaluations of:
- Prompt injection from tool outputs/DB fields, data exfiltration risks, or poisoning.
- Confused deputy problems (cross-domain privileges), and least-privilege enforcement.
- Open questions: How effectively can agents detect and neutralize untrusted data in tool responses? Can sandboxed “red team” tasks be added to probe exploitability?
- Bold theme: Evaluation metrics and diagnostics are narrow
- Primary metric is pass@1; limited reporting on:
- Partial credit for constraint satisfaction (graded severity), side-effect magnitude, number of rollbacks, or tool-call efficiency.
- Interpretability metrics (plan adherence rate, deviation points) and error taxonomies at scale.
- Open questions: What composite metrics best reflect enterprise risk (success, safety, efficiency, policy adherence)? How to measure and enforce plan fidelity?
- Bold theme: Cost and test-time compute methodology needs more rigor
- Cost per task is “estimated”; details (tokenization policies, vendor pricing updates, retries) are not fully specified. Compute scaling was studied for one open model only.
- Open questions: How do cost-performance curves differ across planning strategies, refusal behavior, and longer horizons? What are robust, reproducible costing protocols?
- Bold theme: Limited breadth/depth of negative and edge-case coverage
- Only 30 infeasible tasks versus 1,120 feasible; limited coverage of:
- Data sparsity, ambiguous entity resolution, cross-database joins with missing links, or conflicting records.
- Rare but critical edge cases (e.g., circular dependencies, cyclic approvals, orphan repair).
- Open questions: How to systematically generate and scale hard negatives and rare failure modes? Can coverage be quantified via schema/constraint fuzzing?
- Bold theme: Data/version drift and schema evolution not modeled
- No scenarios where API versions or schemas change mid-execution; no rolling upgrades or deprecations.
- Open questions: Can agents detect and adapt to API/schema evolution, read deprecation notices, and migrate calls safely?
- Bold theme: Memory and long-context management not isolated
- The benchmark does not separately evaluate long-context retrieval, memory compaction, and recall under strict token budgets with dense policy/tool information.
- Open questions: Which memory mechanisms (vector DBs, structured memory, summaries) best maintain state across 10–30+ step horizons?
- Bold theme: Human-in-the-loop oversight and handoff not studied
- No evaluation of “when to escalate,” confidence calibration, or interactive oversight loops that combine human approvals with autonomous execution.
- Open questions: What escalation policies optimize reliability and cost? How to design verifiable handoff points that prevent unsafe autonomy?
- Bold theme: Release structure and overfitting guardrails
- It is unclear whether the benchmark provides public/private splits, hidden tests, or rotation to deter overfitting when used for training.
- Open questions: How to maintain a stable, evolving benchmark with versioning and seeding that supports both training and fair evaluation?
- Bold theme: GUI-based workflows and mixed-modality tool use not covered
- The benchmark centers on function-calling; many enterprise tasks require browser/desktop GUI automation, OCR, attachments, and rich documents.
- Open questions: How to integrate API and GUI agents, and how to evaluate cross-modality execution with attachments, forms, and unstructured inputs?
- Bold theme: Provenance, auditability, and explainability
- While SQL verifiers measure outcomes, there is no evaluation of:
- Action provenance logs, justification quality for audits, or explainability of plan-policy linkage.
- Open questions: Can agents produce auditable traces mapping every action to policy clauses and approvals, and can benchmarks score audit readiness?
Practical Applications
Below is an overview of practical, real-world applications suggested by the paper’s findings and artifacts (EnterpriseOps-Gym benchmark, methods, and analyses). Each item highlights sectors, concrete tools/workflows that could emerge, and feasibility considerations.
Immediate Applications
The following applications can be deployed now with moderate integration work, leveraging EnterpriseOps-Gym as a reproducible, high-fidelity enterprise testbed.
- Pre-deployment evaluation and regression testing for enterprise agents (software/IT operations; sectors: ITSM, CSM, HR, collaboration tools)
- What: Use EnterpriseOps-Gym as a CI/CD “AgentOps” harness to test pass@1 completion, refusal behavior, and side-effect checks before agents touch production.
- Tools/products/workflows: Agent CI pipelines, outcome-based SQL verifiers wired to staging DBs, “AgentOps Dashboard” tracking domain-wise reliability and horizon risk.
- Assumptions/dependencies: Mapping gym tools/tables to your org’s APIs/schemas; sim-to-real gap needs mitigation; policies must be encoded in prompts/tools.
- Vendor/model selection and cost–performance tuning (industry/procurement/finance; sectors: platform teams, CoEs)
- What: Use the paper’s cost–performance trade-offs and horizon analytics to choose models and set thinking-budget policies per workflow.
- Tools/products/workflows: “ThinkBudget Controller” that adapts test-time compute by domain/risk; procurement scorecards tied to benchmark KPIs.
- Assumptions/dependencies: Model prices change; representative task mix must match your org; accuracy depends on tool discovery quality (paper uses oracle tools).
- Plan-conditioned execution in production (software engineering/operations; sectors: ITSM/CSM/HR automation)
- What: Deploy planner+executor architectures and library of human-authored “playbooks” for complex workflows, improving reliability immediately.
- Tools/products/workflows: Plan templates for ticket triage, entitlement checks, HR topic/category operations; plan-following executors with step-by-step adherence.
- Assumptions/dependencies: SMEs needed to author/maintain plans; plan drift across business units; ensure policy updates propagate to plan library.
- Guardrails for policy compliance and safe refusal (compliance, security, risk; sectors: regulated operations)
- What: Train/evaluate refusal behavior using the benchmark’s infeasible tasks; integrate rule-based or learned “RefusalGuard” modules that intercept policy-violating steps.
- Tools/products/workflows: Policy-to-prompt compiler; refusal classifiers with DB lookups for evidence; pre-execution feasibility checks.
- Assumptions/dependencies: Policy formalization quality; access control integration; refusal metrics require outcome-based verification.
- Post-execution safety monitors and side-effect detection (IT operations; sectors: DB-backed enterprise apps)
- What: Port SQL verifiers to staging/production (read-only or “dry-run”) to detect unintended state changes and ensure referential integrity.
- Tools/products/workflows: “StateGuard Verifier” that runs after agent batches; state-diff reports; automatic rollback hooks where supported.
- Assumptions/dependencies: DB access, consistent schemas/foreign keys; performance overhead of verifiers; rollback capability varies by system.
- Data and curricula for planning-focused training (industry R&D, academia; sectors: LLM training, ML Ops)
- What: Use human-authored plans and outcome verifiers to fine-tune or distill planning modules and reward models focused on constraint-aware reasoning.
- Tools/products/workflows: Planner SFT datasets; plan-quality critics; verifier-driven RL signals targeting policy adherence and horizon stability.
- Assumptions/dependencies: Licensing and access to benchmark assets; compute budget; data alignment to your production schemas/tools.
- Benchmark-driven research on long-horizon, stateful execution (academia/industrial research)
- What: Reproducible experiments on horizon scaling, thinking-budget scheduling, tool overload robustness, and multi-agent orchestration.
- Tools/products/workflows: Baseline suites (ReAct, planner+executor), horizon-stratified leaderboards, ablations on state tracking and memory.
- Assumptions/dependencies: Containerized environment setup; consistent evaluation protocols; compare with and without oracle tools.
- Risk-based agent governance policies (policy/organizational governance)
- What: Set deployment gates using benchmark metrics (e.g., pass@1 > X% and refusal > Y% for a given domain/horizon) and enforce human-in-the-loop for high-risk workflows.
- Tools/products/workflows: Governance playbooks per domain; escalation on infeasibility; audit logs tied to verifier outcomes.
- Assumptions/dependencies: Leadership buy-in; mapping technical metrics to risk appetite; ongoing monitoring.
- SMB and personal productivity prototypes using collaboration domains (daily life/small business; sectors: email/calendar/drive/teamware)
- What: Prototype agents that organize calendars, manage files, or draft team updates, validated against gym collaboration tasks before real deployment.
- Tools/products/workflows: Lightweight assistants with plan-conditioned workflows for scheduling, mailbox triage, document management.
- Assumptions/dependencies: Adapting enterprise schemas to consumer/SaaS APIs; privacy safeguards; simpler policies may reduce need for complex planning.
Long-Term Applications
These applications require further research and engineering advances—especially in strategic planning, policy formalization, and robust state management—to be enterprise-ready.
- Autonomous enterprise AI workers for end-to-end workflows (industry; sectors: CSM, HR, ITSM, cross-domain operations)
- What: Agents that plan/execute multi-step tasks across systems (e.g., resolve IT incidents, update entitlements, notify stakeholders) with policy-aware execution.
- Tools/products/workflows: Cross-domain orchestrators; memory/state tracking; policy-aware planners; automatic feasibility/impact analysis prior to commits.
- Assumptions/dependencies: Substantial gains in long-horizon planning and refusal reliability; safe transaction models; strong observability.
- Certification and standards for enterprise agents (policy/standards bodies)
- What: “Agent Reliability Index” and safety certification suites derived from EnterpriseOps-Gym tasks, thresholds, and verifiers.
- Tools/products/workflows: Standardized task packs per domain; audit-grade verifiers; minimum refusal/side-effect criteria for certification.
- Assumptions/dependencies: Industry/regulator consensus; vendor participation; task generalization across platforms.
- Policy-aware planning engines and neuro-symbolic hybrids (software/AI research)
- What: Planners that integrate LLMs with constraint solvers and policy knowledge bases to generate verifiably compliant plans.
- Tools/products/workflows: Structured policy stores; plan verifiers; constraint solving over DB schemas and access rules; plan repair when constraints fail.
- Assumptions/dependencies: Formal policy representations; efficient solver-LLM interfaces; datasets of policy–action pairs.
- Transaction-safe agent execution and state isolation (software/IT; sectors: DB-centric enterprise apps)
- What: End-to-end transactionality with dry-runs, rollbacks, and state diffs; commit gates driven by verifiers and impact analysis.
- Tools/products/workflows: Shadow databases; two-phase commit for agent actions; reversible tool calls; automatic anomaly detection.
- Assumptions/dependencies: Underlying systems must expose transactional APIs; performance overhead management.
- Multi-agent orchestration robust to sequential dependencies (software/robotics)
- What: Architectures that coordinate specialized agents without breaking stateful task dependencies seen to cause regressions in naive decompositions.
- Tools/products/workflows: Orchestration policies that detect and preserve dependency chains; shared state abstractions; subtask verification checkpoints.
- Assumptions/dependencies: New algorithms for dependency-aware decomposition; improved shared memory/state interfaces.
- Enterprise digital twins for AI agent training (industry/academia; sectors: operations, IT)
- What: Scaling the gym into “company-scale” sandboxes mirroring an organization’s processes, policies, and data topology for safe pretraining and stress tests.
- Tools/products/workflows: Synthetic-yet-realistic data generators; domain-specific task libraries; privacy-preserving schema mirroring.
- Assumptions/dependencies: Data anonymization; maintenance overhead; continuous sync with evolving production systems.
- Open standards for enterprise tool schemas and policy metadata (industry consortia; sectors: SaaS/vendors)
- What: Standardized function signatures, policy annotations, and verification contracts to reduce sim-to-real friction for agent deployment.
- Tools/products/workflows: “Enterprise Tool Schema” (ETS) spec; policy metadata schemas; portable verifier packs.
- Assumptions/dependencies: Vendor buy-in; backwards compatibility; governance of schema evolution.
- Cost-effective open-source agent stacks for SMBs (industry; sectors: services, retail, startups)
- What: Open-weight models tuned on planning and refusal using gym data, paired with dynamic thinking budgets for reliable low-cost automation.
- Tools/products/workflows: OSS “AgentOps” bundles; prebuilt plan libraries for common tasks; budget-aware inference controllers.
- Assumptions/dependencies: Open models must close planning/refusal gaps; community-curated plans/verifiers.
- Education and workforce upskilling in agent engineering (education; sectors: CS/IS programs, corporate L&D)
- What: Hands-on courses using the gym to teach planning, tool integration, safety verification, and governance.
- Tools/products/workflows: Course modules; capstone projects; evaluation rubrics aligned to pass@1/side-effect metrics.
- Assumptions/dependencies: Compute resource provisioning; instructor expertise; updated task packs.
- Risk-based AI governance frameworks (policy/enterprise risk)
- What: Regulatory and internal governance models that classify workflows by horizon/policy sensitivity and tie oversight levels to proven benchmark performance.
- Tools/products/workflows: Risk tiers (e.g., policy-heavy ITSM vs. low-risk collaboration); deployment gates; periodic re-certification.
- Assumptions/dependencies: Stable benchmarks; alignment with industry regulations; monitoring infrastructure.
Notes on feasibility across applications
- Key bottleneck: Strategic planning—not tool discovery—limits reliability; gains require better constraint-aware plan generation and long-horizon stability.
- Retrieval vs. oracle tools: Paper’s evaluations assume ideal tool retrieval; real deployments need robust tool discovery or curated toolsets.
- Policy formalization: Effectiveness depends on translating organizational policies into machine-checkable constraints and well-scoped tools.
- Cost controls: Thinking-budget improvements boost performance but increase spend; dynamic budget policies and escalation-to-human workflows are critical.
- Sim-to-real alignment: Success depends on schema/API mapping, data distributions, and policy fidelity; a calibration phase is recommended before production.
Glossary
- Access control policies: Rules that restrict what users or agents can do in a system based on roles and permissions. "access control policies and procedural rules"
- Agentic planning: The process by which autonomous agents devise and execute multi-step plans using tools to achieve goals. "evaluate agentic planning in realistic enterprise settings."
- Cascading State Propagation: Ensuring that required follow-up actions occur when certain state changes happen, to keep system behavior consistent. "Models also fail to trigger the follow-up actions mandated by system policies when certain state transitions occur (Cascading State Propagation)."
- Constraint-aware reasoning: Reasoning that accounts for rules and policies when planning and acting. "These are precisely the domains where constraint-aware reasoning is unavoidable."
- Containerized docker sandbox: An isolated, reproducible Docker-based environment for databases, APIs, and tools to safely evaluate agents. "a containerized docker sandbox hosting domain-specific databases, APIs, and the tool execution layer."
- Cross-domain orchestration: Coordinating actions and data across multiple systems or domains within a single workflow. "cross domain orchestration"
- Decomposition architecture: A multi-agent setup that splits a task into subtasks executed by different agents. "the decomposition architecture is less robust."
- Final-state verifiers: Checks that evaluate only the final system state to determine task success, regardless of the action path. "They are evaluated by final-state verifiers that check goal completion, policy compliance, and side effects."
- Foreign key constraints: Database rules that ensure references between tables point to valid rows. "integrity constraints (are foreign key constraints respected?)"
- Foreign Keys (FK): Columns that reference primary keys in other tables to maintain relationships. "we measure the average number of Foreign Keys (FK) per table."
- Gold-standard trajectory: An expert-executed sequence of steps and tool calls serving as the reference solution for a task. "capture a gold-standard trajectory"
- Infeasibility detection: The ability of an agent to recognize that a task cannot be completed and refuse safely. "Infeasibility detection is a critical weak point,"
- Infeasible tasks: Tasks intentionally made impossible due to policy conflicts, tool limitations, or resource unavailability. "including 30 infeasible tasks designed to evaluate safe refusal behavior."
- Information Technology Service Management (ITSM): A discipline focused on delivering and managing IT services and operations. "Information Technology Service Management (ITSM)"
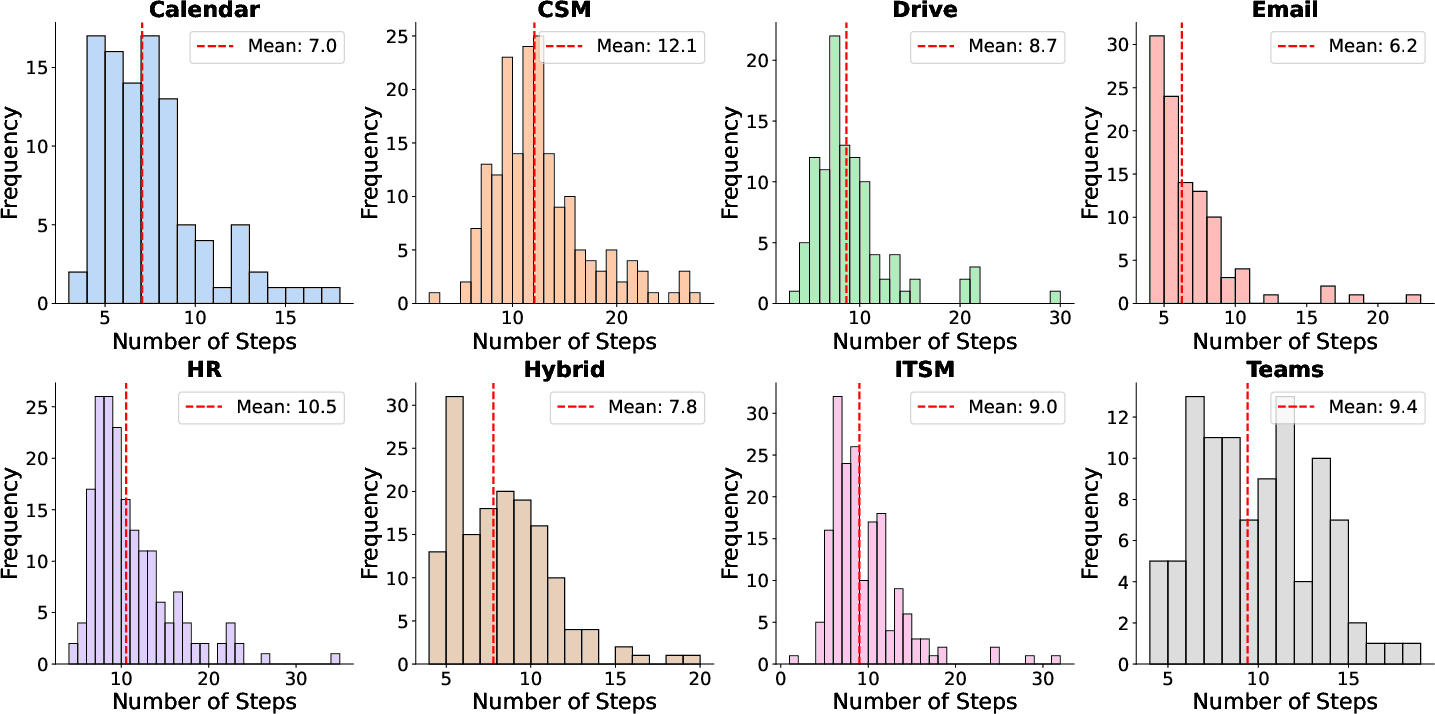
- Long-horizon planning: Planning that spans many steps and requires maintaining and manipulating persistent state across actions. "the need for long-horizon planning amidst persistent state changes"
- Missing Prerequisite Lookup: A failure mode where required lookups are skipped before creation or updates, causing broken references. "producing dangling records with broken foreign-key links (Missing Prerequisite Lookup)."
- Multi-agent orchestration: Coordinating multiple agents (e.g., planner, subtask executors) to solve a task collaboratively. "More complex multi-agent orchestration does not close this gap either;"
- Oracle human plans: Human-authored step-by-step plans given to agents to follow during execution. "providing oracle human plans improves performance by 14--35 percentage points,"
- Oracle-tool setting: An evaluation mode where a perfect retriever provides the correct tools to the agent, isolating planning from tool discovery. "oracle-tool setting where we assume a perfect retriever supplies the agent with the right set of tools."
- Outcome-based verification: Evaluating success by checking final-state conditions (e.g., goal completion, integrity) rather than specific action sequences. "outcome-based verification enforcing goal completion, state integrity, policy compliance, and side-effect checks,"
- Pareto frontier: The set of non-dominated trade-offs between cost and performance where improving one dimension worsens the other. "As shown by the Pareto frontier in \Cref{fig:cost_vs_preformance},"
- Pareto-dominant: A point on the cost–performance curve that is not outperformed by any other point in both dimensions. "emerges as the Pareto-dominant option"
- Pass@1: A metric measuring the proportion of tasks successfully completed on the first attempt. "We evaluate models using pass@1 task completion rate,"
- Planner-executor baseline: A system where one component generates a high-level plan and another executes it via tool calls. "We introduce a planner-executor baseline"
- Planning horizon: The expected number of sequential steps required to complete a task. "planning horizons varying considerably across domains,"
- Policy compliance: Adhering to organizational or system policies during task execution. "policy compliance"
- Policy-constrained execution: Performing actions that are explicitly restricted and guided by system policies. "policy-constrained execution"
- Policy-governed domains: Domains where strict policies heavily constrain and shape permissible actions. "policy-governed domains such as ITSM"
- ReAct-style loop: A prompting and control pattern that interleaves reasoning steps with tool executions. "We use a standard ReAct-style reasoning and tool-execution loop"
- Referential integrity: The correctness and consistency of relationships enforced by foreign keys across tables. "making referential integrity a key challenge."
- Relational density: The degree of inter-table connectivity in a database schema. "indicating relational density and the complexity of inter-table dependencies"
- Side-effect checks: Verifications ensuring that the agent did not cause unintended changes to the system. "side-effect checks"
- Stateful: Characterized by actions that depend on and modify persistent system state. "Actions are stateful and often irreversible,"
- Subject Matter Expert (SME): A domain expert who designs, validates, and verifies tasks and environments. "Subject Matter Experts (SMEs)"
- Test-time compute: The amount of computation allocated during inference, which can affect planning quality. "Test-time compute scaling helps but is not a universal remedy,"
- Thinking budget: The allocated token or computation budget for an agent’s deliberation during inference. "the impact of test-time compute by varying the thinking budget"
- Tool execution layer: The system component responsible for executing function/tool calls initiated by the agent. "the tool execution layer."
Collections
Sign up for free to add this paper to one or more collections.