- The paper proposes POLCA, a framework that uses LLMs to optimize complex systems through stochastic candidate generation and memory-based selection.
- It employs an embedding-based ε-Net filter to maintain candidate diversity and efficiently manage evaluation costs in the face of noise.
- Empirical results across benchmarks demonstrate POLCA’s superior convergence speed and robust performance compared to traditional search methods.
Authoritative Analysis of "POLCA: Stochastic Generative Optimization with LLM" (2603.14769)
"POLCA: Stochastic Generative Optimization with LLM" introduces the POLCA framework, targeting the optimization of complex systems (e.g., LLM prompts, multi-turn agents, code generators) via generative LLMs. The authors formalize this as a stochastic generative optimization problem: an LLM acts as an optimizer, proposing parameterized program modifications guided by numerical rewards and textual feedback. The core challenges addressed are stochasticity (from program execution, minibatch sampling, noisy evaluators) and the unconstrained expansion of solution space—a result of LLMs generating semantically redundant candidates.
POLCA maintains a memory buffer organized as an ε-Net, ensuring diversity among stored candidates and bounding evaluation costs. In each optimization step, POLCA selects promising candidates from the buffer, evaluates them on a sampled minibatch, proposes new parameters, applies semantic filtering (based on embeddings), and updates the buffer, compressing historical context for meta-learning.
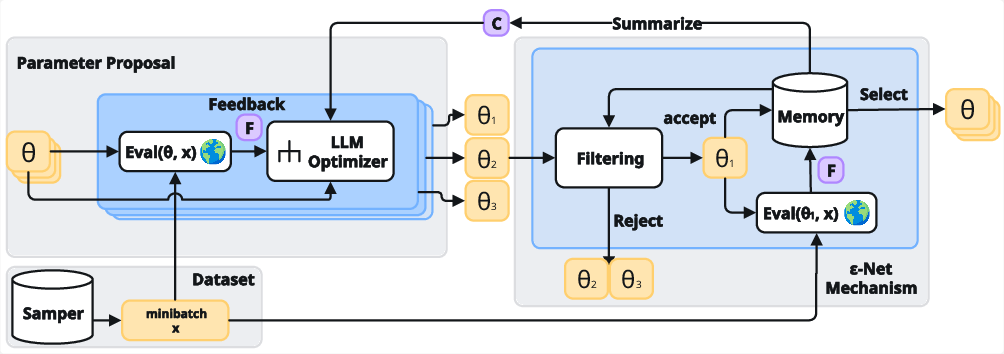
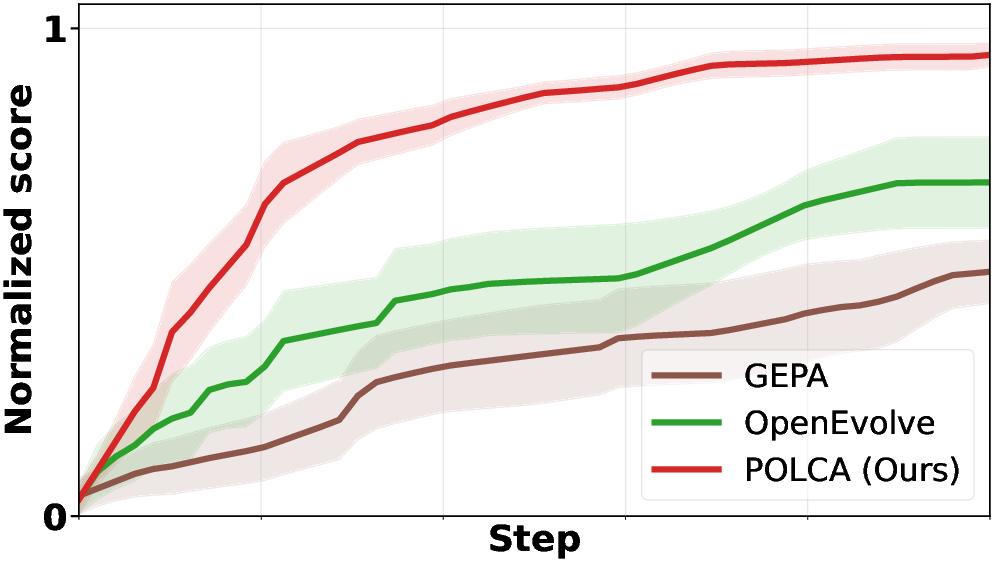
Figure 1: The POLCA optimization cycle, including diverse memory management, candidate selection/evaluation, semantic filtering, and global summarization.
Algorithmic Contributions
Memory Buffer and Priority Queue
POLCA incorporates a priority queue for memory management, tracking candidates and their empirical evaluation history. Priority scores are derived from empirical means (optionally UCB scores), facilitating systematic exploration/exploitation. Candidates with superior empirical performance are repeatedly evaluated, and memory is dynamically updated, smoothing evaluation variance.
ε-Net Semantic Filtering
A fundamental mechanism is the embedding-based ε-Net: new candidate parameters are accepted only if their semantic embedding distance exceeds a threshold ε from all currently stored programs. This principle, theoretically justified by the authors, addresses uncontrolled memory sprawl and evaluation cost. Embedding-based filtering provides scalable diversity and leverages modern LLM embedding models.
POLCA integrates an external LLM Summarizer, which analyzes historical buffer content and compresses context into actionable guidance for the optimizer. This meta-learning component assists in trajectory stabilization and escaping local optima, exploiting population-level information rather than myopic local updates.
Theoretical Analysis
The authors provide rigorous convergence guarantees for POLCA. Under mild assumptions—specifically, that the optimizer can yield strict improvements with positive probability and rewards are sub-Gaussian—POLCA converges to near-optimal candidate solutions. The sample complexity is bounded by terms reflecting stochasticity in evaluations and optimizer efficiency. For deterministic problems, the complexity depends solely on reward space and optimizer strength, demonstrating that persistent memory and semantic filtering yield superior convergence compared to sequential updating or Pareto/beam search.
Empirical Evaluation and Results
POLCA is instantiated on four representative benchmarks: τ-bench (LLM agent prompt optimization), HotpotQA (multi-hop QA), VeriBench (code translation to Lean 4), and KernelBench (CUDA kernel generation). Each domain presents distinct sources of stochasticity. Comparative evaluations with baselines (DSPy, GEPA, OpenEvolve) demonstrate clear superiority in convergence speed and final performance, both under stochastic and deterministic regimes.
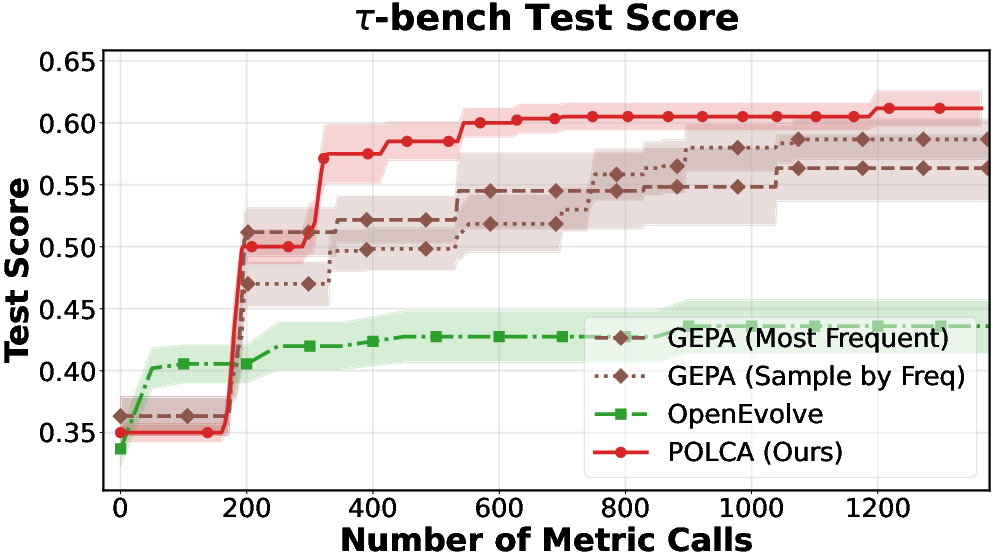
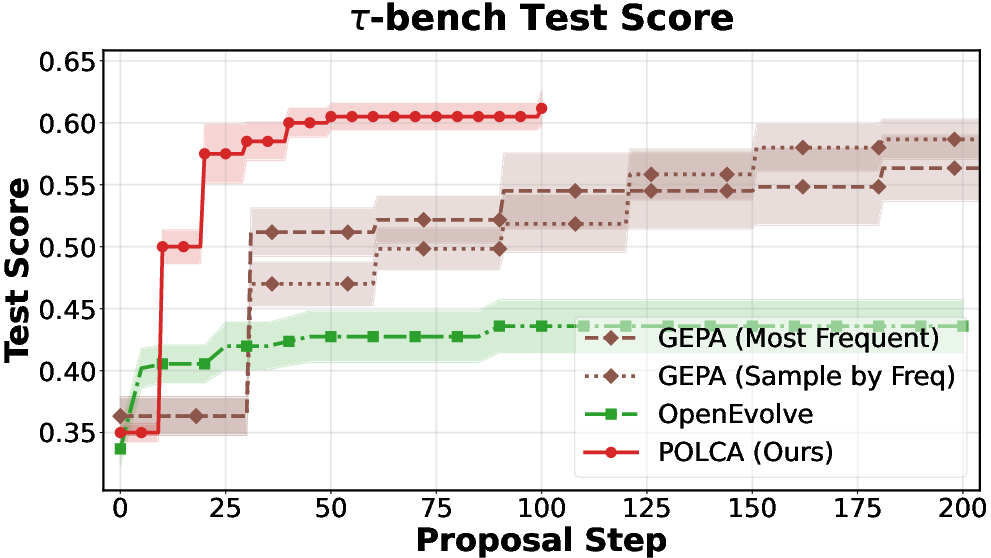
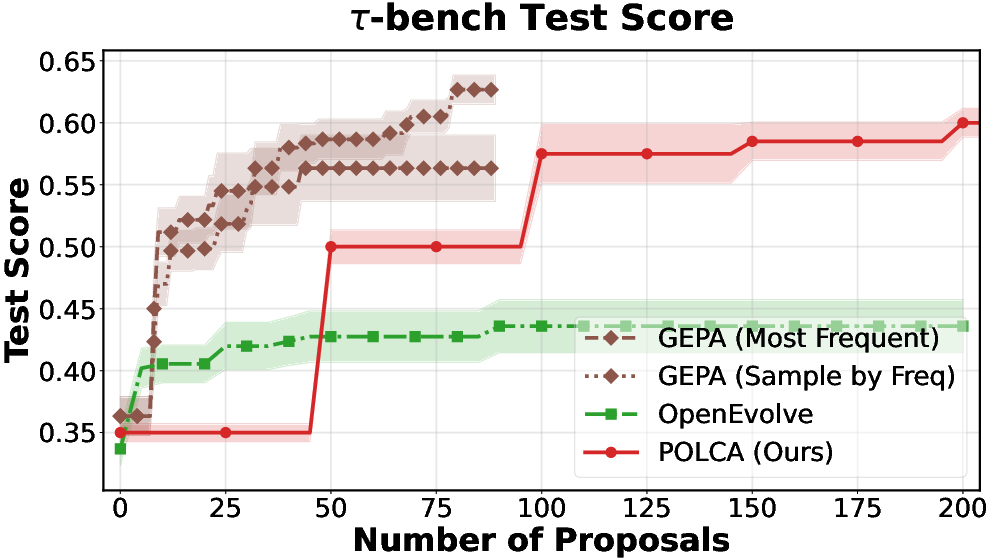
Figure 2: τ-bench: performance scaling with number of samples, proposal steps, and number of proposals.
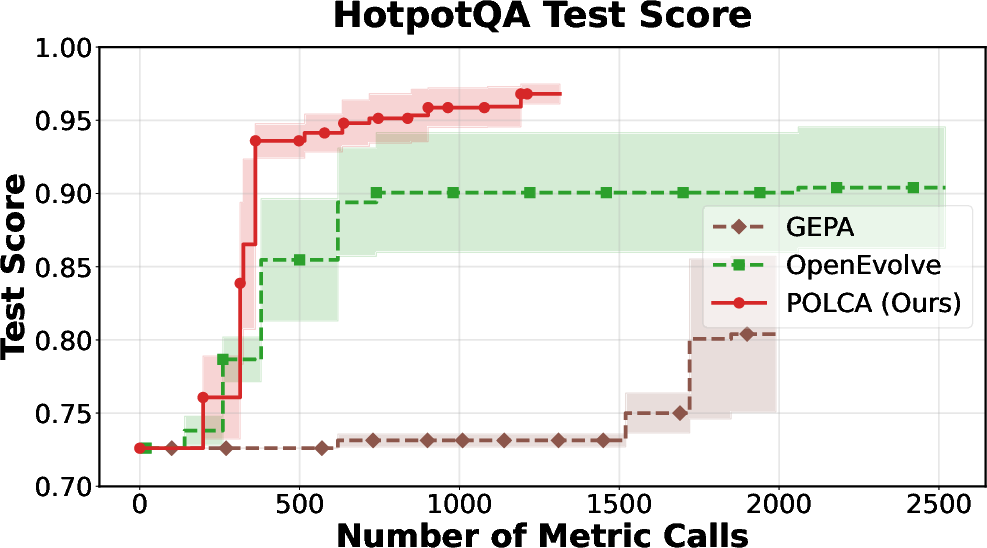
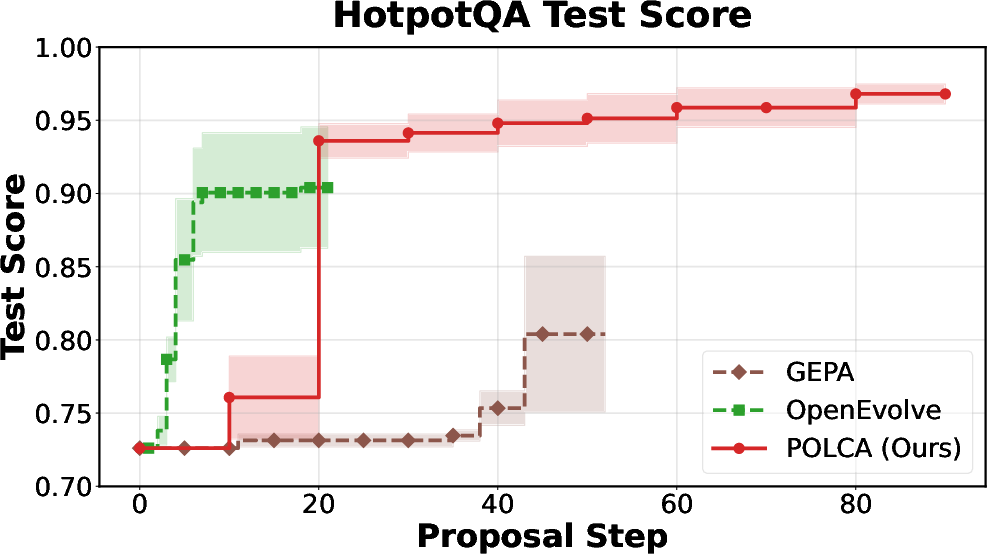
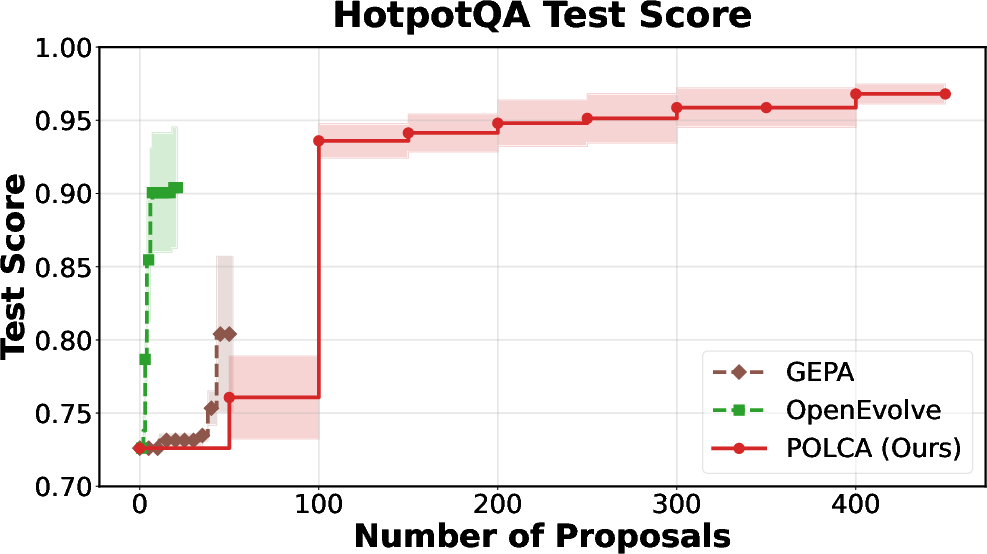
Figure 3: HotpotQA: optimization efficiency versus computational budget.
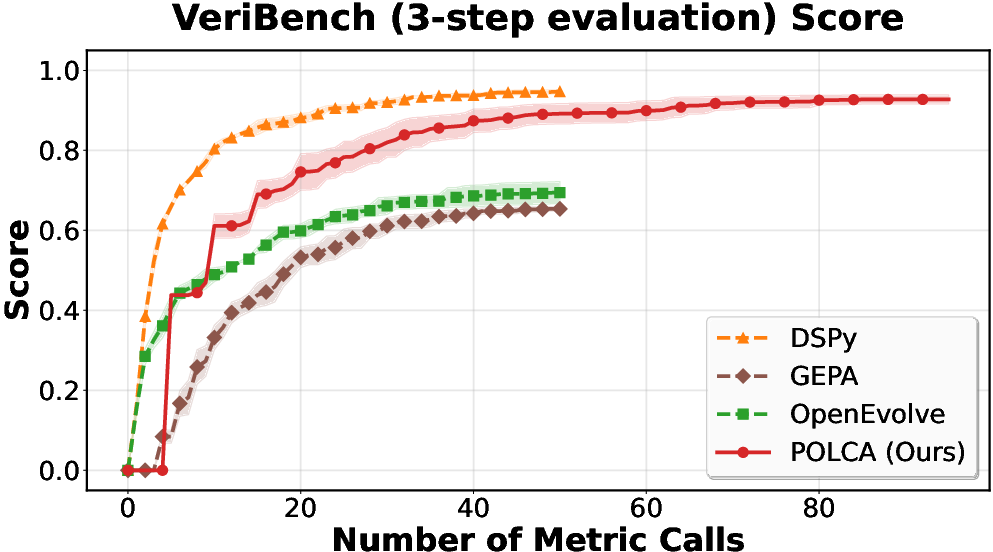
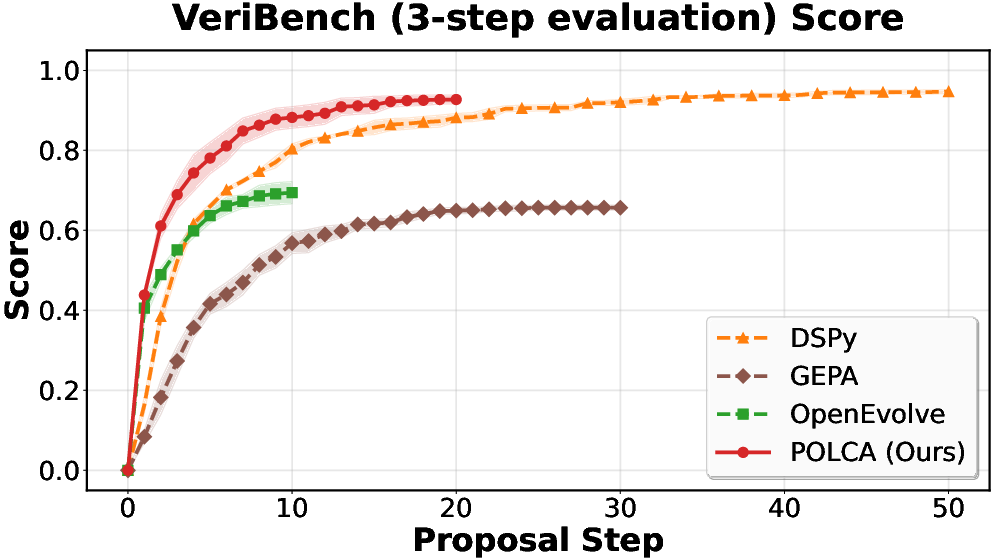
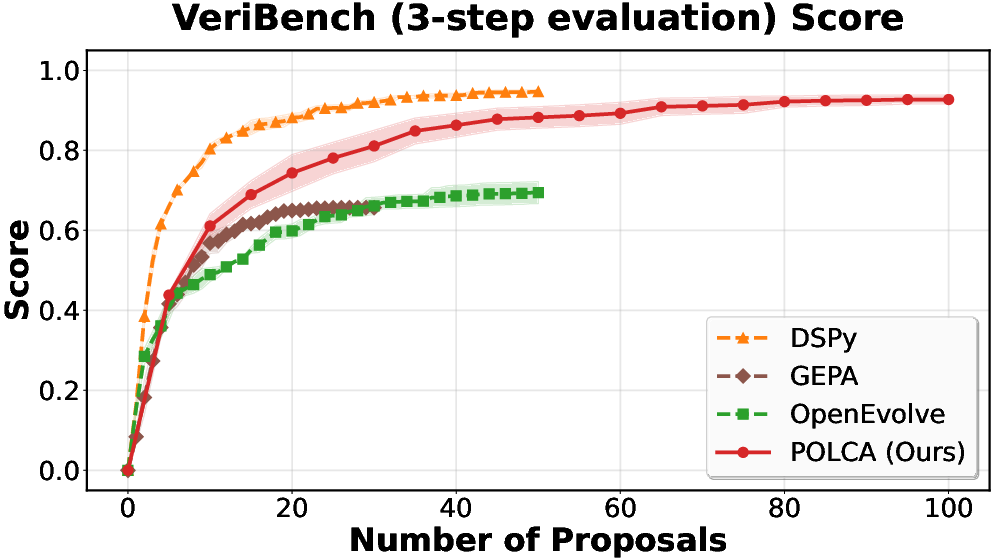
Figure 4: VeriBench: robustness under stochastic evaluator regimes.
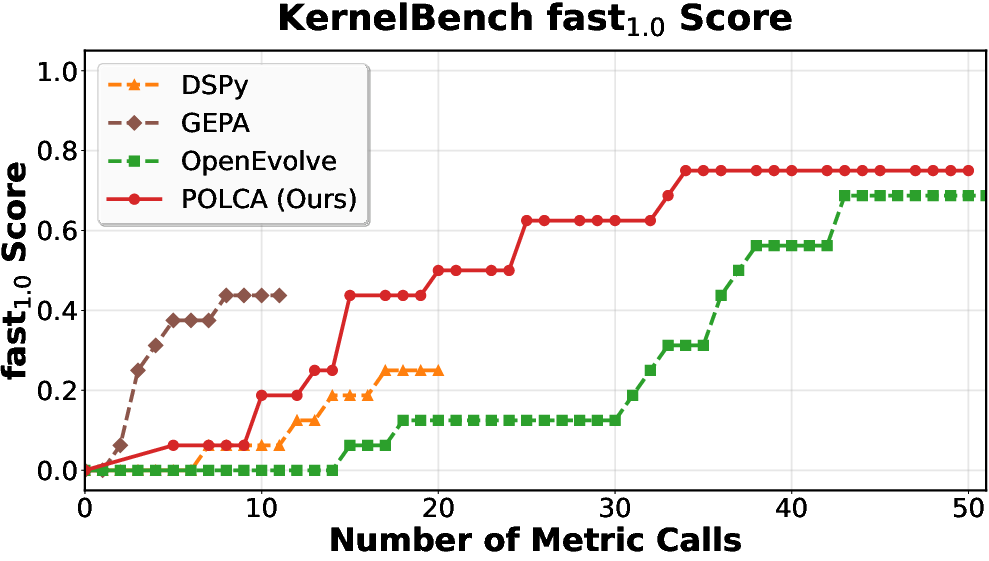
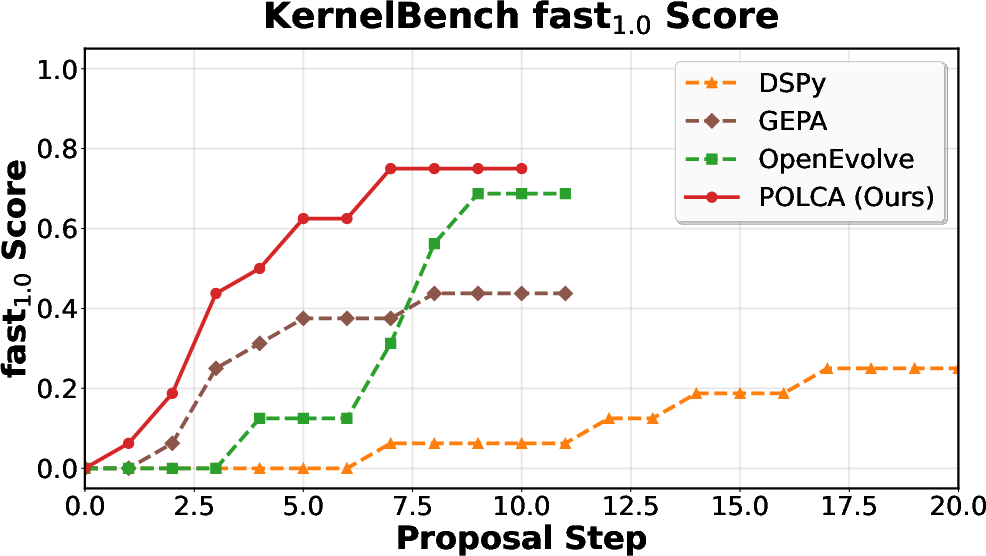
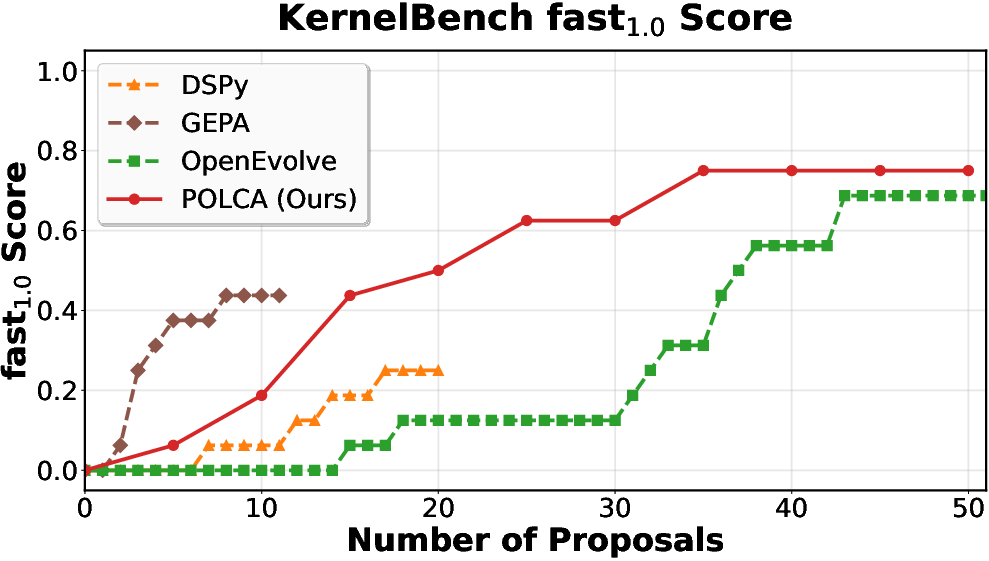
Figure 5: KernelBench: deterministic optimization performance as a function of computation.
Ablation studies confirm the contributions of the ε-Net filter and Summarizer (see Figure 6, Figure 7), revealing both components as critical for efficient search and variance reduction. Further sensitivity analyses (Figure 8) indicate that POLCA’s performance is robust to ε selection within reasonable ranges; however, large values induce approximation error, and ε=0 yields degraded outcomes.
Analytical Comparison with Bandit, Evolution, and Beam Search Methods
POLCA’s algorithmic structure subsumes classical search approaches by simply modifying the priority function and memory management. Empirical evidence suggests that approaches such as beam search, Pareto-frontier, or MAP-Elites degenerate or fail to scale in the presence of stochastic evaluations—often discarding candidates prematurely or becoming sensitive to noisy observations. In contrast, POLCA’s continuous reevaluation and memory persistency avoid the pitfalls of premature exploitation and catastrophic resets, yielding strong empirical and theoretical guarantees.
Practical Implications and Future Directions
POLCA’s design directly addresses robustness and scalability for generative optimization with LLMs, particularly in real-world setups where stochasticity is the norm (e.g., interacting with expensive evaluators, noisy human feedback, stochastic agent execution). The embedding-based filtering enables principled tradeoffs between diversity and evaluation cost, critical for practical deployment. The framework generalizes across prompt engineering, code synthesis, formal verification, and agentic orchestration.
Potential future advances include integrating more sophisticated reward modeling within the memory buffer, adaptive tuning of ε thresholds, extension to multimodal generative optimization, and formalizing performance guarantees under non-sub-Gaussian or heavy-tailed reward distributions. Further model improvements (e.g., higher-capacity Summarizers) and leveraging contrastive task histories for enhanced meta-learning may drive additional sample and computation efficiency.
Conclusion
"POLCA: Stochastic Generative Optimization with LLM" provides a theoretically grounded and empirically validated framework for scalable generative optimization, combining memory persistency, semantic filtering, and meta-learning summarization. Across diverse benchmarks, POLCA demonstrates sample-efficient and robust performance, outperforming baselines in both deterministic and stochastic settings. The work has practical implications for large-scale LLM system optimization and lays a foundation for further advances in generative search under uncertainty.