- The paper introduces an eight-class taxonomy of invisible AI failures, defining key archetypes like the confidence trap and drift using over 196,000 annotated chat transcripts.
- The methodology employs hierarchical annotation with global quality labels and signal tags to distinguish between visible and invisible failures in real-world interactions.
- The study finds that 78% of goal failures are invisible and predominantly interaction-driven, emphasizing persistent risks even with advanced AI models.
Invisible Failures in Human–AI Interactions: Taxonomy, Prevalence, and Structural Dynamics
Overview and Motivation
The paper "Invisible failures in human-AI interactions" (2603.15423) presents a comprehensive empirical investigation into the landscape of AI failure modes that evade typical detection: "invisible failures." Leveraging the WildChat dataset—comprising over one million public ChatGPT (primarily GPT-4) conversation transcripts—the study systematically annotates nearly 200,000 English-language dialogues for qualitative performance, signal tags, and typologies of failures. The primary thesis is that AI systems, despite high-visibility benchmarks and overt user complaints, are systematically failing in ways that commonly go unnoticed. Detection, monitoring, and mitigation of these phenomena are crucial for AI deployment across domains with consequential impacts.
Methodology and Analysis Pipeline
The approach centers on hierarchical annotation: each transcript receives a single overall quality label {good, acceptable, poor, critical}, accompanied by zero or more signal tags from a taxonomy of 28 context-sensitive interaction markers (e.g., {ai_off_topic_drift}, {goal_failure}, {ai_false_confidence}). Annotation is primarily executed using Claude Sonnet 4.5, followed by manual audits for calibration. Explicit adversarial, ambiguous, and non-English interactions are filtered out to yield a core sample of 196,704 transcripts.
The study introduces a systematic process for distinguishing between visible and invisible failures. Only those goal failures lacking explicit user correction, dissatisfaction, or clarification ("visible signals") are deemed invisible. The taxonomy of invisible failures is built by mapping co-occurring signal tags to archetypes, forming an eight-class set covering the vast majority of failures undetected via standard user-facing cues.
Quality Assessment of Human–AI Interactions
The global quality distribution is dominated by "good" or "acceptable" transcripts (84%), but there remains a substantial minority (16%) of "poor" or "critical" cases, flagging many serious interaction breakdowns given current usage volumes. Signal density correlates sharply with quality: 90% of "good" conversations lack negative tags, while almost all "poor" and "critical" cases exhibit multiple negative interactions.
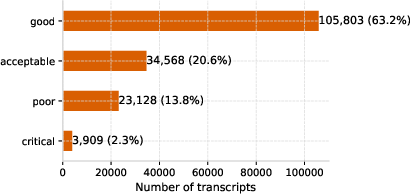
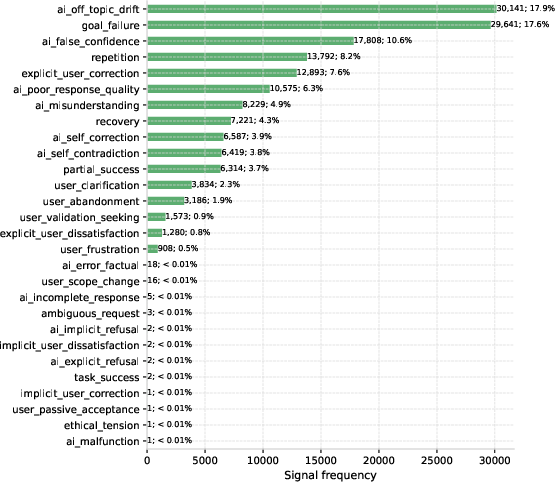
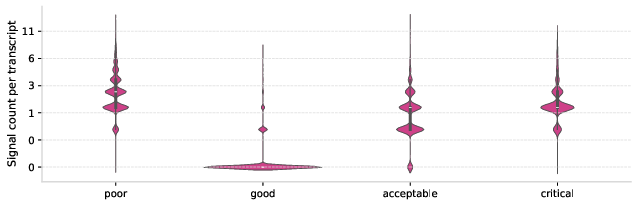
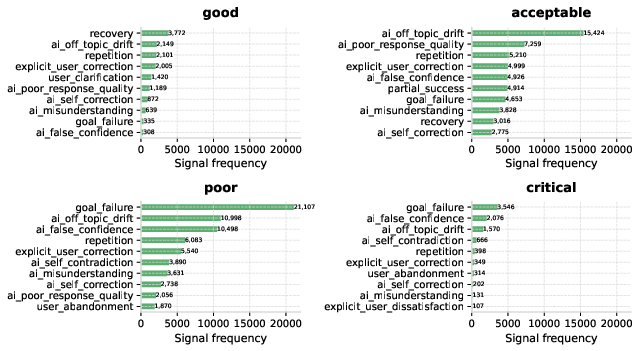
Figure 1: Distribution of overall quality categories reflects predominance of ‘good’ and ‘acceptable’ outcomes but a nontrivial ‘poor’/‘critical’ tail.
Yet, the "acceptable" tier emerges as an area of hidden risk. Although these transcripts achieve user goals, 93% contain at least one quality signal, indicating many interactions succeed while harboring latent, undetected issues.
Invisible Failure Archetypes: Prevalence and Patterns
The crux of the analysis is the decomposition of invisible failures into eight archetypes:
- The confidence trap: False, unsupported assertions delivered with unwarranted confidence.
- The silent mismatch: Subtle misunderstanding or implicit refusal without user detection.
- The drift: AI shifting away from user objectives, often gradually.
- The death spiral: Looping or repetition leading to disengagement.
- The contradiction unravel: Incoherence or self-contradiction coursing through the dialogue.
- The walkaway: User disengagement without overt complaint.
- The partial recovery: Attempts at recovery after error, incomplete or unsatisfactory.
- The mystery failure: Residual category lacking diagnoseable signals beyond global failure.
Invisible archetypes account for 78% of all goal failures. Notably, "drift" and "confidence trap" alone outnumber visible failures. This indicates that the majority of AI errors are likely to pass undetected in production systems reliant on user feedback mechanisms.
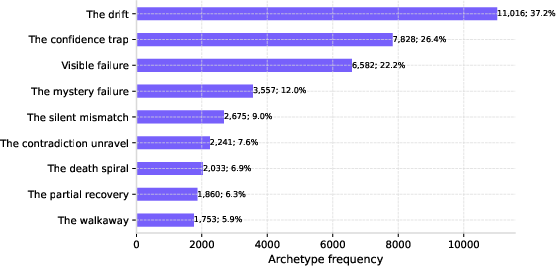
Figure 2: The frequency distribution of invisible failure archetypes in the WildChat sample highlights ‘drift’ and ‘confidence trap’ as leading patterns.
Analysis of archetype severity reveals high concern for "silent mismatch" and "walkaway," both disproportionately associated with "poor" outcomes but potentially under-recognized due to their subtlety.
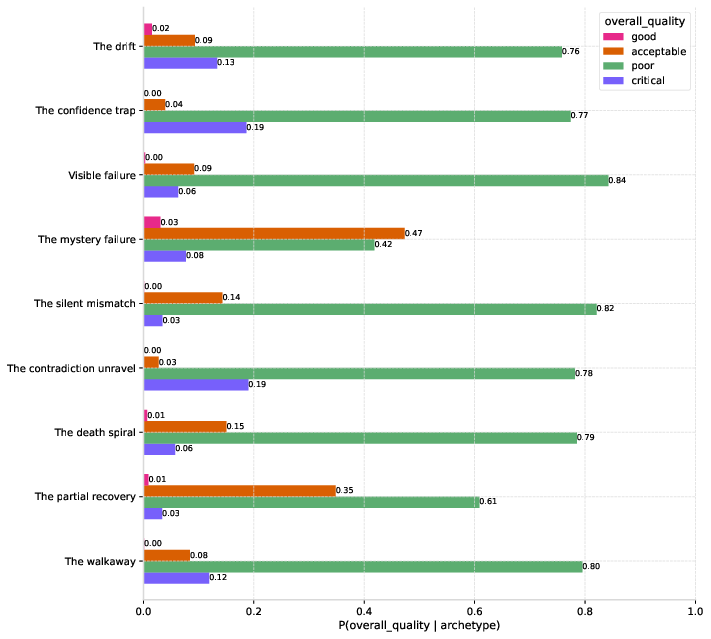
Figure 3: The association between failure archetypes and overall quality labels; archetypes are strongly predictive of subpar interactions.
Investigating co-occurrence of archetypes exposes higher-order structures, such as frequent pairing between "confidence trap" and "contradiction unravel," or between "drift" and "walkaway," indicating composite, compounding failure modes.
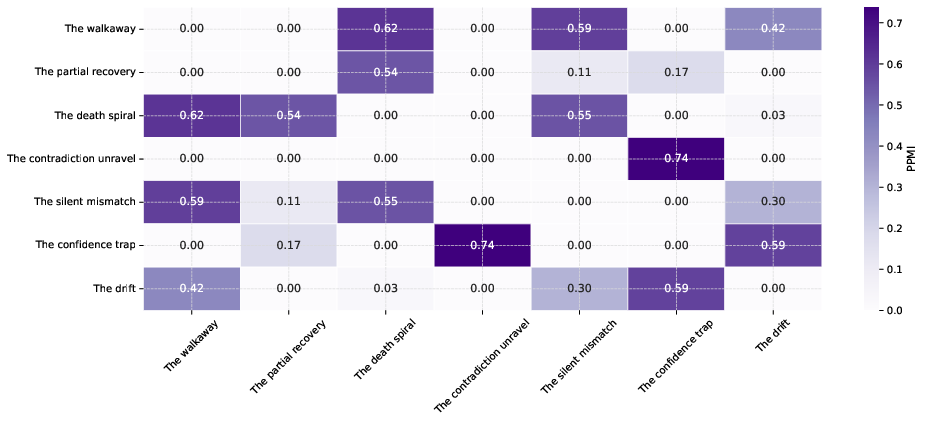
Figure 4: Heatmap of pairwise archetype co-occurrence, with PPMI indicating robust latent structure among failure types.
Structural Nature of Invisible Failures
To assess persistence with more advanced models, the authors conduct retrospective validation using Claude Opus on a stratified subsample of failures. Each transcript is assessed for whether the underlying cause is due to model capability, interactional dynamics, or both, and whether the same issues would persist in substantially more capable models.
Key findings:
- 91% of failures involve interactional, not purely capability-driven, dynamics.
- 94% of interaction-related failures are anticipated to persist even with much stronger models.
- "Generate rather than clarify"—failure to ask clarifying questions in the face of ambiguity—appears in 79% of failures, representing a structural property of current chat system training and deployment rather than a mere artifact of limited competence.
These results indicate that architectural and interface solutions—not just improving model knowledge and reasoning—are required for substantive progress on this front.
Domain Sensitivity and Application Risk Profiles
Domain-level analysis maps the archetypes to usage categories. For instance, software engineering features more visible failures—users are positioned to identify and contest mistakes—while creative writing and UX design are dominated by subtle drift dynamics. Consequently, invisible failures pose distinct risks in different operational contexts.
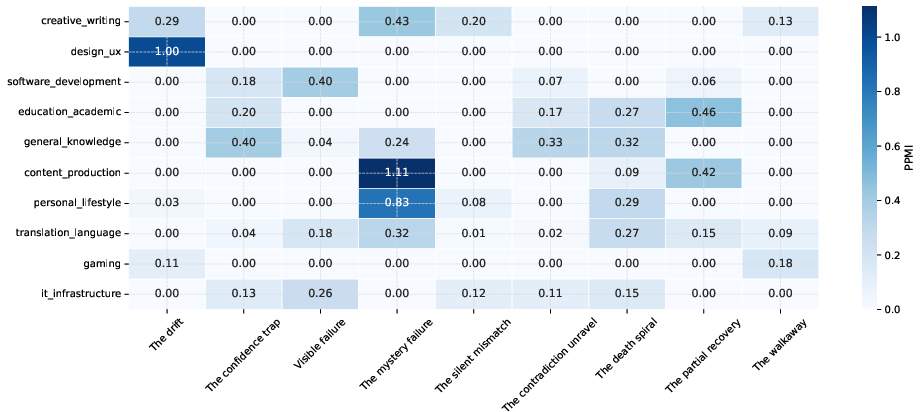
Figure 5: Archetype–domain co-occurrence PPMI matrix illustrating variability in invisible failure patterns by application domain.

Figure 6: Overall domain distribution in the dataset evidences broad coverage across applications.
Implications and Future Directions
The archetype taxonomy emerges as a scalable, composable tool for continuous quality monitoring beyond what is feasible with simple performance metrics or post hoc manual review. Each archetype links to specific intervention opportunities: calibration strategies for "confidence trap," interface changes for "walkaway," or alignment verification mechanisms for "drift." The analysis underscores that many invisible failures are inherent to current patterns of human–AI interaction and their supporting interfaces, not simply fixable by upgrading LLM parameters.
Practically, adopting this taxonomy enables product teams, researchers, and policymakers to identify, monitor, and prioritize AI failures even in the absence of user complaints, a vital precursor to safe and reliable mass deployment.
Conclusion
This study quantifies and structurally maps invisible failures in human–AI conversations, finding that they comprise the majority of nontrivial failures and are likely to persist across model generations absent interface and behavioral innovations. The taxonomy of archetypes, grounded in large-scale empirical analysis, provides a foundation for reliable, scalable failure monitoring and targeted mitigation strategies. As AI systems proliferate and usage diversifies, attention must shift from overt, user-signaled breakdowns to often-overlooked but critical failures embedded in the day-to-day workings of interactive AI.
Figure 1: Distribution of quality categories: predominance of "good" and "acceptable," with a substantial minority of "poor"/"critical" outcomes.
Figure 2: Distribution of invisible failure archetypes among failure transcripts, with “drift” and “confidence trap” leading.
Figure 3: Quality category breakdown by archetype, demonstrating how certain archetypes are tightly coupled to "poor" and "critical" ratings.
Figure 4: Archetype co-occurrence matrix (PPMI), elucidating higher-level compound failure patterns.
Figure 5: PPMI associations between archetypes and application domains, showing that invisible failures manifest with distinct profiles by domain.
Figure 6: Distribution of domains in the WildChat dataset, supporting cross-domain generality of results.
Conclusion
Invisible failures—clustered into an empirically grounded set of eight archetypes—constitute the primary risk to reliable AI deployment, undermining quality in ways opaque to standard user-centric monitoring. These patterns are principally structural, tied to interaction dynamics and design, and are expected to persist even with improved model capabilities. Continuous, archetype-informed monitoring frameworks and proactive interface/intervention research will be essential for future safe, dependable AI systems across domains.