HorizonMath: Measuring AI Progress Toward Mathematical Discovery with Automatic Verification
Abstract: Can AI make progress on important, unsolved mathematical problems? LLMs are now capable of sophisticated mathematical and scientific reasoning, but whether they can perform novel research is still widely debated and underexplored. We introduce HorizonMath, a benchmark of over 100 predominantly unsolved problems spanning 8 domains in computational and applied mathematics, paired with an open-source evaluation framework for automated verification. Our benchmark targets a class of problems where discovery is hard, requiring meaningful mathematical insight, but verification is computationally efficient and simple. Because these solutions are unknown, HorizonMath is immune to data contamination, and most state-of-the-art models score near 0%. Existing research-level benchmarks instead rely on formal proof verification or manual review, both of which are expensive to scale. Using this platform, we find two problems for which GPT 5.4 Pro proposes solutions that improve on the best-known published results, representing potential novel contributions (pending expert review). We release HorizonMath as an open challenge and a growing community resource, where correct solutions to problems in the unsolved problem classes could constitute novel results in the mathematical literature.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
Imagine a giant set of tough math puzzles where nobody knows the answers yet. Now imagine a fast, fair “checker” that can instantly tell whether a proposed answer really works. This paper builds exactly that: a public benchmark called HorizonMath with over 100 mostly unsolved math problems and an automatic checker. The goal is to see whether AI can move from solving homework-style problems to making real, new discoveries in math.
The main questions the paper asks
- Can today’s AI systems do more than repeat known solutions—can they actually discover new math results?
- How can we measure true discovery if the correct answers aren’t known?
- Is there a way to check proposed answers quickly, without needing a panel of expert graders each time?
How the benchmark works (methods explained simply)
To make unsolved problems testable, the authors pick problems with a “hard-to-create, easy-to-check” property—like a lock that’s hard to pick but easy to test once you try a key. They focus on three kinds of problems:
- Closed-form discovery: Find a neat, exact formula (built from standard math building blocks like π, e, logs, trig, Gamma, zeta, etc.) that matches a known number computed very accurately. The checker compares your formula’s value to a trusted high-precision number (up to about 20 digits). If it matches, your formula is a strong candidate.
- Beat-the-best optimization: Build something (like a special arrangement of lines or numbers) that beats the current best result. The checker computes the score (like area or density) and confirms whether it’s strictly better.
- Existence by construction: Provide a concrete object (like a special grid or matrix) that satisfies all the rules. The checker tests every rule exactly and gives pass/fail.
To keep things fair:
- Answers must be concrete and follow strict rules—no sneaky shortcuts like numerical guesses, infinite series, or hidden computations.
- The system uses a “compliance checker” to catch forbidden tricks and only accept allowed math pieces (those computable with standard functions in a math library).
- Everything is open-source, so anyone can run the same checks.
Why this avoids “data contamination”: Because these problems don’t have known solutions, an AI can’t just memorize them from the internet. If it solves one, it’s likely using real reasoning.
What they found and why it matters
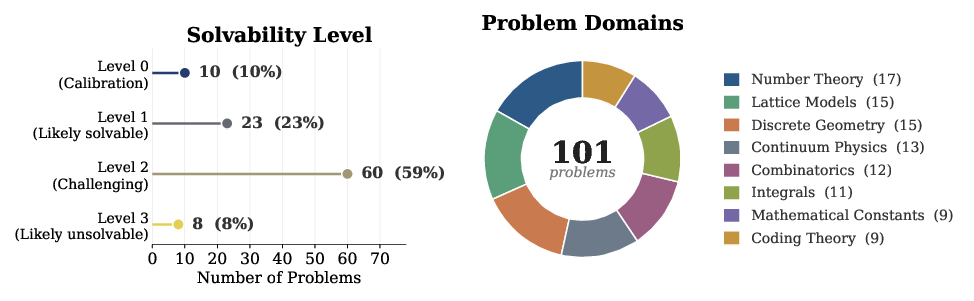
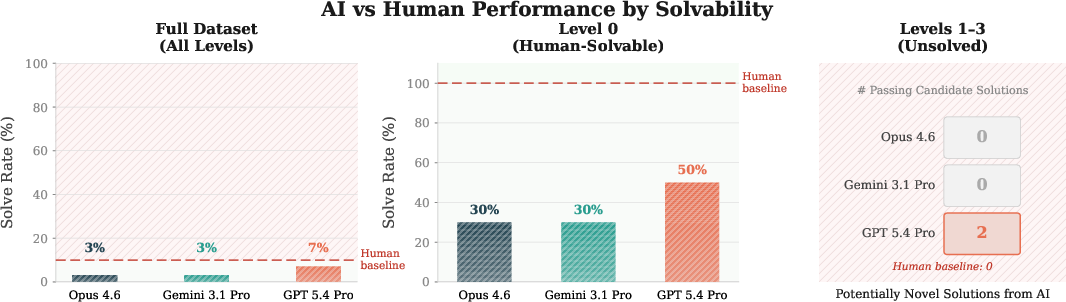
The authors tested several top AI models on 101 problems across 8 areas (like analysis, geometry, number theory, combinatorics, and mathematical physics). Most models scored near zero—showing these are genuinely hard discovery tasks, not standard exercises.
However, one model (GPT 5.4 Pro) produced candidate solutions that improved the best known results on two optimization problems:
- A geometric “Thin-Triangle Kakeya” problem (with 128 fixed slopes): it found a pattern of line positions that reduced the total area more than the previous best (about an 8.44% improvement), verified with exact arithmetic.
- A problem about the constant in an upper bound for diagonal Ramsey numbers (a famous area in combinatorics): it proposed tuned functions that lowered the constant from about 3.7992 to about 3.6961, with checks using interval arithmetic.
These are labeled “potentially novel” because, just like in real math, experts still need to double-check and write formal proofs. Still, getting better-than-published results is a big deal: it suggests AI may be starting to make true research-level progress.
Why this work is important (implications)
- It gives a fair, scalable way to track whether AI is moving from “good student” to “junior researcher.”
- Because checking is automatic and open-source, the community can iterate fast, share results, and add new problems.
- If an AI solves one of these problems, it could be a genuine new result, not just a memorized answer.
- The approach can grow in two promising directions:
- Allowing useful “simplifications” even when a perfect closed form isn’t known—valuable in areas like physics.
- Adding proof-based problems tied to formal systems (like Lean), so discovery-by-proof can be measured too.
In short: HorizonMath turns real, unsolved math questions into a fair, computer-checkable challenge. Most current AIs struggle, but early wins suggest that genuine AI-driven mathematical discovery may be on the horizon.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of concrete gaps and open questions that the paper leaves unresolved; each item is phrased to guide follow‑up research and engineering work.
- Verification soundness for “closed-form” matches:
- What is the empirical false-accept rate (Type I error) for numeric matching at the current tolerance (min(20, D) digits) when adversarial expressions are allowed?
- How often do high-precision numerical matches correspond to true identities vs. sophisticated curve fitting over the allowed special-function basis?
- Admissibility enforcement robustness:
- How reliable is the LLM-based compliance checker at detecting forbidden operations (e.g., hidden numerical integration, implicit digit-encoding via huge rationals, obfuscated search loops)?
- What are precision/recall metrics for the compliance checker under adversarial code attacks and unusual but legitimate constructions?
- Can a purely static, AST-level whitelist (with sandboxing) outperform LLM judging in safety and reproducibility?
- Sandbox and security guarantees:
- Is model-submitted code executed in a hardened sandbox with strict module whitelisting, resource limits, and no network/file access?
- Can currently permitted mpmath special functions be used as surrogates for numerical quadrature (e.g., by representing arbitrary integrals as hypergeometric/elliptic evaluations), effectively bypassing “no numerics” rules?
- Vulnerability to digit encoding and parameter fitting:
- Can a model “cheat” by embedding the target number as an enormous rational/continued-fraction or as tuned hypergeometric parameters that encode digits?
- What programmatic checks can detect expressions with excessive parameter magnitudes or suspicious structure (e.g., bounds on numerator/denominator size, parameter counts, or growth constraints)?
- Function-valued verification (e.g., eigenvalue functions):
- How is correctness over a continuum domain established—finite grids, interval arithmetic, symbolic certificates?
- What is the risk a model overfits a hidden test grid (e.g., piecewise definitions keyed to grid points) and how will grid randomization or certified bounds be used to prevent this?
- How are smoothness, monotonicity, or spectral ordering constraints verified deterministically for function outputs?
- Ground-truth reliability:
- How are “ground-truth” numeric references produced and validated (independent methods, interval bounds, cross-precision checks)?
- For problems with difficult numerics (slow convergence, ill-conditioning), what error budgets and proof-like guarantees (e.g., rigorous interval arithmetic) are in place?
- Definition and scope of “closed form”:
- The allowed special-function set (e.g., hypergeometric, elliptic integrals, L-functions) can be extremely expressive—what complexity measures (length, parameter count, heights) will bound and rank solutions?
- How to adjudicate between multiple “closed forms” with different complexity but numerical equivalence?
- Partial credit and progress signals:
- For near misses (e.g., high-accuracy approximations, improved but not record-setting constructions), is there a graded scoring scheme to capture incremental progress rather than pass/fail?
- Benchmarks for constructions and bounds:
- Do validators fully and exactly check all required properties for combinatorial objects, or can there be missed constraints/edge cases?
- For optimization tasks with real-valued objectives, how are tie-breaking, numerical tolerance, and reproducibility handled across machines and library versions?
- Dataset coverage and selection bias:
- The benchmark emphasizes numerically verifiable problems (special functions, combinatorial constructions). How representative is this of “mathematical discovery” across domains like topology, algebraic geometry, or logic that are proof-heavy?
- What is the plan to diversify problems beyond those amenable to numeric verification while retaining automation?
- Solvability tiers and difficulty calibration:
- How were solvability levels (0–3) assigned and validated? Are there human studies or expert panels confirming relative difficulty?
- Can item-response theory or other psychometric tools be used to calibrate and maintain difficulty as the benchmark grows?
- Contamination claims and empirical checks:
- While solutions are unknown, numeric targets and baselines may appear in literature or web sources. What empirical procedures test for training-data leakage or memorization (e.g., can models recover values without the verifier)?
- How will the benchmark detect and mitigate contamination as improved solutions get published and enter training corpora?
- Reproducibility and statistical rigor of model evaluations:
- Results are reported for three models with limited runs and noted API failures; where are repeated trials, seed sweeps, prompt ablations, and statistical significance analyses?
- How sensitive are outcomes to prompting style, tool-usage allowances, temperature, and reasoning depth?
- Generalization vs. agentic search:
- Do current protocols fairly evaluate one-shot reasoning versus multi-step agentic search (e.g., internal exploration loops), and how are resources capped for comparability?
- Leaderboard governance and baseline freshness:
- How will best-known baselines be updated as literature advances, and how is novelty adjudicated (especially for concurrent or independent discoveries)?
- What is the provenance/attribution mechanism for submissions that later require correction after expert review?
- Expert validation pipeline:
- For “potentially novel” improvements, what formal process (peer review, external referees, replication packages) will confirm correctness and grant credit?
- How will disputes (e.g., validator errors, borderline admissibility) be resolved transparently?
- Computational cost and environmental constraints:
- What are typical runtime and precision costs per problem? Are there resource ceilings to ensure accessibility and prevent compute-heavy overfitting strategies?
- Interoperability with formal proof systems:
- How will the benchmark integrate proof-based tasks (Lean, Coq) while preserving automated grading?
- Can numeric discoveries be automatically turned into proof obligations with machine-checkable certificates?
- Ranking and complexity-aware scoring:
- Beyond pass/fail and “beats best-known,” is there a unified scoring rubric that rewards solution simplicity, generality, and certifiability?
- Robustness to library/version drift:
- How sensitive are results to mpmath/NumPy/Python version changes? Is there a pinned environment and hash-based reproducibility strategy?
- Transparency of the 101-problem set:
- The paper summarizes composition but does not enumerate problems and validators in the text. Are all problems, numerical references, and validator rationales publicly documented for independent audit?
- Handling of unsolved problems with moving targets:
- If a problem is later solved in the literature, how is it reclassified or retired, and how are historical scores adjusted?
- Ethical and credit considerations:
- If AI-generated solutions pass verifiers but fail later expert scrutiny, how are claims rolled back and communications managed to avoid misleading novelty claims?
- Measuring downstream scientific value:
- Beyond beating baselines, how will the benchmark track whether accepted solutions lead to peer-reviewed publications, new conjectures, or follow-up proofs?
- Extending beyond mpmath/Python:
- Does restricting to mpmath limit expressiveness or bias toward certain solution forms? Is there a roadmap for multi-language or CAS-backed but still verifiable submissions (with certified numerics)?
- Replicability of the two “potentially novel” results:
- The paper mentions two improved constructions; are full artifacts (code, parameters, exact objects) released for independent re-verification and robustness checks (e.g., alternative verifiers, exact arithmetic)?
- Failure analysis and error taxonomy:
- What are the dominant failure modes (admissibility violations, numeric mismatch, validator edge cases) across models, and which interventions most improve pass rates?
These gaps collectively outline a research agenda spanning verifier soundness, compliance and sandboxing, benchmarking methodology, dataset governance, and the bridge from numerical conjecture to certified mathematical results.
Practical Applications
Immediate Applications
The following applications can be deployed now using HorizonMath’s benchmark, verification harness, and design patterns around the generator–verifier gap.
- Standardized capability evaluation for “AI-for-math” systems
- Sectors: software/AI, academia
- What: Use HorizonMath’s open-source harness to quantify whether models can produce novel, verifiably correct mathematical objects (constants, constructions, optimizers).
- Tools/workflows: CI pipelines that run the compliance checker and problem-specific verifiers; leaderboards for internal and public benchmarking.
- Assumptions/dependencies: Evaluated systems must return concrete objects; verifiers cover only benchmarked problem classes; numerical agreement is evidence (not a formal proof).
- Model selection and regression testing for research agents
- Sectors: software/AI (model development)
- What: Compare agent variants (prompting, search, self-improvement) by pass/fail and improvement-over-baseline on unsolved tasks to guide deployment.
- Tools/workflows: “Discovery CI” runs nightly across subsets of problems; triggers alerts when discovery rates regress.
- Assumptions/dependencies: Stable compute budget; careful control of stochasticity; reliance on unsolved, auto-verified tasks to avoid training-set leakage.
- Rapid prototyping of new generator–verifier benchmarks beyond pure math
- Sectors: operations research, logistics, energy, finance, telecommunications
- What: Port the “verifier-first” recipe to domains with deterministic simulators (e.g., scheduling, routing, portfolio constraints, unit commitment), enabling immediate auto-scored open challenges.
- Tools/workflows: Build minimal verifiers (Python) that accept candidate solutions and deterministically score feasibility and objective value; integrate into hackathons or internal challenges.
- Assumptions/dependencies: Existence of efficiently checkable constraints; verifiers must be correct and robust against adversarial inputs.
- Guardrails for mathematical outputs via an LLM-based compliance checker
- Sectors: software/AI, education
- What: Enforce admissible operations (no hidden numerics, illegal integrals, or black-box solvers) when models produce “closed forms” or constructions.
- Tools/workflows: Drop-in compliance checker in function-call toolchains; audit logs explaining rejections.
- Assumptions/dependencies: Checker accuracy/coverage; periodic updates to catch new evasion patterns.
- Reproducible, contamination-resistant evaluation in academic studies
- Sectors: academia
- What: Use unsolved-but-verifiable questions to study reasoning, search, and meta-learning without contamination confounds.
- Tools/workflows: Public repo, pinned package versions, seeds; badges for “reproducible discovery claims.”
- Assumptions/dependencies: Community maintenance of verifiers and problem metadata.
- Course modules and competitions on research-level problem solving
- Sectors: education
- What: Integrate HorizonMath tasks into advanced courses/seminars, capstone projects, and student competitions where outputs are auto-graded.
- Tools/workflows: Assignment templates calling mpmath; graded by exact verifiers rather than TA review.
- Assumptions/dependencies: Problem selection appropriate for skill level; awareness that “passes” are conjectural until proved.
- Community-driven open problem curation and validation
- Sectors: academia, open science/citizen science
- What: Run contribution sprints to add verifiable open problems with validators; host public leaderboards for novel improvements.
- Tools/workflows: GitHub issue templates for new problems; automated CI to test added verifiers and seeds.
- Assumptions/dependencies: Governance for scope/quality; clear licensing for contributed problems and checkers.
- Verification utilities for numerical claims in preprints and code
- Sectors: academia, scientific software
- What: Reuse high-precision reference pipelines to check constants, integrals, or discrete constructions in papers or code releases.
- Tools/workflows: mpmath-based high-precision scripts; interval arithmetic or exact rational checks where applicable.
- Assumptions/dependencies: Distinction between “passes numerically” and “proved”; authors’ consent for independent checks.
- Rapid evaluation of combinatorial constructions in communications/coding
- Sectors: telecommunications, error-correcting codes
- What: Test new heuristics (e.g., for difference triangle sets, orthogonal arrays, packing designs) against deterministic validators and current best-known bounds.
- Tools/workflows: Integrate domain-specific validators into R&D pipelines; maintain internal baselines and scopes.
- Assumptions/dependencies: Mappings from benchmarked designs to engineering codebooks; practical constraints (e.g., alphabet size, latency) may differ from theoretical formulations.
- Data-contamination mitigation for model evals
- Sectors: software/AI, policy
- What: Adopt unsolved-problem benchmarks to credibly assess generalization without leak risk.
- Tools/workflows: Use HorizonMath alongside traditional datasets; report split metrics.
- Assumptions/dependencies: Ongoing curation of genuinely unsolved items; transparency about solver heuristics and verification strength.
Long-Term Applications
These applications require additional research, scaling, domain expansion, or integration with formal methods and policy.
- Autonomous mathematical discovery agents producing publishable results
- Sectors: academia, software/AI
- What: End-to-end agents that propose conjectures, verify numerically, refine, and collaborate with humans toward proofs.
- Tools/workflows: Closed-form search + compliance guards + auto-verification + proof assistant integration; experiment tracking for conjecture evolution.
- Assumptions/dependencies: Stronger reasoning and search; robust bridges to formal proof systems; expert oversight.
- Expansion to proof-based, formally verified benchmarks
- Sectors: software/AI, academia
- What: Integrate Lean/Isabelle/Coq to auto-grade proof obligations in addition to numeric/constructive tasks.
- Tools/workflows: Dual-mode scoring (numeric verifier + proof checker); formal libraries of problem statements.
- Assumptions/dependencies: Formalization effort; proof search scalability; community-maintained math libraries.
- Cross-domain “verifier-first” discovery for industrial optimization
- Sectors: chip design (EDA), logistics, energy, finance, robotics
- What: AI agents search for better layouts, schedules, dispatches, policies; deterministic simulators verify constraints/objectives.
- Tools/workflows: Plug agent outputs into standard simulators (e.g., grid simulators, route planners); reward models on verified improvements.
- Assumptions/dependencies: Faithful simulators; alignment of proxy objective with operational KPIs; safety/robustness checks.
- Domain-specific science pipelines (physics, materials, signal processing)
- Sectors: physics, materials science, communications
- What: Discover closed forms, constants, or constructions that reduce compute or improve accuracy in simulators and algorithms (e.g., special-function identities, lattice sums, sequence bounds).
- Tools/workflows: Inner loop: conjecture → numeric verification → surrogate deployment → empirical validation; outer loop: formal proof prioritization for impactful results.
- Assumptions/dependencies: Transferability of benchmark-derived discoveries; validation against experimental/empirical data.
- Procurement and regulation standards for “AI-for-science” claims
- Sectors: policy/government, funding bodies
- What: Use unsolved, auto-verified benchmarks as part of evidence requirements for model procurement, grants, and program evaluations.
- Tools/workflows: Standardized scorecards (pass counts, improvement margins, verifier robustness); audit trails for compute and reproductions.
- Assumptions/dependencies: Community consensus on task sets; governance around changing problem difficulty; conflict-of-interest management.
- Safety governance for discovery-capable AI
- Sectors: policy, AI safety
- What: Gatekeep and monitor capabilities that produce rapid scientific advances (beneficial or dual-use) using discovery benchmarks as capability indicators.
- Tools/workflows: Tiered access aligned to benchmarked capability; red-team tracks; kill-switches for risky verifiers.
- Assumptions/dependencies: Risk taxonomies; calibrated thresholds; oversight bodies.
- Journals and repositories integrating “conjecture registries” and verifiers
- Sectors: academic publishing, open science
- What: DOI-linked registries of machine-generated conjectures with executable verifiers and precision guarantees.
- Tools/workflows: Submission checklists including auto-verification artifacts; badges for verifier completeness and reproducibility.
- Assumptions/dependencies: Publisher buy-in; standards for numeric evidence; long-term artifact hosting.
- Adaptive education built around verifiable open problems
- Sectors: education/edtech
- What: Personalized sequences of unsolved-but-checkable tasks that teach research thinking and computational verification.
- Tools/workflows: Difficulty-adaptive schedulers; feedback from deterministic verifiers; peer discussion around failed attempts.
- Assumptions/dependencies: Adequate problem coverage across topics and levels; clear pedagogical scaffolds.
- Marketplace and infrastructure for verifiers and discovery challenges
- Sectors: software platforms, competitions
- What: Hosted challenge hubs where labs and companies publish verifiers for open problems; participants submit candidate solutions for auto-scoring.
- Tools/workflows: Containerized verifiers, sandboxed execution, leaderboards, prize-backed milestones.
- Assumptions/dependencies: Security isolation; IP/licensing terms for problem statements and solutions.
- Integration with lab automation and experimental design
- Sectors: biotech/chemistry/materials
- What: Use generator–verifier loops where the “verifier” is a surrogate model or high-throughput assay; close the loop for hypothesis generation and testing.
- Tools/workflows: Bayesian optimization + LLM reasoning for structure proposals; automated labs feed back pass/fail and measurements.
- Assumptions/dependencies: Reliable, low-latency experimental verification; safe operation and ethical oversight.
- Improved mathematical software ecosystems
- Sectors: scientific computing
- What: Strengthen libraries (mpmath, CAS bridges, interval arithmetic) driven by benchmark needs for precision, special functions, and robust comparison.
- Tools/workflows: Contributions guided by benchmark failures (e.g., precision loss points); test suites seeded from tasks.
- Assumptions/dependencies: Sustained maintainer effort; cross-library compatibility.
- Convergence of numeric verification and formal proof
- Sectors: academia, software/AI
- What: Pipelines that promote numerically verified conjectures to fully proved theorems with automated or semi-automated proof search.
- Tools/workflows: Conjecture mining → template generation → proof search in proof assistants → certified verification.
- Assumptions/dependencies: Progress in neural theorem proving, tactic synthesis, and library reuse; human-in-the-loop collaboration.
Notes on feasibility across applications:
- The generator–verifier gap is the central dependency: tasks must have difficult generation but efficient, deterministic verification.
- Numeric agreement at high precision is strong evidence but not a substitute for proof; downstream use must reflect this.
- Compliance checking is necessary but imperfect; adversarial or accidental violations require audits and periodic tool updates.
- Compute, reproducibility, and transparent artifact sharing are prerequisites for credible evaluation and deployment.
Glossary
- Airy function: A special function solving the differential equation y'' − x y = 0, often denoted Ai(x), occurring in asymptotics and wave phenomena. "Airy function"
- Airy power moments: Integrals of powers of the Airy function over [0, ∞), defined as a_n = ∫₀∞ Ai(x)n dx. "The Airy power moments are defined by:"
- ansatz: A structured, often parameterized, assumed form for a function or solution used to guide optimization or proofs. "within a specified ansatz"
- Aristotle formal verification system: A formal reasoning toolchain referenced for machine-checked proofs in mathematics. "the Aristotle formal verification system"
- autocorrelation inequality: An inequality involving autocorrelation (self-correlation) functions, often arising in harmonic analysis and combinatorics. "an autocorrelation inequality"
- cap sets: Subsets of vector spaces over finite fields with no three-term arithmetic progression, central in additive combinatorics. "cap sets"
- Cayley digraph: A directed graph defined from a group and a generating set, encoding algebraic structure in graph form. "a Cayley digraph"
- compliance checker: An automated screening component that enforces admissibility rules by detecting forbidden operations in proposed solutions. "compliance checker"
- complete elliptic integrals: Special functions (of the first and second kind) representing integrals over elliptic curves, common in physics and number theory. "complete elliptic integrals"
- Diagonal Ramsey numbers: Values R(n, n) in Ramsey theory giving the smallest graph size guaranteeing a clique or independent set of size n. "Asymptotic Upper Bound Constant for Diagonal Ramsey Numbers"
- Difference Triangle Set (DTS): A combinatorial design consisting of rows of increasing integers starting at zero where all positive pairwise differences across rows are distinct. "Difference triangle sets (DTS)"
- Dirichlet L-functions: Complex analytic functions generalizing the Riemann zeta function via Dirichlet characters, key to number theory. "Dirichlet -functions"
- directed Hamiltonian cycles: Cycles in a directed graph that visit every vertex exactly once following edge direction. "directed Hamiltonian cycles"
- Erdős' minimum overlap problem: A combinatorial optimization problem posed by Erdős concerning minimizing overlaps under certain constraints. "Erd\H{o}s' minimum overlap problem"
- finite field Kakeya problem: A discrete analogue of the Kakeya problem asking for minimal-size sets containing a line in every direction over finite fields. "finite field Kakeya problem"
- formal proof verification: The process of checking mathematical proofs within a proof assistant to ensure correctness by machine. "formal proof verification"
- Gegenbauer expansion: Expansion of functions in terms of Gegenbauer (ultraspherical) polynomials, useful in solving PDEs and evaluating integrals. "a Gegenbauer expansion"
- generator-verifier gap: A class of problems where finding a solution is hard but checking a candidate is computationally easy. "generator-verifier gap"
- Hadamard matrix: A square matrix with entries ±1 whose rows are mutually orthogonal, existing only for certain orders. "a Hadamard matrix of an unresolved order"
- Haar-style overlap pattern: A structured pattern inspired by Haar wavelets used to induce overlaps efficiently in geometric constructions. "Haar-style overlap pattern"
- hypergeometric functions (pFq): A broad class of special functions defined by hypergeometric series, encompassing many classical functions. "hypergeometric functions "
- interval arithmetic: A rigorous numerical method computing with intervals to bound rounding errors and validate inequalities. "interval arithmetic"
- Kakeya problem: A problem about the minimal area/measure set that contains a unit line segment in every direction; thin-triangle variants discretize directions. "Thin-Triangle Kakeya (128 slopes)"
- kissing-number lower bound: A bound on the maximal number of equal spheres that can touch another sphere without overlap in a given dimension. "a kissing-number lower bound"
- Lean proof: A proof formalized and verified in the Lean proof assistant. "via a Lean proof"
- mpmath: A Python library for arbitrary-precision arithmetic and special functions used for high-precision evaluation. "mpmath"
- mutually orthogonal Latin squares (MOLS): Sets of Latin squares where superimposed pairs produce all ordered symbol pairs exactly once. "mutually orthogonal Latin squares"
- piecewise-constant functions: Functions that take constant values on subintervals, used to construct efficiently checkable candidates. "piecewise-constant functions and "
- polylogarithms: Special functions Li_s(z) generalizing the logarithm via power series, appearing in number theory and physics. "polylogarithms"
- Angular Prolate Spheroidal Eigenvalues: Eigenvalues associated with spheroidal wave equations on (−1, 1), depending on a parameter c, arising in separation of variables. "Angular Prolate Spheroidal Eigenvalues (order m = 0)"
- PSLQ: An integer relation detection algorithm used to find linear relations between real numbers with integer coefficients. "PSLQ"
- Remez algorithm: An iterative method for computing minimax (Chebyshev) polynomial approximations. "the Remez algorithm"
- spectral coefficients: Coefficients in an expansion with respect to eigenfunctions or orthogonal basis functions (spectrum), often from PDEs or integral equations. "spectral coefficients"
- spectral theory: The study of spectra (eigenvalues) of operators, especially linear differential operators and integral operators. "spectral theory / special functions."
- Sturm--Liouville eigenvalue problem: A class of second-order linear differential eigenvalue problems with weight functions on an interval. "Sturm--Liouville eigenvalue problem"
- test-time training: A technique where a model adapts its parameters during inference using the test instance or distribution. "``test-time training''"
- zeta function: Typically the Riemann zeta function ζ(s), a central object in analytic number theory. ""
Collections
Sign up for free to add this paper to one or more collections.