- The paper introduces a novel four-phase protocol for Text-to-SQL that reduces hallucinations by enforcing verified schema proposals.
- It leverages Dual-Track GRPO to assign rewards separately for schema exploration and SQL generation, achieving up to 9.9% execution accuracy improvement.
- The framework demonstrates robust performance on multiple benchmarks without reliance on static schema injection.
Tool-Integrated Multi-Turn RL for Text-to-SQL over Unknown Schemas: An Analysis of TRUST-SQL
Problem Context and Motivation
Text-to-SQL parsing, the conversion of natural language queries to executable SQL, historically assumes Full Schema observability—i.e., the complete database schema is accessible to the model at inference. This assumption does not hold in large-scale, evolving enterprise databases where excessive, noisy, or outdated metadata not only bloats the context window but actively degrades LLM performance by introducing distractors. The "Unknown Schema" paradigm formalizes this realistic scenario, demanding that Text-to-SQL agents autonomously explore and validate relevant schema components just-in-time, performing selective metadata retrieval rather than static ingestion.
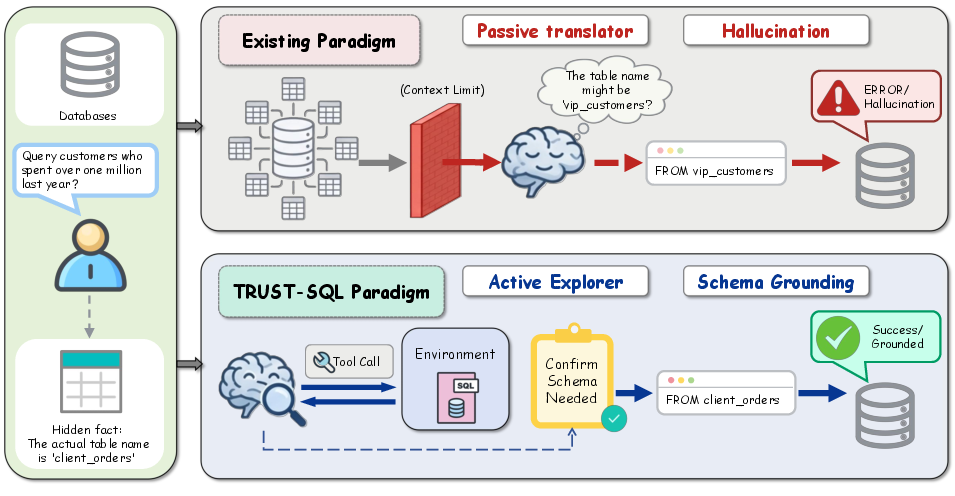
Figure 1: Existing methods rely on pre-loaded schemas, while the Unknown Schema setting requires active exploration.
TRUST-SQL Framework
TRUST-SQL (Truthful Reasoning with Unknown Schema via Tools) addresses Text-to-SQL under unknown, partially observable database schemas by formulating the task as a POMDP solvable by a multi-turn LLM agent. The method introduces a four-phase protocol—Explore, Propose, Generate, and Confirm—that enforces explicit separation between metadata exploration, schema commitment, constrained SQL generation, and final validation.
The Propose phase acts as a cognitive bottleneck: after repeated tool-driven schema exploration, the agent is forced to commit to a minimal, verified schema, grounding subsequent SQL generation strictly to observed structures and eliminating parametric hallucination. This structural separation is exploited by the novel Dual-Track GRPO training scheme, which divides each trajectory into a Schema Track (terminated at Propose) and a Full Track (ending after Confirm), each with independent reward assignment and token-level masked policy updates.
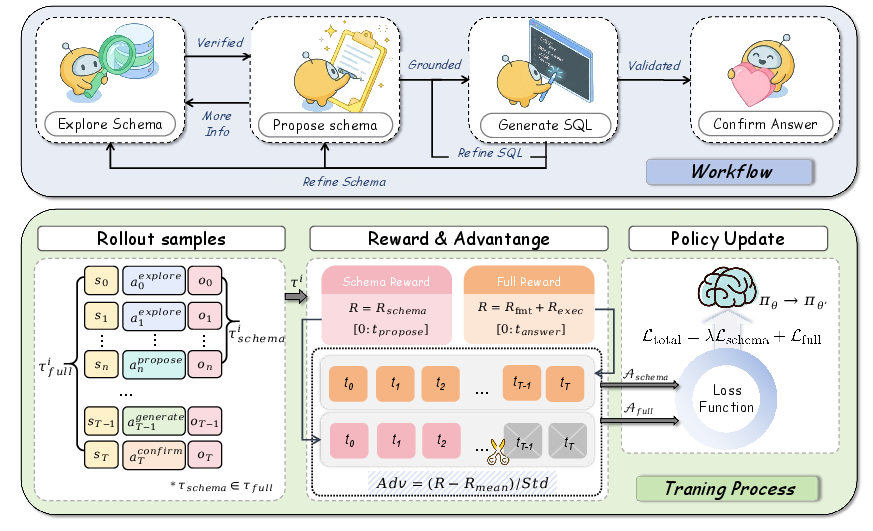
Figure 2: Overview of the TRUST-SQL framework. (Top) The four-phase workflow comprising Explore, Propose, Generate, and Confirm, with non-linear transitions enabling iterative schema refinement. (Bottom) The Dual-Track GRPO training pipeline, where trajectories are decomposed into a Schema Track τschema and a Full Track τfull, each optimized with independent rewards and masked advantages.
Error Anatomy and Protocol Justification
A pilot study on BIRD-Dev with incrementally constrained protocols—(EC), (EGC), and full (EPGC/Explore-Propose-Generate-Confirm)—reveals that hallucination (i.e., generation of unobserved schema elements) is significantly suppressed only by mandatory schema proposal. The addition of only a Generate step yields minor improvement, whereas the Propose checkpoint reduces hallucination incidents by 9.4×, down to 2.8%.
Schema linking remains the chief unresolved bottleneck, with errors due to incorrect or missing table/column selection persisting even with enhanced protocol structure. Moreover, as exploration becomes more reliable, semantic SQL errors (logical failures with correct schema) constitute a greater fraction of failures, indicating that true SQL reasoning emerges as a bottleneck only when schema grounding is solved.
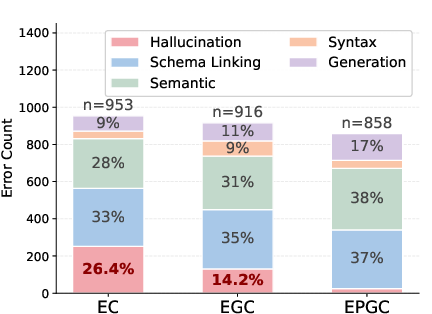
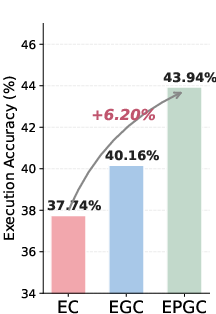
Figure 3: Stacked error distribution from pilot study, exposing reduction in hallucination and the persistent schema linking challenge.
Dual-Track GRPO for Fine-Grained Credit Assignment
The central methodological innovation is Dual-Track GRPO—an extension of Group Relative Policy Optimization to the multi-turn agentic context with explicit trajectory segmentation. Token-level masking ensures that schema exploration actions are rewarded exclusively on the Schema Track up to the Propose point, while SQL generation and protocol adherence receive rewards on the Full Track. Advantages are normalized per-group, preventing reward conflation and ineffective gradient assignment prevalent in prior RL methods that use terminal-only or naïve aggregated rewards. Empirically, Dual-Track GRPO provides 9.9% relative gains over standard GRPO on execution accuracy, largely by resolving credit assignment in extended decision-making.
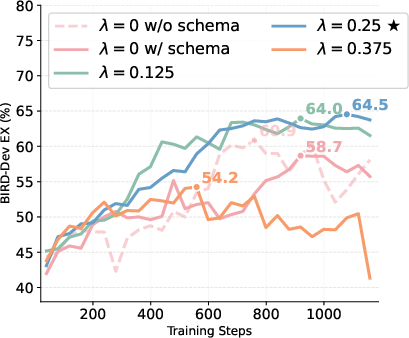
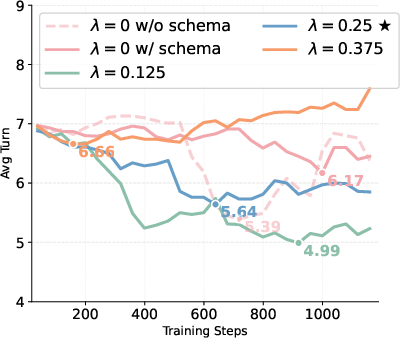
Figure 4: Execution accuracy (EX%) during training, showing clear separation between single- and dual-track optimization with varying λ weights.
Experimental Results
TRUST-SQL is evaluated on five benchmarks: BIRD-Dev, Spider-Test, Spider-DK, Spider-Syn, and Spider-Realistic. Using Qwen3-4B and Qwen3-8B as backbones, TRUST-SQL delivers absolute execution accuracy improvements of 30.6% (4B) and 16.6% (8B) over base models under the strict Unknown Schema regime, and matches or exceeds multi-turn and single-turn baselines that require full schema access.
Crucially, schema prefill ablation shows that while vanilla LLMs degrade by up to 17% without context injection, TRUST-SQL’s performance is invariant (or even slightly degraded) by schema injection—demonstrating robust independence from static metadata and reliance on active, verified exploration.
Analysis of Reward and Training Design
Ablations on the schema reward reveal that reward coupling to execution is critical: uncoupled schema rewards incentivize spurious exploration, while dense formulations conflict with the central objective. Sparse, execution-coupled rewards yield the strongest learning signal and training stability.
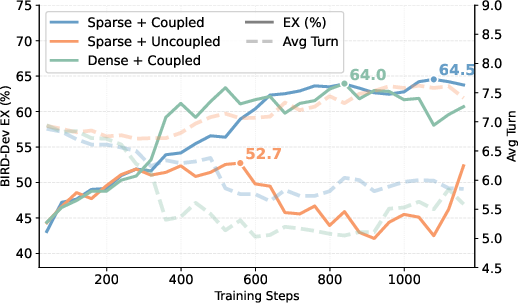
Figure 5: Ablation on schema reward formulation showing that only sparse, execution-coupled schema reward achieves optimal accuracy and efficient exploration.
Further, the turn budget analysis highlights a nontrivial trade-off: too permissive budgets induce exploration bloat, destabilizing training, while test-time horizon extension confers measurable recovery from exploration deficits if the train-time budget is properly tuned.
Practical and Theoretical Implications
Practically, TRUST-SQL unlocks robust Text-to-SQL for real-world enterprise databases with vast, changing, and unobservable schemas—eliminating the infeasibility and brittleness of static schema prefilling. The agent acquires relevant metadata on-demand, minimizing extraneous input and exposure to spurious schema. This especially facilitates deployments where context window size and metadata cleanliness are limiting factors.
Theoretically, this work establishes that agentic, tool-integrated LLMs can be reliably trained to autonomously resolve compositional semantic parsing under observation constraints. The explicit separation of reasoning phases and reward hierarchies paves the way for more general multi-phase, hybrid-planning RL protocols for other partially observable tasks requiring hypothesis commitment and verification.
Looking forward, promising research avenues include dynamic turn budget adaptation relative to schema complexity, extending to non-SQLite dialects, scaling to longer horizons, and integrating data-level value verification. Additionally, architectural advances that further improve retention of long-horizon exploration history will extend agent reliability in even larger database environments.
Conclusion
TRUST-SQL marks a shift in Text-to-SQL methodology, operationalizing autonomous schema exploration via a rigorously structured multi-phase protocol and fine-grained, phase-aware RL. It achieves strong empirical performance, superior to models reliant on static schema injection, and introduces principled solutions to the long-standing challenges of hallucination and reward assignment. This framework generalizes robustly to realistic, unstructured database environments and sets a new baseline for agentic semantic parsing under partial observability.
Reference:
“TRUST-SQL: Tool-Integrated Multi-Turn Reinforcement Learning for Text-to-SQL over Unknown Schemas” (2603.16448)