V-Co: A Closer Look at Visual Representation Alignment via Co-Denoising
Abstract: Pixel-space diffusion has recently re-emerged as a strong alternative to latent diffusion, enabling high-quality generation without pretrained autoencoders. However, standard pixel-space diffusion models receive relatively weak semantic supervision and are not explicitly designed to capture high-level visual structure. Recent representation-alignment methods (e.g., REPA) suggest that pretrained visual features can substantially improve diffusion training, and visual co-denoising has emerged as a promising direction for incorporating such features into the generative process. However, existing co-denoising approaches often entangle multiple design choices, making it unclear which design choices are truly essential. Therefore, we present V-Co, a systematic study of visual co-denoising in a unified JiT-based framework. This controlled setting allows us to isolate the ingredients that make visual co-denoising effective. Our study reveals four key ingredients for effective visual co-denoising. First, preserving feature-specific computation while enabling flexible cross-stream interaction motivates a fully dual-stream architecture. Second, effective classifier-free guidance (CFG) requires a structurally defined unconditional prediction. Third, stronger semantic supervision is best provided by a perceptual-drifting hybrid loss. Fourth, stable co-denoising further requires proper cross-stream calibration, which we realize through RMS-based feature rescaling. Together, these findings yield a simple recipe for visual co-denoising. Experiments on ImageNet-256 show that, at comparable model sizes, V-Co outperforms the underlying pixel-space diffusion baseline and strong prior pixel-diffusion methods while using fewer training epochs, offering practical guidance for future representation-aligned generative models.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper looks at how to make image-generating AI models “understand” what they’re drawing, not just copy pixels. The authors build a method called V-Co that teaches a pixel-based image generator to work side-by-side with a smart vision model (like a strong image recognizer). By letting the generator and the recognizer “clean up” their signals together during generation, the pictures end up looking better and matching the intended content more closely.
What questions the researchers asked
The team focused on four simple questions:
- Architecture: What is the best way to let the “pixels” side and the “meaning/recognition” side talk to each other without getting in each other’s way?
- Guidance: When we use a trick called guidance (which helps images follow what we want, like a class label), how should we define the “without hints” version the model needs to compare against?
- Extra training signals: What additional training nudges help the model learn both accurate details and good overall structure?
- Calibration: How do we keep the pixel information and the recognition features balanced, so one doesn’t drown out the other?
How they approached the problem (in everyday terms)
Think of image generation like un-blurring a noisy photo step by step. A standard diffusion model starts with noise and gradually “cleans” it into a clear picture.
V-Co adds a second “stream” alongside the pixels: a set of features from a pretrained vision model (like DINOv2) that describe what’s in the image (for example, “this patch looks like fur,” “this region is a wheel,” etc.). The key idea is to clean up both the image and these meaning-features together, so the image knows where objects should be and how they relate.
To test ideas fairly, the authors used a well-known pixel-based generator (“JiT”) and built many versions, changing only one thing at a time. They compared:
- How the two streams are connected (one shared path vs two separate paths that can talk).
- How to do guidance: the model makes two predictions—one “with hints” (labels and features) and one “without hints”—and combines them to get sharper, more accurate images. The challenge is: what does “without hints” mean when you have two streams?
- What extra training signals to add. They tried:
- A “perceptual” loss: tells the model “your image should feel like the real one” in a high-level sense, not just pixel-by-pixel.
- A “drifting” loss: gently pushes the model away from making lots of nearly identical images, encouraging variety.
- A hybrid that mixes both.
- How to balance the strengths of the two streams, a bit like making sure two people speaking into a microphone are at the same volume. They did this by rescaling the recognition features so they match the “loudness” of the pixel stream, which is similar to giving them the right difficulty level at each clean-up step.
What they found and why it matters
They discovered four ingredients that make co-denoising (cleaning both streams together) work best:
- Dual-stream architecture: The image and the meaning-features work best when each has its own processing path, with frequent, flexible communication between them. This preserves what each is good at and lets them help each other.
- Smarter guidance: For the “without hints” prediction, instead of just deleting inputs, they “mask” the connection so the meaning-features don’t influence the pixel stream. This makes guidance more stable and effective.
- Hybrid loss: Combining a perceptual loss (pull images toward the right “look and feel”) with a drifting loss (avoid making all images too similar) gives both accuracy and variety.
- Careful calibration: Rescaling the recognition features by their RMS (a measure of average size) keeps the two streams balanced. The authors show this is essentially the same as adjusting the difficulty schedule for that stream.
Why this matters: With these choices, V-Co makes sharper, more realistic, and more semantically correct images faster and with fewer training passes (epochs) than strong baselines. On a standard test set (ImageNet at 256×256), V-Co beat the base pixel model and other advanced pixel-diffusion methods at comparable sizes. For example, a mid-sized V-Co matched or exceeded larger baseline models, showing this approach is both effective and efficient.
What this could lead to
This work offers a simple, practical “recipe” for building better image generators that actually understand what they’re drawing:
- More reliable images that follow labels and keep coherent object structure.
- Faster training to good quality, saving time and compute.
- A clear blueprint (dual streams, structural guidance, hybrid loss, and feature calibration) that others can reuse in image, video, or multi-signal generation.
In short, V-Co shows that letting a generator clean up pixels while listening to a strong “meaning” guide—and doing so in the right way—can make AI-generated images both smarter and prettier.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed as concrete directions future researchers can act on:
- Dataset and task scope
- Validate generalization beyond class-conditional ImageNet-256 to higher resolutions (e.g., 512/1024), natural images with captions (e.g., COCO), and web-scale data (e.g., LAION); assess whether gains persist under text-conditioning and open-vocabulary prompts.
- Evaluate transfer to non-natural image domains (e.g., medical, satellite, sketches) where pretrained semantic encoders may carry different biases.
- Teacher feature choices and configurations
- Quantify sensitivity to the choice of teacher encoder (DINOv2 vs CLIP/SigLIP, MoCo-v3, supervised ViTs), to teacher layer(s), and to using multi-layer/multi-scale features rather than a single patch-level feature set.
- Study whether fine-tuning or lightly adapting the teacher (vs keeping it frozen) during co-denoising improves alignment without destabilizing training.
- Assess robustness to teacher domain shift (e.g., features trained on different datasets), and measure how teacher biases propagate to generation.
- Architectural design space and efficiency
- Compare the proposed dual-stream joint self-attention to explicit cross-attention, gated cross-attention, per-head gating, or mixture-of-experts designs; identify when joint self-attention is preferable.
- Investigate where in the network cross-stream interaction should occur (early/mid/late blocks) and whether dynamic scheduling (e.g., gradually enabling cross-stream attention across timesteps) further helps.
- Profile compute/memory overheads of dual-stream token concatenation (sequence length doubling) and propose more efficient variants that retain performance (e.g., low-rank adapters, bottleneck tokens).
- Examine inference-time trade-offs: can the semantic stream be pruned or run at lower frequency or resolution (e.g., every k denoising steps) without large quality loss?
- Classifier-free guidance (CFG) and unconditional branch design
- Characterize sensitivity to the dropout probabilities for labels and features under the structural semantic-to-pixel masking; identify optimal schedules (e.g., cosine/linear decay).
- Explore alternative guidance strategies (e.g., adaptive per-step CFG, consistency/score distillation guidance, classifier guidance) and whether guidance should be applied asymmetrically to pixel vs semantic streams.
- Test variants of the structural mask (e.g., block-wise or head-wise masking, partial attenuation instead of hard masking) and measure effects on stability and controllability.
- Loss design and training dynamics
- Provide a more systematic ablation of the hybrid loss: batch-size dependence, temperature choices (), neighbor selection (same-class vs cross-class), and kernel alternatives beyond RBF.
- Examine whether the negative (repulsive) term harms rare-class fidelity or minority modes; include precision/recall or density/coverage metrics to quantify coverage vs fidelity trade-offs.
- Compare the hybrid loss to modern feature-matching/diversity losses (e.g., InfoNCE in feature space, diffusion-prior contrastive objectives) and to class-conditional energy-based regularizers.
- Analyze the interaction between the semantic-stream weight and the hybrid loss weight ; propose principled schedules (e.g., higher early alignment, decay later) and test curriculum strategies.
- Calibration and noise schedules
- Move beyond global RMS scaling: test per-channel or per-layer normalization/whitening of teacher features; analyze token-wise variance heterogeneity and class-dependent scale differences.
- Evaluate dynamic, timestep-dependent calibration (e.g., time-varying feature rescaling or learned time-shifts) and verify equivalence to SNR matching for general noise schedules (beyond the specific flow parameterization).
- Provide a more rigorous derivation and empirical validation of the stated equivalence between RMS rescaling and timestep shifting under varying schedules (linear/cosine/logSNR) and with normalization layers present.
- Evaluation breadth and rigor
- Report additional metrics (precision/recall, density/coverage, FID/IS per class, CLIP score for text-conditioned settings) to disentangle fidelity vs diversity gains and semantic alignment quality.
- Conduct human evaluations for semantic faithfulness and artifact rates, and analyze failure modes (e.g., small-object counts, fine textures, cluttered scenes).
- Compare sample efficiency rigorously (FID vs training FLOPs or wall-clock) to validate the “fewer epochs” claim across scales and datasets.
- Stability, reproducibility, and ablations
- Quantify training stability across seeds and hyperparameters (e.g., instability from the repulsive term, sensitivity to LR/optimizer variants), and release detailed recipes for reproducible runs at all scales.
- Study long-horizon effects: does strong semantic alignment early in training over-constrain the model later? Evaluate staged or cyclical schedules for auxiliary losses and cross-stream coupling.
- Broader applicability and extensions
- Extend co-denoising to additional structured signals (segmentation, depth, normals) and analyze multi-stream interactions (pixel–semantic–geometry); determine whether the same design choices generalize.
- Test applicability to latent diffusion (VAE- or RAE-based) and hybrid pixel–latent setups to see if pixel–semantic co-denoising is complementary to or redundant with latent compressors.
- Explore downstream uses: controllable generation, image editing, and alignment with text or multi-modal instructions; assess whether the semantic stream improves compositionality and attribute binding.
- Theory and interpretation
- Provide a deeper theoretical explanation for why fully dual-stream architectures outperform shared backbones in co-denoising, and how information flow affects learned invariances/equivariance in pixel-space denoisers.
- Analyze how co-denoising modifies the learned score field in pixel space and whether it induces better-conditioned gradients or more linear semantics in intermediate features.
- Ethical and bias considerations
- Measure and mitigate biases inherited from the teacher encoder (e.g., demographic or content biases in DINOv2 pretraining), and evaluate fairness and representation harms in generated outputs.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage the paper’s “V-Co” recipe (dual-stream co-denoising, structural CFG masking, perceptual-drifting hybrid loss, RMS-based feature calibration) with today’s tools and datasets.
- Stronger, faster training of pixel-space diffusion models for image generation
- Sectors: software/AI platforms, creative industries, gaming/film, e-commerce
- What it enables:
- Drop-in training improvements for class-conditional pixel diffusion (e.g., JiT, PixelDiT) to reach better FID in fewer epochs, cutting compute cost and wall-clock time.
- More semantically faithful assets (e.g., product images, textures, concept art) with improved guidance stability via structural CFG masking.
- Tools/products/workflows:
- “V-Co trainer” module: a reusable, dual-stream training loop that plugs a frozen DINOv2 (or domain encoder) into pixel-diffusion pipelines.
- “Dual-stream CFG” sampler: a CFG path with semantic-to-pixel attention masking to stabilize and strengthen guided sampling.
- “Hybrid loss plugin”: perceptual + drifting loss add-on to increase semantic fidelity and diversity, reducing mode collapse.
- “SNR calibrator”: RMS-based feature rescaling utility to match signal scales across streams.
- Assumptions/dependencies:
- Availability of a strong frozen encoder (e.g., DINOv2) and class labels; the paper’s results are on ImageNet 256×256.
- Existing pixel-space diffusion training stack with Transformer denoisers.
- Proper licensing and domain fit for the chosen encoder.
- Content creation with higher semantic fidelity and controllability
- Sectors: marketing/advertising, media/design, e-commerce
- What it enables:
- Guided generation that adheres better to category or concept constraints, improving brand-specific asset creation or product image variants.
- More consistent structure and semantics under CFG due to structural unconditional definition.
- Tools/products/workflows:
- Asset-generation services integrating V-Co for category- or style-conditioned image synthesis.
- “Brand pack” fine-tuning pipelines that reuse V-Co’s hybrid loss to maintain diversity while matching brand semantics.
- Assumptions/dependencies:
- Curated datasets with reliable labels or features; encoder must generalize to the domain.
- Data augmentation for discriminative models
- Sectors: computer vision applications in software, manufacturing, retail
- What it enables:
- Generation of semantically faithful synthetic data to balance classes or enrich rare conditions, while avoiding over-collapse via the hybrid loss.
- Tools/products/workflows:
- Augmentation pipelines that generate class-consistent images, cache semantic patch features, and feed into classifier or detector training.
- Assumptions/dependencies:
- Alignment between encoder semantics and downstream task; monitoring for dataset shift.
- Research testbed for representation alignment and co-denoising
- Sectors: academia, industrial research labs
- What it enables:
- A controlled JiT-based framework to isolate architectural choices, CFG design, auxiliary losses, and calibration in generative training.
- Reproducible ablations to study early-vs-late alignment, supervision strength, and modality fusion strategies.
- Tools/products/workflows:
- Open-source V-Co codebase as a baseline for future representation-aligned generators and for classroom demos on generative modeling.
- Assumptions/dependencies:
- Access to compute for ImageNet-scale experiments or smaller curated datasets for classroom use.
- Stable multimodal fusion when adding a single auxiliary visual stream
- Sectors: robotics simulation assets, visual effects, scientific imaging (non-clinical)
- What it enables:
- Practical, low-friction way to co-denoise pixel tokens with one semantic stream (e.g., DINOv2 features) while maintaining training stability via RMS rescaling.
- Tools/products/workflows:
- Training scripts that rescale feature streams to match pixel RMS, or equivalently time-shift the semantic stream’s noise schedule.
- Assumptions/dependencies:
- Availability of a reliable auxiliary stream; careful evaluation to avoid leaking biases from the encoder.
Long-Term Applications
The following applications are promising but require additional research, scaling, domain encoders, or broader systems integration.
- Text-to-image and multimodal controllable generation using dual-stream co-denoising
- Sectors: creative industries, software platforms, education
- What it could enable:
- Replace or augment the semantic stream with CLIP/SigLIP or language-vision encoders for stronger text grounding; structural CFG masking to cleanly separate unconditional branches.
- Richer controls by co-denoising pixels with multiple streams (e.g., text semantics, segmentation priors).
- Potential tools/products/workflows:
- “Multistream V-Co”: pixel + text-embedding + segmentation streams with selective cross-attention gates and RMS/SNR calibration per stream.
- Assumptions/dependencies:
- High-quality, large-scale text–image corpora; scalable training and careful safety alignment; licensing for pretrained encoders.
- Video generation with joint semantics for temporal coherence
- Sectors: entertainment, simulation, social media tools
- What it could enable:
- Co-denoising frames with per-frame semantic features, optical flow, or trajectories to enforce structure and reduce flicker.
- Potential tools/products/workflows:
- Video V-Co training where the semantic stream includes temporal features; attention masks extended to spatiotemporal tokens.
- Assumptions/dependencies:
- Large-scale video data, robust temporal encoders, and efficient training to handle sequence length.
- Robotics/world modeling and sim-to-real transfer via multimodal co-generation
- Sectors: robotics, autonomous systems, digital twins
- What it could enable:
- Joint generation of images with maps, depth, or scene graphs to build structured world models for planning and policy learning.
- Potential tools/products/workflows:
- “World-model V-Co” that co-denoises pixels with state/affordance/depth tokens; hybrid loss to maintain coverage and fidelity of rare states.
- Assumptions/dependencies:
- Task-specific encoders for geometry/affordances; rigorous evaluation in closed-loop control; safety constraints.
- Medical imaging synthesis with semantic co-supervision
- Sectors: healthcare (R&D, data augmentation for CAD systems)
- What it could enable:
- Synthetic medical images that respect anatomical semantics (e.g., co-denoising with features from domain-specific encoders).
- Potential tools/products/workflows:
- Privacy-preserving augmentation where the semantic stream comes from encoders trained on public or federated data; hybrid loss to avoid collapse on scarce pathologies.
- Assumptions/dependencies:
- Regulatory compliance, clinical validation, domain encoders (not DINOv2), and bias auditing.
- 3D/scene and NeRF-style asset generation with semantic alignment
- Sectors: gaming, AR/VR, digital twins
- What it could enable:
- Co-denoising images with geometry-aware features (depth, normals) to generate multi-view-consistent assets and boost reconstruction priors.
- Potential tools/products/workflows:
- “Geometry V-Co” that calibrates multiple streams (pixels + depth/normals) using SNR matching; structural masks defining which streams guide which outputs.
- Assumptions/dependencies:
- Reliable multi-view datasets and geometry encoders; integration with differentiable rendering or 3D pipelines.
- Energy- and cost-aware training standards for generative models
- Sectors: policy, sustainability offices in tech enterprises
- What it could enable:
- Best-practice guidelines: early semantic alignment, hybrid loss for sample efficiency, and calibration rules to reduce training epochs and emissions for image generators.
- Potential tools/products/workflows:
- Benchmark protocols that track compute, FID/IS, and energy; standardized reporting on auxiliary encoders and guidance strategies.
- Assumptions/dependencies:
- Community consensus on metrics beyond FID/IS, transparent compute accounting, and reproducibility infrastructure.
- Safer and more controllable generation via structural conditioning pathways
- Sectors: platform safety, enterprise AI
- What it could enable:
- Explicit control of which streams influence outputs (via attention masks) to enforce policy constraints or content filters in guided sampling.
- Potential tools/products/workflows:
- “Conditioning firewall” modules that mask or attenuate certain semantic-to-pixel routes at inference for compliance controls.
- Assumptions/dependencies:
- Verified mapping between semantic features and policy constraints; robust detection of prohibited concepts; guardrails beyond generation quality.
- General multimodal co-denoising beyond vision
- Sectors: audio-visual media, accessibility, HCI
- What it could enable:
- Co-denoising of audio and video streams for lip-synced avatar generation or dubbing; hybrid loss to preserve both intelligibility and diversity.
- Potential tools/products/workflows:
- Audio–visual V-Co with RMS-calibrated streams and structural masks to direct cross-modal influence.
- Assumptions/dependencies:
- High-quality paired datasets, domain encoders (e.g., Wav2Vec-like), and evaluation metrics for multimodal fidelity.
Cross-cutting assumptions and dependencies
- Pretrained encoders: V-Co assumes access to a strong, frozen semantic encoder; domain transfer may require training or selecting encoders aligned with the target domain (e.g., medical, industrial, geo).
- Scale and resolution: Paper results are at 256×256 with class conditioning; moving to higher resolutions, text conditioning, or video needs further engineering and compute.
- Compute and engineering: Dual-stream models can increase parameter counts; overall cost savings depend on faster convergence outweighing larger models.
- Licensing and governance: Using third-party encoders requires proper licensing; downstream uses must adhere to safety and IP guidelines.
- Evaluation breadth: FID/IS improvements do not cover all aspects of quality, safety, and bias; additional task- or domain-specific metrics and audits are needed.
Glossary
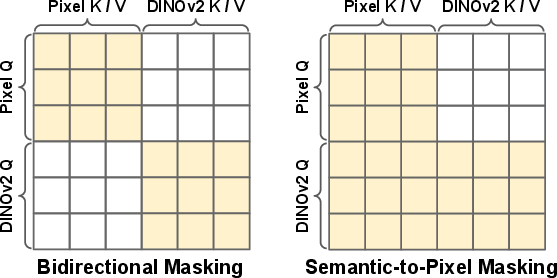
- bidirectional cross-stream masking: An attention-masking strategy that blocks information flow in both directions between pixel and semantic streams during co-denoising. "We also study a symmetric variant, bidirectional cross-stream masking, which blocks attention in both directions (rows (c) and (g))."
- Channel-concatenation fusion: A single-stream integration method that concatenates pixel and semantic tokens along the channel dimension before feeding them to shared blocks. "Channel-concatenation fusion (row (e)): Pixel tokens and semantic features are concatenated along the channel dimension..."
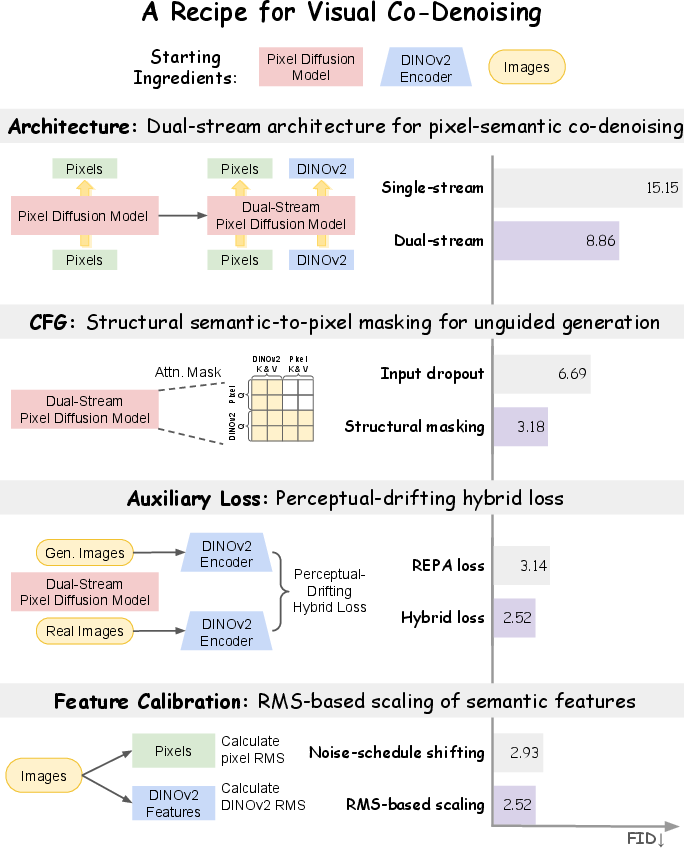
- classifier-free guidance (CFG): A sampling technique that combines conditional and unconditional model predictions to steer generation toward desired conditions. "Second, effective classifier-free guidance (CFG) requires a structurally defined unconditional prediction."
- co-denoising: Jointly denoising multiple correlated streams (e.g., pixels and semantic features) so they can exchange information during generation. "visual co-denoising has emerged as a promising direction"
- DINOv2: A strong self-supervised vision encoder used to provide pretrained semantic features for alignment and supervision. "a pretrained DINOv2 encoder"
- distribution-level regularization: A training signal that encourages the generated distribution to match the real data distribution, complementing per-instance alignment. "we observe that instance-level semantic alignment and distribution-level regularization play complementary roles"
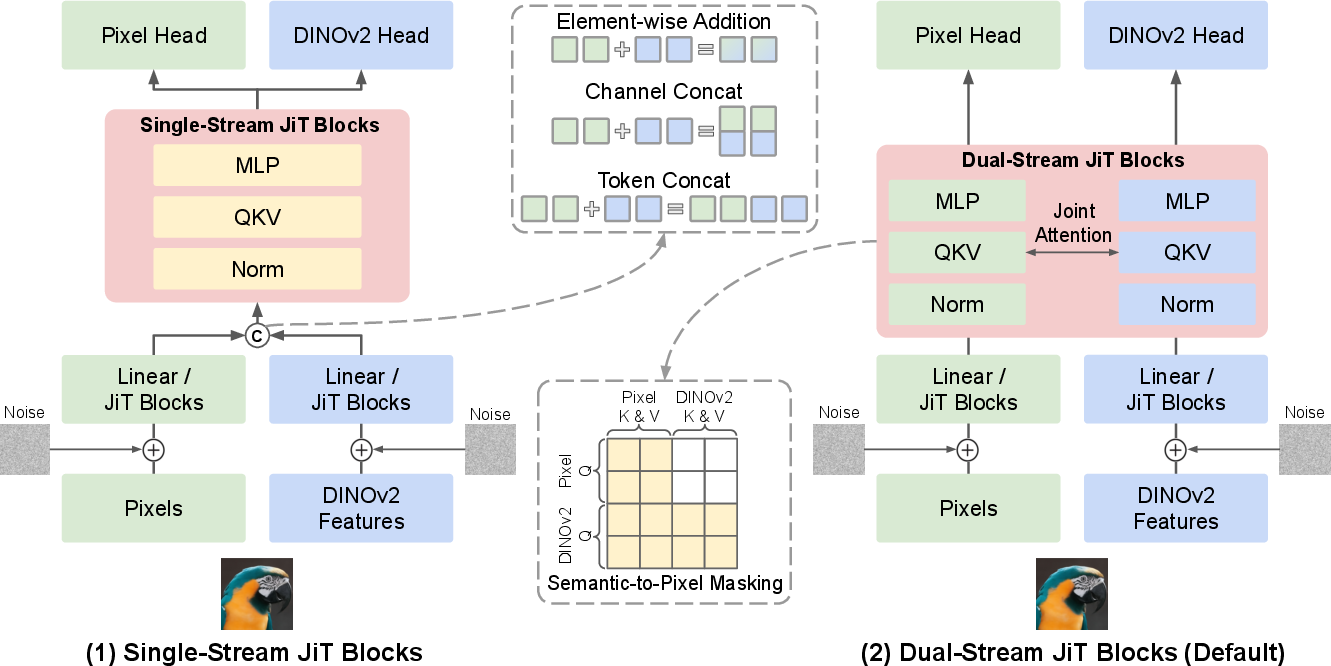
- dual-stream JiT architecture: A co-denoising design with separate pixel and semantic branches that interact via shared attention while maintaining stream-specific parameters. "we further introduce a dual-stream JiT architecture, illustrated on the right of \cref{fig:model_architecture_ablation}"
- FID (Fréchet Inception Distance): A metric that quantifies the distance between distributions of real and generated images using Inception features. "Following previous works~\cite{li2025back, baade2026latent}, we mainly use FID as reference."
- flow-matching parameterization: A diffusion parameterization framing noisy inputs as a linear interpolation between signal and noise over continuous time. "Under this flow-matching parameterization, the noised input takes the form"
- guided sampling: The process of combining conditional and unconditional predictions (often scaled) during inference to enforce conditioning signals. "Guided sampling combines the conditional and unconditional predictions in the pixel and semantic streams as"
- JiT: A minimalist pixel-space Transformer diffusion framework used as the base for experimentation and ablations. "Recent systems such as JiT~\cite{li2025back} show that direct pixel-space denoising can be competitive"
- latent diffusion models (LDMs): Diffusion models that operate in compressed latent spaces (e.g., VAE latents) rather than pixel space. "latent diffusion models~\cite{Rombach_2022_CVPR} (LDMs)"
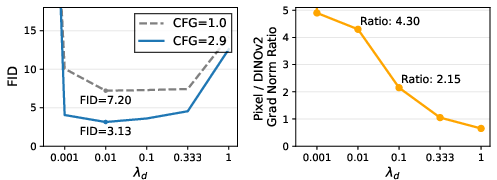
- noise-schedule shifting: Adjusting the diffusion timestep schedule for a specific stream (e.g., semantic features) to balance denoising difficulty across streams. "Feature rescaling \vs{ noise-schedule shifting in V-Co.}"
- patch-level semantic features: Spatially localized embeddings from a vision encoder corresponding to image patches, used for semantic guidance. "patch-level semantic features from a frozen pretrained visual encoder (\eg{}, DINOv2~\cite{oquab2023dinov2})"
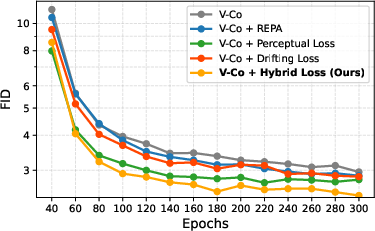
- perceptual loss: An auxiliary objective that penalizes differences between generated and target images in a pretrained feature space. "We also consider a perceptual loss~\cite{johnson2016perceptual, ma2026pixelgen} in the pretrained semantic feature space."
- perceptual-drifting hybrid loss: A combined objective that attracts generated samples toward paired targets in feature space while adding repulsion to improve distributional coverage. "a perceptual-drifting hybrid loss that combines instance-level alignment with distribution-level regularization"
- REPA: A representation-alignment approach that matches diffusion model features to those of a pretrained encoder during training. "representation-alignment methods (\eg{}, REPA) suggest that pretrained visual features can substantially improve diffusion training"
- representation alignment: The practice of aligning a generative model’s internal features or outputs to a pretrained representation space to inject semantic structure. "we study visual co-denoising as a mechanism for visual representation alignment."
- representation latent space: A feature space produced by a pretrained encoder in which diffusion can be performed instead of pixel or VAE-latent spaces. "Another performs denoising directly in a representation latent space, rather than in pixel or VAE latent space"
- RMS-based feature rescaling: Scaling semantic features to match pixel RMS magnitude to calibrate signal levels across streams. "RMS-based feature rescaling for cross-stream calibration"
- semantic-to-pixel masking: An attention mask that prevents semantic tokens from attending into the pixel branch to form an unconditional path for CFG. "we apply semantic-to-pixel masking (see \cref{fig:attention_mask}), which blocks cross-stream attention from the semantic stream to the pixel stream"
- self-attention (joint self-attention): The attention mechanism allowing tokens within and across streams to interact; “joint” denotes shared attention across streams. "while interacting through joint self-attention."
- signal-to-noise ratio (SNR): The ratio of signal power to noise power at a diffusion timestep, used for calibration analysis. "We define the signal-to-noise ratio (SNR) at time as the ratio between the signal power and the noise power:"
- similarity kernel: A kernel function measuring similarity between features, used to weight neighbors in the drifting field. " is a similarity kernel"
- similarity-based gating: A mechanism that adaptively balances attraction and repulsion based on how close a generated feature is to its target. "we introduce a similarity-based gating mechanism based on how close the generated feature is to its target"
- stop-gradient: An operation that prevents gradients from flowing through a tensor, used to stabilize vector-field objectives. "where denotes stop-gradient."
- token-concatenation fusion: A fusion strategy concatenating pixel and semantic tokens along the sequence dimension before shared processing. "token-concatenation fusion outperforms direct addition and channel concatenation among the single-stream variants"
- unconditional prediction: The model’s prediction without conditioning inputs, required for forming guidance in CFG. "the model must define an unconditional prediction, \ie{}, a prediction in which the conditioning signals are removed."
- v-loss (velocity loss): A diffusion objective in which models predict velocity (a linear transform of noise and signal) rather than denoised pixels directly. "we extend the -prediction and -loss formulation of JiT to jointly denoise pixels and pretrained semantic features."
- velocity predictions: Predictions of the velocity parameterization used for training diffusion models more stably than direct denoising. "we convert these clean predictions into velocity predictions"
- x-prediction: A diffusion training target in which the model predicts the clean data (x) directly. "we extend the -prediction and -loss formulation of JiT"
Collections
Sign up for free to add this paper to one or more collections.