Chronos: Temporal-Aware Conversational Agents with Structured Event Retrieval for Long-Term Memory
Abstract: Recent advances in LLMs have enabled conversational AI agents to engage in extended multi-turn interactions spanning weeks or months. However, existing memory systems struggle to reason over temporally grounded facts and preferences that evolve across months of interaction and lack effective retrieval strategies for multi-hop, time-sensitive queries over long dialogue histories. We introduce Chronos, a novel temporal-aware memory framework that decomposes raw dialogue into subject-verb-object event tuples with resolved datetime ranges and entity aliases, indexing them in a structured event calendar alongside a turn calendar that preserves full conversational context. At query time, Chronos applies dynamic prompting to generate tailored retrieval guidance for each question, directing the agent on what to retrieve, how to filter across time ranges, and how to approach multi-hop reasoning through an iterative tool-calling loop over both calendars. We evaluate Chronos with 8 LLMs, both open-source and closed-source, on the LongMemEvalS benchmark comprising 500 questions spanning six categories of dialogue history tasks. Chronos Low achieves 92.60% and Chronos High scores 95.60% accuracy, setting a new state of the art with an improvement of 7.67% over the best prior system. Ablation results reveal the events calendar accounts for a 58.9% gain on the baseline while all other components yield improvements between 15.5% and 22.3%. Notably, Chronos Low alone surpasses prior approaches evaluated under their strongest model configurations.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Chronos, a new way to give AI chatbots a reliable long-term memory that understands time. Imagine chatting with an assistant for months: your plans change, your preferences update, and you refer back to “last week” or “the month after my trip.” Chronos helps the AI remember and reason about those time-based details so it can answer questions like “What camera lens did I buy most recently?” or “How many times did I exercise in May?” accurately.
What questions were the researchers trying to answer?
In simple terms, they asked:
- How can we help AI remember long conversations over weeks or months without getting lost in the details?
- How can the AI handle time-based questions (like “before,” “after,” “last month,” or “most recent”) correctly?
- Can we retrieve only the information that matters for a given question instead of building a giant, complicated knowledge graph?
- Will a system that mixes structured time-based facts with the original chat text beat existing methods?
How does Chronos work?
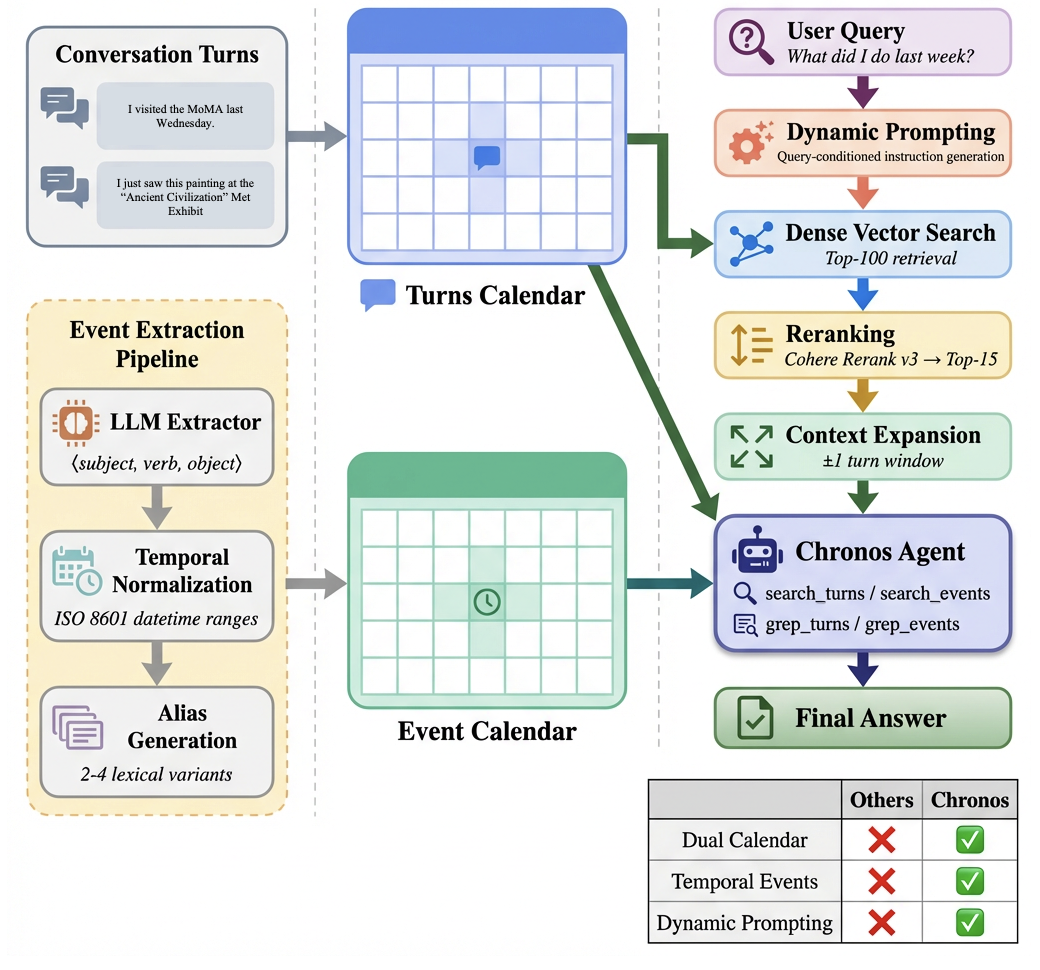
Chronos is built around a simple idea: keep two “calendars” of your conversations, and use them smartly.
Two calendars: one for events, one for full conversations
- Event calendar: A tidy timeline of important happenings, each with who did what to whom and when it happened. Think of it as a neat planner.
- Turn calendar: The original chat messages (turns) with their timestamps. Think of it as your full chat history.
Why both? The event calendar makes time math easy (“most recent,” “in May”), while the turn calendar keeps the full context and tone of the conversation.
Turning chats into structured events
Chronos breaks parts of your chat into simple sentence “skeletons” like subject–verb–object (for example, “I bought Fitbit”). It also turns fuzzy time phrases such as “last month,” “recently,” or “the week after my vacation” into exact date ranges (like May 1–May 31). When words can mean the same thing (“bought a Fitbit” vs. “picked up a fitness tracker”), Chronos adds a few synonyms to help find the right event later.
Analogy: It’s like taking messy notes and rewriting them as tidy calendar entries with clear dates, while keeping the original notebook nearby.
Smart guidance for each question (dynamic prompting)
Before searching, Chronos writes a short “tip sheet” for the AI, customized to the question. For “What camera lens did I buy most recently?”, it might say: look for purchase events about camera lenses and pick the newest one. This helps the AI choose the right search strategy for the problem at hand (counting, finding latest, filtering by time, etc.).
Finding the right information
Chronos starts by pulling the most relevant chat snippets from the turn calendar using:
- Meaning-based search (finds text that “means” the same thing even if words differ)
- A re-check step (reranking) to sort the best matches to the top
- Small context windows around those matches so the AI sees what came before and after
This gives the AI a helpful starting point.
The agent’s search-and-think loop
The AI then reasons step by step:
- If more info is needed, it can search the event calendar (great for time filtering) or the turn calendar (great for full context).
- It can do meaning-based search (find similar ideas) or exact keyword search (like using Ctrl+F).
- It repeats this “think → search → read → think again” loop until it’s confident enough to answer.
This loop helps on “multi-hop” questions (multi-step problems), like “Count all my gym visits in May, then tell me if that’s more than in June.”
What did they find?
The team tested Chronos on a standard long-term memory benchmark with 500 questions across six types of tasks (like tracking updates over time, counting across many sessions, and temporal reasoning).
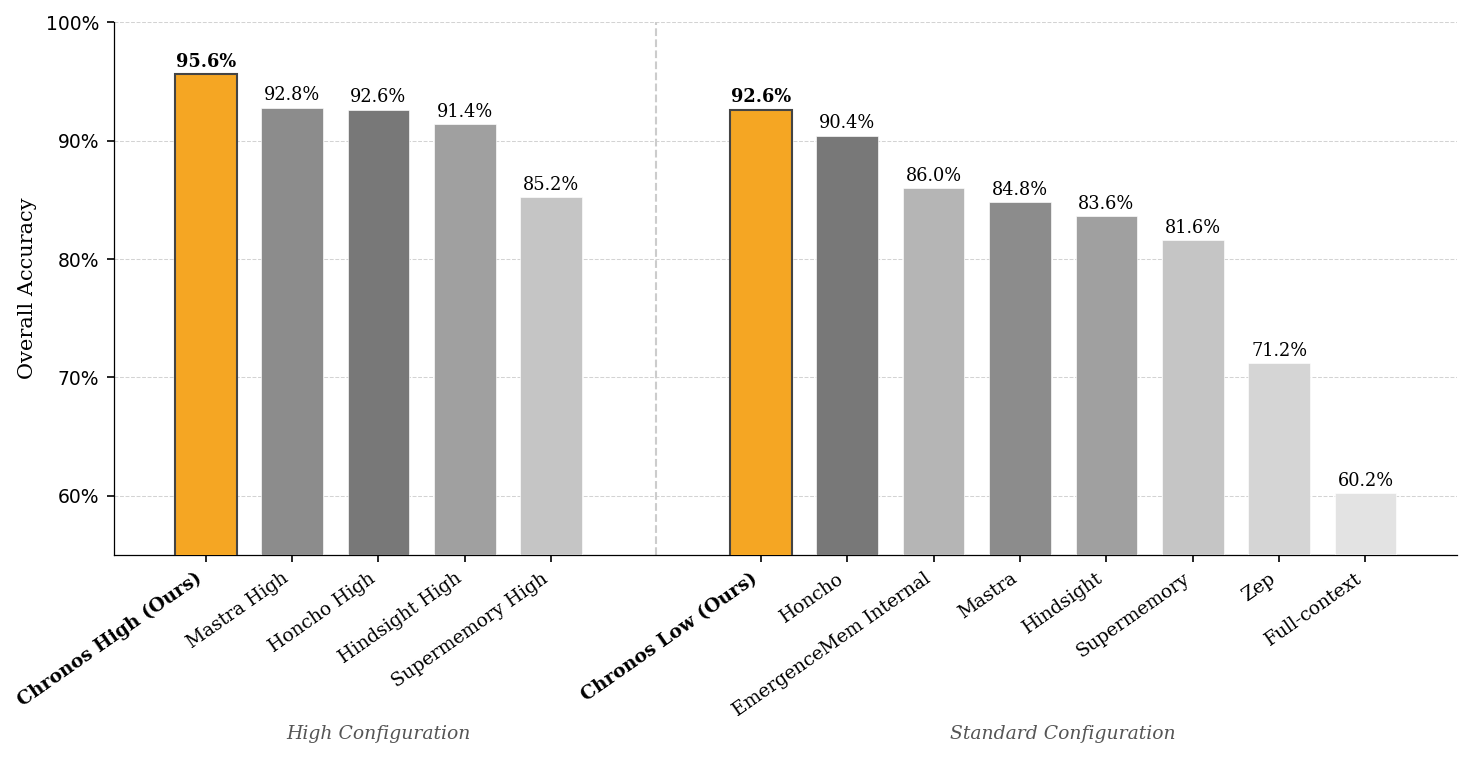
- Chronos Low scored 92.60% accuracy.
- Chronos High scored 95.60% accuracy.
- These are new state-of-the-art results, with Chronos beating the best prior systems. For example, Chronos improved by 7.67% over a strong previous method in a comparable setting.
Why it works:
- The event calendar (the structured timeline) was the biggest win. In ablation tests (turning features off to see what matters), the events calendar accounted for most of the gains (about 58.9% of the improvement over the baseline).
- Other pieces—like the tip sheet for each question (dynamic prompting), the initial retrieval, and reranking—each added helpful boosts (roughly 15–22% improvements in their tests).
- Even the “smaller” Chronos setup (Chronos Low) beat prior methods that used stronger AI models, showing the architecture itself matters a lot.
Why does this matter?
This research suggests a practical path to trustworthy, long-term AI assistants:
- Better recall over months: The AI can handle “latest,” “before,” “after,” and “in May” precisely, not just roughly.
- Less clutter, more relevance: Instead of building a giant, complicated knowledge graph for everything, Chronos only structures what helps with time-based questions and keeps the rest as normal chat text.
- Strong performance without extreme complexity: It shows you don’t need to overengineer memory to get great results—just structure the time parts well and retrieve smartly.
Possible real-world uses:
- Personal assistants that track changing schedules, health logs, habits, and purchases over time.
- Work assistants that remember project milestones, role changes, or deadlines accurately.
- Education or coaching tools that track progress and “most recent” achievements.
Limitations and future ideas
- Extra storage and compute: Keeping two indexes (events + turns) and doing event extraction costs space and time.
- Speed vs. thoroughness: The agent’s multi-step searching can add latency.
- Future directions: Teach models to learn from these event timelines (not just retrieve them), make the system faster, and support shared histories across teams or multiple assistants.
In short: Chronos shows that if you treat time carefully—by building a simple event calendar alongside the full chat—you can make AI assistants much better at long-term memory and time-based reasoning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- Event extraction quality is unquantified: no precision/recall or human-annotated evaluation of the SVO tuple extraction and temporal normalization accuracy (including coreference resolution and ambiguity handling).
- Temporal normalization robustness is unvalidated: the method for resolving vague expressions (“recently,” “last month”) into ISO 8601 ranges lacks error analysis across diverse phrasings, time zones, DST changes, and multi-locale formats.
- Entity resolution details are underspecified: Chronos mentions “entity aliases” but provides no method or metrics for cross-session entity disambiguation, alias merging, or handling name collisions.
- Alias generation impact is unknown: the retrieval benefit and potential noise introduced by 2–4 lexical aliases per event are not ablated or measured (e.g., false positives, vocabulary drift, and multilingual queries).
- Preference recall weakness is unexplained: Chronos underperforms on single-session preference recall (SSP) but provides no root-cause analysis or architectural mitigation (e.g., specialized preference schemas or decoupled preference indices).
- Multi-session regression in Chronos High is unexplored: the drop in MS accuracy relative to Chronos Low is noted but not investigated (e.g., model reasoning trade-offs, prompt interactions, or retrieval dynamics).
- Dynamic prompting necessity is unclear across models: its negligible effect for stronger models (Chronos High) and large gains for weaker ones are reported without systematic analysis of when and why it helps.
- Retrieval pipeline design choices are untested: the decision to rerank using the original question (not agent-generated subqueries), top-k values (100→15), and the 1-turn context expansion are not tuned or compared against alternatives (e.g., agent-query reranking, ColBERT-style late interaction, session-level windows).
- Agentic tool-calling policies lack formalization: no analysis of step limits, termination criteria, failure recovery, or cost–latency trade-offs under varying query complexity and index sizes.
- Scalability and cost are uncharacterized: storage growth, offline extraction cost, inference-time latency, and cloud spending for dual indices and parallel tool usage lack empirical measurements and scaling curves.
- Real-world longitudinal evaluation is missing: results are limited to LongMemEvalS; performance on naturalistic, noisy, months-long production conversations (e.g., LoCoMo or enterprise logs) is not assessed.
- Benchmark reliability concerns are unaddressed: reliance on LLM-as-judge with known dataset issues raises validity questions; no human evaluation or judge calibration study is provided.
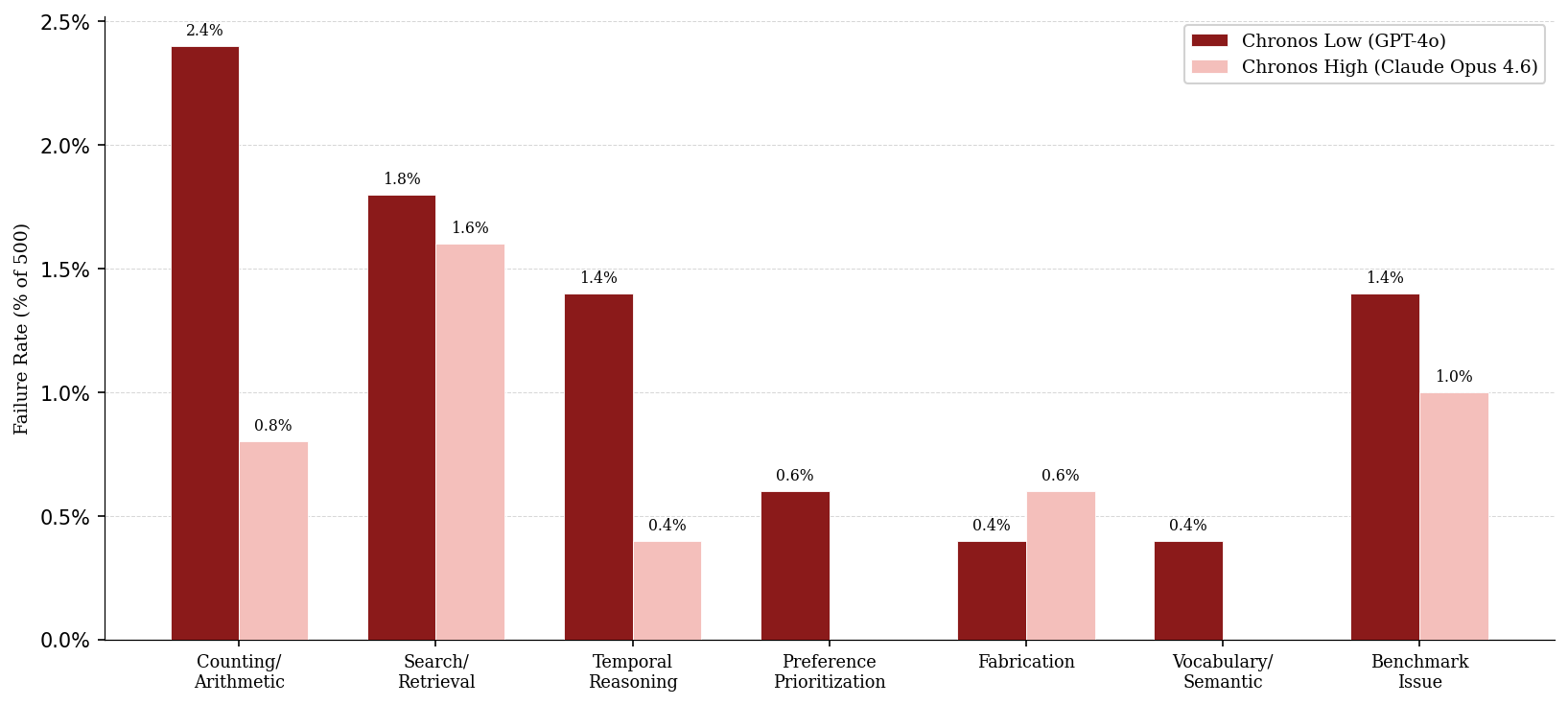
- Error mitigation strategies are absent: counting/arithmetic errors, retrieval failures, and fabrications are documented but no algorithmic remedies (symbolic aggregators, abstention detection, evidence thresholds) are proposed or tested.
- Conflict resolution for “current vs. past” facts is heuristic: the approach seems to prefer the most recent event, but does not formalize state-change detection (start/end states, ongoing vs. completed) or handle overlapping updates.
- Event deduplication and consolidation are unspecified: how repeated, overlapping, or near-duplicate events are merged, ranked, or pruned (to reduce index entropy) is not described or evaluated.
- Cross-session temporal reasoning coverage is partial: relative references anchored to the conversation timestamp may mis-handle events described generically (e.g., “every other Sunday”) or spanning long durations; recurrence handling is not addressed.
- Grep vs. vector interplay is underexplored: grep-based exact matching is useful but no analysis of its precision/recall trade-offs, brittleness to paraphrase, or scalability on large corpora is provided.
- Multilingual and cross-lingual scenarios are unsupported: extraction, aliasing, and retrieval are English-centric; adaptability to multilingual conversations and code-switching is unknown.
- Domain generalization is untested: applicability to specialized domains (health logs, financial planning, compliance) requiring domain-specific temporal schemas, ontologies, or units is not evaluated.
- Privacy, security, and compliance are not discussed: PII handling, encryption, access controls, retention policies, and auditability for temporal event stores and raw turns are absent.
- Streaming and near-real-time updates are unspecified: how Chronos handles continuous ingestion, consistency between indices, and concurrency in live deployments is not covered.
- Multi-user/multi-agent shared memory is future work only: mechanisms for shared event histories, conflict resolution, and access isolation are proposed but not designed or tested.
- Learning from events is an open direction: the idea to update model weights using accumulated event traces lacks a concrete training protocol, data selection strategy, and evaluation plan.
- Robustness to adversarial or noisy inputs is unknown: no tests on misdated statements, contradictory claims, or adversarial phrasing that could poison temporal normalization or retrieval.
- Non-text modalities are unsupported: images, attachments, or structured logs (calendars, emails) that carry rich temporal signals are not integrated or evaluated.
Practical Applications
Immediate Applications
The following applications can be deployed with today’s LLMs, vector databases, and standard RAG tooling by incorporating Chronos’s dual calendars (event calendar + turn calendar), multi-resolution temporal normalization, dynamic prompting, and agentic retrieval with vector + grep search and reranking.
- Sector(s): Customer Support, CRM, CX; Use case: Case timeline assistants that recall “most recent” actions, policy changes, or resolution steps across months of emails/chats; Workflow/tools: Ingest support threads into turn calendar, extract timestamped SVO events (e.g., user reported bug, agent shipped replacement), index in vector DB (e.g., Pinecone/Milvus), rerank (Cohere Rerank), agent uses date filters to answer “What did we try last time?”; Assumptions/dependencies: Reliable timestamps and channel IDs, access to CRM/Helpdesk (Salesforce/Zendesk), LLM API budget, PII governance (GDPR/CCPA).
- Sector(s): Healthcare (non-diagnostic assistants, care navigation); Use case: Patient-facing assistants that track med start/stop, appointment changes, symptom logs, and “when did I start that medication?” queries; Workflow/tools: Event extraction for dose changes and appointments with ISO ranges; dual retrieval across secure chat and portal messages; HIPAA-compliant deployment with audit logs; Assumptions/dependencies: Clinical safety guardrails, accurate time logging, BAA-covered infrastructure, consent.
- Sector(s): Project/Program Management & Productivity; Use case: Meeting and decision memories—“what did we decide last sprint?”, “who took ownership and when?”, “what changed since Q1?”; Workflow/tools: Index Slack/Teams, calendar notes, PR descriptions; extract decisions/assignments as events; dynamic prompting guides aggregation by sprint/month; integrate with Jira/Asana; Assumptions/dependencies: Access to collaboration platforms, identity resolution across tools, data retention policies.
- Sector(s): Legal, Compliance, eDiscovery; Use case: Auto-constructed factual timelines across document dumps and chat, with exact-phrase grep for names/IDs and temporal filters; Workflow/tools: Hybrid vector+grep over turns and event calendar, exportable “timeline report” with source citations; Elastic/OpenSearch for text search; Assumptions/dependencies: Chain-of-custody/auditability, strict PII handling, validated export formats, defensibility in court.
- Sector(s): Security Operations (SOC), IT Operations; Use case: Incident timeline assistants that answer “what happened before/after the outage?”, “when was the first occurrence?”; Workflow/tools: Parse tickets/alerts into events, apply date-based filters and multi-hop aggregation; integrate with SIEM (Splunk, Sentinel) and ITSM; Assumptions/dependencies: High-volume log ingestion pipelines, de-duplication to reduce noise, role-based access.
- Sector(s): Sales/RevOps; Use case: “Most recent contact” and “next step” recall across emails/calls/CRM notes; Workflow/tools: Event aliases to capture varied phrasing (“demo booked” vs “scheduled presentation”), dynamic prompting to emphasize recency; Assumptions/dependencies: Email/calendar access, compliance with company monitoring policies, consent.
- Sector(s): Education, EdTech; Use case: Tutoring and coaching systems that track skill progression, recent mistakes, and study streaks—“what did I struggle with last week?”; Workflow/tools: Extract assessment results/session topics as events, date filters for per-week/per-unit summaries; integrate with LMS (Canvas/Moodle); Assumptions/dependencies: Student consent and FERPA-like protections, consistent timestamps in LMS exports.
- Sector(s): Personal Productivity & Consumer Assistants; Use case: Long-term personal memory—preferences updates (“coffee order changes”), purchase recency (“last camera lens”), habit tracking; Workflow/tools: On-device or cloud index of chats/notes; event aliasing to handle varied phrasing; Assumptions/dependencies: App permissions, privacy expectations, clear opt-in, on-device storage for sensitive data.
- Sector(s): Software Engineering/DevOps; Use case: “When did we release X?”, “how many rollbacks in March?”, “who approved the last change?”; Workflow/tools: Extract deployment/approval events from CI/CD logs and PRs; dual retrieval across commit history and chat; Assumptions/dependencies: Access to repos/pipelines, consistent commit metadata, SRE policy alignment.
- Sector(s): HR/People Ops; Use case: Performance review assistants with chronological evidence (goals set/achieved, feedback moments); Workflow/tools: Extract milestone events from feedback tools and 1:1 notes; temporal filters to surface latest achievements; Assumptions/dependencies: Consent, bias mitigation, transparency to employees, secure storage.
- Sector(s): Knowledge Management/Enterprise Search; Use case: “What changed since last quarter?” knowledge-update tracking across wikis, announcements, and chats; Workflow/tools: Event extraction focused on state transitions (e.g., policy updated from v2 to v3), reranking to reduce noise; Assumptions/dependencies: Versioned docs, change logs availability.
- Sector(s): Field Service, IoT/Devices; Use case: Maintenance history recall—“what parts were replaced last year?”, “time since last calibration?”; Workflow/tools: Extract service events from work orders and technician chats; exact-phrase grep for SKUs; Assumptions/dependencies: Structured identifiers, timestamp accuracy, offline-to-online data sync.
Long-Term Applications
These concepts extend Chronos’s approach but may require further research, engineering, scaling, or policy development before broad deployment.
- Sector(s): Cross-Org “Memory Fabric”; Use case: Shared event histories across teams and tools (multi-agent, multi-user), enabling enterprise-wide timeline queries; Workflow/tools: Standardized event schemas, identity resolution, federation across vector/search backends; Assumptions/dependencies: Interoperability standards, data lineage, access controls, governance councils.
- Sector(s): Privacy-Preserving / On-Device Memory; Use case: Edge indexing of events and turns with local LLMs for personal assistants and regulated industries; Workflow/tools: Quantized embeddings, local rerankers, encrypted storage; Assumptions/dependencies: Device compute/storage constraints, MLC/ggml-class models, secure enclaves.
- Sector(s): Model Training & Continual Learning; Use case: Fine-tune or adapt models from accumulated event traces to boost time-aware reasoning and reduce tool calls; Workflow/tools: Curate event datasets with labels, rehearsal strategies to prevent forgetting, privacy-preserving training; Assumptions/dependencies: Data minimization, consent, reproducibility, robust evaluation against temporal drift.
- Sector(s): Real-Time Streaming Memory; Use case: Low-latency event extraction from live voice meetings, chats, and telemetry to support in-call “what did we agree just now?”; Workflow/tools: Incremental indexing, streaming ASR, sliding-window event extraction; Assumptions/dependencies: ASR accuracy, latency budgets, backpressure handling, cost optimization.
- Sector(s): Healthcare, Finance, Legal (Regulated); Use case: Auditable “explainable memory”—every answer links to event sources and time ranges for compliance; Workflow/tools: Provenance tracking, immutable logs, evidence-bounded generation; Assumptions/dependencies: Regulatory acceptance, standardized audit formats, independent validation.
- Sector(s): Multi-Modal Memory; Use case: Temporal events from audio/video/images (e.g., meeting recordings, facility inspections) to enrich timelines; Workflow/tools: Vision/ASR models feeding event extractor, cross-modal alignment with timestamps; Assumptions/dependencies: High-quality transcription/captioning, storage costs, rights management.
- Sector(s): Safety & Reliability; Use case: Memory guardrails—abstention policies, confidence scoring, retrieval coverage checks to prevent fabrication in long-horizon queries; Workflow/tools: Evidence-gap tracking, calibration layers, contrastive answers with “insufficient evidence” handling; Assumptions/dependencies: Policy frameworks, user experience design for refusals.
- Sector(s): Domain-Specific Event Ontologies; Use case: Healthcare orders, financial transactions, supply chain movements with richer event types and constraints; Workflow/tools: Schema extensions, validators for domain rules, temporal reasoning libraries; Assumptions/dependencies: SME input, standards alignment (e.g., FHIR, ISO 20022), sustained maintenance.
- Sector(s): Government & Civic Tech; Use case: Citizen case-management chatbots that maintain long-term histories (benefits, permits) with clear timelines and updates; Workflow/tools: Secure event indices per citizen, cross-agency data sharing agreements; Assumptions/dependencies: Policy for data sharing, resident consent, accessibility standards.
- Sector(s): Large-Scale IoT / Digital Twins; Use case: Time-aware digital twins that answer multi-hop, time-windowed queries over billions of device events; Workflow/tools: Hierarchical indexing, approximate nearest neighbor search at scale, time-series fusion with event calendars; Assumptions/dependencies: Cost-effective infra, data quality, deduplication strategies.
- Sector(s): Research & Benchmarking; Use case: Improved long-term memory benchmarks that isolate temporal reasoning and knowledge updates, plus open-source Chronos-style SDKs; Workflow/tools: Public datasets with controlled temporal artifacts, reproducible evaluation harnesses; Assumptions/dependencies: Community adoption, clear licensing, funding for maintenance.
Notes on Feasibility and Dependencies (Common Across Applications)
- Technical: Availability and stability of LLMs, embedding models, and rerankers; vector/full-text search infra (e.g., Pinecone, Milvus, Weaviate, Elasticsearch); latency/cost trade-offs for dynamic prompting and agentic tool-calling; storage overhead for dual indexes.
- Data: Accurate timestamps, session metadata, and identity resolution; access to source systems (chat, email, tickets, logs); data quality for temporal normalization; alias generation may boost recall but can introduce noise.
- Security/Privacy: Compliance with HIPAA/GDPR/CCPA and internal policies; PII redaction and role-based access; auditability and provenance for regulated answers.
- Organizational: Change management to integrate with existing workflows; stakeholder consent and transparency (especially HR/education); governance for cross-system memory sharing.
- Evaluation: Need for domain-specific acceptance tests beyond generic benchmarks; monitor error modes (counting, retrieval misses, hallucination) and implement guardrails and abstention strategies.
Glossary
- Ablation: A controlled removal of components in a system to measure their individual contributions to performance. "Ablation results reveal the events calendar accounts for a 58.9\% gain on the baseline while all other components yield improvements between 15.5\% and 22.3\%."
- Agentic RAG: A retrieval-augmented generation paradigm where an LLM autonomously decides when and how to retrieve information using tools during reasoning. "Beyond static retrieval pipelines, agentic RAG introduces a tool-calling paradigm in which an LLM autonomously decides when and how to retrieve additional context, iteratively refining its search until sufficient evidence is gathered"
- Agentic retrieval: An iterative, LLM-driven retrieval process that adapts queries and tools over multiple steps to gather evidence. "Although agentic retrieval improves recall on complex, multi-hop queries, it introduces latency and cost at inference time, creating a tradeoff between retrieval thoroughness and system responsiveness."
- BM25: A probabilistic sparse retrieval algorithm that ranks documents by exact term matches and term frequencies. "Sparse retrieval methods like BM25 excel at exact lexical matching and are computationally efficient, but miss semantic variations and synonymy"
- Chain-of-thought: A prompting strategy that guides models to articulate intermediate reasoning steps before final answers. "The generated preamble integrates into the agent's system prompt alongside retrieval tool descriptions, chain-of-thought guidelines, and pre-retrieved context as detailed in Subsection~\ref{subsec:initial_retrieval}."
- Coreferences: Mentions in text that refer to the same entity and must be resolved for accurate understanding. "event-based methods like elementary discourse unit (EDU) extraction rewrite sessions into self-contained, event-like statements that normalize entities and resolve coreferences"
- Cross-encoder reranking: Re-scoring retrieved candidates with a model that jointly encodes query and candidate text to improve relevance ordering. "Chronos applies cross-encoder reranking to improve relevance, using Cohere Rerank v3 to rescore the 100 retrieved candidates based on semantic similarity between the query and turn text."
- Cross-session aggregation: Combining information spread across multiple conversation sessions to answer a query. "while extracted events with structured datetime ranges enable precise temporal filtering and cross-session aggregation."
- Dense retrieval: Retrieval using learned vector embeddings to capture semantic similarity between queries and documents. "Dense retrieval using learned embeddings captures semantic similarity but struggles with precise term matching and rare entities"
- Dense-sparse hybrid search: A retrieval approach that combines dense (embedding-based) and sparse (lexical) methods to improve recall and precision. "Simpler turn-level retrieval approaches avoid this overhead through direct dense-sparse hybrid search over conversation turns"
- Dynamic prompting: Generating per-question instructions that steer the agent’s retrieval and reasoning strategy at inference time. "At query time, Chronos applies dynamic prompting to generate tailored retrieval guidance for each question, directing the agent on what to retrieve, how to filter across time ranges, and how to approach multi-hop reasoning"
- Elementary Discourse Unit (EDU) extraction: Segmenting text into minimal discourse units to produce event-like, normalized summaries. "event-based methods like elementary discourse unit (EDU) extraction rewrite sessions into self-contained, event-like statements that normalize entities and resolve coreferences"
- Entity aliases: Alternative phrasings or synonyms for entities to improve matching and retrieval recall. "decomposes raw dialogue into subject-verb-object event tuples with resolved datetime ranges and entity aliases"
- Entity resolution: The process of detecting and unifying mentions that refer to the same real-world entity. "Systems employing comprehensive knowledge graphs extract all facts and relationships at ingestion time, building elaborate graph structures with entity resolution, fact validation, and temporal metadata"
- Event calendar: A structured index of extracted, timestamped events with normalized time ranges for temporal retrieval. "indexing them in a structured event calendar alongside a turn calendar that preserves full conversational context."
- Evidence-gap trackers: Mechanisms that monitor missing information during retrieval, guiding subsequent retrieval actions. "Others introduce autonomous retrieval controllers with evidence-gap trackers that route between different retrieval actions based on accumulated evidence"
- HyDE (Hypothetical Document Embeddings): A technique that generates synthetic answers to bridge the semantic gap between queries and documents. "Hypothetical document embeddings (HyDE) generate synthetic answers to bridge the query-document semantic gap"
- ISO 8601: An international standard for date and time representations, enabling precise, machine-readable timestamps. "The pipeline implements multi-resolution temporal normalization to convert natural language time references into precise ISO 8601 datetime ranges."
- Knowledge graph: A structured representation of entities and relations enabling explicit, graph-based reasoning. "Systems employing comprehensive knowledge graphs extract all facts and relationships at ingestion time, building elaborate graph structures with entity resolution, fact validation, and temporal metadata"
- LLM judge: An LLM-based evaluator that compares system outputs to ground truths using rubric-based prompts. "we implement LongMemEval's LLM judge, which compares the hypothesis to the ground truth, routing to a specific prompt based on the question's category."
- Meta-prompt: A higher-level prompt used to instruct an LLM on how to generate or adapt another prompt. "The template generator uses an LLM meta-prompt to analyze the question structure and produce tailored guidance."
- Multi-hop reasoning: Solving queries that require chaining multiple pieces of evidence or sub-questions. "directing the agent on what to retrieve, how to filter across time ranges, and how to approach multi-hop reasoning through an iterative tool-calling loop over both calendars."
- Multi-resolution temporal normalization: Converting time expressions at varying granularities into precise, standardized time ranges. "The pipeline implements multi-resolution temporal normalization to convert natural language time references into precise ISO 8601 datetime ranges."
- Query decomposition: Splitting a complex question into sequential sub-queries that can be retrieved and answered step-by-step. "Query decomposition breaks complex multi-hop questions into sequential sub-queries, each retrievable independently"
- Query rewriting: Reformulating a user query to improve retrieval by resolving ambiguities and aligning with indexed content. "Chronos introduces dynamic prompting for long-term memory, extending query rewriting from the document retrieval literature"
- Query-conditioned selective extraction: Extracting and structuring only the information relevant to a specific question rather than building a comprehensive knowledge base upfront. "a conversational memory framework centered on query-conditioned selective extraction."
- RAG (Retrieval-Augmented Generation): A paradigm where generation is augmented by retrieved external knowledge. "With breakthroughs in RAG for conversational memory, LLM agents can efficiently access historical information without exhausting context window limits"
- ReAct: A reasoning pattern that interleaves thoughts and actions (tool calls) to iteratively gather evidence and solve tasks. "The agent follows a ReAct reasoning pattern, alternating between thought generation, tool calling, and observation processing"
- Reciprocal rank fusion: A method for combining rankings from multiple retrieval systems by aggregating reciprocal ranks. "Hybrid approaches that fuse both modalities (typically via reciprocal rank fusion or learned reranking) have emerged as the dominant paradigm in RAG systems"
- Temporal filtering: Restricting retrieval to items that fall within specified time windows or ranges. "extracted events with structured datetime ranges enable precise temporal filtering and cross-session aggregation."
- Temporal metadata: Time-related annotations associated with facts or entities that enable time-aware reasoning. "building elaborate graph structures with entity resolution, fact validation, and temporal metadata"
- Temporal normalization: Converting informal or relative time expressions into standardized, comparable temporal representations. "While these systems employ LLM-based temporal normalization, they rely on global extraction strategies that process all conversational content uniformly"
- Tool-calling: The ability of an LLM agent to invoke external tools (e.g., search, grep) during reasoning. "The Chronos Agent is an LLM agent with native tool-calling capabilities for iterative memory retrieval."
- Turn calendar: An index preserving raw conversational turns to retain full semantic context for retrieval. "indexing them in a structured event calendar alongside a turn calendar that preserves full conversational context."
- Vector search: Retrieval using embeddings (vectors) to match semantically similar items via nearest-neighbor search. "Vector search tools (search_turns, search_events) enable semantic retrieval by querying each calendar's index with agent-generated keywords or rephrased queries."
Collections
Sign up for free to add this paper to one or more collections.