Efficient Exploration at Scale
Abstract: We develop an online learning algorithm that dramatically improves the data efficiency of reinforcement learning from human feedback (RLHF). Our algorithm incrementally updates reward and LLMs as choice data is received. The reward model is fit to the choice data, while the LLM is updated by a variation of reinforce, with reinforcement signals provided by the reward model. Several features enable the efficiency gains: a small affirmative nudge added to each reinforcement signal, an epistemic neural network that models reward uncertainty, and information-directed exploration. With Gemma LLMs, our algorithm matches the performance of offline RLHF trained on 200K labels using fewer than 20K labels, representing more than a 10x gain in data efficiency. Extrapolating from our results, we expect our algorithm trained on 1M labels to match offline RLHF trained on 1B labels. This represents a 1,000x gain. To our knowledge, these are the first results to demonstrate that such large improvements are possible.



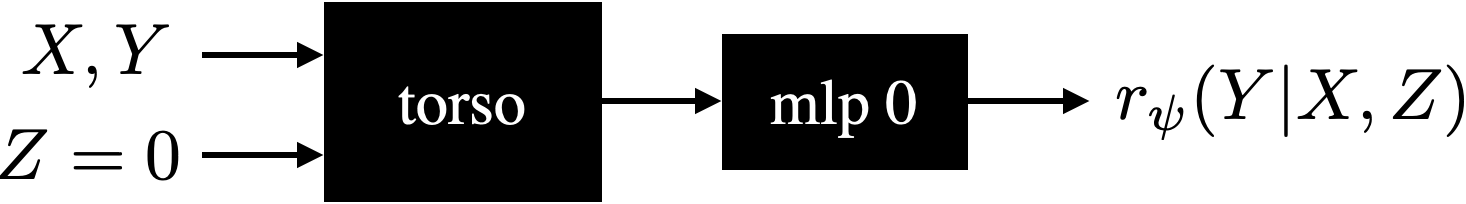

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Efficient Exploration at Scale — A simple explanation
1) What is this paper about?
The paper introduces a new way to teach LLMs using human preferences much more efficiently than before. This teaching method is called “reinforcement learning from human feedback” (RLHF), where people (or a simulator of people) choose which of two AI answers is better, and the AI learns from these choices. The authors show that by learning continuously and asking for feedback in smarter ways, the AI can reach the same quality with far fewer labels (choices), saving lots of time and effort.
2) What questions were the researchers trying to answer?
They focused on a few simple questions:
- Can an AI learn faster if it updates itself while it’s collecting feedback, instead of waiting until the end?
- Can we choose which examples to ask people about so that each helps the AI learn as much as possible?
- Can we make learning more stable so the AI doesn’t “tank” (suddenly get worse) mid-training?
- How does performance improve as we collect more feedback (the “scaling law” for RLHF)?
3) How did they do it?
Think of training the AI like coaching a student:
- The “student” is the LLM (LM), which writes answers.
- The “judge” is a reward model (RM), which estimates which answer a human would prefer.
- A “coach” decides which questions and answer pairs to show the judge, and how to update the student.
Here’s the core approach, in everyday language:
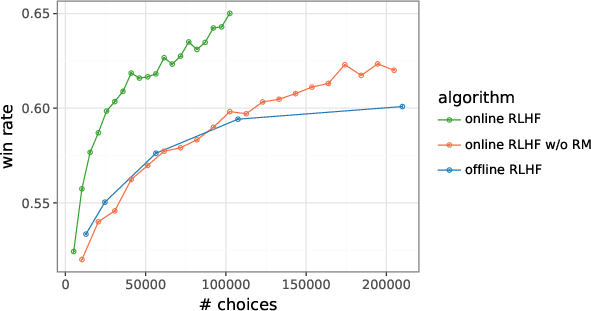
- Learning while going (online RLHF): Instead of collecting a big pile of feedback first and training later (offline), the AI asks for feedback in small batches and updates both the judge (RM) and the student (LM) right away. This keeps the practice focused on current weaknesses.
- Smarter questions (information-directed exploration): The AI first drafts many possible answers to a prompt, then asks for feedback on the two that would be most informative. How does it know which pair is most informative? It uses an uncertainty-aware judge called an epistemic neural network (ENN), which estimates not just which answer is better but also how unsure it is. The pair with the highest uncertainty is most likely to teach the AI something new—like asking a teacher about the topics you’re most confused about.
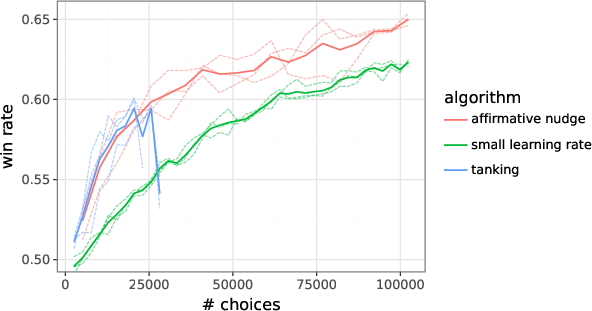
- A tiny encouragement each step (the “affirmative nudge”): During training, the model gets signals that say “move toward answers the judge prefers.” The authors add a very small positive bonus to every such signal—like a gentle “keep going!”—to prevent the model from getting stuck or suddenly collapsing in quality. This keeps learning stable and strong.
- Practical setup:
- They start with a Gemma 9B model (the student).
- They simulate human feedback using a large, reliable judge (a Gemini-based reward model trained on real human choices).
- For each prompt, the model generates multiple answers, selects pairs likely to be informative, gets a choice from the judge, and updates both the judge and the student.
- They compare several training styles:
- Offline RLHF: collect all data first, then train.
- Periodic RLHF: collect some data, train; repeat.
- Online RLHF: update after every small batch.
- Online with information-directed exploration (their best method): like online RLHF, but with the uncertainty-aware judge to pick the most educational pairs.
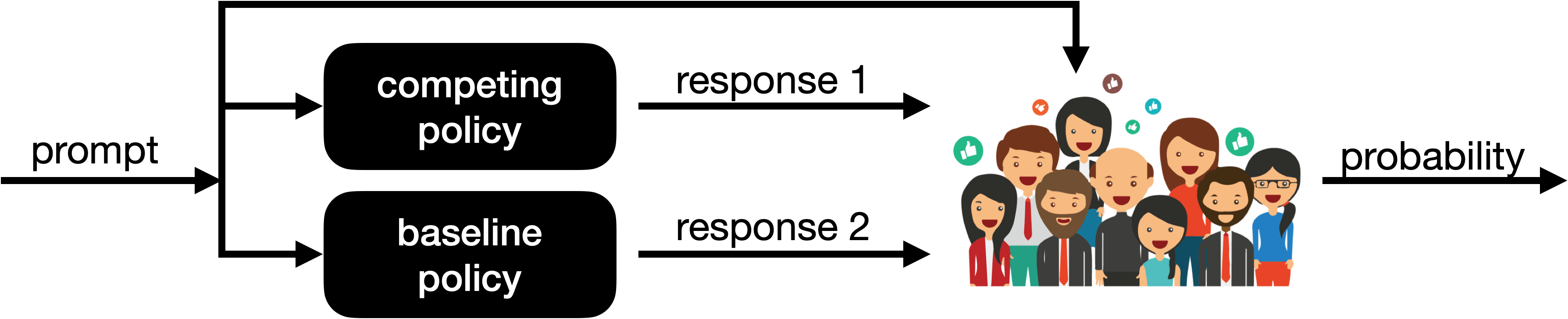
- How they measured progress: For 1,000 new prompts, they compared the new model’s answers to a baseline model’s answers. A “win rate” of 0.7, for example, means the new model’s answer is preferred 70% of the time.
4) What did they find, and why is it important?
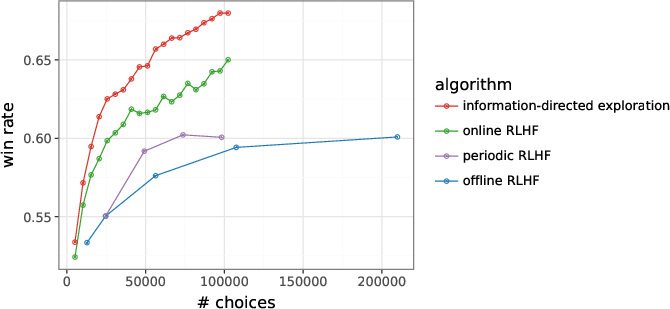
- Much less data for the same quality: Their online, uncertainty-guided method reached the same win rate that traditional offline RLHF only gets with 10 times more human labels. For example, they matched the performance of a model trained with 200,000 labels using fewer than 20,000 labels.
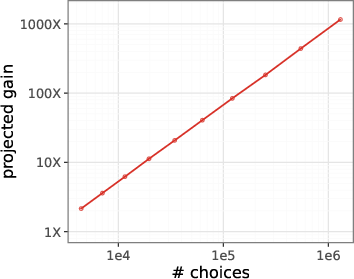
- Bigger gains at larger scales (projected): Based on their results, they predict that 1 million labels with their method could match what offline RLHF would need about 1 billion labels to achieve—a 1,000× improvement in data efficiency.
- Stability matters: A small “affirmative nudge” (tiny positive bonus added to learning signals) prevented the model from collapsing mid-training and let it keep improving—without lowering the learning rate.
- Reward models help: Training the student directly without a learned judge was worse. The separate reward model (judge) improved feedback quality and guided learning better.
- Smarter questions = faster learning: Choosing answer pairs that the judge was most uncertain about led to more educational feedback. The paper shows examples where the “most informative” pairs differ in meaning, forcing the judge’s preference to reveal something new, while “least informative” pairs are nearly identical and teach very little.
Why this matters: Human feedback is expensive. If we can learn with 10–1,000× fewer labels, we can train safer, more helpful AI systems faster and at lower cost.
5) What could this change in the future?
- Cheaper, faster AI alignment: Getting high-quality behavior from AI can rely less on massive amounts of human labeling—great for organizations without giant data budgets.
- Safer systems sooner: Asking for the most informative feedback helps models quickly learn human preferences and avoid harmful or low-quality answers.
- Broader applications: The same ideas—online updates, uncertainty-aware judges, and informative queries—could help in multi-turn conversations, tool-using agents, or tasks where actions have delayed effects.
- Better research directions: The authors suggest improving uncertainty modeling further, selecting not only responses but also which prompts to ask about, and using AI-assisted feedback that helps humans give clearer, more informative guidance.
In short, the paper shows that by learning continuously, asking the right questions, and keeping training stable with a small positive push, we can teach AI much more efficiently—getting better results with far less human feedback.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research:
- External validity: All preference data and evaluation rely on an AI “human feedback simulator” (Gemini-based RM). How do the reported gains transfer to real human raters with heterogeneous preferences and noise profiles?
- Circularity and judge alignment: The same simulator provides both training labels and evaluation (win rate). How robust are results when evaluated with independent human judges or standardized human-eval benchmarks (e.g., MT-Bench, Arena), and when trained on one judge but evaluated on another?
- Projection risk: The 1,000× data-efficiency claim is an extrapolation from limited data using a hand-picked functional form; no confidence intervals or robustness checks are provided. How sensitive are projections to functional assumptions and additional data?
- Compute vs. label efficiency: The method samples 16 candidates per prompt and runs an ENN with 200 auxiliary MLPs; compute costs, latency, and wall-clock comparisons to baselines are not reported. What are compute-adjusted efficiency gains and engineering trade-offs?
- Baseline breadth and strength: Comparisons omit several strong or widely used baselines (e.g., DPO/IPO/ORPO variants, PPO-based RLHF with best practices, RLAIF, APO/XPO with active prompt selection). How do results change against stronger, tuned baselines?
- Reward-model-free methods: The paper states such approaches “were not competitive” but provides minimal detail. Which methods, tuning, and design choices were tried, and are there configurations that perform competitively online?
- Affirmative nudge (ε) theory: The additive positive shift prevents “tanking,” but lacks theoretical justification. What are its convergence properties, bias effects, and interaction with policy gradient baselines, and can adaptive or principled alternatives be devised?
- Hyperparameter sensitivity: No ablations on ε, KL/anchor strength (β, η), batch sizes, top-K, number of candidates (16), or number of ensemble particles (100). Which components drive gains and how sensitive are results?
- Uncertainty calibration: The ENN’s variance of preference probabilities is used for exploration, but no calibration metrics (e.g., Brier score, ECE) or error–uncertainty correlation are reported. Does predicted variance reliably track informativeness and error?
- IDS formalization: The “information-directed” criterion is operationalized as variance maximization, not a principled information gain or regret–information ratio. How does true mutual information or established IDS formulations compare?
- ENN design choices: The prior networks are fixed, the backbone is frozen for differential networks, and head sizes are set ad hoc. What is the impact of each design (e.g., number/size of particles, learning the prior, sharing vs. freezing backbone)?
- Reward model architecture: Rewards are derived from a last-layer embedding with a head; aggregation across tokens and length normalization are not described. How do per-token (sequence-level) reward modeling and length control affect performance and stability?
- Pseudo-label reliance: Policy updates use multiple unlabeled response pairs per prompt scored by the (imperfect) RM, potentially amplifying RM bias. What is the trade-off between labeled vs. pseudo-labeled updates, and how does RM mis-specification affect policy?
- Noise robustness: The simulator’s noise process follows a Bradley–Terry model. How do gains change under higher/noisy/biased human feedback regimes, or with adversarial label noise and rater disagreement?
- Safety and exploration: Uncertainty-guided exploration may sample unsafe, biased, or low-quality responses. How to integrate safety-aware exploration, guardrails, and rater protection while retaining sample efficiency?
- Generalization scope: Experiments use a single 9B Gemma and an internal prompt set. How do results scale across model sizes (smaller/larger LMs), model families, multilingual settings, and out-of-domain prompts?
- Evaluation modality: Performance is measured via top-1 deterministic decoding; common LLM use involves stochastic decoding (temperature, nucleus). Do gains persist under practical decoding strategies and across task-specific metrics (helpfulness, toxicity, hallucination)?
- Prompt acquisition: Exploration is applied to response selection only; active selection of prompts is not tested. Does adding prompt-level exploration further improve efficiency in realistic data pipelines?
- Catastrophic forgetting and stability: The EMA anchor is proposed to stabilize training, but its dynamics and optimal schedules are not studied. How do anchor choices influence forgetting, plasticity, and long-horizon stability?
- Periodic RLHF settings: Only one period (τ = 400) is examined; compute-adjusted fairness vs. online updates is unclear. What are the performance–compute frontiers across τ and training schedules?
- Candidate generation: Only top-5 sampling is used for exploration; no ablations on temperature, nucleus sampling, or diverse decoding strategies. How do candidate-generation choices affect exploration quality and label efficiency?
- Category-wise gains: No breakdown by task/domain (coding, math, reasoning, safety-critical tasks). Are gains uniform or concentrated in specific categories, and where does the method underperform?
- Robustness across seeds and runs: Plots lack error bars and multiple seeds. What is the run-to-run variance and statistical significance of observed improvements?
- Reward hacking risk: Training optimizes toward a learned RM (and simulator preferences). Does policy quality improve on human-centric qualitative metrics or does it overfit simulator idiosyncrasies?
- Multi-turn and delayed credit: The method is single-turn; value models for multi-turn dialogue or agentic settings are suggested as future work. What adaptations are required for multi-step credit assignment and long-horizon exploration?
- Reproducibility and transparency: Many implementation details (tokenization, sequence lengths, gradient clipping specifics, hyperparameters) are omitted, and code/data are not released. Can the community independently validate the reported gains?
Practical Applications
Immediate Applications
The following applications can be deployed now by adapting the paper’s methods (online RLHF with uncertainty-guided exploration, ENN-based reward modeling, and the affirmative nudge) into existing RLHF pipelines and evaluation workflows.
- Application: Replace offline RLHF with online, uncertainty-guided RLHF to cut preference data requirements by ≥10x
- Sectors: software/AI labs, consumer assistants, enterprise productivity, coding assistants
- Tools/Workflows:
- Online RLHF loop: for each prompt, generate 16 responses via top-K sampling (e.g., top-5), select high-variance response pairs for labeling, update RM and LM incrementally with AdamW
- ENN reward model head: ensemble (prior + differential MLPs) with epistemic index Z to estimate uncertainty and compute choice-probability variance
- Information-directed exploration: query raters with the response pair that maximizes variance of predicted preference probability across ensemble particles
- Policy optimization: REINFORCE-style update with EMA “anchor” and KL regularization; add a small affirmative nudge ε to avoid tanking
- Assumptions/Dependencies:
- Gains demonstrated with a Gemini-based simulator and a Gemma-9B LM; real-human validation is still needed
- Extra inference cost to sample multiple responses per prompt; net cost-benefit depends on labeling vs compute budgets
- Application: Faster product alignment sprints for specific domains (e.g., safety, coding, customer support)
- Sectors: trust & safety, developer tools, customer service
- Tools/Workflows:
- Active pair selection in rater UIs to present diverse, high-information comparisons
- Domain-tuned ENN heads initialized on general data, then adapted with a small number of domain-specific labels
- Continuous win-rate tracking vs a baseline policy for regression detection
- Assumptions/Dependencies:
- Labeler guidance and rubrics strongly influence RM quality; domain-specific instructions must be clear
- Batch sizes, ε (affirmative nudge), and KL regularization require tuning to prevent over-optimization or drift
- Application: Reduce data-center energy and annotation costs by improving data efficiency
- Sectors: energy/sustainability, operations
- Tools/Workflows:
- Centralized “active feedback scheduler” to allocate labeling budget to the highest-value prompts across teams
- Audit of energy per useful win-rate gain to quantify sustainability ROI
- Assumptions/Dependencies:
- Compute overhead from extra sampling and ENN inference may offset some energy savings; measure end-to-end energy vs offline baselines
- Application: Safety and policy alignment via uncertainty-guided discovery of ambiguous/edge cases
- Sectors: trust & safety, policy
- Tools/Workflows:
- Use ENN uncertainty to mine contentious or uncertain prompts/responses for red-teaming and policy refinement
- IDS-driven curation to focus raters on borderline or high-disagreement items
- Assumptions/Dependencies:
- Uncertainty quality depends on ENN calibration; requires monitoring and periodic recalibration
- Safety review needed for sensitive content; human-in-the-loop remains essential
- Application: Academic benchmarking and teaching labs for RLHF scaling laws
- Sectors: academia
- Tools/Workflows:
- Course and lab materials implementing: (i) REINFORCE with anchor regularization, (ii) affirmative nudge ε, (iii) ENN-based uncertainty, (iv) win-rate evaluation via Bradley–Terry mapping
- Small-scale replications on open LMs to study scaling curves on a log axis
- Assumptions/Dependencies:
- Access to open backbones and modest compute; substitute real raters for simulators when feasible
- Application: Annotation marketplace optimization
- Sectors: data labeling platforms
- Tools/Workflows:
- Integrate information-directed query selection into job routing to maximize information per label
- UX for raters to compare pairs efficiently and avoid near-duplicate “infomin” comparisons
- Assumptions/Dependencies:
- Worker ergonomics and fairness considerations; prevent overexposure to challenging content
- Platform must support dynamic task selection APIs
- Application: Privacy-aware enterprise personalization with minimal feedback
- Sectors: enterprise software, productivity, knowledge management
- Tools/Workflows:
- On-policy collection of small amounts of org-specific preferences; frequent incremental updates instead of large offline runs
- Strict anchoring to a vetted baseline to reduce drift and maintain compliance
- Assumptions/Dependencies:
- Data governance approvals for feedback collection; careful evaluation to avoid amplifying biases in small datasets
- Application: Standardized A/B evaluation workflow for post-training
- Sectors: AI evaluation, MLOps
- Tools/Workflows:
- Win-rate evaluation against a fixed baseline using probability-of-preference estimates
- Checkpointing and early-stop rules guided by win-rate curves to prevent “tanking”
- Assumptions/Dependencies:
- Agreement between simulator-based win-rate and human win-rate must be validated for the target domain
Long-Term Applications
These applications require further research, engineering scale-up, validation with real human raters, or integration into more complex agentic systems.
- Application: Scaling to 1M labels for ~1000x projected data-efficiency gains
- Sectors: AI labs, foundation model providers
- Tools/Workflows:
- Industrialized online RLHF infrastructure with robust scheduling, data lifecycle management, and continuous evaluation
- Elastic compute to support heavy on-policy sampling and frequent updates
- Assumptions/Dependencies:
- Projection is based on extrapolated scaling curves; real-world returns may saturate sooner or differ by domain
- Application: Multi-turn dialogue alignment with value models
- Sectors: customer support, education, healthcare triage
- Tools/Workflows:
- Extend ENN to model uncertainty over sequence-level returns; incorporate value models that predict anticipated rewards over turns
- Collect preferences over conversation trajectories, not just single responses
- Assumptions/Dependencies:
- More complex credit assignment; requires additional feedback schemas and rater training
- Application: Agent alignment with delayed consequences
- Sectors: robotics, autonomous agents, AI operations (DevOps, data pipelines)
- Tools/Workflows:
- Combine information-directed exploration with reward/value models that handle temporal delay and long-horizon outcomes
- Preference queries over plans or tool-use traces, not only text responses
- Assumptions/Dependencies:
- Safety, environment simulators, and human oversight for high-stakes actions
- Application: AI-assisted feedback to increase label informativeness
- Sectors: data labeling, education, policy analysis
- Tools/Workflows:
- Debate or rationale verification UIs where models propose reasons and raters validate or correct them
- Use ENN uncertainty to trigger when to show rationales or request additional scrutiny
- Assumptions/Dependencies:
- Risk of anchoring or biasing raters with model rationales; requires careful UX and protocol design
- Application: Uncertainty modeling beyond the reward model (uncertainty-aware policy updates)
- Sectors: safety-critical applications (healthcare, law), compliance
- Tools/Workflows:
- Represent and propagate uncertainty in the LM itself (e.g., Bayesian or ensemble heads), not only in the RM
- Uncertainty-aware regularization and exploration bonuses during policy optimization
- Assumptions/Dependencies:
- Additional compute and engineering complexity; calibration challenges
- Application: Active prompt selection for data acquisition
- Sectors: data strategy, research
- Tools/Workflows:
- Extend IDS to choose which prompts (not just response pairs) to label for maximal global information gain
- Maintain diversity and coverage constraints to avoid overfitting to narrow regions
- Assumptions/Dependencies:
- Requires new objective design and safeguards against prompt distribution shift
- Application: Multimodal alignment with ENN-based uncertainty
- Sectors: healthcare imaging, robotics (vision + language), media
- Tools/Workflows:
- ENN heads over multimodal backbones; active selection of video/image-text pairs with maximal preference uncertainty
- Preference schemas that combine visual and textual reasoning
- Assumptions/Dependencies:
- Data availability and careful safety evaluation in high-stakes domains
- Application: Privacy-preserving RLHF with fewer labels
- Sectors: healthcare, finance, legal
- Tools/Workflows:
- Combine online data-efficiency with differential privacy or federated updates
- Preference learning from limited on-prem feedback; release only aggregated updates
- Assumptions/Dependencies:
- Privacy accounting and utility trade-offs; potential degradation from DP noise
- Application: Standards and policy for efficient alignment practices
- Sectors: government, standards bodies, procurement
- Tools/Workflows:
- Benchmarks and reporting for data-efficiency (win-rate per label), energy per unit gain, and uncertainty calibration metrics
- Procurement guidelines encouraging uncertainty-aware data collection and on-policy learning
- Assumptions/Dependencies:
- Multi-stakeholder consensus; independent audits and reproducibility requirements
- Application: Education technology with adaptive questioning
- Sectors: education
- Tools/Workflows:
- Use uncertainty-guided selection to ask the most informative follow-up questions and adapt tutoring flows
- Incremental preference learning from minimal student feedback to personalize explanations and pacing
- Assumptions/Dependencies:
- Strong safeguards for pedagogy, fairness, and measurement of learning outcomes
- Application: Edge and on-device alignment for personal assistants
- Sectors: mobile, IoT
- Tools/Workflows:
- Lightweight ENN heads and periodic online updates to personalize behavior from small amounts of user feedback
- Strict anchoring to prevent drift and maintain safety on constrained devices
- Assumptions/Dependencies:
- Resource constraints; careful budgeting of sampling and update frequency to preserve latency and battery
Across all applications, common dependencies include: validation with real human raters (beyond simulators), careful hyperparameter tuning (especially the affirmative nudge ε and KL regularization), monitoring for “tanking” and drift, uncertainty calibration checks, and robust governance for safety, privacy, and fairness.
Glossary
- active contextual dueling bandit: A bandit formulation where, given context, the learner compares pairs of actions (duels) to learn preferences efficiently. Example: "formalize this problem as an active contextual dueling bandit."
- active preference optimization (APO): An active learning approach that selects informative preference queries to optimize preference-based objectives. Example: "Techniques like active preference optimization (APO) and its variants, apply active learning principles directly to preference-based objectives (like DPO), iteratively collecting choice data that resolve uncertainty"
- AdamW: An optimizer that decouples weight decay from the gradient-based update, often improving generalization. Example: "using AdamW"
- affirmative nudge: A small positive offset added to the reinforcement signal to prevent training collapse (“tanking”) in online RLHF. Example: "a small affirmative nudge added to each reinforcement signal"
- anchor: An exponential moving average of parameters used as a reference point for regularizing policy updates. Example: "We refer to as an anchor."
- Bradley–Terry model: A probabilistic model for pairwise comparisons that converts scores into choice probabilities. Example: "via the Bradley-Terry model \citep{Bradley1952Rank} with an exponential score function."
- direct preference optimization (DPO): A method that directly optimizes a model using preference data without an explicit reward model. Example: "Iterative versions of direct preference optimization (DPO)"
- differential networks: Trainable ensemble members in an ENN that, combined with fixed priors, represent epistemic uncertainty. Example: "and 100 differential networks, each with two hidden layers of width 1024."
- epistemic index: A discrete selector for different ensemble members/particles in an epistemic neural network to probe uncertainty. Example: "We refer to as an {\it epistemic index}."
- epistemic neural network (ENN): A neural architecture that explicitly represents epistemic uncertainty by conditioning on an index over ensemble members. Example: "Our architecture serves as an epistemic neural network (ENN), as studied in \citep{osband2023epistemic}."
- ensemble particles: Individual members of an ensemble used to compute uncertainty statistics, such as variance of predicted choice probabilities. Example: "over ensemble particles ."
- exponential moving average: A running average that exponentially discounts older parameter values, often used for stability. Example: "maintaining an exponential moving average of parameters"
- exponential score function: A scoring transformation where exponentiated rewards are used to derive choice probabilities in pairwise models. Example: "with an exponential score function."
- information-directed exploration: An exploration strategy that selects queries expected to yield high information about preferences or rewards. Example: "Information-directed exploration, in particular, demonstrates large improvement."
- information-directed sampling (IDS): A principled exploration method that balances expected information gain against regret. Example: "those based on information-directed sampling (IDS) incorporate exploration bonuses"
- information gain: The expected reduction in uncertainty from observing a label or choice; used to pick informative comparisons. Example: "selecting responses to maximize a measure of information gain."
- last-layer embedding: The final hidden representation from the transformer backbone used as input to lightweight heads (e.g., reward heads). Example: "the {\it last-layer embedding}"
- multilayer perceptron (MLP): A feedforward neural network with one or more hidden layers used here as heads on top of a transformer backbone. Example: "an ensemble of multilayer perceptron (MLP) heads"
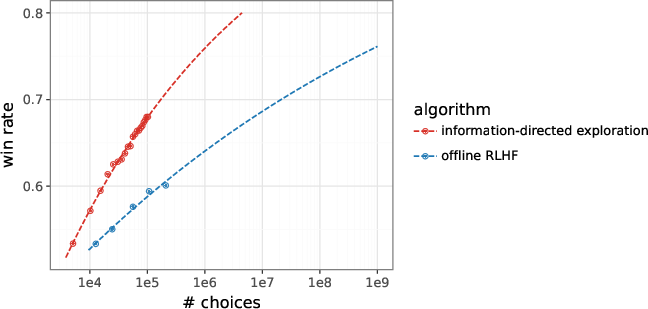
- offline RLHF: RLHF where the model is optimized using a fixed dataset of human preferences collected beforehand. Example: "Offline RLHF needs more than 200K choices to match that performance at 20K choices."
- on-policy: A data collection strategy where samples are drawn from the current policy, aligning training data with the model’s behavior. Example: "online algorithms sample responses on-policy"
- online RLHF: RLHF where the reward and policy are updated incrementally as new preference data arrives. Example: "Our online RLHF algorithm interleaves between updates of reward model and policy parameters."
- periodic RLHF: A semi-online RLHF scheme that periodically refreshes the policy and reward model using chunks of newly collected data. Example: "Periodic RLHF operates much in the same way as offline RLHF."
- point estimate head: The deterministic (mean) reward head in an ENN used for standard inference when the epistemic index selects it. Example: "We call this point estimate head ."
- policy gradient: A gradient-based method that updates policy parameters in the direction that increases expected reward. Example: "our update rule computes a policy gradient"
- prior networks: Fixed, randomly initialized networks in an ensemble that act as priors to induce epistemic diversity. Example: "including 100 prior networks, each with two hidden layers of width 256"
- randomized prior functions: A technique where randomly initialized, fixed-function priors are combined with learned components to capture uncertainty. Example: "form an ensemble with randomized prior functions"
- REINFORCE: A classic Monte Carlo policy-gradient algorithm that uses sampled returns to update policy parameters. Example: "as a variant of reinforce \citep{sutton2018reinforcement}"
- reward model (RM): A learned function that maps (prompt, response) pairs to scalar rewards, used to provide learning signals. Example: "The reward model (RM) is fit to the choice data"
- reward uncertainty: The model’s epistemic uncertainty about reward predictions, used to drive informative exploration. Example: "an epistemic neural network that models reward uncertainty"
- scaling laws: Empirical relationships describing how performance improves as a function of model/data scale. Example: "scaling laws have been studied extensively"
- supervised fine-tuning (SFT): Post-pretraining training on supervised data to align models before RLHF. Example: "supervised fine-tuning (SFT) of the Gemma model"
- top-K policy: A sampling policy that restricts next-token choices to the K most probable tokens before sampling from them. Example: "we refer to as top- policies."
- unembedding matrix: The final linear layer that maps hidden states to vocabulary logits; removing it yields a backbone for other heads. Example: "with the unembedding matrix and softmax removed."
- value model: A model predicting future or cumulative rewards (e.g., anticipated human preferences) in multi-turn settings. Example: "involves learning not only a reward model but also a value model that predicts anticipated rewards."
- win rate: The average probability that a model’s response is preferred over a baseline across evaluation prompts. Example: "in terms of the win rate over a baseline policy"
Collections
Sign up for free to add this paper to one or more collections.