Argument Reconstruction as Supervision for Critical Thinking in LLMs
Abstract: To think critically about arguments, human learners are trained to identify, reconstruct, and evaluate arguments. Argument reconstruction is especially important because it makes an argument's underlying inferences explicit. However, it remains unclear whether LLMs can similarly enhance their critical thinking ability by learning to reconstruct arguments. To address this question, we introduce a holistic framework with three contributions. We (1) propose an engine that automatically reconstructs arbitrary arguments (GAAR), (2) synthesize a new high-quality argument reconstruction dataset (Arguinas) using the GAAR engine, and (3) investigate whether learning argument reconstruction benefits downstream critical thinking tasks. Our experimental results show that, across seven critical thinking tasks, models trained to learn argument reconstruction outperform models that do not, with the largest performance gains observed when training on the proposed Arguinas dataset. The source code and dataset will be publicly available.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI LLMs to “think critically” about arguments the way people are trained to do in logic or debate class. The authors focus on a key skill called argument reconstruction: taking a messy, real-world argument and clearly laying out its premises (reasons) and conclusion, including any hidden assumptions. They build an automatic system to do this, create a new dataset from it, and show that training AI on this skill makes the AI better at other critical-thinking tasks.
What questions were they trying to answer?
- Can an AI learn to think more clearly by learning to reconstruct arguments, not just judge them?
- Can we automatically reconstruct many kinds of arguments (short or long, from any topic, with or without mistakes in reasoning)?
- If we train AI on argument reconstruction, will it do better on related tasks like judging the quality of arguments, understanding legal reasoning, and solving logic questions?
How did they do it?
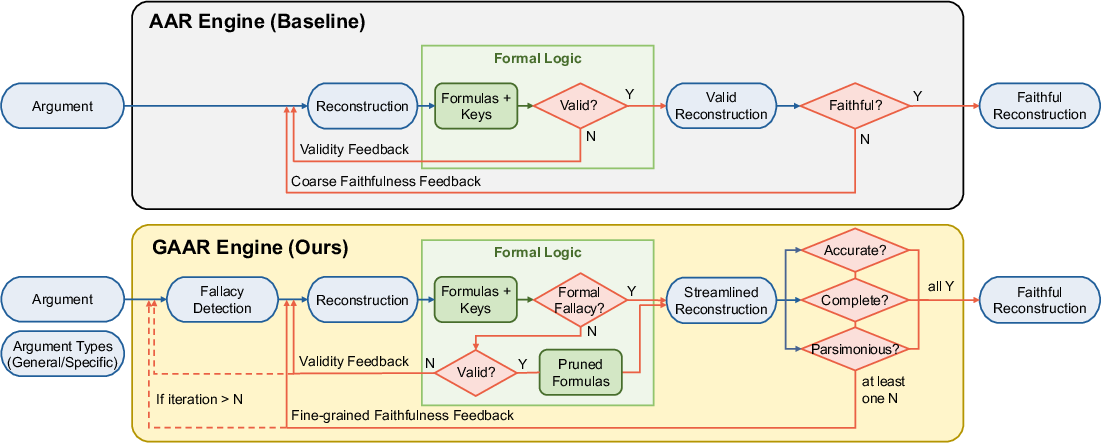
They built a system called GAAR (Generalized Automatic Argument Reconstruction). Think of GAAR as a careful editor who turns a fuzzy argument into a clean “if-this-then-that” structure.
Here’s the idea in everyday terms:
- Arguments often have premises (reasons) and a conclusion (what the reasons are trying to prove). People also make different types of arguments: deduction (guaranteed conclusion), induction (likely conclusion), abduction (best explanation), and analogy (comparing two things).
- Arguments sometimes contain fallacies—mistakes in reasoning—like “hasty generalization” (judging all dogs by one bad experience) or “false equivalence” (treating two different things as the same).
GAAR works in a few steps:
- It first checks whether the argument contains fallacies and what type they are. This matters because a fallacious argument shouldn’t be forced into a “perfectly valid” shape.
- It reconstructs the argument in clear, structured language, including hidden premises (unstated reasons that are needed for the conclusion).
- It temporarily translates the argument into a math-like logic language (first-order logic) so a logic checker (a SAT solver) can verify if the reasoning structure is valid.
- It trims any extra, unused premises—like pruning branches that don’t help support the conclusion.
- It translates the streamlined logic back into plain language.
- It checks the reconstruction with three simple standards of faithfulness: 1) Accuracy: Are the premises and conclusion expressed correctly, without changing their meaning? 2) Completeness: Did we include the necessary reasons? 3) Parsimony: Did we avoid unnecessary fluff?
To build training data, the authors used GAAR to reconstruct 2,850 arguments collected from many places: debate handbooks, a news debate column, online argument datasets, and AI-generated arguments (including some with fallacies). They call this dataset Arguinas.
What did they find, and why does it matter?
The main results can be summed up in a few points:
- GAAR reconstructs arguments more faithfully than earlier systems and simple prompting of big AI models. It also keeps the logic structure valid more reliably.
- The fine-grained checks (accuracy, completeness, parsimony) catch common mistakes, like overgeneralizing a premise or leaving out a key hidden assumption.
- Handling different argument types and fallacies makes reconstructions more true to the original argument.
- Training models on the Arguinas dataset improves performance on seven downstream tasks, including:
- Judging argument quality
- Understanding argument reasoning (like spotting whether a conclusion is truly new or what hidden “warrant” connects a claim to a reason)
- Legal reasoning questions
- Logical reasoning questions (like those on standardized tests)
- This training is especially helpful when there isn’t much data for the target task. In other words, it’s data-efficient: learning to reconstruct arguments gives the model a general skill it can reuse elsewhere.
Why it matters: If we want AI to be a good helper in places like education, journalism, law, or policy, it needs to analyze reasoning clearly, not just give a quick opinion. Teaching it to reconstruct arguments is like teaching it to show its work.
What’s the potential impact?
- Better AI critics and tutors: AI could help students, writers, and debaters by laying out arguments clearly, identifying missing assumptions, and pointing out weak reasoning.
- More trustworthy judgments: Before rating persuasiveness or correctness, the AI can expose the skeleton of the reasoning—making its judgments more transparent and reliable.
- Stronger general reasoning: Training on reconstruction seems to “pre-adapt” models to think more carefully, which carries over to legal and logical tasks.
- Handling real-world messiness: Because GAAR supports different argument types and detects fallacies, it’s more suited to everyday arguments, not just clean textbook examples.
In short, the paper shows that teaching AI to rebuild arguments step by step—like a good debate coach—makes it better at thinking critically across many tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable future research:
- Reliability of LLM-based evaluation: The validity and faithfulness assessments rely heavily on a single LLM (Claude Sonnet 4.5) for NL→FOL translation and pairwise faithfulness judgment, with limited human verification (99.0% for NL→FOL and 89.5% for faithfulness on an unspecified sample); larger-scale, multi-annotator human studies are needed to quantify accuracy, variance, and failure modes across topics and argument types.
- Expressiveness and correctness of the FOL formalization: It is unclear how the engine represents inductive, abductive, analogical, and defeasible reasoning in FOL and where FOL’s expressiveness (e.g., analogical similarity, defaults, exception handling) breaks down; formal characterization and alternative formalisms (e.g., probabilistic or non-monotonic logics, abstract/structured argumentation frameworks) are not explored.
- Decidability and solver assumptions: The paper does not specify how first-order validity is decided (SAT solvers are propositional and FOL validity is undecidable in general); details on quantifier handling, skolemization, grounding, and solver pipelines—and their error profiles—are missing.
- Robustness of premise pruning: The SAT-based pruning removes premises not used in the proof but ignores alternative proof paths, defeasible supports, or rhetorical dependencies; the impact of pruning on argument fidelity and downstream tasks is not quantified.
- Fallacy detection reliability and coverage: The fallacy stage appears LLM-based with no rigorous evaluation against a human-labeled benchmark; detection accuracy, confusion across fallacy types, cross-domain robustness, and coverage beyond the listed schemes remain unmeasured.
- Ambiguity in fallacy-heavy arguments: How GAAR handles borderline or disputed fallacies (where human experts disagree) is not addressed; adjudication protocols and uncertainty-aware outputs are absent.
- Generalization beyond English and selected sources: The framework is tested on English-only sources; applicability to other languages, cultural rhetorical norms, and legal/philosophical traditions is untested.
- Argument identification is out of scope: The system assumes well-bounded argument inputs; integrating an upstream argument identification/segmentation step for long, noisy, or multi-party discourse is left unexplored.
- Handling of long, multi-turn, or dialogical arguments: GAAR’s scalability to debates, dialogues with rebuttals/undercutters, or documents with multiple intertwined argumentative threads is not evaluated.
- Treatment of multiple conclusions and sub-arguments: The paper does not clarify how GAAR manages arguments with several conclusions, nested sub-arguments, or convergent/linked structures typical in argument maps.
- Implicit premise hallucination control: The engine encourages adding implicit premises but lacks safeguards against over-inference or bias; calibration strategies and human-in-the-loop mechanisms to constrain unwarranted implicit content are not studied.
- Fine-grained faithfulness criteria reliability: Accuracy, completeness, and parsimony are judged by an LLM without reported inter-rater reliability, thresholding, or sensitivity analyses; potential gaming or circularity is not addressed.
- Dataset provenance and bias: Arguinas includes a large portion of LLM-generated arguments (including fallacious ones) and selected English sources; the impact of author-type, topic, and style distributions on learned behavior and biases is not analyzed.
- Human vetting of Arguinas: There is no systematic human audit of the dataset’s reconstructions for fidelity, bias, or safety; the reported human checks target evaluation components, not the dataset content at scale.
- Dataset licensing and release details: Use of proprietary sources (e.g., NYT) raises questions about redistribution rights and the eventual public availability of the full dataset vs. subsets.
- Reproducibility of GAAR outputs: GAAR depends on a closed-source model (Claude Sonnet 4.5) with non-deterministic behavior; reproducibility across runs, seeds, and alternative open models is only partially examined (appendix) and lacks quantitative stability analyses.
- Cost and scalability analysis: Iterative loops with multiple LLM calls and solver invocations may be expensive; the paper lacks cost/time metrics, iteration counts, and scaling curves needed to assess feasibility for large-scale deployment.
- Sensitivity to hyperparameters: Key control parameters (e.g., number of iterations N, fallacy revision thresholds) are not specified or tuned systematically; their effect on reconstruction quality and compute costs is unknown.
- Formal fallacy handling bypasses validity check: Skipping the validity stage for formal fallacies may mask errors in FOL translation or streamline steps; empirical validation that this path preserves faithfulness is absent.
- Evaluation task coverage: Downstream gains are shown on selected benchmarks; effects on debate moderation, misinformation detection, causal argumentation, and real-world educational assessments remain untested.
- Attribution of gains to reconstruction vs. generic structuring: The paper compares to “ArgumentOnly,” AAAC, and EntailmentBank, but does not include controls that train on other structured reasoning signals (e.g., step-by-step plans, logic puzzles) to isolate whether gains are specific to argument reconstruction.
- Data efficiency boundaries: While some data-efficiency findings are reported, the minimal Arguinas size needed for consistent gains and the scaling laws relating reconstruction data volume to downstream performance are not established.
- Interactions with persuasion/rhetoric: Parsimony and pruning may remove rhetorical elements essential in persuasion tasks (e.g., WebisCMV20); how to preserve rhetorically salient yet logically unnecessary content is an open design question.
- Safety and ethics: The framework reconstructs arguments on sensitive topics but lacks discussion of potential harms (e.g., sanitizing or strengthening harmful reasoning), mitigation strategies, or safety auditing protocols.
- Beyond 60 schemes and mixed types: Real arguments often instantiate multiple or hybrid schemes; GAAR’s capacity to detect and reconstruct mixed or evolving schemes, or schemes beyond the listed 60, is not evaluated.
- Alternative faithfulness metrics: Pairwise LLM-judged “winning rates” provide limited resolution; absolute scoring rubrics, expert annotation protocols, and task-specific agreement measures are needed.
- Longitudinal transfer: The persistence of gains from reconstruction pre-adaptation over continued training, domain shifts, or instruction tuning is only partially tested; catastrophic forgetting and interference are unexamined.
- Multimodal arguments: The approach does not cover arguments supported by figures, data visualizations, or images; extensions to multimodal reconstruction are not discussed.
- Practical integration in pipelines: How GAAR integrates with retrieval, citation grounding, or fact-checking to support premise verification and evaluation is not explored.
- Toolchain robustness: The impact of NL→FOL translation errors on solver outcomes and back-translations (streamlining) is not quantified; end-to-end error propagation analysis is missing.
- Annotator guidelines and pedagogy: If positioned for educational use, alignment of reconstructions with established curricula and the pedagogical effectiveness of GAAR-generated feedback are unverified.
- Legal/domain-specific logic: For legal reasoning, domain-specific canons, precedents, and defeasible rules are not modeled; whether GAAR can incorporate specialized ontologies or logic systems remains open.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s GAAR engine, the Arguinas dataset, and the demonstrated performance gains from argument reconstruction pre-adaptation.
- Legal tech (legal)
- Use case: Fallacy-aware legal argument mapping and brief refinement. Automatically reconstruct arguments in motions/briefs, expose implicit premises, and flag formal/informal fallacies to improve clarity before filing.
- Tools/workflows: “Legal Argument Mapper” plugin for document editors; e-discovery triage that prioritizes documents with weak/invalid chains; deposition prep that surfaces hidden assumptions.
- Assumptions/dependencies: Access to robust LLMs (e.g., Claude Sonnet 4.5–quality), reliable NL→FOL translation and SAT solver integration; human-in-the-loop review for high-stakes decisions; English-centric models.
- Regulatory/compliance audits (finance, healthcare, energy)
- Use case: Justification traceability for audits and risk assessments. Reconstruct and prune premises behind decisions (e.g., model risk, ESG claims, safety rationales), detect overgeneralizations and missing support.
- Tools/workflows: “Compliance Justification Tracker” that exports premise–conclusion structures into audit trails; fallacy detection for marketing claims.
- Assumptions/dependencies: Organization-specific taxonomies; policies modeled as premises; privacy controls for sensitive documents.
- Enterprise decision memos and ADRs (software/IT, product management)
- Use case: Improve Architecture Decision Records (ADRs) and product decision memos by making assumptions explicit and pruning unused premises.
- Tools/workflows: “ADR Analyzer” integrated with RFC/PR templates; automatic premise pruning with SAT-based checks; change-impact analysis via reconstructed premises.
- Assumptions/dependencies: Domain knowledge grounding; noise in FOL translation for technical jargon; access to internal docs.
- Newsroom and fact-checking support (media)
- Use case: Reconstruct columnist/editorial arguments, identify implicit warrants, and flag false equivalences or hasty generalizations for editors.
- Tools/workflows: “Argument Map for Editors” integrated into CMS; persuasion-quality spot checks using accuracy/completeness/parsimony criteria.
- Assumptions/dependencies: Editorial guidelines integration; operates on argumentative structure, not truth of premises; multilingual coverage may be limited.
- Debate education and writing tutoring (education)
- Use case: Personalized feedback on essays/debates that surfaces implicit premises, checks parsimony, and highlights fallacies.
- Tools/workflows: “Critical Thinking Tutor” that produces streamlined reconstructions; assignment auto-feedback using Arguinas-tuned small models.
- Assumptions/dependencies: Curriculum alignment; safeguarding against over-automation; content moderation.
- Customer support escalation reasoning (software, telecom)
- Use case: Make escalation rationales explicit—why an issue is prioritized and what assumptions justify the resolution path—reducing miscommunication.
- Tools/workflows: “Escalation Reasoner” that attaches an argument reconstruction to each ticket; parsimonious rationale templates.
- Assumptions/dependencies: Ticket schema adaptation; scaling cost with volume.
- Online platform moderation and community management (social platforms)
- Use case: Analyze argument quality in user debates; flag posts with formal fallacies or missing support for moderator review or educational prompts.
- Tools/workflows: “Community Argument Coach” for users; mod dashboards with faithfulness criteria indicators.
- Assumptions/dependencies: Policy calibration to avoid partisan bias; high-volume processing costs.
- Scientific peer review and rebuttals (academia)
- Use case: Reconstruct reviewer critiques and author responses to expose mismatched premises, overgeneralizations, or missing warrants.
- Tools/workflows: “Review Argument Analyzer” for conference/journal systems; structured rebuttal generator.
- Assumptions/dependencies: Reviewer/author consent; scientific nuance beyond logical structure.
- Procurement and RFP evaluation (industry, public sector)
- Use case: Compare vendors’ argumentative justifications, making hidden assumptions explicit and checking for weak analogies or unsupported leaps.
- Tools/workflows: “RFP Argument Comparator” generating side-by-side premise maps with pruning and fallacy flags.
- Assumptions/dependencies: Domain-specific scoring rubrics; sensitivity to persuasive rhetoric vs logical support.
- Meeting minutes and decision capture (daily work)
- Use case: Convert meeting discussions into explicit premise–conclusion structures, separating rhetoric from support and recording dissenting premises.
- Tools/workflows: “Decision Rationale Extractor” integrated with meeting transcription tools.
- Assumptions/dependencies: High-quality transcripts; participant consent and privacy.
- Browser extension for news and civic discourse (daily life, policy)
- Use case: One-click “argument map” for articles and op-eds; highlight implicit premises and likely fallacies, with a concise, pruned rationale.
- Tools/workflows: “Argument Explainer” extension with user-controlled depth (e.g., identify analogy vs induction).
- Assumptions/dependencies: Fairness across viewpoints; model cost for on-demand analysis.
- LLM pre-adaptation for downstream reasoning tasks (software/AI)
- Use case: Improve small/medium LLMs’ accuracy and data efficiency on legal, logical, and argument-reasoning tasks by finetuning on Arguinas before downstream training.
- Tools/workflows: “Pre-adaptive Finetuning Pipeline” that injects reconstruction ability to reduce downstream data requirements.
- Assumptions/dependencies: Availability of training infrastructure; downstream data distributions similar to evaluated tasks.
Long-Term Applications
These opportunities require further research, scaling, domain adaptation, multilingual capability, or tighter integration with organizational systems.
- Clinical and policy justification support (healthcare, public policy)
- Use case: Make diagnostic/treatment and health policy rationales explicit, checking for missing premises or overgeneralization in evidence-to-recommendation chains.
- Potential tools/products: “Clinical Argument Assistant” integrated with EHRs; “Policy Rationale Auditor” for regulatory impact assessments.
- Dependencies: High-stakes validation; integration with evidence hierarchies; multilingual and domain ontologies.
- Regulatory comment analysis at scale (policy, civic tech)
- Use case: Reconstruct arguments across thousands of public comments, cluster by premises, and surface recurring fallacies or novel warrants.
- Potential tools/products: “Deliberation Analyzer” for agencies/NGOs.
- Dependencies: Robust summarization + argument reconstruction; fairness and transparency; language coverage.
- Contract negotiation and automated redlining with rationale (legal, finance)
- Use case: Not just clause suggestions, but explicit argument chains that justify acceptance or rejection with premise pruning.
- Potential tools/products: “Rationale-backed Redline Assistant.”
- Dependencies: Legal risk models; jurisdiction-specific templates; strict human oversight.
- Safety case engineering and assurance cases (aviation, automotive, robotics)
- Use case: Translate safety cases into validated premise–conclusion structures; detect missing warrants and prune unused evidence.
- Potential tools/products: “Assurance Argument Verifier” aligned with GSN/SACM standards.
- Dependencies: Formal methods integration; certification requirements; multi-modal evidence.
- Multilingual, cross-cultural critical thinking tutors (education)
- Use case: Teach argument reconstruction and fallacy recognition across languages and cultural argumentation styles.
- Potential tools/products: “Global Critical Thinking Coach” aligned with curricula.
- Dependencies: High-quality multilingual datasets; culturally-aware argument schemes.
- News ecosystem integrity and deliberative democracy platforms (media, civic tech)
- Use case: Large-scale mapping of public debates into argument graphs; facilitate cross-viewpoint engagement with explicit warrants.
- Potential tools/products: “Public Argument Graphs” with interactive premise exploration.
- Dependencies: Scalability; governance and neutrality frameworks; real-time processing.
- Evidence-linked argumentation in research and meta-analyses (academia)
- Use case: Connect premises to citations and evidence quality, enabling structured meta-argumentation across studies.
- Potential tools/products: “Evidence-Linked Argument Mapper” for literature reviews and grant panels.
- Dependencies: Citation parsing; evidence hierarchies; domain-specific knowledge graphs.
- Internal decision governance with traceable rationales (enterprises)
- Use case: Organization-wide “rationale ledger” where major decisions store reconstructed arguments with fallacy checks and pruning.
- Potential tools/products: “Decision Governance Hub.”
- Dependencies: Change management; privacy and compliance; integration with existing platforms.
- Agentic systems with argument-aware reasoning (software/AI)
- Use case: LLM agents that surface and verify their own premises during planning and tool use; reject plans with formal fallacies.
- Potential tools/products: “Argument-Verified Agents” for high-stakes automation.
- Dependencies: Robust symbolic-LLM interfaces; reliability improvements beyond current 89.5% judgment agreement.
- Cross-domain, multi-modal argumentation (energy, environment, infrastructure)
- Use case: Combine text with data/figures (e.g., emissions charts) to reconstruct arguments that link quantitative evidence to policy claims.
- Potential tools/products: “Data-Linked Argument Analyzer.”
- Dependencies: Multi-modal reasoning; rigorous grounding to data; provenance tracking.
Notes on feasibility across applications:
- The GAAR pipeline depends on accurate NL↔FOL translation and SAT-based validity checks; while validity reached 100% in tested settings, faithfulness judgments rely on LLMs with measured human agreement of ~89.5%.
- Arguinas (2,850 samples) improves downstream tasks and data efficiency, but broader coverage, multilingual data, and domain-specific grounding are needed for high-stakes deployment.
- Reconstruction ensures structural fidelity, not factual correctness; human verification and evidence grounding remain essential.
- Cost and latency constraints may limit real-time or large-scale deployments without optimization or distilled models.
Glossary
- AAR: An automatic engine designed to reconstruct argumentative AI conference review points into deductively valid premise–conclusion structures. Example: "AAR falls short of faithfully reconstructing domain-general arguments."
- AAC: A benchmark that defines argument reconstruction from symbolic inferences, emphasizing structure identification. Example: "AAC~\cite{cript} and AAAC~\cite{deepa2} define the task as reconstructing an argument synthesized from symbolic inferences, so the primary required skill is identifying an argument structure, making these tasks less applicable."
- AAAC: A related benchmark to AAC focusing on reconstruction from symbolic inferences. Example: "AAC~\cite{cript} and AAAC~\cite{deepa2} define the task as reconstructing an argument synthesized from symbolic inferences, so the primary required skill is identifying an argument structure, making these tasks less applicable."
- abduction: A non-deductive argument type that infers the best explanation from observations. Example: "(1) Deduction, Induction, Abduction, Analogy (general)"
- ablation: An experimental analysis method where components are removed or varied to assess their impact. Example: "We also conduct ablation studies on three dimensions: argument types, faithfulness criteria, and fallacy-handling logic."
- analogy: An argument type drawing conclusions based on relevant similarity between cases. Example: "(1) Deduction, Induction, Abduction, Analogy (general)"
- Arguinas: A high-quality argument reconstruction dataset synthesized using GAAR. Example: "(2) synthesize a new high-quality argument reconstruction dataset (Arguinas) using the GAAR engine"
- ArgRC: Argument Reasoning Comprehension, a task requiring identification of implicit warrants in arguments. Example: "Argument reasoning tasks include Argument Novelty Prediction (ArgsNovel)~\cite{argvalidity} and Argument Reasoning Comprehension (ArgRC)~\cite{argrc}."
- ArgsNovel: Argument Novelty Prediction, a task predicting whether a conclusion is novel with respect to premises. Example: "Argument reasoning tasks include Argument Novelty Prediction (ArgsNovel)~\cite{argvalidity} and Argument Reasoning Comprehension (ArgRC)~\cite{argrc}."
- ARCHE: A dataset defining reconstruction from single sentences in scientific paper introductions. Example: "ARCHE~\cite{arche} defines the task as reconstructing a sentence from the introduction of a scientific paper, but it requires the same skill set as EntailmentBank."
- completeness: A faithfulness criterion assessing whether all necessary premises are included in a reconstruction. Example: "completeness evaluates whether all necessary or core premises required to reconstruct an argument are included"
- continued finetuning: Further finetuning an instruction-tuned model on Arguinas without additional downstream training. Example: "We consider two scenarios: pre-adaptive finetuning and continued finetuning on the proposed Arguinas dataset."
- deductively valid form: A representation where premises logically entail the conclusion. Example: "By definition, deductive arguments can be reconstructed in a deductively valid form (i.e., a set of premises deductively implies a conclusion)."
- downstream critical thinking tasks: Evaluation tasks used after the reconstruction training to assess broader reasoning ability. Example: "investigate whether learning argument reconstruction benefits downstream critical thinking tasks."
- EntailmentBank: A dataset defining reconstruction with a conclusion and a set of sentences, emphasizing explicit premise identification. Example: "EntailmentBank~\cite{entailmentbank} defines the task as reconstructing an argument with a conclusion and a set of sentences."
- faithfulness: The extent to which a reconstruction preserves the original argument’s content and intent without distortion. Example: "a coarse criterion for judging the faithfulness of argument reconstructions"
- fallacy detection: A stage that identifies the presence and type of fallacies before reconstruction. Example: "we introduce a fallacy detection stage prior to the initial reconstruction."
- fallacy-handling logic: Decision procedures that guide reconstruction when fallacies are present. Example: "We also conduct ablation studies on three dimensions: argument types, faithfulness criteria, and fallacy-handling logic."
- false equivalence: An informal fallacy that treats two things as equivalent despite relevant differences. Example: "Informal fallacy of false equivalence is detected."
- first-order logic (FOL): A formal logic system with quantifiers used to verify validity of reconstructions. Example: "first-order logic (FOL) formulas"
- formal fallacy: A logical error in an argument’s form that invalidates the inference. Example: "An example of a formal fallacy is affirming the consequent: ``If it is snowing, then it is cold. It is cold. Therefore, it is snowing.''"
- formalization stage: The step that translates natural language reconstructions into formal logical formulas. Example: "After the formalization stage, the resulting FOL formulas are directly translated back into the NL domain"
- GAAR: Generalized Automatic Argument Reconstruction, an engine that reconstructs arbitrary arguments faithfully. Example: "We propose Generalized Automatic Argument Reconstruction (GAAR), an automatic engine that can faithfully reconstruct arbitrary arguments into formal premise--conclusion structures."
- hasty generalization: An informal fallacy drawing a broad conclusion from insufficient evidence. Example: "An example of an informal fallacy is hasty generalization: ``My neighbor's dog bit me, so all dogs are vicious.''"
- instruction-tuned model: A LLM trained on instruction-following data, later adapted via Arguinas. Example: "we find that finetuning an instruction-tuned model on Arguinas also improves the modelâs performance on downstream critical thinking tasks"
- legal reasoning: Reasoning about legal questions using rules and precedents; evaluated via the LegalArg task. Example: "The legal reasoning task corresponds to the Legal Argument Reasoning Task (LegalArg)~\cite{legalarg}"
- LegalArg: Legal Argument Reasoning Task evaluating correctness of legal answers. Example: "The legal reasoning task corresponds to the Legal Argument Reasoning Task (LegalArg)~\cite{legalarg}"
- LLM prompting: Directly prompting LLMs without auxiliary engines or tooling. Example: "GAAR outperforms all baseline methods, including AAR and LLM prompting, on argument reconstruction."
- logical streamlining: Clarifying and structuring the logical content by formal translation and back-translation. Example: "a process known as logical streamlining~\cite{deepa2}"
- Macro F1: A classification metric averaging F1 scores across classes. Example: "For the evaluation, Macro F1 score is reported for WebisArgQuality20, ArgsNovel, and LegalArg"
- non-deductive arguments: Arguments (e.g., inductive, abductive, analogical) whose conclusions are not guaranteed by premises. Example: "non-deductive arguments can also be reconstructed in a deductively valid form"
- parsimony: A faithfulness criterion assessing whether unnecessary premises are excluded. Example: "parsimony evaluates whether premises that are unnecessary for supporting the conclusion are excluded."
- pairwise judgments: Comparative evaluations between two arguments based on quality or persuasiveness. Example: "scalar or pairwise judgments of argument quality or persuasiveness"
- premise--conclusion structure: A structured representation of arguments highlighting logical support relations. Example: "resulting in a valid premise--conclusion structure"
- premise pruning: Removing premises that are not used in any valid proof of the conclusion. Example: "we employ a SAT solver to automatically perform premise pruning in the symbolic domain."
- pre-adaptation signal: An intermediate training objective that improves later task performance. Example: "argument reconstruction acts as a pre-adaptation signal that consistently improves subsequent learning on seven downstream critical thinking tasks."
- pre-adaptive finetuning: Finetuning on Arguinas prior to downstream task finetuning as an intermediate stage. Example: "We define finetuning on Arguinas as pre-adaptive when it is used as an intermediate stage before downstream task finetuning"
- ReClor: A logical reasoning dataset comprising standardized test-style multiple-choice questions. Example: "The logical reasoning task corresponds to ReClor~\cite{reclor}, which consists of multiple-choice questions drawn from standardized graduate admission examinations."
- SAT solver: A tool that checks propositional satisfiability, used here to test whether premises entail conclusions. Example: "a SAT solver determines whether the premises deductively imply the conclusion."
- symbolic domain: The representation space of formal logic expressions used for validation and pruning. Example: "we employ a SAT solver to automatically perform premise pruning in the symbolic domain."
- Walton’s argument types: A taxonomy of 60 informal logic schemes categorizing everyday arguments. Example: "Waltonâs argument types can likewise be reconstructed in a deductively valid form."
- WebisArgQuality20: A dataset for pairwise argument quality assessment across multiple dimensions. Example: "Argument quality evaluation tasks include WebisArgQuality20~\cite{webisargqulaity20}, UKPConvArg2~\cite{ukpconvarg2}, and WebisCMV20~\cite{webiscmv20}."
- WebisCMV20: A dataset assessing whether a rebuttal changes the author’s viewpoint (from Change My View). Example: "Argument quality evaluation tasks include WebisArgQuality20~\cite{webisargqulaity20}, UKPConvArg2~\cite{ukpconvarg2}, and WebisCMV20~\cite{webiscmv20}."
- UKPConvArg2: A dataset for evaluating argument quality via pairwise comparisons. Example: "Argument quality evaluation tasks include WebisArgQuality20~\cite{webisargqulaity20}, UKPConvArg2~\cite{ukpconvarg2}, and WebisCMV20~\cite{webiscmv20}."
Collections
Sign up for free to add this paper to one or more collections.

