Towards sample-optimal learning of bosonic Gaussian quantum states
Published 18 Mar 2026 in quant-ph, cs.IT, cs.LG, and math-ph | (2603.18136v1)
Abstract: Continuous-variable systems enable key quantum technologies in computation, communication, and sensing. Bosonic Gaussian states emerge naturally in various such applications, including gravitational-wave and dark-matter detection. A fundamental question is how to characterize an unknown bosonic Gaussian state from as few samples as possible. Despite decades-long exploration, the ultimate efficiency limit remains unclear. In this work, we study the necessary and sufficient number of copies to learn an $n$-mode Gaussian state, with energy less than $E$, to $\varepsilon$ trace distance with high probability. We prove a lower bound of $Ω(n3/\varepsilon2)$ for Gaussian measurements, matching the best known upper bound up to doubly-log energy dependence, and $Ω(n2/\varepsilon2)$ for arbitrary measurements. We further show an upper bound of $\widetilde{O}(n2/\varepsilon2)$ given that the Gaussian state is promised to be either pure or passive. Interestingly, while Gaussian measurements suffice for nearly optimal learning of pure Gaussian states, non-Gaussian measurements are provably required for optimal learning of passive Gaussian states. Finally, focusing on learning single-mode Gaussian states via non-entangling Gaussian measurements, we provide a nearly tight bound of $\widetildeΘ(E/\varepsilon2)$ for any non-adaptive schemes, showing adaptivity is indispensable for nearly energy-independent scaling. As a byproduct, we establish sharp bounds on the trace distance between Gaussian states in terms of the total variation distance between their Wigner distributions, and obtain a nearly tight sample complexity bound for learning the Wigner distribution of any Gaussian state to $\varepsilon$ total variation distance. Our results greatly advance quantum learning theory in the bosonic regimes and have practical impact in quantum sensing and benchmarking applications.
The paper establishes nearly-tight, sample-optimal bounds for learning multimode bosonic Gaussian states using both Gaussian and non-Gaussian measurement strategies.
It demonstrates that non-Gaussian measurements outperform Gaussian ones, reducing sample complexity from Θ(n^3/ε^2) to Θ(n^2/ε^2) in passive states.
Adaptivity and energy constraints are key factors, with optimized protocols enabling efficient quantum state tomography in practical, high-dimensional settings.
Sample-Optimal Learning of Bosonic Gaussian Quantum States: Complexity, Measurement Strategies, and Non-Gaussian Advantages
Problem Setting and Context
The paper "Towards sample-optimal learning of bosonic Gaussian quantum states" (2603.18136) provides an in-depth information-theoretic and operational analysis of the sample complexity for quantum state tomography of multimode bosonic (continuous-variable) Gaussian states. These states, fundamental to quantum optics and CV quantum information, are pivotal in quantum sensing (including gravitational wave and dark matter detection), communication (CV-QKD), and quantum computing with photonic or phononic systems. The challenge is to determine, for an unknown n-mode Gaussian state ρ(μ,Σ) with bounded energy (per-mode operator norm ∥Σ∥op≤E), how many copies N are necessary and sufficient to learn ρ up to trace distance ε with high probability, and how these limits depend on the class of allowed measurements.
Main Results and Complexity Bounds
The primary contributions are a sequence of tight and nearly-tight lower and upper bounds on the sample complexity for various state and measurement constraints, summarized as follows:
General Gaussian States with Gaussian or Classical Measurements: Any protocol using only Gaussian (or more generally, Wigner-positive/classical) measurements requires
N=Ω(ε2n3)
copies for learning to trace distance ε, matching (up to polylogarithmic factors) the previous upper bound given in [bittel2025energy]. Hence, the known adaptive Gaussian tomography is essentially optimal within this measurement class.
General Gaussian States with Arbitrary Measurements: Allowing arbitrary, potentially non-Gaussian, collective measurements reduces the lower bound to the optimal classical statistical scaling,
N=Ω(ε2n2),
and this can be saturated (up to polylogarithms and energy factors) for pure and passive Gaussian states.
Pure Gaussian States: The sample-optimal scaling is
N=Θ(n2/ε2)
(suppressing log factors), achievable using only Gaussian measurements.
Passive Gaussian States: The same optimal scaling holds for arbitrary (non-Gaussian) measurements, while Gaussian (or classical) measurements are provably a factor n less efficient,
Nclassical=Θ(n3/ε2),Narbitrary=O(n2/ε2).
This constitutes a formal demonstration of a strict non-Gaussian advantage for quantum tomography even within the (highly regular) subclass of passive Gaussian states.
Single-Mode and Energy Dependence: For non-adaptive, single-copy Gaussian protocols, the sample complexity for a single mode scales as N=Θ(E/ε2). Adaptivity is necessary for the (almost) energy-independent scaling achieved by the best known protocols.
These regimes demarcate a full hierarchy of quantum learning rates determined by both the physical class of the state and the operational power of the allowed measurements.
Technical Innovations
A key technical tool is a sharp quantitative comparison between the (quantum) trace distance of two Gaussian states and the total variation (TV) distance of their Wigner distributions. The authors establish:
For general n-mode Gaussian states, the trace distance can exceed the Wigner TV distance by a factor O(n), which is tight. For pure states, the two are proportional up to a universal constant.
This yields a byproduct: learning the Wigner function to TV distance ε requires and suffices with N=Θ(n2/ε2) samples using only Gaussian measurements (the same as for classical Gaussian distribution learning), but controlling TV distance is, in general, not enough for controlling trace distance on states.
Lower bounds are constructed using Fano-type arguments. The authors design explicit ensembles of hard-to-distinguish Gaussian states whose Wigner functions are only slightly separated but whose quantum distinguishability scales unfavorably for classical measurement protocols.
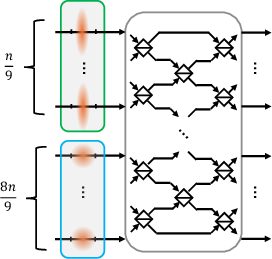
Figure 1 presents the essential construction of these hard ensembles used in lower bound proofs.
Figure 1: An illustration of the Gaussian state ensembles used in the lower bound proofs, for the case of n/9 squeezed states (cyan) and $8n/9$ vacuum states; each choice of the unitary defines a distinct ensemble member.
By leveraging the impossibility of simulating general quantum measurements by sampling from the Wigner distribution when the measurement is non-classical, the protocols demonstrate that only non-Gaussian resources can saturate the optimal sample complexity in the mixed case.
Measurement Strategies and Non-Gaussian Advantage
An operational separation is established:
Gaussian (or classical) measurements: These include all general-dyne strategies (heterodyne, homodyne, etc.) and admit efficient simulation via Wigner samples. Their sample complexity is fundamentally limited by the classical difficulty of estimating both the mean vector and the second-order structure of the Wigner function in high dimensions.
Non-Gaussian collective strategies: Notably, photon number detection (or more generally, measurements extracting higher-order non-Gaussian features) can achieve optimal rates for certain structured cases (passive, pure states).
For tomography of passive Gaussian states, the authors adapt recent random purification channel techniques to show that non-Gaussian operations allow for a quantum channel transforming N copies of a passive mixed state into random Gaussian purifications, thereby reducing mixed-state tomography to the pure state case with no essential overhead. While theoretically powerful, actual circuits are left as a future challenge.
This separation is the first formal "non-Gaussian learning advantage" in continuous-variable quantum learning theory, suggesting the practical necessity of engineering non-Gaussian measurements for efficient high-precision tomographic protocols in large-scale photonic systems.
Role of Adaptivity and Energy
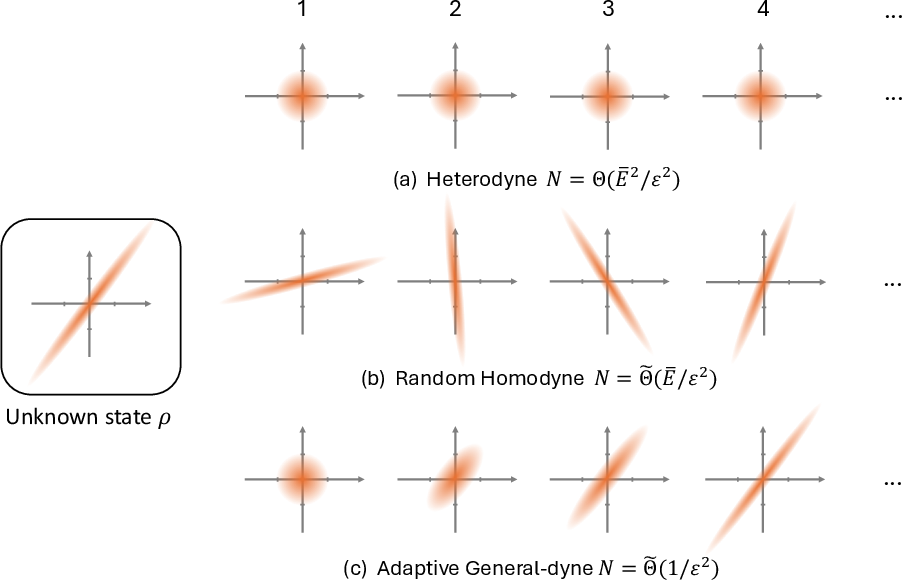
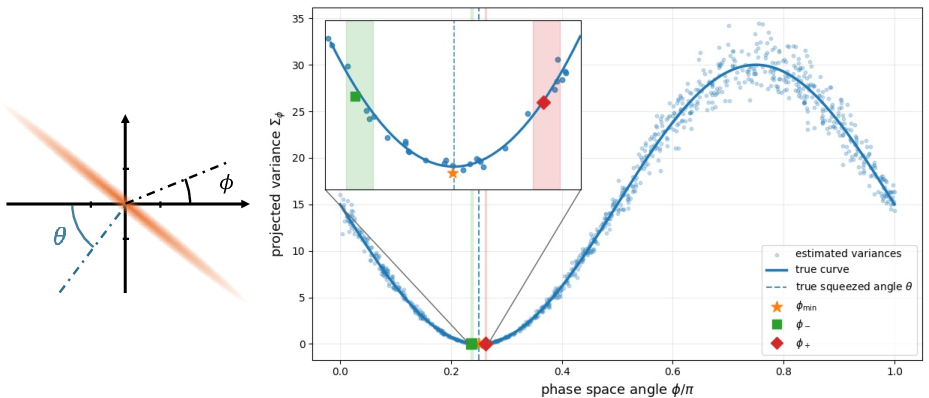
A detailed investigation shows that in the single-mode regime (or under non-adaptive, product measurement constraints), sample complexity necessarily scales at least linearly in the energy bound E, i.e., high squeezing (energy) renders learning hard unless one uses adaptive measurements. The optimal protocol in the non-adaptive regime uses randomized homodyne directions.
Figure 2: Comparison of Wigner functions for the unknown state and for three measurement schemes: (a) heterodyne (vacuum seed), (b) angle-randomized homodyne (random squeezed quadrature), (c) adaptive general-dyne (adaptive squeezing).
Theoretical and Practical Implications
Theoretical: The optimal sample complexity for mixed Gaussian state tomography is robustly pinned at N=Θ(n2/ε2) for arbitrary measurements, and N=Θ(n3/ε2) for general-dyne protocols. The formal separation between Gaussian and non-Gaussian learning power is both conceptually and operationally significant, demonstrating intrinsic quantum advantages not just from entanglement or ancillary memory but from higher moments and non-Wigner-positive strategies. The analysis establishes new tools (Wigner-TVD vs. trace distance comparison, random purification bounds) which could impact related fields such as quantum data hiding, metrological bounds, and channel discrimination.
Practical: The results are directly relevant for the design of scalable, sample-efficient tomography in experimental platforms—particularly for broadband, multimode detectors in quantum sensing, or in benchmarking large-scale boson samplers. For high-dimensional, weak-signal settings (e.g., axion searches, gravitational wave detectors), deploying non-Gaussian resources may be essential to attain information-theoretically minimal time or resource overhead.
Future directions: Open questions include extending random purification constructions to general (non-passive) Gaussians, understanding the role of entangled Gaussian measurements in the presence or absence of adaptivity, query complexity for Gaussian channel learning, and experimental implementation of the provably optimal non-Gaussian protocols. A rich avenue is also the exploration of these separations in structured non-Gaussian and weakly non-Gaussian states (as found in realistic noisy platforms).
Conclusion
This work establishes the landscape for sample-optimal learning of bosonic Gaussian quantum states, rigorously characterizing the dependence of the minimal tomographic overhead on state class, system size, target accuracy, available measurement resources, and operational adaptivity/collectivity. The central innovation is the identification of a strict and robust separation between Gaussian and non-Gaussian measurement strategies in mixed state tomography, providing both a theoretical template and a practical roadmap for quantum-limited CV learning and sensing tasks.
Figure 3: Example execution of the non-adaptive randomized homodyne algorithm for single-mode Gaussian state learning; dots show projected empirical variances versus homodyne angle, with the minimum corresponding to the squeezed quadrature, which enables parameter extraction.