Learning to Reason with Curriculum I: Provable Benefits of Autocurriculum
Published 18 Mar 2026 in cs.LG and stat.ML | (2603.18325v1)
Abstract: Chain-of-thought reasoning, where LLMs expend additional computation by producing thinking tokens prior to final responses, has driven significant advances in model capabilities. However, training these reasoning models is extremely costly in terms of both data and compute, as it involves collecting long traces of reasoning behavior from humans or synthetic generators and further post-training the model via reinforcement learning. Are these costs fundamental, or can they be reduced through better algorithmic design? We show that autocurriculum, where the model uses its own performance to decide which problems to focus training on, provably improves upon standard training recipes for both supervised fine-tuning (SFT) and reinforcement learning (RL). For SFT, we show that autocurriculum requires exponentially fewer reasoning demonstrations than non-adaptive fine-tuning, by focusing teacher supervision on prompts where the current model struggles. For RL fine-tuning, autocurriculum decouples the computational cost from the quality of the reference model, reducing the latter to a burn-in cost that is nearly independent of the target accuracy. These improvements arise purely from adaptive data selection, drawing on classical techniques from boosting and learning from counterexamples, and requiring no assumption on the distribution or difficulty of prompts.
The paper presents autocurriculum algorithms that achieve exponential reductions in sample complexity by focusing supervision on errors through outcome verifiers.
It demonstrates both supervised fine-tuning and reinforcement learning improvements, optimizing chain-of-thought reasoning with adaptive training curricula.
Theoretical analysis connects with recent LLM training methods, highlighting practical cost reductions and enhanced scalability in structured sequence prediction.
Provable Benefits of Autocurriculum for Reasoning Models
Overview
This paper provides a rigorous theoretical analysis of autocurriculum learning for chain-of-thought (CoT) reasoning in LLMs, addressing both supervised fine-tuning (SFT) and reinforcement learning (RL) with verifier-based rewards (2603.18325). The central result is a series of provable, often exponential, reductions in sample and compute requirements for reasoning models when they autonomously select curricula based on their own performance—referred to as "autocurriculum"—as opposed to fixed, human-designed training regimes.
Chain-of-Thought Reasoning and Curriculum Selection
Recent LLM advances hinge on CoT reasoning, where the model generates multi-step intermediate tokens before predicting final answers. Training such models is costly because acquiring high-quality traces—either via human supervision or synthetic teachers—demands significant compute and curation efforts. Standard reinforcement learning finetuning amplifies compute costs due to the need for large numbers of rollout traces. The paper asks whether these costs are fundamental or surmountable by enhanced algorithmic design.
A crucial observation is that curriculum design—systematically ordering training problems—can accelerate learning, but autonomously learned curricula (autocurricula) are theoretically underexplored. The paper formalizes autocurriculum within a framework for autoregressive reasoning and establishes its superiority over non-adaptive approaches.
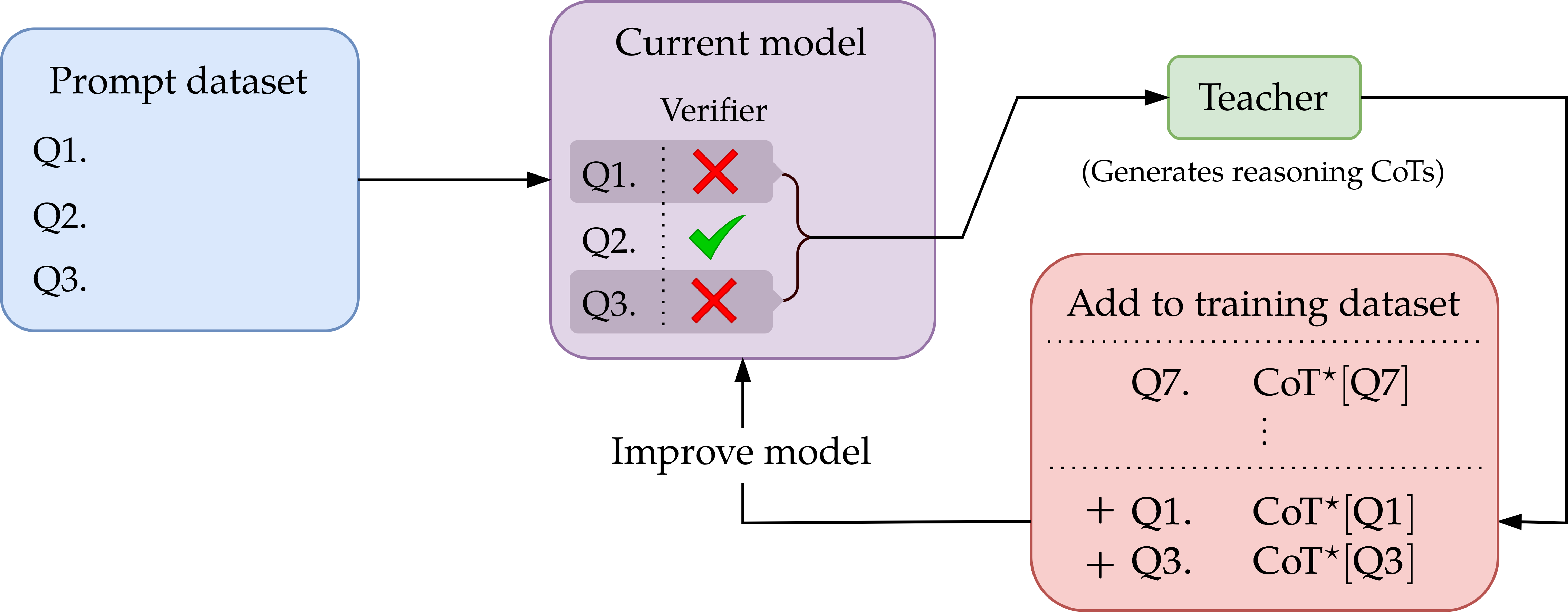
Figure 1: With autocurriculum in SFT, the learner selectively queries teacher CoTs for prompts it currently mispredicts, substantially reducing demonstration requirements.
Supervised Fine-Tuning: Exponential Gains via Autocurriculum
The authors introduce AutoTune, an autocurriculum SFT algorithm inspired by boosting and learning-from-counterexamples. At each iteration, the model queries CoT demonstrations only for prompts where its predictions are currently incorrect, as determined by a verifier. This selective focus yields exponential reductions in the number of CoT demonstrations necessary to achieve accuracy 1−ε—shrinking requirements from Θ(d/ε) to O(d), where d denotes model class complexity (Natarajan dimension). The critical insight is that the model's own error signal efficiently routes supervision, rendering costs nearly independent of the accuracy target—without any assumptions on prompt difficulty distributions.
This improvement stands in contrast to classical active learning, which typically requires stringent distributional or structural assumptions for logarithmic label complexities.
The paper also establishes that these guarantees hold in both deterministic and general (stochastic) model settings: for the latter, autocurriculum achieves high per-prompt pass@k rates using only logarithmically many teacher queries with respect to model class size.
Reinforcement Learning with Verifiable Rewards
In the RL variant, the learner starts from a reference model and iteratively improves performance with outcome-verifier feedback. The authors adopt a "sequence-level coverage" abstraction: the reference model must assign at least inverse-polynomial probability to the correct CoT for each prompt.
As a baseline, the authors consider rejection sampling: repeatedly sampling from the reference model until a verifiably correct CoT is obtained, then fine-tuning. The compute cost here scales linearly with the desired accuracy (O(d/ε), with d and ε as above).
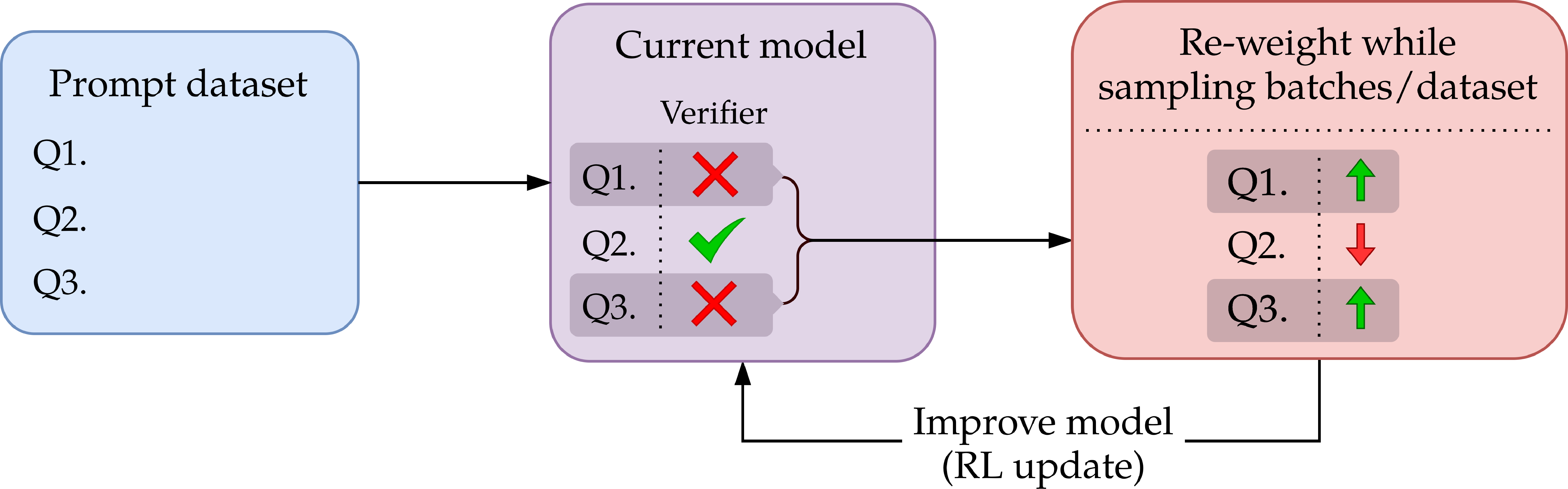
Figure 3: In autocurriculum-based RL, the learner adaptively samples prompts and updates on those with frequent errors, substantially decoupling compute cost from reference model coverage.
By applying AutoTune with RL and verifier guidance, the total cost is decoupled from coverage in the target accuracy regime—the coverage-dependent cost becomes a one-time "burn-in," while the dominant term for fine-tuning scales nearly independently of the reference's limitations. Formally, compute drops from O(d/ε) for standard rejection finetuning to O(d+d/ε) under autocurriculum.
Theoretical Characterization
A key technical contribution is a boosting-inspired ensemble analysis. By adaptively reweighting the training distribution to focus on errors (as certified by a verifier), each successive model in the ensemble is forced to correct a large fraction of the remaining mistakes. The ensemble prediction is then aggregated via plurality vote. These results generalize beyond LLMs to any sequence modeling or structured prediction setting with access to outcome verifiers.
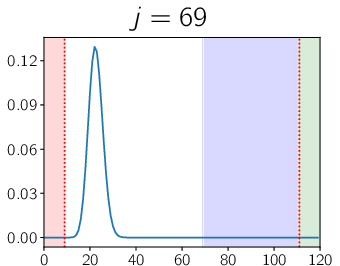
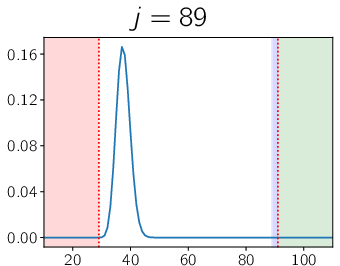
Figure 2: Progression of the ensemble's weighting and correction mechanism shows how the autocurriculum approach incrementally converges toward full coverage and high accuracy.
The use of outcome-level verifiers, as opposed to full CoT supervision, is central to enabling these gains—active learning analogs require much stricter assumptions, whereas autocurriculum leverages the unique structure of CoT verification for exponential effects.
Practical and Theoretical Implications
On the empirical side, the analysis unifies and explains the efficiency gains seen in recent RL-based LLM training systems (e.g., DAPO, ReST, DeepSeek-R1), where variants of autocurriculum have been applied heuristically. The theory predicts when such systems are likely to realize exponential compute reductions and clarifies that hand-designed or curriculum-based sampling, absent verification-based adaptivity, cannot generally match these sample complexities.
Practically, these results suggest that as LLMs and reasoning tasks grow more complex, *self-adaptive training will be essential for scaling, sharply reducing the cost of human and computational supervision. In environments where ground-truth or high-quality outcome verification is available (mathematics, code, theorem proving), autocurriculum is nearly optimal in terms of data and compute efficiency.
Theoretically, the results challenge the limits of long-standing lower bounds in active and passive learning for structured sequence-prediction, showing that fine-grained verification feedback unlocks regimes with exponentially better complexity. The framework is expected to inform future analysis of open-ended self-improvement, coverage expansion, and curriculum discovery in reinforcement learning.
Future Directions
The analysis leaves several important avenues open, including:
Handling scenarios with imperfect, partial, or learned outcome verifiers.
Extending the theory to dynamic, self-improving references ("self-play") where coverage improves iteratively.
Adapting the autocurriculum framework for online, on-policy RL settings (e.g., PPO variants) prevalent in current LLM training pipelines.
Formalization and quantification of coverage expansion—can autocurriculum alone expand the model's intrinsic capability frontier via curriculum on easier problems?
Conclusion
This paper establishes provable exponential improvements in sample and computational complexity for reasoning model training via autocurriculum, using outcome verifier feedback to adaptively select and prioritize supervision. These results provide a rigorous foundation for self-adaptive training protocols in LLM post-training and RL, showing that autocurriculum mechanisms dramatically enhance learning efficiency and scalability in structured sequence prediction. The theoretical tools and insights introduced are poised to influence future LLM training pipelines and curriculum learning algorithms.