3DreamBooth: High-Fidelity 3D Subject-Driven Video Generation Model
Abstract: Creating dynamic, view-consistent videos of customized subjects is highly sought after for a wide range of emerging applications, including immersive VR/AR, virtual production, and next-generation e-commerce. However, despite rapid progress in subject-driven video generation, existing methods predominantly treat subjects as 2D entities, focusing on transferring identity through single-view visual features or textual prompts. Because real-world subjects are inherently 3D, applying these 2D-centric approaches to 3D object customization reveals a fundamental limitation: they lack the comprehensive spatial priors necessary to reconstruct the 3D geometry. Consequently, when synthesizing novel views, they must rely on generating plausible but arbitrary details for unseen regions, rather than preserving the true 3D identity. Achieving genuine 3D-aware customization remains challenging due to the scarcity of multi-view video datasets. While one might attempt to fine-tune models on limited video sequences, this often leads to temporal overfitting. To resolve these issues, we introduce a novel framework for 3D-aware video customization, comprising 3DreamBooth and 3Dapter. 3DreamBooth decouples spatial geometry from temporal motion through a 1-frame optimization paradigm. By restricting updates to spatial representations, it effectively bakes a robust 3D prior into the model without the need for exhaustive video-based training. To enhance fine-grained textures and accelerate convergence, we incorporate 3Dapter, a visual conditioning module. Following single-view pre-training, 3Dapter undergoes multi-view joint optimization with the main generation branch via an asymmetrical conditioning strategy. This design allows the module to act as a dynamic selective router, querying view-specific geometric hints from a minimal reference set. Project page: https://ko-lani.github.io/3DreamBooth/








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
3DreamBooth: High‑Fidelity 3D Subject‑Driven Video Generation — Explained Simply
What is this paper about?
This paper presents a new way to make videos that keep a specific object (like a sneaker, toy, or character) looking correct from every angle as it moves. The goal is to take just a few photos of the object from different sides and then automatically place that object into new scenes and motions—while keeping its true 3D shape and fine details consistent throughout the video.
What questions are the researchers trying to answer?
The paper focuses on four main goals:
- How can we make videos that treat a subject as a real 3D object, not just a flat picture?
- How can we keep the subject’s appearance (its shape and details) separate from its motion (how it moves), so it doesn’t “learn” the wrong motion?
- How can we keep small, important details (like logos, textures, or patterns) sharp and accurate?
- How can we do all this efficiently, without needing huge special video datasets?
How does their method work?
The method combines two main ideas: 3DreamBooth and 3Dapter.
- Think of a video AI model like a smart painter that usually learns from tons of videos. The team “teaches” this painter about a specific object using only a few photos from different angles.
- 3DreamBooth: This is a training trick. Instead of feeding the model full videos during training, they only give it one image at a time (“1‑frame training”).
- Why? Because one image forces the model to focus on what the object looks like (its 3D shape and appearance) and not on time or motion.
- They also attach a tiny add‑on called LoRA (like a small set of knobs you can adjust on the model) to memorize the subject’s unique look without changing the whole model.
- They use a special “token” (like a unique name, say “V”) in the text prompt to represent your specific object. Over training, this token learns the object’s 3D identity across views.
- 3Dapter: This is a helper module that feeds the model visual hints from the reference photos.
- First, it’s trained to understand how to use a single reference image to guide the model.
- Then, it’s used with a handful of different views (e.g., front, side, back) of the same object.
- It acts like a “smart router”: for each frame the model is drawing, it pays more attention to the reference photo that best matches the current viewing angle. This helps the model keep shape and details correct from all sides.
- Because 3Dapter supplies rich visual details, the model learns faster and preserves fine textures (like tiny text or patterns).
In short: 3DreamBooth teaches the model the object’s 3D identity from single frames, and 3Dapter supplies view‑specific visual clues to keep details crisp. Together, they make consistent, high‑quality videos of the object in motion and new scenes.
What did they find?
The researchers tested their system in several ways and built a new benchmark (3D‑CustomBench) for fair comparison. Here’s what stood out:
- Better 3D consistency: Their method kept shapes and details stable as the camera moved around the object, outperforming other methods that relied on only a single reference image.
- More accurate geometry: Using a simple “shape difference” test (imagine comparing 3D point clouds of the real and generated shapes), their videos matched the true 3D shape more closely than the baselines.
- Sharper details: Thanks to 3Dapter, small textures and text (like logos or labels) were preserved much better.
- Faster, more efficient training: Because 3Dapter provides strong visual hints, the model learned more quickly and didn’t need tons of video data.
- Overall video quality stayed high: Even with the extra 3D control, the videos remained smooth, good‑looking, and aligned with the prompts.
Why is this important?
This approach makes it much easier to create realistic, consistent videos of a specific 3D object without expensive filming from every angle or collecting special multi‑view videos. It can help:
- VR/AR and games: Drop customized 3D characters or items into any scene and motion while staying true to their look.
- Advertising and e‑commerce: Show products rotating, moving, and being used in different environments—accurately and quickly.
- Virtual production: Reduce reshoots and manual 3D modeling by generating high‑fidelity, view‑consistent footage from just a few photos.
Bottom line
The paper introduces a practical, efficient way to make subject‑specific videos that respect an object’s full 3D shape and fine details. By training with single frames (3DreamBooth) and guiding the model with multi‑view visual hints (3Dapter), the method produces more consistent and realistic videos than previous approaches—opening the door to faster, more flexible video creation for a wide range of applications.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that the paper leaves unresolved, framed to guide future research.
- Dependence on implicit 3D priors: The method relies on the pretrained video DiT’s implicit 3D understanding without quantifying where it succeeds/fails versus explicit geometry-aware models (e.g., NeRF/3DGS, mesh priors). How does performance vary by backbone, and can explicit 3D inductive biases further improve consistency?
- 1-frame optimization limits: Training with bypasses temporal attention, but the impact on non-rigid or articulated subjects (humans, animals, cloth) where identity is entangled with motion is untested. What mechanisms could inject identity–motion coupling without temporal overfitting?
- Multi-view reference burden: The approach assumes ~30 views for 3DreamBooth and background-masked conditioning views covering . What is the minimal view count and angular coverage required to maintain quality, and how does performance degrade with sparser, occluded, or noisy views?
- Automatic view selection: Conditioning views are “selected to maximize angular coverage,” but no algorithm is described or evaluated. Can an automatic, data-driven selection or active acquisition policy improve results under fixed budget ?
- Sensitivity to segmentation/matting: 3Dapter conditions use background-masked references. The robustness to imperfect masks, matting halos, or segmentation errors is not analyzed; failure modes and simple robustness strategies (e.g., soft masks, augmentation) are open.
- Lighting and materials: The method does not explicitly model relighting, shadows, or view-dependent reflectance/transparency. How robust is geometry/texture preservation under drastic illumination/material changes, and can learned relighting modules or BRDF-aware cues be integrated?
- Camera intrinsics/extrinsics mismatch: The pipeline ignores known camera parameters and assumes unknown intrinsics; the effect of focal-length changes, lens distortions, or pose errors in references is unstudied. Can pose-aware conditioning improve geometric fidelity?
- Explicit 3D asset output: Despite “3D-aware” conditioning, the model cannot export meshes/point clouds. Can the learned subject prior be distilled into an explicit 3D representation for reuse (e.g., mesh, 3DGS, NeRF) or leveraged by differentiable renderers for stronger constraints?
- Long-horizon temporal consistency: Evaluations focus on short 360° spins. Identity drift, texture flicker, and geometry wobble over long or complex videos (camera and subject motion, scene cuts) are not measured; strategies for long-horizon consistency remain open.
- Motion–camera disentanglement and control: The framework relies on pretrained temporal priors at inference but does not offer explicit controls to separate subject motion from camera motion; methods for controllable and precise trajectory specification are absent.
- Multi-subject and interaction scenarios: The approach and metrics target single-object videos. Compositionality (multiple customized subjects), occlusions, contacts, and physical interactions are not addressed.
- Generalization across categories: Benchmarks emphasize rigid objects. Performance on deformable subjects, fine structures (hair/fur), thin/transparent/reflective materials, and highly symmetric objects (with ambiguous views) is unknown.
- Domain and backbone generality: The method is implemented on HunyuanVideo-1.5; transferability to different video DiTs or latent/video backbones (and to image-only backbones with temporal modules) is not evaluated.
- Inference-time conditioning requirements: It remains unclear whether 3Dapter’s multi-view images are required at inference for all use cases, and how runtime/memory scale with . What is the trade-off between conditioning strength and efficiency at inference?
- Training/inference efficiency: Claims of efficiency lack concrete GPU-hours/latency/memory profiles relative to baselines and as a function of LoRA rank, number of optimized layers, and . Can adaptation be reduced below 400 steps without quality loss?
- Parameter-placement ablations: The impact of LoRA placement (which layers, attention vs MLP, spatial vs cross-attention) and rank on identity, geometry, and text alignment is not explored; optimal configurations remain unknown.
- Positional encoding for multi-view conditions: The use of 3D RoPE with “sequential temporal indices” for view tokens is introduced without comparisons. Are other positional encodings (e.g., absolute 3D orientation cues, spherical harmonics) or learned view embeddings superior?
- Router interpretability and control: The “dynamic selective router” behavior is qualitatively shown, but not quantified. Can attention routing be explicitly supervised, regularized, or user-controlled to improve robustness and avoid view conflicts?
- Identity–text trade-off: Results show slight drops in text alignment (ViCLIP) when maximizing identity fidelity. Methods for balancing or decoupling identity preservation and prompt adherence (e.g., multi-objective losses, gating) are unexplored.
- Fairness of comparisons: Baselines are single-view methods while the proposed method uses multi-view supervision; apples-to-apples comparisons with multi-view-capable baselines or single-view variants with matched data budgets are missing.
- Benchmark size and reproducibility: 3D-CustomBench has only 30 objects and includes custom-captured items; the release status, licensing, and reproducibility details are unclear. Broader, standardized datasets with varied categories and scenes are needed.
- Geometry metric reliability: Chamfer Distance is computed from monocular depth estimates and masks, which can be noisy and biased. Evaluations against ground-truth scans or multi-view stereo reconstructions, and uncertainty-aware metrics, are needed.
- LLM-as-a-judge bias: GPT-4o scoring lacks human inter-rater validation, calibration, or bias analysis. Human studies (with IRR metrics) or open-source vision-language judges could strengthen reliability.
- Robustness to domain shift: The 3Dapter is pre-trained on Subjects200K (white-background objects). Behavior on in-the-wild references (cluttered backgrounds, varied lighting), rare categories, or stylized/handcrafted objects is not quantified.
- Handling of view-dependent effects: The pipeline does not explicitly model specular highlights or anisotropy; tests on objects with strong view-dependent appearance and methods to encode/view-condition such effects are open.
- Compositional editing and subject updates: How the method handles adding/removing parts, color changes, or accessories to the customized subject post-adaptation (without full re-optimization) is not addressed.
- Catastrophic interference with temporal priors: Although avoids temporal attention, shared weights may still alter motion priors indirectly. The effect on motion diversity/quality across unseen prompts is unmeasured.
- Failure cases and diagnostics: The paper does not catalog failure modes (e.g., texture bleeding, geometry collapse at unseen angles) or provide diagnostic tools to detect/view-coverage gaps and suggest remedial data acquisition.
Practical Applications
Immediate Applications
The following applications can be deployed today using the paper’s methods (3DreamBooth 1-frame optimization, 3Dapter multi-view conditioning, multi-view joint attention) on top of existing video diffusion backbones (e.g., HunyuanVideo), with modest subject-specific fine-tuning and a small set of multi-view images.
- 3D-consistent product videos for e-commerce
- Sectors: retail, marketing, software (SaaS), finance (conversion optimization)
- What: Turn 8–30 multi-view photos of a product into high-fidelity 360° spins and dynamic in-scene videos (lighting/motion variations) without full reshoots.
- Tools/products/workflows: “Product Video Generator” Shopify/BigCommerce app; CMS plugin that ingests multi-view photos, runs 3DreamBooth+3Dapter, and exports short 360° spins and lifestyle clips; batch pipeline for PIM/DAM systems.
- Assumptions/dependencies: Access to a pre-trained T2V model; 4–8 well-spaced reference views (background-masked if possible); GPU for LoRA fine-tuning; consent and IP rights for the product.
- Virtual production and advertising previsualization
- Sectors: media/entertainment, advertising, creative tools
- What: Previz or final-quality shots of custom props/products in varied scenes while preserving identity across camera moves.
- Tools/products/workflows: NLE/VFX plugins (Premiere/After Effects/DaVinci) and Unreal/Unity add-ons that accept reference views + text prompts; “on-set previz” desktop tool to iterate shot design with 3D-consistent subject inserts.
- Assumptions/dependencies: Not real-time; best used as pre-render; requires multi-view capture of the subject; motion physics may be stylized.
- Game asset and cinematic content prototyping
- Sectors: gaming, software, creative tools
- What: Generate cutscenes and promos showcasing custom in-game items/props across diverse environments with consistent 3D identity.
- Tools/products/workflows: Unity/Unreal editor extension to ingest multi-view captures of in-game merch/props; generate trailers or in-engine billboards.
- Assumptions/dependencies: Outputs are videos (not meshes); for in-game 3D use, a separate mesh-generation or reconstruction step is needed.
- Rapid product design review and concept marketing
- Sectors: industrial design, manufacturing, PLM
- What: Show design variants of prototypes (e.g., sneakers) in motion and in multiple settings for stakeholder review and early marketing tests.
- Tools/products/workflows: Internal “Design-to-Video” tool chained to CAD snapshots or photo prototypes; A/B test video creatives directly from design labs.
- Assumptions/dependencies: Clean multi-view captures of mockups; alignment between CAD snapshots and photo views improves consistency.
- Automated 360° product spins for marketplace sellers
- Sectors: small business, marketplaces, marketing
- What: Turn phone-captured multi-view images into uniform 360° spins and short videos to boost listing quality and buyer trust.
- Tools/products/workflows: Mobile app that guides users to capture 8–12 angles, applies background removal, fine-tunes, and generates consistent videos.
- Assumptions/dependencies: Basic capture discipline (coverage, lighting); cloud GPU for per-item LoRA adaptation.
- Interior/architecture staging with custom furniture/fixtures
- Sectors: real estate, AEC, retail
- What: Insert client-specific furniture or fixtures into rooms and generate smooth camera moves with accurate identity and textures.
- Tools/products/workflows: Interior design app integration; “Staging Video” export from floor-planning tools; batch room-scene renderings with client SKUs.
- Assumptions/dependencies: Multi-view captures of SKUs; background-masked references help; scene physics approximated.
- Cultural heritage artifact presentation
- Sectors: museums, education, media
- What: Create 360° rotations and contextualized videos of artifacts for exhibits and online catalogs while preserving fine textures and inscriptions.
- Tools/products/workflows: Museum digitization workflow: turntable photos → 3DreamBooth+3Dapter → exhibit loops and guided narration videos.
- Assumptions/dependencies: High-resolution multi-view images; careful lighting to capture inscriptions and patina.
- Synthetic data for perception models (object-centric)
- Sectors: robotics, autonomous systems, CV R&D
- What: Generate multi-view-consistent videos of specific objects with varied backgrounds and lighting for data augmentation.
- Tools/products/workflows: “Object Video Synthesizer” that samples prompts for domain randomization; label transfer via known object identity.
- Assumptions/dependencies: Domain gap to real world remains; videos not guaranteed physically accurate; labeling focuses on object identity, not precise 3D metrics.
- Academic benchmark and QC tools
- Sectors: academia, R&D, software tooling
- What: Use 3D-CustomBench methodology and point-cloud Chamfer Distance pipeline (Depth Anything + matting) for evaluation and production QA.
- Tools/products/workflows: Internal “3D consistency QA” that rejects assets with high CD/error; adoption of CLIP/DINO and LLM-as-judge protocols in CI.
- Assumptions/dependencies: Depth estimation and matting introduce their own errors; use as relative QC rather than absolute ground truth.
- Social media and creator tools for subject-personalized clips
- Sectors: creator economy, marketing
- What: Personalized videos of user objects (e.g., collectibles, crafts) placed in thematic scenes with smooth camera moves.
- Tools/products/workflows: Mobile/desktop creator apps integrating a simple “capture → choose scene → render” flow.
- Assumptions/dependencies: Content provenance and labeling; GPU latency/queue times; moderation for brand/IP use.
- Policy and compliance pilots (synthetic content labeling)
- Sectors: policy, platforms, advertising
- What: Pilot C2PA-style provenance, disclosure labels, and internal review criteria specific to object-personalized videos in ads/marketplaces.
- Tools/products/workflows: Watermarking and manifest attachment post-generation; reviewer dashboards with identity-consistency and benchmark scores.
- Assumptions/dependencies: Platform adoption of provenance standards; alignment with regional ad disclosure rules.
Long-Term Applications
These rely on further research, scaling, or system integration (e.g., real-time performance, mesh output, robust human/animal support, physical interaction modeling).
- Real-time AR try-before-you-buy with personalized, 3D-consistent assets
- Sectors: retail, AR/VR, mobile
- What: Live camera overlays that insert a personalized product into the scene from any angle with consistent identity and dynamic lighting.
- Tools/products/workflows: On-device distilled adapters; streaming inference; scene-aware conditioning; latency-optimized selective routing.
- Assumptions/dependencies: Significant model compression and acceleration; robust on-device background removal and lighting estimation.
- From video to editable 3D asset (mesh/NeRF) via inverse reconstruction
- Sectors: gaming, VFX, AEC, e-commerce
- What: Convert generated multi-view-consistent videos into textured meshes/NeRFs for direct use in engines and DCC tools.
- Tools/products/workflows: Post-process pipeline: multi-view depth/pose estimation → surface fusion → texture baking → USD/GLTF export.
- Assumptions/dependencies: Reliable geometry across frames; accurate camera pose recovery; dedicated reconstruction module.
- Multi-subject and human-centric 3D-consistent video customization
- Sectors: entertainment, fashion, sports
- What: Compose multiple customized subjects (including humans) with interactions while preserving identities from all viewpoints.
- Tools/products/workflows: Multi-token, multi-adapter conditioning; collision/pose priors; motion capture fusion.
- Assumptions/dependencies: Larger, curated multi-view datasets; stronger priors for deformation and cloth/hair; safety/consent frameworks.
- Robotics simulation assets with controllable physical properties
- Sectors: robotics, industrial automation
- What: Generate object videos that reflect realistic material and dynamics for training and sim-to-real transfer.
- Tools/products/workflows: Physics-informed prompts; learned material adapters tied to simulators (Isaac, Mujoco) for supervision.
- Assumptions/dependencies: Integration of physics priors; evaluation against real measurements; bridging video realism and physical accuracy.
- Interactive storytelling and education with subject-aware cinematography
- Sectors: education, media, museums
- What: Tutor or guide agents that generate bespoke videos of a student’s object (e.g., a microscope) in context-aware lessons.
- Tools/products/workflows: LLM planning + 3D-consistent video generation; curriculum APIs; teacher dashboards.
- Assumptions/dependencies: Reliable alignment with pedagogical goals; content safety; school device constraints.
- Supply-chain digital twins and catalog unification
- Sectors: manufacturing, logistics, PLM
- What: Produce standardized, identity-true video assets of SKUs for every region/channel from minimal captures.
- Tools/products/workflows: PIM connectors; automated identity audits using 3D-CustomBench-like metrics; global style localization.
- Assumptions/dependencies: Governance for source-of-truth assets; SKU version control; integration with ERP/PLM.
- Insurance and claims: damage scenario reconstructions
- Sectors: insurance, finance
- What: Generate standardized, multi-view-consistent videos of damaged items from limited photos to support adjuster review and fraud detection.
- Tools/products/workflows: Claims portal ingestion; controlled prompts for incident scenarios; anomaly detectors trained on synthetic vs real.
- Assumptions/dependencies: Ethical use and disclosure; biases in generation; validation against expert assessments.
- Content provenance, watermarking, and standards setting
- Sectors: policy, ad tech, platforms
- What: Establish norms for labeling, auditing, and detecting object-personalized synthetic videos at scale.
- Tools/products/workflows: C2PA manifests; robust watermarks; third-party certification based on 3D-consistency and identity-preservation metrics.
- Assumptions/dependencies: Cross-industry agreement; regulatory buy-in; resilient watermarking under editing.
- On-device creator experiences and edge appliances
- Sectors: consumer tech, mobile, retail kiosks
- What: Kiosks or smartphones that capture multi-view images and generate branded 360° videos on the spot (events, retail stores).
- Tools/products/workflows: Edge GPU appliances; quantized/distilled models; offline licensing.
- Assumptions/dependencies: Efficient memory/compute; thermal constraints; content moderation offline.
- Synthetic benchmarks and curriculum learning for 3D-aware T2V
- Sectors: academia, AI tooling
- What: Large-scale synthetic multi-view curricula to improve geometric fidelity and reduce reliance on scarce multi-view video datasets.
- Tools/products/workflows: Procedural asset banks; automatic prompt generation; self-training with 3D consistency rewards.
- Assumptions/dependencies: High-quality procedural assets; careful bias control; scalable evaluation protocols.
- Cross-domain adaptation to specialized sectors (healthcare devices, energy hardware)
- Sectors: healthcare (devices), energy (equipment), industrial B2B
- What: Generate training and marketing videos of specialized equipment with accurate identity and labeling.
- Tools/products/workflows: Sector-specific adapters (logos, gauges, compliance labels); regulated content pipelines with human-in-the-loop.
- Assumptions/dependencies: Strict compliance and approvals; domain-grounded verification; privacy and safety constraints.
- Fraud-resistant brand/IP asset generation and protection
- Sectors: legal, brand management, advertising
- What: Brand-authorized generators that produce canonical, labeled videos; detection models trained on known-good identity signatures.
- Tools/products/workflows: Brand registry of fine-tuned adapters; signed outputs; monitoring for misuse across platforms.
- Assumptions/dependencies: Legal frameworks; effective takedown processes; robust signature matching.
Notes on feasibility across applications
- Core dependencies: a strong pre-trained video diffusion backbone; 4–8+ multi-view images per subject (ideally with background removal); GPU access for short LoRA fine-tuning (hundreds of iterations).
- Method assumptions: best suited for object-centric, relatively rigid subjects; fine detail preserved via 3Dapter; dynamics driven by pre-trained temporal priors (not guaranteed physically accurate).
- Risks/constraints: IP and consent for subject capture; disclosure and provenance expectations; domain shift (extreme lighting/materials); current outputs are videos (not directly manipulable 3D assets).
Glossary
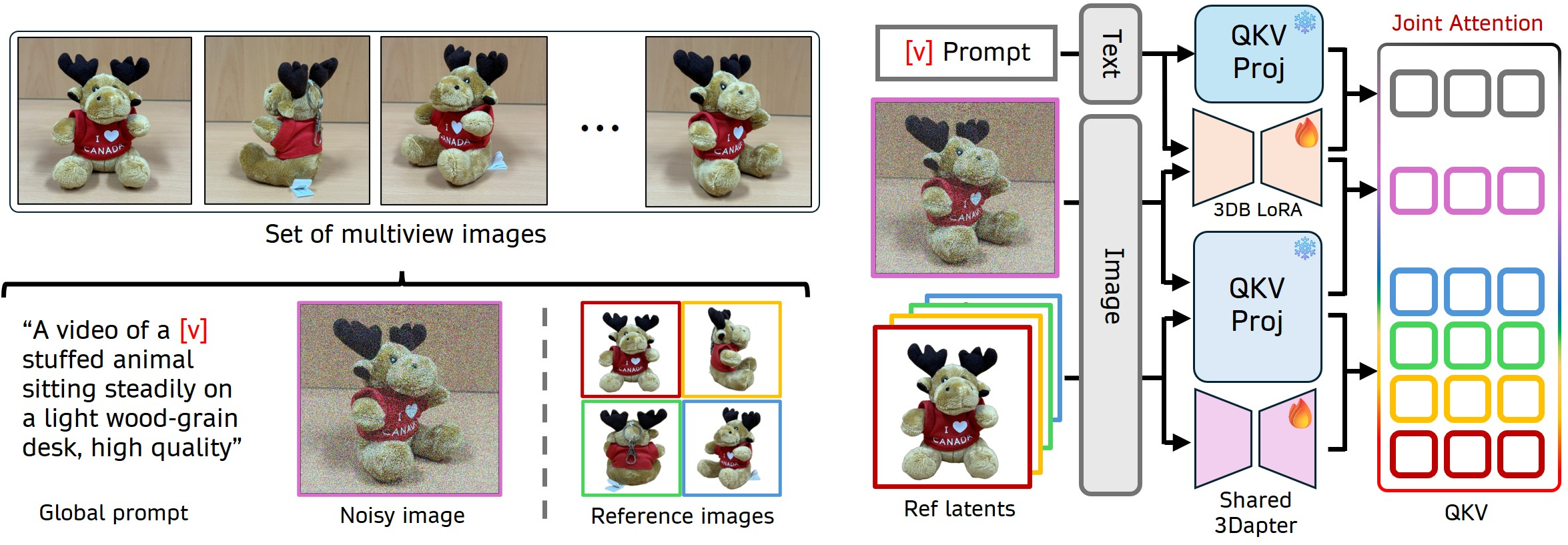
- 1-frame optimization paradigm: A training approach that uses only single-frame inputs to decouple spatial learning from temporal dynamics and avoid temporal overfitting. "3DreamBooth decouples spatial geometry from temporal motion through a 1-frame optimization paradigm."
- 3D Rotary Positional Encoding (RoPE): A positional encoding method that applies rotary transformations in 3D token space to preserve relative positions for attention. "When applying 3D Rotary Positional Encoding (RoPE)~\cite{su2024roformer} to the concatenated tensors, we assign distinct, sequential temporal indices..."
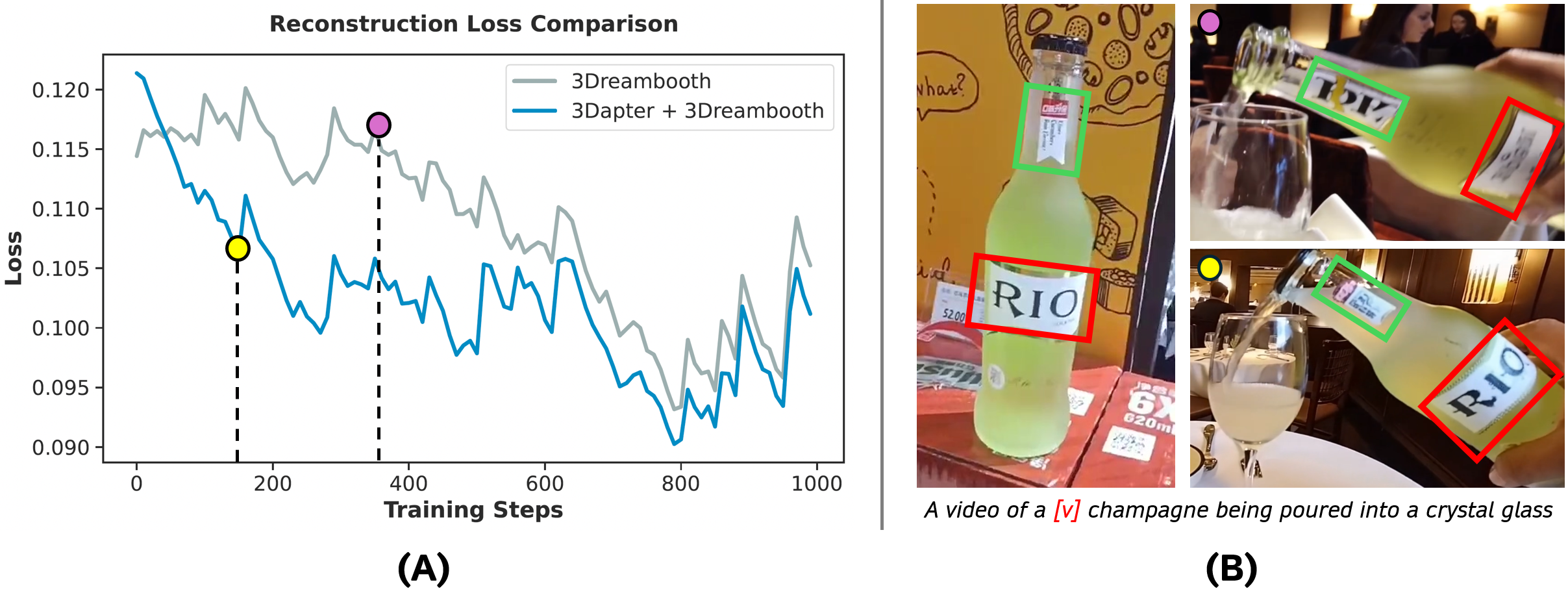
- 3Dapter: A multi-view visual conditioning module (implemented via LoRA) that injects reference-image features into the video diffusion process to preserve high-frequency details. "To enhance fine-grained textures and accelerate convergence, we incorporate 3Dapter, a visual conditioning module."
- 3DreamBooth: A 3D-aware personalization strategy that fine-tunes a video diffusion model (with LoRA) using single-frame, multi-view images to implant a subject’s 3D identity. "3DreamBooth adopts a 1-frame training paradigm~\cite{wei2024dreamvideo, huang2025videomage}."
- adapter-based conditioning: Conditioning a largely frozen model through lightweight adapter modules that inject external control signals (e.g., images). "We present a novel framework for 3D-aware customized video generation, unifying optimization-based personalization and adapter-based conditioning."
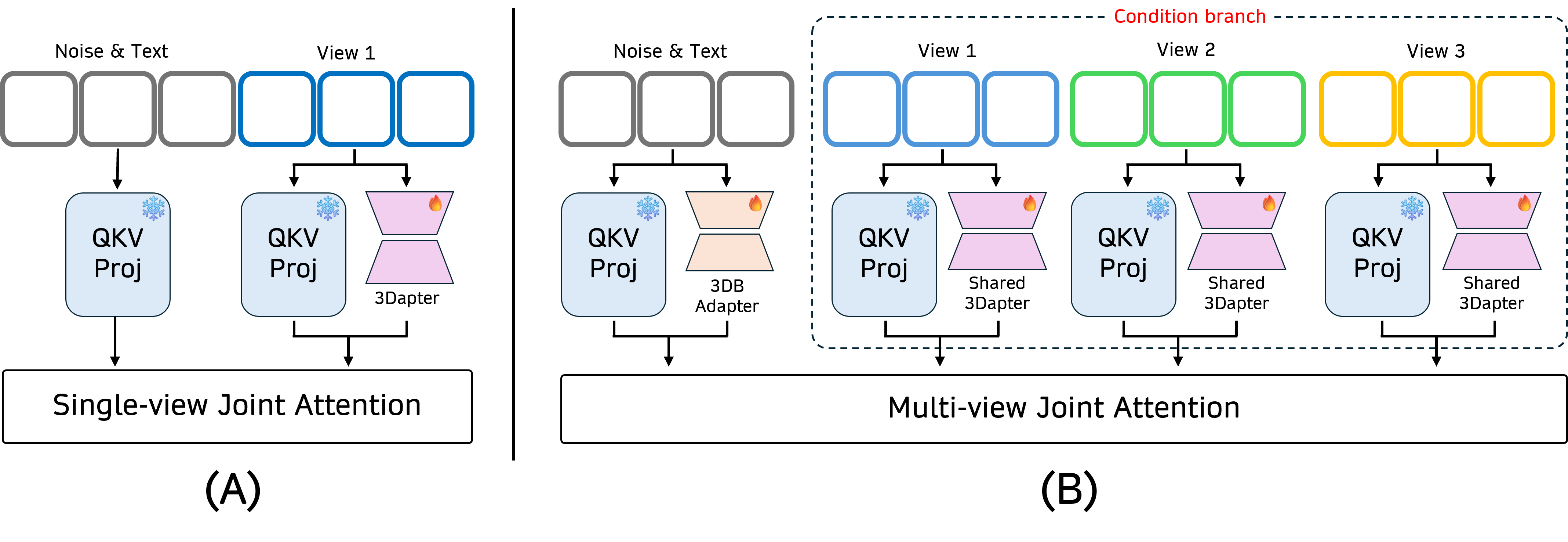
- asymmetrical conditioning strategy: A design where different branches receive different conditioning roles (e.g., main vs. adapter) to better utilize multi-view information. "Following single-view pre-training, 3Dapter undergoes multi-view joint optimization with the main generation branch via an asymmetrical conditioning strategy."
- BiRefNet: A bilateral refinement network for high-quality foreground extraction used to isolate subjects from backgrounds. "Using Depth Anything 3~\cite{lin2025depth} and BiRefNet~\cite{zheng2024bilateral}, we extract per-view depth maps and foreground masks..."
- bi-directional maximum cosine similarity: An evaluation measure that takes the maximum cosine similarity in both directions between generated frames and references to assess identity consistency. "we compute the bi-directional maximum cosine similarity between generated frames and the four condition views"
- Chamfer Distance: A geometric metric that measures the distance between two point clouds by averaging nearest-neighbor distances in both directions. "We then measure geometric consistency via Chamfer Distance~\cite{aanaes2016large}"
- CLIP: A contrastive vision–LLM used to quantify image-text or image-image similarity. "using CLIP~\cite{radford2021learning}"
- cross-attention heatmaps: Visualizations of attention weights showing how queries attend to keys across modalities or views. "Cross-attention heatmaps across diffusion timesteps ()."
- Depth Anything 3: A general-purpose monocular depth estimation model employed to recover depth from images. "Using Depth Anything 3~\cite{lin2025depth} and BiRefNet~\cite{zheng2024bilateral}, we extract per-view depth maps and foreground masks"
- depth maps: Per-pixel estimates of scene depth used to reconstruct 3D geometry from images. "we extract per-view depth maps and foreground masks"
- DINOv2: A self-supervised vision transformer used for feature-based image similarity evaluation. "using CLIP~\cite{radford2021learning} and DINOv2~\cite{oquab2023dinov2}"
- Diffusion Transformer (DiT): A transformer-based architecture that performs diffusion modeling, often with joint spatio-temporal attention for video. "Modern video Diffusion Transformers (DiTs)~\cite{peebles2023scalable} often process inputs via joint spatio-temporal attention."
- DreamBooth: A personalization technique that fine-tunes diffusion models to bind a subject to a unique textual identifier. "we build upon the foundational concept of DreamBooth~\cite{ruiz2023dreambooth}."
- dual-branch architecture: A design with separate main and conditioning branches whose tokens are fused via attention. "we introduce 3Dapter, a multi-view conditioning module integrated via a dual-branch architecture~\cite{zhang2025easycontrol, tan2025ominicontrol}."
- dynamic selective router: An emergent behavior where attention selectively routes information from the most relevant conditioning views to reconstruct the target view. "This design allows the module to act as a dynamic selective router, querying view-specific geometric hints from a minimal reference set."
- foreground masks: Binary masks isolating the subject from the background for cleaner geometric reconstruction. "we extract per-view depth maps and foreground masks"
- HunyuanVideo-1.5: A large-scale video generative foundation model used as the backbone for training and evaluation. "We build our framework upon HunyuanVideo-1.5~\cite{kong2024hunyuanvideo}"
- LLM-as-a-Judge: An evaluation paradigm where a LLM provides human-aligned judgments of generated content. "and an LLM-as-a-Judge~\cite{zheng2023judging} via GPT-4o~\cite{hurst2024gpt}."
- Likert scale: A psychometric scale used for subjective ratings; here, a five-point scale. "on a 1--5 Likert scale"
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning method that adds low-rank updates to a frozen model’s weights. "We optimize the pre-trained video Diffusion Transformer (DiT) using Low-Rank Adaptation (LoRA)."
- Multi-view Joint Attention: An attention mechanism that jointly attends over tokens from multiple conditioning views and the target to fuse 3D cues. "The Multi-view Joint Attention acts as a dynamic selective router, querying relevant view-specific geometric hints to reconstruct the target view."
- multi-view conditioning framework: A system that injects multiple views of a subject as conditions to enforce 3D consistency during generation. "by introducing a multi-view conditioning framework that mitigates the entanglement of spatial identity and temporal dynamics in video diffusion models."
- point cloud-based evaluation protocol: A 3D assessment pipeline that reconstructs point clouds from images/videos to compare geometry. "we employ a point cloud-based evaluation protocol."
- Query, Key, and Value tensors: The three sets of representations used in attention mechanisms to compute weighted combinations of values. "For each joint attention module, we produce Query, Key, and Value tensors for the subject views, conditioning views, and the text prompt."
- scaled dot-product attention: The standard attention computation that scales query–key dot products before softmax to stabilize training. "Then, we perform the standard scaled dot-product attention using those concatenated tensors ()."
- spatio-temporal attention: Attention that jointly models spatial and temporal dependencies, typical in video transformers. "process inputs via joint spatio-temporal attention."
- test-time optimization: Adapting a model to a specific instance during inference by running additional optimization, often increasing latency. "yet their reliance on test-time optimization leads to slow inference."
- Text-to-Video (T2V): Generating videos from textual prompts, potentially with subject or motion customization. "customized Text-to-Video (T2V) generation"
- unique identifier : A rare token introduced to represent and trigger generation of a specific customized subject. "a universal text prompt containing the unique identifier "
- velocity prediction loss: The diffusion training objective that predicts the velocity (a reparameterization of noise) of latent variables. "The training objective is defined by the velocity prediction loss:"
- ViCLIP: A video–text alignment model/metric used to quantify how well generated videos match prompts. "we compute a video-text alignment score using ViCLIP~\cite{wang2024internvideo2}"
- VBench: A benchmarking suite that evaluates video generation along dimensions like aesthetics, imaging quality, and motion smoothness. "we evaluate the intrinsic video quality using VBench~\cite{huang2024vbench}."
- video diffusion models: Generative models that extend diffusion processes to synthesize coherent video sequences. "With the rapid advancement of video diffusion models~\cite{videoworldsimulators2024, kong2024hunyuanvideo, wan2025wan}"
- visual adapters: Lightweight modules that inject visual features (e.g., reference images) into diffusion models to preserve identity/details. "visual adapters were introduced to directly inject reference images into the diffusion process"
- world-coordinate point clouds: 3D point sets expressed in a shared, global coordinate frame to enable direct geometric comparison. "we reconstruct unified world-coordinate point clouds from both the ground-truth multi-view images and the generated rotation videos."
Collections
Sign up for free to add this paper to one or more collections.