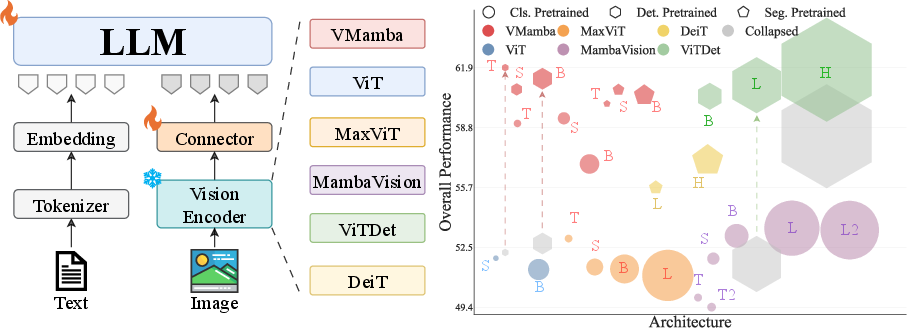
Do VLMs Need Vision Transformers? Evaluating State Space Models as Vision Encoders
Abstract: Large vision--LLMs (VLMs) often use a frozen vision backbone, whose image features are mapped into a LLM through a lightweight connector. While transformer-based encoders are the standard visual backbone, we ask whether state space model (SSM) vision backbones can be a strong alternative. We systematically evaluate SSM vision backbones for VLMs in a controlled setting. Under matched ImageNet-1K initialization, the SSM backbone achieves the strongest overall performance across both VQA and grounding/localization. We further adapt both SSM and ViT-family backbones with detection or segmentation training and find that dense-task tuning generally improves performance across families; after this adaptation, the SSM backbone remains competitive while operating at a substantially smaller model scale. We further observe that (i) higher ImageNet accuracy or larger backbones do not reliably translate into better VLM performance, and (ii) some visual backbones are unstable in localization. Based on these findings, we propose stabilization strategies that improve robustness for both backbone families and highlight SSM backbones as a strong alternative to transformer-based vision encoders in VLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple question: Do vision–LLMs (VLMs) really need Transformer-based vision encoders (like ViT), or can a different kind called state space models (SSMs) work as well—or even better? The authors test this by swapping in an SSM vision encoder, called VMamba, and comparing it to Transformer-based options in a fair, controlled way.
What questions did the researchers ask?
They focused on a few easy-to-understand questions:
- Can SSM-based vision encoders be a strong alternative to Transformers in VLMs?
- Does making a vision encoder bigger or better on ImageNet automatically make a better VLM?
- Does training the vision encoder for “dense” tasks (like detection or segmentation that care about exact locations) help the VLM understand and point to things in images?
- Why do some VLM setups suddenly get bad at pointing to things (a problem they call “localization collapse”), and how can we fix it?
How did they study it? (Explained simply)
Think of a VLM like a team:
- The “vision encoder” is the teammate who looks at a picture and turns it into a set of compact signals (like notes).
- A small “connector” is the adapter that translates those signals into a format the LLM understands.
- The “LLM” (LLM) is the teammate that reads the translated signals and writes the answer.
The researchers:
- Froze the vision encoder (so its “eyes” stay the same for fairness) and trained only the connector and the LLM. This makes comparisons fair and avoids mixing up training tricks with architecture differences.
- Swapped different vision encoders into the same VLM setup—some Transformers (like ViT and MaxViT), some hybrids, and an SSM (VMamba).
- Tested two kinds of abilities:
- Answering questions about images (like “What color is the car?”), called VQA.
- Finding/pointing to things in images (like “Where is the red ball?”), called localization or grounding.
- Tried different ways of pretraining the vision encoders:
- Image classification (recognizing what’s in a picture).
- Dense tasks like detection or segmentation (finding exactly where things are).
- Investigated why some models failed to point to things reliably and tested simple fixes:
- Making the connector bigger (more capacity to “translate”).
- Changing the input image shape (e.g., using square images) to make the interface more stable.
Simple analogy:
- Transformers are like a group chat where every patch of the image talks to every other patch at once.
- SSMs are like walking up, down, left, and right across the image grid, passing information along the way. This can help keep track of where things are in the picture (spatial details).
What did they find?
Here are the highlights, with why they matter:
- SSMs are strong, especially for pointing to things:
- In strictly fair tests (same training, same image size, same number of tokens), the SSM vision encoder (VMamba) did best overall and was especially good at grounding/localizing objects.
- Why it matters: Being able to point to “where” something is often helps VLMs answer questions more accurately.
- Bigger or “better on ImageNet” does not guarantee a better VLM:
- Simply using a larger vision encoder or one that scores higher on ImageNet did not reliably improve the VLM. Sometimes it made things worse.
- Why it matters: Model size and ImageNet top-1 accuracy are not good shortcuts for picking the best VLM backbone.
- Training the vision encoder on dense tasks usually helps—especially segmentation:
- Adapting encoders with detection or segmentation training often boosted both VQA and localization, across both SSMs and Transformers.
- Segmentation training tended to be more stable; detection sometimes caused big drops in localization (localization collapse).
- Why it matters: If you need precise spatial understanding, pretraining on tasks that care about “where” (not just “what”) makes sense.
- Some failures are not the vision encoder’s fault—they’re interface problems:
- In some cases, localization suddenly collapsed after detection-style adaptation. The authors found two simple stabilizers:
- Use a stronger connector (a deeper “adapter” between vision and language).
- Use square input images (e.g., 512×512) instead of very wide/tall ones.
- These fixes often recovered (and sometimes improved) localization and VQA.
- Why it matters: If your VLM struggles to point to things, you might not need a new backbone—you may just need a better “plug” (connector) or more stable input image geometry.
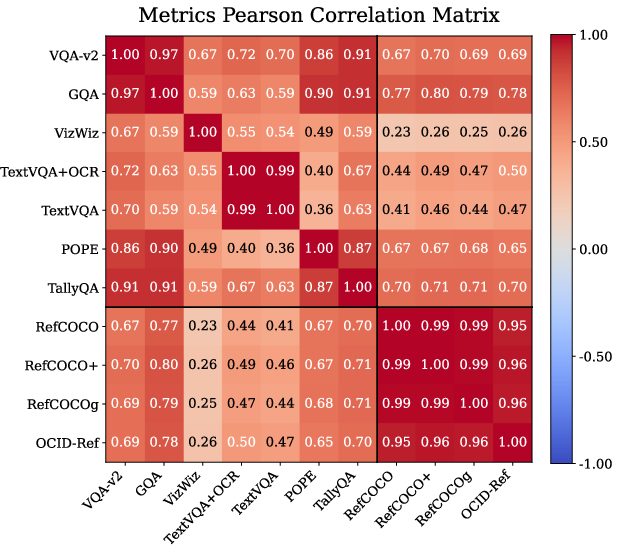
- Localization and VQA are linked:
- Benchmarks that test grounding (pointing to the right place) correlate with better performance on general visual question answering.
- Why it matters: Teaching models to use spatial details tends to improve overall understanding.
Why this matters and what’s next
- For builders of VLMs:
- You don’t have to stick to Transformer vision encoders. SSMs (like VMamba) are a strong alternative, often at smaller model sizes.
- Don’t assume “bigger is better” or “higher ImageNet accuracy means better VLMs.”
- If your model struggles with grounding, try:
- Pretraining the vision encoder on dense tasks (especially segmentation).
- Increasing connector capacity.
- Using square, stable image resolutions.
- For future research:
- Explore more SSM-based vision encoders and better vision–language interfaces.
- Develop pretraining strategies that strengthen spatial understanding without fragile behavior.
- Study how to keep spatial information intact when passing from vision to language.
In short: The paper shows that SSM vision encoders can match or beat standard Transformers in VLMs—especially for tasks that require knowing where things are—and offers simple, practical tips to make VLMs more stable and accurate.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list consolidates the key uncertainties and unexplored areas left by the paper. Each point is framed to be specific and actionable for follow-up research.
- Frozen-encoder restriction: Effects of end-to-end or partial (e.g., LoRA/adapters) finetuning of SSM vs Transformer vision backbones on both performance and stability remain untested.
- Single LLM dependence: Generality of findings beyond Vicuna-7B (e.g., different sizes, families, and tokenizer geometries) is unknown.
- Narrow connector design: Only shallow MLP connectors are explored; performance/stability impacts of alternative interfaces (cross-attention, Q-Former/Perceiver-style, gated/residual connectors, normalization choices) are unstudied.
- Limited pretraining regimes: Lack of SSM backbones trained with contrastive/SSL vision pretraining (e.g., CLIP, SigLIP, DINOv2) prevents fair comparison against strong Transformer pipelines; feasibility and impact of CLIP-style SSM pretraining is open.
- Data scale and diversity: Effects of larger/alternative pretraining datasets (IN-21k, JFT, OpenImages) and larger/varied instruction-tuning corpora on SSM vs ViT parity remain unexplored.
- Token budget vs resolution trade-offs: Systematic scaling curves over visual token count L, input resolution, and compute are missing, especially for SSMs that may encode spatial detail differently.
- Multi-scale feature usage: The study extracts a single stage for matched L; potential gains from multi-scale pyramids or FPN-style fusion into the LLM are not evaluated for SSMs or ViTs.
- Geometry sensitivity: The “square vs non-square” stabilization is promising but ad hoc; no systematic sweep over aspect ratios, padding strategies (letterbox vs crop), positional embeddings, or positional encoding injection into the LLM is provided.
- Collapse causality: Localization collapse is attributed to “transmission vs utilization bottlenecks,” but causal factors are not isolated (e.g., connector capacity vs LLM token utilization vs positional encoding schemes).
- Connector capacity ablations: Only 2- vs 3-layer MLPs are compared; the effect of connector width, depth, residual pathways, normalization, and positional/coordinate encoding on stability and localization is uncharted.
- Vision-to-language positional alignment: Whether injecting explicit 2D positional signals (relative/rotary/coord embeddings) into the connector or LLM mitigates collapse is untested.
- Generality across SSM variants: Claims rely mainly on VMamba; broader coverage of SSM architectures (e.g., 2D-Mamba variants, S4ND, Hyena-based state spaces, different scan patterns/kernels) is missing.
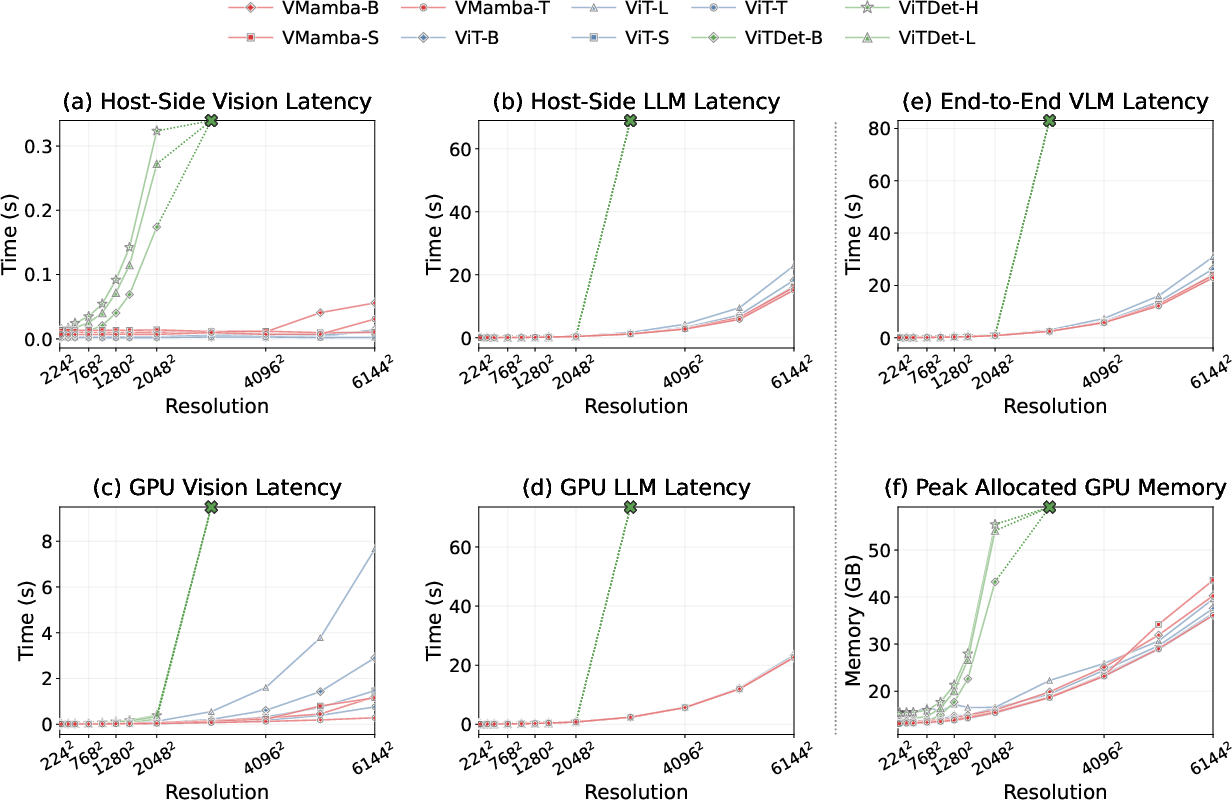
- Compute and efficiency: End-to-end latency, memory, and throughput comparisons of SSM vs Transformer encoders within VLMs (for fixed accuracy and token budgets) are not reported.
- Robustness and OOD generalization: Sensitivity to distribution shifts, occlusions, small objects, clutter, adversarial perturbations, and data corruptions is not assessed.
- Task breadth: Evaluation focuses on VQA and referring expression localization; open-vocabulary detection/segmentation, phrase grounding segmentation, region-to-text/text-to-region retrieval, and compositional reasoning benchmarks are not covered.
- OCR/text-centric performance: TextVQA improvements are limited and correlations are weak; whether SSMs help document understanding (DocVQA, ST-VQA) or benefit from text-specific augmentations remains open.
- Error diagnostics: No fine-grained error analysis of localization (e.g., by target size, occlusion, attribute complexity, spatial relations) to guide where SSMs help/hurt.
- Scale laws and regularization: The observed degradation when scaling backbones lacks a remedy; roles of regularization (e.g., augmentation, mixup, weight decay), sparsity, or architectural constraints to prevent “classification objective overfitting” in large models are untested.
- Alternative preprocessing: Impact of different resize/crop/tiling strategies, patch sizes, and overlapping/strided tokenization on spatial fidelity and stability is unstudied.
- Visual token utilization by the LLM: How LLM attention attends to spatial tokens across layers (and how this differs for SSM vs ViT) is not instrumented or quantified.
- Fair dense-objective comparisons: Detection/segmentation-adapted experiments confound architecture with token count and geometry; matched-L and matched-geometry comparisons are needed to isolate objective effects.
- Partial finetuning for stability: Whether lightly unfreezing top layers of the vision encoder, or adding visual adapters during instruction tuning, prevents collapse without losing control is unknown.
- Multi-scale or region-token interfaces: Injecting region proposals, bounding-box tokens, or multi-level features into the LLM (vs flat grids) could improve grounding; untested for SSMs.
- LLM-size dependence: How backbone–LLM pairings (e.g., 3B vs 7B vs 13B+) change reliance on vision encoder quality and collapse propensity is unexplored.
- Statistical confidence: All results use a fixed seed; variance across seeds and confidence intervals are absent, limiting claims about robustness of the observed trends.
- Video and temporal extension: Whether SSMs’ sequential inductive biases yield larger gains in video VLMs or multi-image reasoning is unexplored.
- Comparison to strong CNNs: Modern convolutional backbones (e.g., ConvNeXtV2) are not included; SSM advantages over CNN inductive biases in VLMs remain unquantified.
- Hallucination beyond POPE: Broader faithfulness and grounding-hallucination metrics (e.g., Object HalBench, GRIT) are not used to validate whether SSMs reduce hallucination.
- Token compression/pruning: Whether SSMs enable more aggressive token pruning or learned token selection without hurting localization is untested.
- Reproducibility of stabilizations: Generality of the proposed stabilizations across datasets, LLMs, and other backbones (beyond tested cases) is not demonstrated.
Practical Applications
Immediate Applications
The following use cases can be deployed now using the paper’s findings on SSM vision backbones (e.g., VMamba), dense-task adaptation, and stabilization strategies (connector capacity and input geometry) within LLaVA-style VLMs.
- Drop-in SSM backbone swap to boost grounding in VLMs
- Sector: software, robotics, retail, media
- Workflow: Replace ViT-family encoders with VMamba-T/S in existing frozen-encoder VLMs (e.g., LLaVA/BLIP2-style) to improve spatial grounding without increasing visual token count; keep the connector + LLM fixed.
- Tools/products: “SSM Vision Encoder” option in VLM stacks; model selection dashboards emphasizing localization metrics; inference services that expose grounded answers with bounding boxes.
- Dependencies/assumptions: Availability of VMamba checkpoints (IN1K/224 or dense-task adapted); compatibility with current connector interfaces; evaluation and UX capable of showing grounded outputs.
- Build grounding-first multimodal chat features
- Sector: e-commerce, content moderation, media search, customer support
- Workflow: Enable “point-and-ask” or “find this item” features with tighter, more reliable boxes around referenced objects using VMamba-T/S at fixed token budgets; expose localization masks/boxes alongside answers.
- Tools/products: Product search with referring expressions; moderation tools highlighting localized evidence; image support assistants that annotate parts/components.
- Dependencies/assumptions: Training data covering in-domain objects/attributes; UI to display bounding boxes; compliance with user privacy.
- Stabilization toolkit for detection-pretrained backbones
- Sector: software tooling, MLOps
- Workflow: Apply two stabilizers to mitigate localization collapse in detection-adapted models: (1) increase connector depth/capacity (e.g., 3-layer MLP), (2) normalize input geometry to square (e.g., 512×512) at inference/tuning while keeping checkpoints fixed.
- Tools/products: “Geometry/Connector Stabilizer” module; automated checks that detect collapse and toggle stabilizers.
- Dependencies/assumptions: Access to connector architecture; ability to standardize image preprocessing; monitoring of localization KPIs.
- Backbone selection guidance and evaluation policy
- Sector: industry R&D, procurement, policy
- Workflow: Prioritize localization/grounding benchmarks (RefCOCO/+/g, OCID-Ref) during model selection; do not use ImageNet top-1 or backbone size as proxies for VLM quality; run correlation analyses between VQA and localization to set acceptance criteria.
- Tools/products: Procurement checklists; evaluation scripts emphasizing grounding metrics; model cards that report grounding stability.
- Dependencies/assumptions: Access to evaluation suites; organizational buy-in to adjust KPIs beyond ImageNet accuracy.
- Compute-efficient deployment on edge GPUs
- Sector: robotics, field service, manufacturing, AR devices
- Workflow: Use smaller SSM backbones (VMamba-T/S) and frozen-encoder pipelines to reduce memory/compute vs. larger ViT backbones while preserving or improving grounding; maintain token budgets to keep LLM cost stable.
- Tools/products: Edge-ready VLMs for inspection/maintenance tasks; on-device visual assistants highlighting components.
- Dependencies/assumptions: Support for FSDP or quantized inference; acceptable latency at selected resolution; robust image preprocessing.
- Accessibility-focused visual assistants
- Sector: healthcare accessibility, public services
- Workflow: Improve reliability of answers on user-captured images (e.g., VizWiz-type inputs) by leveraging SSM encoders’ better spatial selectivity; include bounding boxes to explain answers.
- Tools/products: Mobile apps for visually impaired users that localize and describe items; assistive shopping or navigation.
- Dependencies/assumptions: Responsible data handling; robustness to varied lighting/occlusion; human-centered UX validation.
- Instruction-following for desktop/mobile assistance
- Sector: productivity software, education
- Workflow: Use SSM-based VLMs to ground references in screenshots/diagrams (e.g., “Click the blue icon in the top-right”); highlight UI elements with bounding boxes.
- Tools/products: Screen-assist copilots; study tools that reference parts of figures or diagrams.
- Dependencies/assumptions: Domain-adapted instruction data; UI image capture permissions; geometry-stable preprocessing (square inputs can help).
- Content moderation with explainable localization
- Sector: social platforms, enterprise security
- Workflow: Detect and localize policy-relevant content (logos, weapons, sensitive imagery) with SSM-equipped VLMs; present localized evidence in moderation dashboards.
- Tools/products: Moderation APIs that return text + bounding boxes; triage tools for human reviewers.
- Dependencies/assumptions: Domain-specific fine-tuning for target classes; auditable logs; fairness and bias assessments.
- MLOps diagnostics: “localization collapse” detectors
- Sector: platform/tooling
- Workflow: Integrate probes (e.g., RefCOCO perf thresholds, token–region similarity visualizations) into CI pipelines; trigger connector/geometry stabilizers or rollback on collapse detection.
- Tools/products: Visualization utilities for token–region similarity; regression tests on grounding suites.
- Dependencies/assumptions: Access to intermediate model representations; standard benchmark subsets for quick checks.
- Curriculum for dense-task adaptation
- Sector: ML engineering, academia
- Workflow: Prefer segmentation-style adaptation for stable gains; use detection pretraining with caution and stabilizers; tune resolutions and extraction stages to balance tokens and stability.
- Tools/products: Prescribed pretraining menus (IN1K → ADE20K segmentation preferred; IN1K → COCO detection with stabilizers); staged training pipelines.
- Dependencies/assumptions: Availability of dense-task checkpoints; consistent feature extraction settings across stages.
Long-Term Applications
These opportunities require additional research, domain adaptation, scaling, or standardization beyond the current paper’s scope.
- SSM-based contrastive/SSL pretraining (CLIP/DINOv2 equivalents)
- Sector: software, foundation models
- Workflow: Develop SSM vision encoders with contrastive/SSL pretraining to unlock further VLM gains, particularly for zero-shot tasks and robust generalization.
- Tools/products: “SSM-CLIP” backbones; multi-objective pretraining pipelines.
- Dependencies/assumptions: Large-scale image–text or vision-only corpora; stable training methods for SSMs at scale.
- Standardized vision–language interfaces for robustness
- Sector: policy, standards, industry consortia
- Workflow: Establish guidelines for input geometry, token budgets, connector capacity, and benchmarking of grounding stability; include tests for “collapse” in certification.
- Tools/products: Interop standards; model audit kits; certification regimes for grounding reliability.
- Dependencies/assumptions: Cross-organization collaboration; regulator and industry adoption.
- Domain-specialized grounded VLMs
- Sector: healthcare, manufacturing, geospatial, scientific imaging
- Workflow: Adapt SSM-based VLMs with dense-task pretraining on domain data (e.g., medical segmentation, defect detection) to deliver grounded assistance and decision support.
- Tools/products: Radiology report assist with localized findings; factory QA tools that localize defects; satellite imagery assistants.
- Dependencies/assumptions: Access to labeled domain data; regulatory approval (e.g., medical); rigorous validation and bias assessments.
- Real-time embodied agents with grounded language
- Sector: robotics, logistics, home automation
- Workflow: Integrate SSM-based VLM perception with planners and control stacks for instruction following that depends on precise, low-latency localization (e.g., “pick the red cup on the left shelf”).
- Tools/products: Manipulation pipelines; warehouse picking systems; home robots with on-device grounded perception.
- Dependencies/assumptions: Real-time inference on constrained hardware; robust multi-view/3D grounding; safety and reliability engineering.
- AR/VR assistants with on-device grounded guidance
- Sector: consumer electronics, training/simulation
- Workflow: Provide step-by-step guidance that anchors instructions to objects/regions in the user’s view (assembly, maintenance, education).
- Tools/products: AR overlays with localized highlights; tutorial systems that “point” to parts.
- Dependencies/assumptions: Efficient on-device models; low-latency video processing; privacy-preserving pipelines.
- Energy- and cost-aware deployment policies
- Sector: policy, sustainability, enterprise IT
- Workflow: Update procurement and sustainability policies to account for smaller, grounding-strong SSM backbones that reduce compute and carbon while meeting task KPIs.
- Tools/products: Green AI scorecards; TCO calculators incorporating grounding performance.
- Dependencies/assumptions: Transparent reporting of energy use; standardized benchmarks to avoid overfitting to ImageNet-like metrics.
- Adaptive tokenization and connector learning
- Sector: foundation model research
- Workflow: Research dynamic token selection or spatially-aware connectors that preserve critical spatial cues while minimizing token count; combine with SSM inductive biases.
- Tools/products: Token-pruning modules; spatial adapters.
- Dependencies/assumptions: Training recipes for stable joint optimization; robust evaluation of trade-offs.
- Safety and explainability frameworks for grounded AI
- Sector: regulation, enterprise risk
- Workflow: Use localized evidence (boxes/masks) to audit model decisions; require grounding-based explanations for high-stakes uses (e.g., QA of vision-language outputs).
- Tools/products: Explanation UIs that overlay evidence; audit logs linking answers to regions.
- Dependencies/assumptions: Agreement on acceptable explanation quality; human factors research on interpretable overlays.
- Education and STEM aides that ground references in visuals
- Sector: education technology
- Workflow: Interactive tutors that precisely reference parts of diagrams, charts, and lab apparatus; reduce ambiguity in visual instruction.
- Tools/products: Classroom tools for figure comprehension; auto-graded assignments that verify grounded responses.
- Dependencies/assumptions: High-quality curriculum-aligned data; robust handling of diverse visual styles.
- Cross-modal dataset design emphasizing localization
- Sector: academia, dataset curation
- Workflow: Construct multimodal corpora and benchmarks that jointly test VQA and localization; encourage training that rewards spatial fidelity.
- Tools/products: New grounding-rich instruction datasets; public leaderboards separating VQA vs. localization.
- Dependencies/assumptions: Annotation budgets for grounding; community consensus on task definitions.
- Multi-resolution and aspect-ratio robust VLMs
- Sector: research, deployment
- Workflow: Develop methods that make grounding robust to diverse image geometries (non-square, panoramic, tall/skinny), reducing the need for geometry-specific stabilizers.
- Tools/products: Geometry-robust encoders; learned positional schemes compatible with SSMs.
- Dependencies/assumptions: Training regimes covering varied geometries; careful connector/interface design.
Notes on feasibility across applications:
- The paper’s strongest evidence is for improved localization under frozen-encoder, LLaVA-style pipelines using VMamba; translating to different LLMs/connectors may require light adaptation.
- Dense-task pretraining improves localization but can induce instability for detection-adapted models; stabilization (connector capacity, square inputs) mitigates collapse.
- Gains were shown on natural-image tasks; domain transfer requires additional data and adaptation.
- Improvements often do not correlate with ImageNet top-1 or scale; evaluation must include localization-heavy benchmarks to ensure real-world readiness.
Glossary
- 2D-Selective-Scan (SS2D): A VMamba scanning mechanism that aggregates information along multiple directions on a 2D token grid to build spatially aware features. "2D-Selective-Scan (SS2D) design"
- ADE20K: A widely used semantic segmentation dataset for dense prediction pretraining and evaluation. "ADE20K"
- CLIP: A contrastive image–text pretraining model that learns aligned visual and textual representations. "CLIP"
- COCO: Common Objects in Context; a large-scale dataset for detection and segmentation used for dense-task adaptation. "COCO"
- contrastive-pretrained backbones: Vision encoders trained with contrastive objectives (often on image–text pairs) to align modalities. "contrastive-pretrained backbones"
- connector: A lightweight mapping module that projects vision features into the LLM’s embedding space. "lightweight connector"
- decoder-only LLM: An autoregressive LLM architecture that generates outputs without an encoder module. "a decoder-only LLM (Vicuna-7B)"
- DeiT: Data-efficient Image Transformers; a ViT variant trained with knowledge distillation and used here with adapters for dense tasks. "DeiT"
- dense prediction tasks: Vision tasks requiring structured, per-pixel or region outputs (e.g., detection, segmentation). "dense prediction tasks"
- DINOv2: A self-supervised vision model used as a strong pretraining baseline. "DINOv2"
- feature pyramid: A multi-scale feature hierarchy used in detection to capture objects at different sizes. "a simple feature pyramid from a single-scale feature map"
- Fully Sharded Data Parallel (FSDP): A distributed training technique that shards model parameters, gradients, and optimizer states across devices. "Fully Sharded Data Parallel (FSDP)"
- GELU: Gaussian Error Linear Unit; a smooth activation function commonly used in transformers and connectors. "GELU"
- GQA: A visual question answering dataset grounded in scene graphs, assessing compositional reasoning and grounding. "GQA"
- grounding/localization: The task of identifying and localizing image regions that correspond to textual references. "grounding/localization"
- ImageNet-1K (IN1K): A 1,000-class image classification dataset used for supervised pretraining. "ImageNet-1K (IN1K)"
- inductive biases: Architectural tendencies that push models toward certain solution classes (e.g., locality in vision). "inductive biases"
- instruction tuning: Fine-tuning on instruction–response pairs to enable open-ended, instruction-following behavior. "instruction tuning"
- LLM: A high-capacity generative LLM used to process and produce text in VLMs. "LLM"
- letterbox resizing: Image preprocessing that preserves aspect ratio by scaling and padding to a target resolution. "letterbox resizing"
- LLaVA: A popular VLM framework design where visual tokens are fed to an LLM via a connector for instruction tuning. "LLaVA-style VLM"
- linear probing: Evaluating representation quality by training a linear classifier on frozen features. "linear probing"
- localization collapse: A failure mode where grounding performance drops sharply after certain adaptations. "localization collapse"
- MambaVision: A hybrid Mamba–Transformer vision backbone retaining self-attention in final layers for long-range dependencies. "MambaVision"
- MaxViT: A hierarchical hybrid vision architecture combining convolutions with blocked local and dilated global attention. "MaxViT"
- multi-axis attention: Attention that operates over different axes (e.g., local and global) to capture varied spatial interactions. "multi-axis attention (blocked local and dilated global attention)"
- multi-directional scans: Processing sequences by scanning in multiple directions across the 2D grid to propagate spatial context. "multi-directional scans over the 2D grid"
- OCID-Ref: A referring expression grounding dataset with cluttered scenes, used to evaluate localization. "OCID-Ref"
- Pearson correlation matrix: A matrix of Pearson r values summarizing correlations among metrics across model runs. "Pearson correlation matrix"
- permutation-invariant: A property of vanilla transformers where token order does not affect computation without positional encodings. "permutation-invariant"
- positional encodings: Additive vectors that inject position information into transformer token embeddings. "positional encodings"
- RefCOCO: A benchmark for referring expression comprehension, requiring localizing objects from text. "RefCOCO"
- RefCOCO+: A variant of RefCOCO with fewer location words, emphasizing appearance-based grounding. "RefCOCO+"
- RefCOCOg: A version of RefCOCO with longer, more descriptive expressions for grounding. "RefCOCOg"
- segmentation adaptation: Using segmentation-pretrained backbones as vision encoders to enhance spatial fidelity in VLMs. "segmentation adaptation yields more consistently strong localization"
- self-attention: A mechanism in transformers enabling tokens to attend to each other globally. "global self-attention"
- SigLIP: A contrastive image–text pretraining model similar to CLIP, used as a baseline in prior work. "SigLIP"
- SS4D layer: A VMamba layer that aggregates state-space updates along four scan directions on the 2D grid. "SS4D layer"
- state space model (SSM): A modeling paradigm using state-space updates to process sequences or images with structured dynamics. "state space model (SSM) vision backbones"
- token budget: The fixed limit on the number of visual (and text) tokens processed by the model. "multimodal token budget"
- Token--region similarity: A visualization of alignment between visual tokens and text tokens over image regions. "Token--region similarity"
- transmission bottleneck: Failures due to insufficient connector capacity to convey spatial information into the LLM. "Transmission bottleneck"
- utilization bottleneck: Failures where the LLM does not effectively use spatial cues even if transmitted. "Utilization bottleneck"
- ViT: Vision Transformer; a backbone that tokenizes images into patches and uses global self-attention. "ViT"
- ViT-Adapter: A framework adding adapters to ViT to inject inductive biases for dense prediction without pretraining the adapter. "ViT-Adapter framework"
- ViTDet: A ViT adapted for object detection, demonstrating strong detection after dense-task fine-tuning. "ViTDet"
- Vicuna-7B: A 7-billion-parameter decoder-only LLM used as the language component in experiments. "Vicuna-7B"
- VMamba: An SSM-based vision backbone using selective scans to preserve spatial structure. "VMamba"
- visual tokens: The sequence of embeddings produced by the vision encoder from an input image. "visual tokens"
- VizWiz: A VQA dataset featuring real-world images captured by blind users, emphasizing robustness. "VizWiz"
- VLMs: Vision–LLMs that combine vision encoders and LLMs for multimodal tasks. "vision--LLMs (VLMs)"
- VQA-v2: A widely used visual question answering benchmark evaluating open-ended QA over images. "VQA-v2"
Collections
Sign up for free to add this paper to one or more collections.

