On the Ability of Transformers to Verify Plans
Abstract: Transformers have shown inconsistent success in AI planning tasks, and theoretical understanding of when generalization should be expected has been limited. We take important steps towards addressing this gap by analyzing the ability of decoder-only models to verify whether a given plan correctly solves a given planning instance. To analyse the general setting where the number of objects -- and thus the effective input alphabet -- grows at test time, we introduce C*-RASP, an extension of C-RASP designed to establish length generalization guarantees for transformers under the simultaneous growth in sequence length and vocabulary size. Our results identify a large class of classical planning domains for which transformers can provably learn to verify long plans, and structural properties that significantly affects the learnability of length generalizable solutions. Empirical experiments corroborate our theory.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but important question: can today’s transformer models (the kind used in LLMs) reliably check whether a step‑by‑step plan will actually work? Think of a plan like a recipe: you start with some ingredients (the initial state), apply a sequence of steps (actions), and hope to end with a finished dish (the goal). The paper studies whether transformers can learn to “verify” such plans, especially when plans get longer and when there are more objects involved than the model saw during training.
What the researchers wanted to find out
They focused on two easy-to-understand questions:
- If we teach a transformer to check short plans, will it keep doing well on longer plans?
- Will this still be true when the new plans include more objects (like more rooms or items) than the model ever saw before?
They explored these questions for different kinds of planning problems:
- Delete‑free: actions only add facts; they never remove anything (like only putting items into a bag, never taking anything out).
- Well‑formed: every action actually changes something when used (no “do-nothing” steps).
- STRIPS (standard planning): actions can both add and delete facts; some actions might do nothing if their effects don’t apply.
- Conditional effects: an action can cause different effects depending on the situation (like “if it’s raining, the ground gets wet; otherwise nothing happens”).
How they studied it
The big idea in everyday terms
- Plan verification: Given a start, a list of steps, and a goal, decide if following those steps from the start reaches the goal.
- Length generalization: Train on short plans, then test on longer ones.
- Two test worlds:
- Fixed universe: the set of objects (like rooms, balls, robots) stays the same between training and testing.
- Variable universe: tests can include more objects than the model saw during training.
A simple “programming language” for what transformers can do
To reason about what transformers can learn, the authors use a math/modeling tool called C‑RASP (and a known subset called Pos). You can think of C‑RASP/Pos as a simple “pseudo‑code” for the kinds of counting and pattern‑matching transformers are good at when they generalize to longer inputs.
But C‑RASP assumes the set of possible tokens (like all possible object names) doesn’t grow. That’s a problem in planning, where test cases may include more objects than ever seen before.
So the authors introduce an extension they call C*‑RASP, plus a related idea called a Symbolic Limit Transformer:
- C*‑RASP adds a careful, identity‑agnostic way to match “this object here is the same as that object there” without memorizing specific names. It’s like checking “the ball in step 3 is the same ball in step 5,” even if it’s a brand‑new name.
- Symbolic Limit Transformers formalize the idea that the model is learning an algorithm that doesn’t depend on exact positions or specific object IDs but only on local patterns and relationships. Two key principles:
- Translation invariance: the model’s “algorithm” shouldn’t depend on absolute positions or exact IDs—only on relative relationships.
- Locality: the model should rely on local context (nearby tokens), not far‑away details.
They show that if a task can be written in C*‑RASP, then (under a reasonable training setup that encourages invariance and locality) a transformer can learn an algorithm that generalizes to longer plans and more objects.
A quick note on “hard” patterns
Some pattern families are known to be tough for transformers to length‑generalize on (like “flip‑flop” toggling and “parity” checking—deciding if a count is odd or even). The authors connect certain planning setups to these hard patterns, predicting poor generalization there.
What they found and why it matters
Fixed universe (same objects at train and test)
- Delete‑free and well‑formed plan verification are learnable in a way that should generalize to longer plans. Intuition:
- Delete‑free: you can just count additions—if something is ever added (or starts true), it stays true.
- Well‑formed: each action truly flips a fact from false to true or true to false, so keeping track by counting applies/changes works.
- Some STRIPS domains are not learnable in a way that generalizes. Why? Because deciding if something is true may require finding the last action that actually changed it—a “flip‑flop” pattern transformers struggle to length‑generalize on.
- With conditional effects, it can get even harder—some cases boil down to “parity” (odd/even toggles), another known hard pattern for transformers to generalize on.
Variable universe (more objects at test time)
- With their new C*‑RASP framework, the authors show that:
- Delete‑free and well‑formed plan verification still look good: the model can generalize both to longer plans and to more objects than seen in training.
- Some STRIPS setups and conditional‑effect setups remain hard—they sometimes contain the same “flip‑flop” or “parity” patterns, so generalization is not expected.
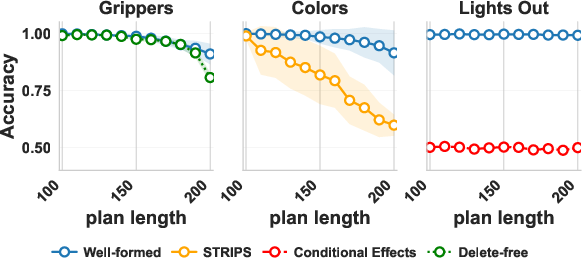
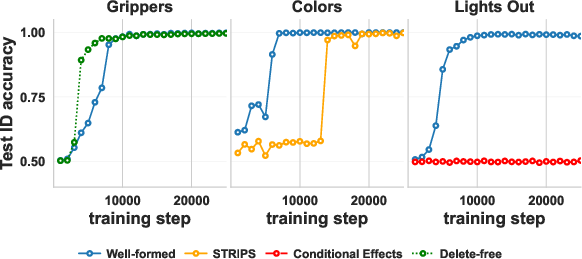
Experiments that back up the theory
They trained a GPT‑2‑style transformer to read inputs of the form: <init> initial state; <plan> actions; <goal> desired state; and to output a verdict: “correct” or “incorrect.”
They tested three toy worlds that behave like puzzles:
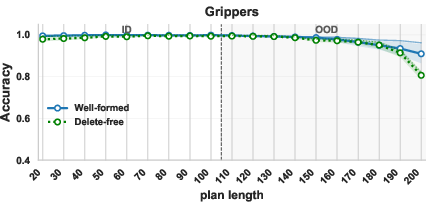
- Heavy Grippers: a robot moves balls between rooms using grippers. They tried well‑formed and delete‑free versions.
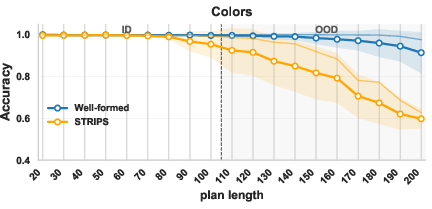
- Colors: add/remove colored balls from bags. They tried a well‑formed version and a standard STRIPS version.
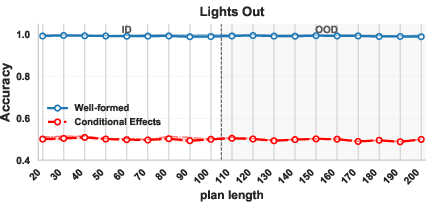
- Lights Out: a grid of lights that toggle in patterns. They tried a well‑formed version and a conditional‑effects version.
Results matched the theory:
- Well‑formed and delete‑free versions generalized well to longer plans (and in Heavy Grippers/Colors, to more objects).
- The STRIPS version of Colors got worse as plans grew.
- The conditional‑effects Lights Out version stayed near chance even when the number of objects stayed fixed.
What this means in practice
- Structure matters more than size. Whether transformers can learn to verify plans isn’t just about how many steps or objects there are; it’s about how the actions behave.
- If you can write or “compile” your planning problem into a well‑formed or delete‑free version, transformers are much more likely to learn and generalize.
- The new C*‑RASP framework and Symbolic Limit Transformers are useful beyond planning. They help us reason about transformers in any task where inputs get longer and the set of “things” (like object IDs) grows. This could guide better training setups and data formats that encourage true generalization.
In short
- Goal: test if transformers can check whether plans work, even when plans get longer and involve more objects.
- Method: analyze what transformers can, in principle, learn using simple “pseudo‑code” frameworks (C‑RASP, Pos), extend it to growing vocabularies (C*‑RASP), and verify with experiments.
- Main result: If actions never delete facts (delete‑free) or always change the state when applied (well‑formed), transformers can learn to verify plans and generalize. In more general settings (some STRIPS, conditional effects), they often can’t, because the problem hides patterns known to be hard for length generalization.
- Impact: Designing and formatting planning tasks with the right structure can make transformers reliable plan checkers, and the new theory helps predict when that will work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, structured to guide future research.
- Bridging idealized learning theory to practice:
- The generalization guarantees rely on an idealized inference procedure (exact matching on all length- inputs, finite-precision hypothesis class, explicit locality regularization, enforced translation invariance). It is unclear when standard training with SGD, finite data, and common regularizers converges to the same Symbolic Limit Transformer.
- Conditions (data distributions, model sizes, optimization settings) under which SGD recovers the “simplest local algorithm” remain uncharacterized.
- Positional encodings not covered:
- Theory and experiments consider APE/NoPE only; widely used alternatives (RoPE, ALiBi, relative encodings) are not analyzed. Does the proposed framework and guarantees extend to these encodings?
- Lack of formal sample-complexity bounds:
- Theorems provide asymptotic guarantees but do not yield quantitative training-length or data-size requirements (e.g., thresholds ) for practical models. How do data amount, model depth, and precision trade off to achieve length generalization?
- Limited scope of planning formalisms:
- Results are for propositional STRIPS and conditional effects; extensions to richer PDDL features (numeric fluents, temporal/durative actions, quantified/derived predicates, preferences) are not analyzed.
- No treatment of partially observable settings or stochastic actions.
- Plan generation versus verification:
- Only plan verification is studied; whether analogous guarantees or structural conditions exist for plan generation (PSPACE-complete) is open. Can similar positive/negative results be obtained for search-guided decoding or policy learning?
- Sufficiency but not necessity of structural conditions:
- Well-formedness and delete-free are shown sufficient for learnability; a broader structural taxonomy ensuring membership in the new class is missing (e.g., acyclic causal graphs, monotone transitions, invertibility constraints, bounded toggle depth).
- Conversely, necessary-and-sufficient characterizations beyond reductions to PARITY/FlipFlop for general STRIPS remain open.
- Compilation to well-formed domains:
- The paper demonstrates a manual compilation of Lights Out with conditional effects to a well-formed variant, but does not provide a general compilation framework or cost analysis. When can arbitrary domains be compiled into well-formed ones without blowing up plan length/action sets?
- Variable-universe generalization beyond toy domains:
- Empirical validation covers three synthetic domains; broader testing on standard IPC benchmarks (with growing object sets) is missing. Does the predicted success/failure pattern hold at larger scales and across diverse domains?
- Practical enforcement of invariance/locality:
- The proposed “offset trick” for both positions and object IDs is described but not empirically ablated. To what extent do such offsets, architectural constraints, or regularizers improve OOD generalization in practice?
- Encoding and input formatting sensitivity:
- The framework presumes that relevant argument/object identifiers appear in local neighborhoods so the match predicate can operate. The impact of alternative linearizations (e.g., different delimiters, orderings, or interleavings of , , ) on learnability is not analyzed.
- Tokenization and open-vocabulary objects:
- How subword tokenization, multi-token object identifiers, or unseen string formats affect the match predicate’s efficacy and invariance to object identity is not explored.
- Depth/width requirements and capacity guarantees:
- Unlike recent work that links task difficulty to model depth, the paper does not provide depth/width lower bounds needed to implement the required counting/matching computations for specific domains.
- Average-case versus worst-case hardness:
- Negative results are by reduction to worst-case languages (PARITY/FlipFlop). Are there average-case distributions over STRIPS domains/instances where transformers generalize despite worst-case hardness?
- Separation of failure modes:
- Verification admits two failure types (non-executable vs incomplete). The paper does not disentangle their relative learnability or characterize which component (precondition checking vs goal satisfaction) drives OOD failure.
- Effects of scratchpads and tool use:
- Chain-of-thought, scratchpads, or external memory (e.g., state tracking traces) are not analyzed. Can such aids overcome negative results for STRIPS/conditional effects?
- Robustness and noise tolerance:
- Sensitivity to token-level noise, spurious delimiters, or distribution shifts in plan/action statistics is not assessed. How robust are learned verifiers to small input corruptions or adversarial perturbations?
- Context-length and scaling constraints:
- Theoretical analysis assumes arbitrarily long contexts; practical models have finite windows. How do chunking, recurrence, or memory-augmented architectures interact with the guarantees?
- Cross-domain generalization:
- Whether a single model can learn domain-agnostic verification (fixed predicate/action vocabularies across multiple domains) is untested. How does the framework extend to multi-domain training with shared ?
- Beyond binary validity:
- Verifying plan optimality, minimality, or cost feasibility is not studied. Do these problems admit membership in the proposed class, or do they inherit hardness akin to PARITY/FlipFlop reductions?
- Extension of the match predicate:
- The match predicate enforces local equality relationships with fixed offsets. Tasks requiring long-range object matching, aliasing resolution, or multi-step reference chains may exceed this expressivity. Can the predicate be safely extended without breaking locality guarantees?
- Quantitative link to empirical thresholds:
- Although Theorem statements imply an , the experiments do not probe where empirical thresholds lie (e.g., minimal training length for given OOD target lengths). Calibrating theory to practice remains open.
- Alternative architectures and baselines:
- No comparison with specialized neuro-symbolic or GNN-based plan verifiers. Are the positive/negative boundaries specific to transformers, or do they hold more broadly?
- Dataset generation coverage:
- Invalid plans are produced via a small set of perturbations (incomplete/non-executable). Broader invalidity patterns (e.g., subtle state aliasing, repeated toggling artifacts, redundant action sequences) are not explored.
- Handling of derived/implicit constraints:
- While acknowledging implicit state constraints in benchmarks, the impact of such invariants on well-formedness detection and verification complexity is not formally studied.
- Naming/notation and replicability of the new formalism:
- The extended -RASP variant is introduced abstractly (with a match predicate and split alphabet) but lacks a complete, standardized specification and tooling for program synthesis or verification on real inputs.
- Empirical use of invariance tricks on objects:
- It is not stated whether object-ID offsets were actually applied during training. Ablating and quantifying their effect on variable-universe generalization is an open empirical gap.
- Partial verification tasks:
- The learnability of subproblems (e.g., only precondition checking, only goal verification, state reconstruction from a plan) is not separately assessed; these may have different generalization profiles.
Practical Applications
Immediate Applications
Below are concrete ways to use the paper’s results right now, organized by sector. Each item notes assumptions/dependencies that affect feasibility.
Robotics, Manufacturing, Logistics
- Plan-verification guardrail for robot/agent execution (Immediate Application)
- What: Use a decoder-only transformer as a fast, learned verifier that checks whether a proposed action sequence (plan) is executable and reaches the goal before sending it to robots/agents.
- Where it fits: Warehouse picking, AMRs/AGVs routing, assembly lines, fulfillment centers.
- Why it works: The paper proves length-generalization for verification in well-formed and delete-free domains; many industrial workflows can be modeled to satisfy these properties or compiled to do so.
- Tools/workflows that could emerge:
- PlanGuard: an API service that validates action sequences; rejects plans that violate preconditions/goals; routes rejections to a classical planner or human.
- A build-time “domain checker” that flags whether a PDDL domain instance is well-formed/delete-free and recommends edits.
- Assumptions/dependencies:
- Domain is well-formed or delete-free (or compiled to be so).
- Uses absolute/no positional encodings with the offset-training trick to enforce translation invariance over positions and object IDs.
- Verification only (does not cover plan generation guarantees).
Software Engineering and Agent Frameworks
- Safety filter for tool-use and agentic LLMs (Immediate Application)
- What: Before executing multi-tool workflows (e.g., file edits, DB migrations, CI/CD runbooks), the agent submits a plan to a verifier model trained per the paper’s recipe.
- Sectors: Software automation, RPA, DevOps, MLOps.
- Tools/workflows:
- LangChain/LlamaIndex integration: a “VerifyPlan” node called before action execution.
- CI pipelines: verify step sequences (migrations → tests → deploy) modeled as delete-free (only “adds” progress flags) so the verifier length-generalizes.
- Assumptions/dependencies:
- Model inputs separate symbols (actions/predicates) from object identifiers.
- Domains refactored to avoid conditional effects or compiled into well-formed variants.
Operations Research and Scheduling
- Fast verification for long procedural checklists (Immediate Application)
- What: Encode checklists as delete-free plans (only mark progress flags true); use the transformer to verify long sequences reliably.
- Sectors: Field maintenance, airline/rail ops, compliance operations.
- Assumptions/dependencies:
- Reformulate tasks as monotone progress (delete-free) checklists.
- Goals expressed as “all required flags true.”
Healthcare Administration and Clinical Operations
- Verification of care-pathway and order-set sequences (Immediate Application)
- What: Verify that a proposed sequence of orders/interventions is executable (preconditions satisfied) and reaches target clinical goals.
- How to model: Treat care progression as well-formed (every action must change state) or delete-free (only add achieved milestones).
- Assumptions/dependencies:
- Domain modeling with strict preconditions so no-ops are disallowed (well-formedness).
- Verification step is advisory; clinical decisions remain under human oversight.
Education and Evaluation
- Benchmarking and teaching length generalization (Immediate Application)
- What: Use the paper’s domains (Heavy Grippers, Colors, Lights Out) to test LLMs’ length generalization; create course modules on planning vs. transformer learnability.
- Tools/workflows:
- A “C*-RASP analyzer” that classifies tasks as learnable/not learnable for length generalization.
- Course labs on Plan Verification vs. Plan Generation limits.
- Assumptions/dependencies:
- Access to the provided code and datasets; adherence to the offset trick for APE/NoPE.
Policy and Governance
- Risk-tiering for LLM planning use (Immediate Application)
- What: Mandate a structural analysis (well-formed/delete-free vs. STRIPS with conditional effects) before deploying LLM-based plan verification in safety-critical contexts.
- Guidance: Allow LLM verification when domains are well-formed/delete-free; require classical planners or formal methods otherwise.
- Assumptions/dependencies:
- Availability of domain diagnostics and documentation of modeling choices.
- Human-in-the-loop for high-stakes environments.
Long-Term Applications
These use cases require further research, scaling, or domain engineering, building on the paper’s theoretical framework (Symbolic Limit Transformers and C*-RASP).
Advanced Robotics, Autonomy, and CPS (Cyber-Physical Systems)
- Verified autonomy at scale with domain compilation (Long-Term Application)
- What: Systematically compile real-world domains (with conditional effects) into behaviorally equivalent well-formed variants that preserve safety guarantees and enable LLM verification at long horizons.
- Potential product: Domain2WF compiler that transforms PDDL with conditional effects into well-formed schemas (accepting action-space blowups when feasible).
- Dependencies/risks:
- Compilation may cause exponential action growth.
- Need toolchains to maintain readability and maintainability of compiled domains.
- Hybrid planning stacks (Long-Term Application)
- What: Pair a classical planner (for generation) with a learned verifier (for fast screening); escalate hard instances to full search or formal verification.
- Dependencies:
- Strong interfaces for state/action grounding and symbolic/LLM interop.
- Robust handling of variable universes and object identity changes.
Scientific Automation and Lab Robotics
- Protocol verification under state-dependent side effects (Long-Term Application)
- What: Many wet-lab actions have conditional effects; develop modeling/compilation strategies or new architectures to extend learnability to these domains.
- Dependencies:
- Either eliminate/compile conditional effects or extend theory beyond current limits (paper shows conditional effects reduce to PARITY-like hardness).
Energy, Finance, and Critical Infrastructure
- Pre-execution verification of control/transaction sequences (Long-Term Application)
- Energy: Validate grid operation sequences (switching, dispatch) after domain engineering for well-formedness (each action must change system state).
- Finance: Verify trade lifecycles/compliance pipelines by modeling as delete-free progress accrual.
- Dependencies:
- Significant domain modeling; high-stakes require layered assurance (formal methods, auditing).
LLM Systems and Architecture Research
- Toward plan generation guarantees (Long-Term Application)
- What: Extend the theory from verification to generation (harder; STRIPS planning is PSPACE-complete).
- Paths:
- Learn-to-compile domains for generation-friendly structure.
- Explore scratchpads/auxiliary memory with proofs analogous to C*-RASP.
- Positional encoding generalization (Long-Term Application)
- What: Extend guarantees from APE/NoPE to rotary or other encodings used at scale.
- Dependencies:
- New invariance proofs; adapted offset strategies for token identities and positions.
- Index-hint and schema-design languages (Long-Term Application)
- What: Standardize “index hints” for object identities and symbolic scaffolds that improve generalization in variable-universe settings, leveraging the paper’s split-alphabet and match-predicate ideas.
- Tools:
- A C*-RASP IDE for designing verifiable plan-verification programs.
- Symbolic Limit Transformer libraries for analysis/synthesis.
Governance, Standards, and Auditing
- Standards for deployable LLM verification in safety-critical planning (Long-Term Application)
- What: Certification criteria that require demonstrating C*-RASP expressibility (or equivalent) and training under invariance-promoting regimes (offset trick, locality regularization).
- Dependencies:
- Community-agreed testing protocols and disclosure of domain modeling choices.
Assumptions and dependencies common across applications:
- Guarantees apply to plan verification, not plan generation.
- Strong positive results require domains to be well-formed or delete-free; unconstrained STRIPS and conditional effects can encode FlipFlop/PARITY-like hardness and are predicted not to length-generalize.
- Training conditions matter: decoder-only models with absolute (or no) positional encodings trained with the offset trick for both positions and object IDs; regularization promoting locality; careful tokenization that separates domain symbols from object identities (split alphabet).
- Domain engineering may be needed (e.g., forbid no-ops to enforce well-formedness, or compile conditional effects away) and may increase action-space size.
- In safety-critical contexts, use learned verification as one layer in a defense-in-depth stack with formal methods and human oversight.
Glossary
- Absolute positional encodings (APE): A way to encode token positions with fixed embeddings tied to absolute indices. Example: "decoder-only transformers with absolute positional encodings (APE) provably generalize to longer inputs under a specific formal model of training (Theorem 7 in \citet{huangformal2025})."
- Action schema: A parameterized action template (with arguments, preconditions, and effects) that generates concrete actions by grounding its variables. Example: "An action $a(o_1,\ldots,o_{arity{a})$ is a ground instance of an action schema "
- B-RASP: A variant of the RASP programming formalism tailored to mask-based transformer computations. Example: "B-RASP \cite{yang2024masked}"
- C-RASP: Counting RASP; a programmatic formalism used to model and predict which tasks transformers can learn with length generalization. Example: "expressiveness in the (Counting RASP) language \cite{yangcounting2024}"
- Closed world assumption: The convention that any proposition not explicitly listed as true in a state is assumed false. Example: "A state is a set of propositions under the closed world assumption, i.e. this set contains exactly those propositions that hold in the state."
- Conditional effects: Action effects that apply only when certain conditions hold at execution time. Example: "Conditional effects are a useful feature when modeling real-world problems, and are strictly more expressive than STRIPS \cite{nebel:00}."
- Decoder-only model: A transformer architecture that autoregressively predicts the next token using only a decoder stack. Example: "analyzing the ability of decoder-only models to verify whether a given plan correctly solves a given planning instance."
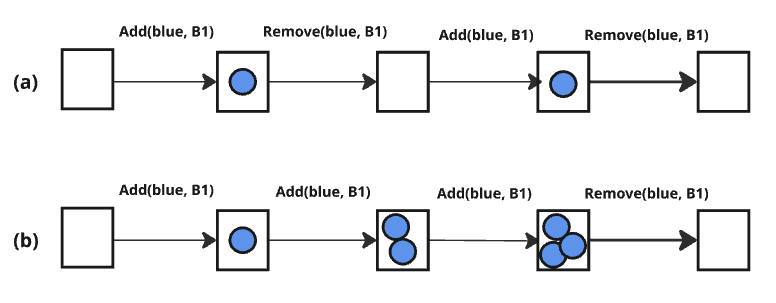
- Delete-free: A STRIPS subclass where actions only add propositions and never delete them. Example: "Delete-Free: a STRIPS instance where actions only have positive effects, i.e. for all $#1{eff{a} =\emptyset$."
- Fixed Universe: A generalization setting where the set of objects is fixed across training and testing. Example: "1. Fixed Universe: The set of objects is fixed, but and can vary per input sample."
- FlipFlop (language): A formal language () known to be hard for length generalization under Pos/C-RASP frameworks. Example: "the Flipflop language (over )"
- Goal state: A state that satisfies all goal literals. Example: " is a goal state iff ."
- Ground instance: A predicate or action with all variables replaced by concrete objects. Example: "A proposition $p(o_1,\ldots,o_{arity{p})$ is a ground instance of a predicate "
- Hypothesis Class: The constrained family of transformer models considered during learning in the theoretical framework. Example: "Hypothesis Class (): We restrict the search space to transformers that already satisfy translation invariance, and where any parameter is specified at fixed precision (finite number of bits used to represent any parameter)."
- Inference Procedure: The idealized learning rule that selects the simplest model consistent with short examples, used to prove generalization. Example: "Inference Procedure: We model learning as an idealized selection of the minimizing while matching the target function on all inputs of length "
- International Planning Competition (IPC): A benchmarking venue for planning systems and domains. Example: "International Planning Competition (IPC) \citep{McDermott2000AIPS}"
- Lights Out (domain): A planning benchmark where pressing a light toggles it and its neighbors, with the goal of turning all lights off. Example: "We formalize the Lights Out\ game as our final domain."
- Literal: A proposition or its negation; goals and conditions are sets of literals. Example: "The goal is represented by a set of ground literals."
- Locality: A constraint that model interactions depend only on bounded-distance relationships, promoting local algorithms. Example: "Locality: Interactions must vanish when the relative distance exceeds a finite bandwidth , ensuring the algorithm relies only on local context."
- Match Predicate: A predicate over token positions that tests object-identity consistency via local equality checks under shifts. Example: "A Match Predicate is a conjunction of equality checks between tokens in the neighborhoods of and "
- NoPE: Transformers without positional encodings. Example: "then length generalization would be guaranteed even for NoPE transformers."
- Offset trick: Training methodology that shifts positions (and, here, object IDs) to promote invariance to absolute indices. Example: "Practically, invariance can be brought about during training via the offset trick"
- PARITY (language): A formal language () used to show non-generalization beyond Pos/C-RASP expressivity. Example: "the PARITY language "
- PDDL (Planning Domain Definition Language): A standard language for specifying planning domains and problems. Example: "variants of the STRIPS formalism as standardized in the PDDL planning definition language \cite{fikes:etal:71,haslum:etal:19}."
- Plan verification: The task of checking whether a given action sequence solves a given planning instance. Example: "We focus specifically on plan verification, which decides for a given planning instance and a given plan whether the plan correctly solves the instance."
- Planning instance: A concrete problem specification consisting of a domain, objects, initial state, and goal. Example: "A planning instance , has a domain ."
- Pos (periodic): A fragment of C-RASP capturing periodic/counting computations that predict transformer length generalization. Example: "and its variant \cite{huangformal2025, jobanputra2025born}"
- Precondition: A set of literals that must hold for an action to be applicable. Example: "An action is applicable in a state iff its preconditions are satisfied (i.e. )"
- Product functions: Inner-product expressions that formalize transformer computations (attention, MLP) in the analysis. Example: "parameterize transformers using product functions \citep{huangformal2025}"
- Regularizer: A penalty term used in the theoretical learning model to induce simple, local algorithms. Example: "A regularizer penalizes model complexity (depth, norms) and non-local interactions, forcing the inference procedure to select `algorithms' that are local."
- RASP: A programmatic abstraction for transformer-like computations used to study expressivity. Example: "RASP \cite{weiss2021thinking}"
- Self-attention: The mechanism by which a token attends to other tokens to compute contextualized representations. Example: "Pairwise interactions are those between different tokens, arising for instance from self attention or with the unembedding matrix."
- Star-free regular languages: A subclass of regular languages definable without the Kleene star in first-order logic with order. Example: "\citet{Lin_Bercher_2022} already showed that when is a STRIPS instance, is a strict subset of star free regular languages."
- STRIPS: A canonical planning formalism with actions specified by preconditions and add/delete effects. Example: "STRIPS is the standard formalism to describe planning problems."
- Symbolic Limit Transformer: The idealized, invariant, local algorithm that a sequence of learned transformers converges to under the framework. Example: "which we refer to as a Symbolic Limit Transformer"
- Translation Invariance: The requirement that interactions depend on relative, not absolute, positions or identities. Example: "Translation Invariance: Interactions must depend only on relative differences, not absolute indices."
- Unembedding matrix: The output projection matrix mapping hidden states back to vocabulary logits in a transformer. Example: "arising for instance from self attention or with the unembedding matrix."
- Variable Universe: A generalization setting where the object set (and thus effective alphabet) grows at test time. Example: "2. Variable Universe: The set of objects can all vary across samples."
- Well-formed: A STRIPS subclass where each effect necessarily changes the truth value of the affected proposition when applied. Example: "Well-Formed: a STRIPS instance where each proposition listed in the effects of an action strictly changes value whenever the action is applied."
Collections
Sign up for free to add this paper to one or more collections.