Beyond Single Tokens: Distilling Discrete Diffusion Models via Discrete MMD
Abstract: It is currently difficult to distill discrete diffusion models. In contrast, continuous diffusion literature has many distillation approaches methods that can reduce sampling steps to a handful. Our method, Discrete Moment Matching Distillation (D-MMD), leverages ideas that have been highly successful in the continuous domain. Whereas previous discrete distillation methods collapse, D-MMD maintains high quality and diversity (given sufficient sampling steps). This is demonstrated on both text and image datasets. Moreover, the newly distilled generators can outperform their teachers.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making certain AI models that generate text and images faster without losing quality. These models are called “discrete diffusion models.” They usually need lots of tiny steps to turn noisy, scrambled data into clean, meaningful words or pictures. The authors introduce a new training trick named Discrete Moment Matching Distillation (D-MMD) that teaches a smaller, faster “student” model to copy a slower “teacher” model—often so well that the student becomes even better, while using far fewer steps.
What problem are they trying to solve?
The main goals are simple:
- Make discrete diffusion models much faster at generating text and images by reducing how many steps they need.
- Keep the quality and variety of the outputs high (no bland or repetitive results).
- Show that these faster “student” models can match or even beat their “teacher” models.
- Create a better way to judge text quality for these models, since a popular metric (perplexity) can be misleading.
How does their method work?
To understand the approach, here are a few quick ideas and analogies:
- Diffusion model: Imagine starting with a blurry picture (or scrambled text) and cleaning it up little by little. That “cleaning” is done in many tiny steps.
- Discrete: Instead of sliding numbers smoothly (like turning a dimmer up or down), discrete models pick from fixed options, like choosing one word from a vocabulary or one color value for a pixel.
- Distillation: Think of a teacher helping a student learn to solve problems in fewer steps by focusing on the most important patterns.
The key technique, D-MMD, teaches the student by matching “moments,” which you can think of as the average “best guess” the model would give at a noisy stage. Rather than copying every detail of the teacher’s complex process, the student learns to produce the same expected outcomes at each step. This is powerful because:
- The student generates “soft tokens” (probabilities over options, like “cat” with 60%, “dog” with 30%, “car” with 10%) and then samples final “hard tokens” (one choice, like “cat”). Soft tokens help the student adjust its thinking smoothly.
- An extra “auxiliary” helper model is used during training to guide the student more effectively. The student tries to match the teacher better than it matches the auxiliary model, which nudges it toward the teacher’s behavior.
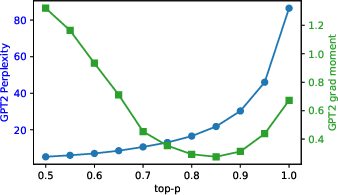
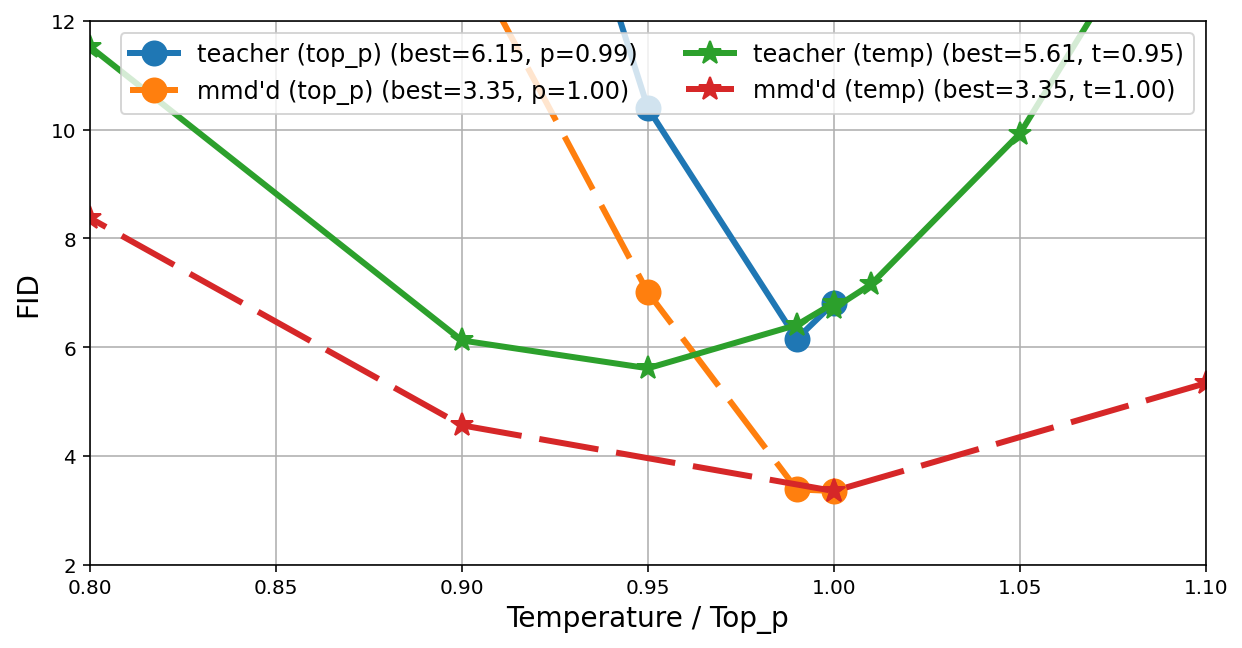
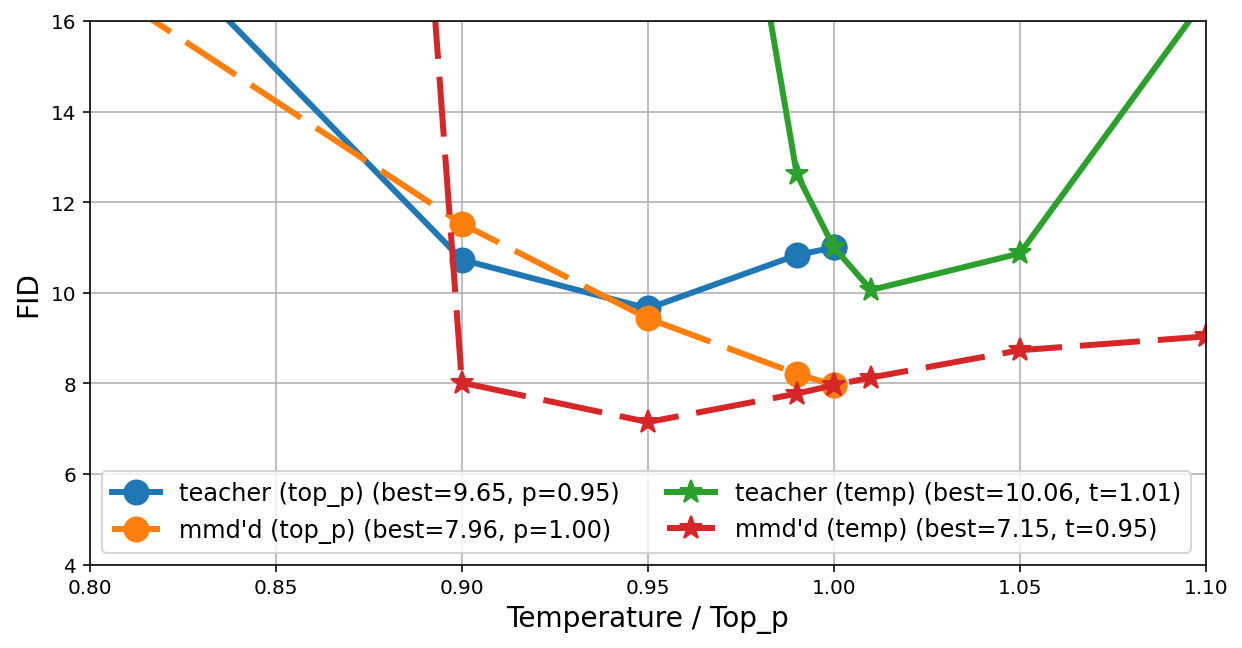
- The training sometimes includes popular sampling tweaks used in practice, like lower temperature or “top-p” sampling, which push outputs to be more confident and less random. The authors add these carefully to avoid unstable training.
Finally, for judging text quality, they introduce a new metric called the Gradient Moment. In simple terms: they use a reference LLM (like GPT-2) and check how much that model would want to change its own parameters after reading the student’s generated text versus real text. If the student’s text looks like real data, the reference model sees no reason to change—so the metric stays low. This avoids the pitfalls of perplexity, which can look “good” even for repetitive or unnatural text.
What did they find?
The results are strong for both images and text.
- Images (CIFAR-10 dataset):
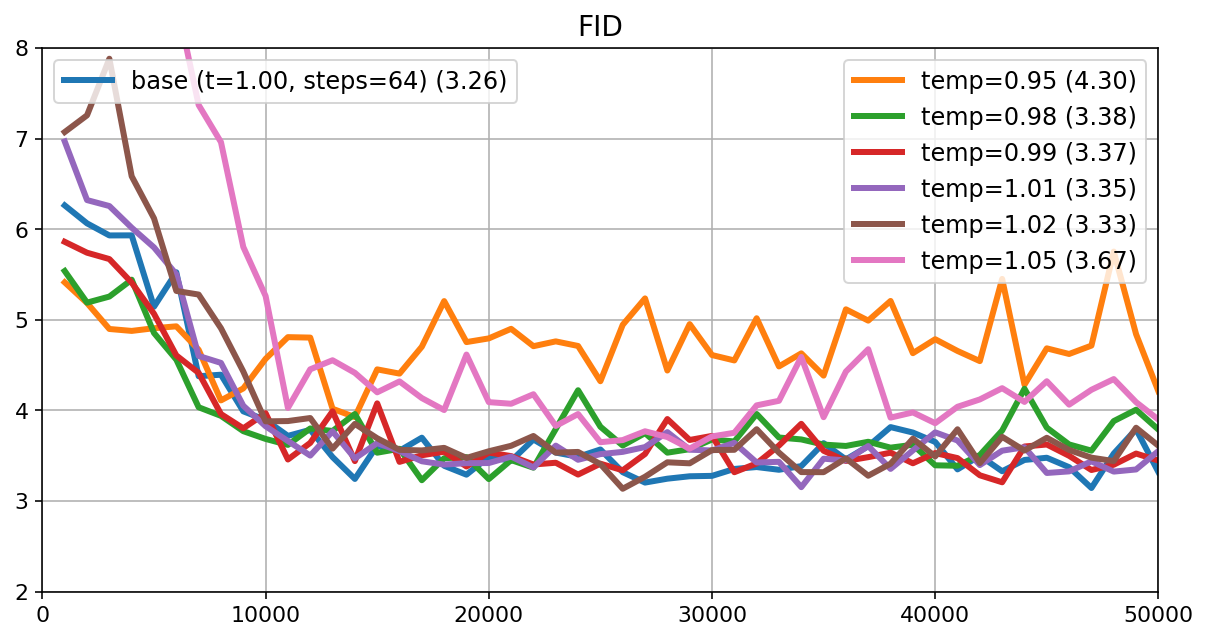
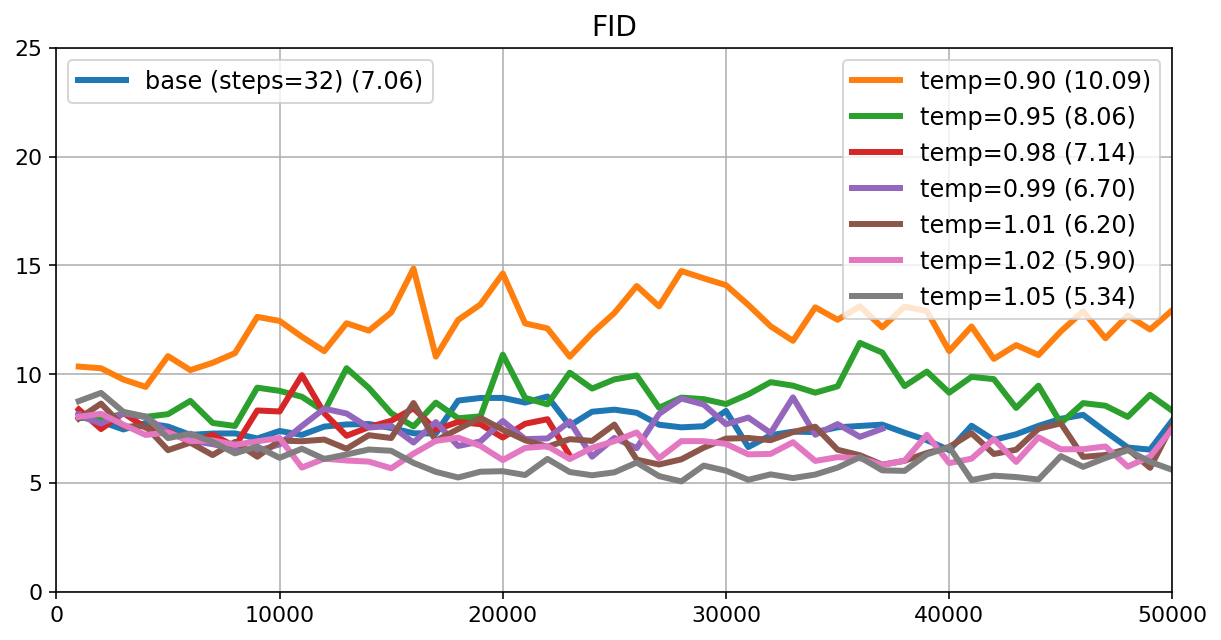
- Teachers need many steps to reach decent quality (measured by FID, lower is better).
- D-MMD students matched or beat the teachers using far fewer steps. For example, one student reached FID ≈ 3.7 with 32 steps, compared to a teacher at FID ≈ 7.5 with 1,024 steps. Another student hit FID ≈ 3.5 with 64 steps, beating a teacher at ≈ 6.4 with 1,024 steps.
- Text (Open Web Text):
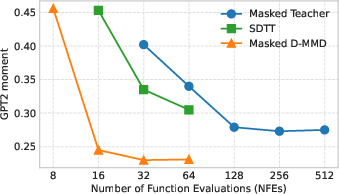
- Using the new Gradient Moment metric (lower is better), the Masked D-MMD student already outperformed its teacher at just 16 steps (around 0.236 on the metric), and did even better with moderate step counts.
- In a “block autoregressive diffusion” setup (generating text in chunks with context), a 16-step student matched the performance of a 256-step teacher.
- Compared to other distillation methods:
- D-MMD consistently gave better image quality with fewer steps than previous state-of-the-art methods.
- For text, D-MMD remained strong while some other methods tended to degrade when pushed to fewer steps or repeated distillation.
Additional insights:
- The student can still produce coordinated (correlated) outputs even if the final sampling is done independently across tokens. It does this by making its soft probabilities more confident together, so the independent choices end up aligning.
- Adding a small amount of input noise helped the student for “masked” diffusion on images—it gave the student the randomness it needed to model a full distribution and improve quality.
- Using temperature/top-p during distillation (to mimic practical sampling) worked, but needed careful handling to keep training stable.
Why is this important?
- Speed: Fewer steps mean faster generation and lower compute costs. This matters a lot for big models and long sequences of text.
- Quality: The student can be more “mode-seeking” (picking strong, realistic outputs) without collapsing into repetition. This often looks better for images and reads better for text.
- Reliability: The new Gradient Moment metric gives a more trustworthy way to tell if generated text really matches the data distribution, which is important for fair comparisons.
- Versatility: The method works for different kinds of discrete diffusion (like masked and uniform) and for both text and images.
Implications and potential impact
This research shows a practical path to make non-autoregressive generative models (like discrete diffusion) far more efficient, sometimes even outperforming their original teachers. That could:
- Enable faster image and text generation in real apps, with lower hardware costs.
- Make diffusion-style LLMs more competitive with classic autoregressive approaches.
- Encourage better evaluation practices for text generation, reducing over-reliance on perplexity.
- Inspire new hybrid designs (mixing blocks of diffusion with autoregressive context) that balance speed, quality, and flexibility.
In short, D-MMD helps bridge the gap between high-quality generation and efficient sampling, opening the door to faster, better generative AI systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions left unresolved by the paper, written to guide future research.
- Convergence and stability of the min–max optimization: No theoretical guarantees or empirical analysis of convergence rates, stability regions, or failure modes for the adversarial generator–auxiliary training in the discrete setting; hyperparameter sensitivity (e.g., step sizes, update ratios, weighting functions) is acknowledged but not systematically studied.
- Validity of “soft-sample” substitution for discrete tokens: For masked diffusion, replacing hard samples by the student’s soft probabilities is argued to be acceptable, but the exact conditions under which this substitution yields unbiased or low-bias gradients are not derived; for uniform diffusion, the bias and variance introduced by using hard samples only (and the absence of soft targets) is not quantified.
- Applicability when the posterior q(z_s | z_t, x) is not analytically available: D-MMD relies on posterior sampling (q(z_s | z_t, x)); how to extend the method to processes without closed-form posteriors (e.g., learned forward processes or non-standard discrete noising) remains open (e.g., amortized posteriors, MCMC, or variational approximations).
- Theoretical sufficiency under practical approximations: While the appendix shows sufficiency results (matching E[x | z_t] or factorized probabilities) in the dt → 0 limit, it is unclear how discretization, finite-step training, and the soft-sample approximation impact those guarantees in practice.
- Higher-order dependency matching: The method matches first-moment quantities via auxiliary modeling, but there is no analysis of when (and how quickly) higher-order token dependencies are recovered, nor diagnostics for residual long-range or multi-token correlation errors.
- Risk of diversity loss via entropy collapse: The mechanism by which a factorized generator learns correlations (collapsing output entropies) risks mode dropping; diversity metrics beyond token entropy (e.g., MAUVE, self-BLEU for text; precision–recall for images) are not reported or analyzed.
- Student surpassing teacher vs mode dropping: The paper posits reverse-KL-like, mode-seeking behavior as an explanation for students outperforming teachers, but it does not quantify the trade-off between improved “quality” and potential loss of coverage (e.g., missing modes, lower recall).
- Top‑p distillation surrogate is ad hoc: The proposed workaround of subtracting a constant Δ from masked logits avoids gradient spikes but does not implement true top‑p; the induced bias, calibration error, and impact on learned distributions are not characterized; more principled differentiable top‑p surrogates are not explored.
- Temperature distillation design space: While temperature-guided distillation is included, there is no systematic study of how temperature schedules, per-step temperatures, or annealing strategies affect quality/diversity trade-offs and stability.
- Scope and scalability of experiments: Results are limited to CIFAR‑10 and OWT; it is unknown how D‑MMD scales to larger vocabularies, longer contexts, larger LMs, or more complex modalities (e.g., speech, protein sequences, code, multimodal tasks).
- Conditional generation beyond blocks: Apart from one block‑autoregressive experiment (block size 256), the method’s effectiveness for conditional tasks (e.g., instruction following, translation, captioning, controllable generation) is not evaluated; how to integrate conditioning signals or guidance into D‑MMD is not detailed.
- Gap to strong autoregressive baselines: The AR baseline’s GPT‑2 GM is substantially lower than D‑MMD’s; the paper does not assess whether D‑MMD can close the gap with competitive AR models in text or how to combine D‑MMD with AR decoders to narrow it.
- Training cost and resource footprint: Claims focus on reduced NFEs at inference; training-time cost (wall‑clock, FLOPs, memory), auxiliary model overhead, and overall distillation efficiency vs. teacher sampling are not reported.
- Sensitivity to teacher quality and sampling policy: How D‑MMD behaves with weak teachers, different teacher temperatures/top‑p choices, or mismatched teacher/student sampling policies is only partially explored; robust distillation under teacher mismatch remains open.
- Architectural and capacity dependence: There is no ablation on student/auxiliary capacity, architecture (e.g., receptive field size, attention patterns), or conditioning mechanisms (e.g., noise embeddings) and how these factors mediate correlation learning and collapse.
- Noise conditioning rationale and generality: Noise inputs improve masked distillation but not uniform diffusion; the underlying reason is hypothesized (sufficient noise in z_t) but not verified; whether similar findings hold for other datasets/modalities is unknown.
- Evaluation with FID on train set: Image FID is computed against the training distribution (50k train images), risking overfitting confounds; standard FID vs. test sets, precision/recall, or improved modern metrics (e.g., DINO-separable metrics) are not provided.
- New GPT‑2 Gradient Moment (GM) metric validation: Although the metric is motivated, there is no empirical correlation study with human judgments or downstream task performance; sensitivity to the reference model’s capacity, domain mismatch, tokenizer, and training convergence is not quantified.
- GM implementation details and variance: The minibatch inner‑product estimator is claimed unbiased, but estimator variance, dependence on batch size, gradient layer selection (all parameters vs. subsets), and computation cost are not analyzed.
- Robustness of GM under conditional settings: While the metric is claimed to extend to conditional generation, experiments and calibration for conditional prompts (e.g., distribution shift between prompts and data) are not reported.
- Uniform diffusion target mismatch: For processes where the optimal target is not E_qx | z_t, the appendix outlines a modified loss, but its empirical behavior, sensitivity, and benefits versus the simpler CE-based variant are not investigated.
- Posterior discretization granularity: The choice of k (number of sampling steps for student) and the dt discretization used during training versus inference are not systematically probed for bias–variance trade-offs or optimal schedules.
- Generalization to other discrete processes: Extensions are claimed (e.g., discrete flow matching), but there are no experiments on alternative discrete diffusions (e.g., non-absorbing multi-state processes) or datasets to confirm generality.
- Stability aids for the adversarial game: Beyond auxiliary regularization to the teacher, no techniques (e.g., gradient penalties, two‑time‑scale updates, EMA targets, or proximal objectives) are evaluated to improve stability and convergence.
- Fairness and apples‑to‑apples comparisons: External baselines use different teachers or processes (e.g., Di4C’s Gaussian-mimicking process), and top‑p/temperature settings differ; a standardized benchmark suite with identical teachers and sampling policies is missing.
- Long‑sequence behavior and repetition: The paper generates 1024 tokens unconditionally but does not quantify repetition, degeneration, or coherence over long spans using standard repetition/uniqueness metrics.
- Safety, bias, and calibration: No analysis of undesirable artifacts (e.g., toxicity, bias), or probability calibration (e.g., expected calibration error) in text outputs after distillation is provided, especially important given entropy collapse tendencies.
- Extension to 1–2 step text generators: While few‑step generators are demonstrated, the feasibility and failure modes of true 1–2 step students for high‑quality text (analogous to DiMO’s one‑step images) are not explored.
- Reference‑model choice for images: The GM idea is only explored for text (GPT‑2); the image evaluation relies on FID; whether a “reference‑model gradient moment” using a vision model (e.g., ViT) yields a better image metric is untested.
- Principled top‑p/temperature-aware objectives: A learning objective that exactly matches the teacher’s sampling transformation (top‑p or temperature) with controlled gradients (e.g., using differentiable sorting or soft‑capping) is not developed.
- Handling vocabulary/domain shifts: The GM metric and distillation pipeline assume shared tokenization and domains (OWT, GPT‑2); effects of vocabulary mismatches, multilingual settings, or domain shifts are not studied.
- Reliability under different destruction schedules: Only specific noise schedules are reported; sensitivity to schedules (e.g., α_t, discretization grids) and whether D‑MMD can learn across schedules remains unexplored.
- Combining D‑MMD with richer student outputs: The paper intentionally keeps the student’s per‑token outputs factorized; whether D‑MMD can be combined with mixture heads or low‑rank coupling to improve correlation without severe cost is an open direction.
- Data efficiency and overfitting: There is no study of how many examples are needed for successful distillation, whether the student overfits to teacher idiosyncrasies, or how D‑MMD behaves in low‑data regimes.
- Uncertainty quantification: No method is proposed to measure or control the uncertainty of the distilled generator (e.g., via ensembling, Bayesian heads, or calibrated temperature), especially important when students collapse entropy.
- Reproducibility details: Full training schedules, optimizer settings, and code for the GM metric and the top‑p surrogate are not detailed sufficiently for precise replication; ablations clarifying which components are essential are limited.
Practical Applications
Overview
The paper introduces Discrete Moment Matching Distillation (D‑MMD), a principled method to distill discrete diffusion models into few‑step generators for text and image tokens, often surpassing teacher quality while using a fraction of the sampling steps. It also proposes a new evaluation metric for discrete generators: the Gradient Moment of a reference autoregressive (AR) model (e.g., GPT‑2 GM), which better detects distributional mismatch and mode collapse than generative perplexity. The method supports masked and uniform diffusion, temperature and top‑p distillation, and block‑autoregressive (block‑AR) workflows.
Below are practical applications derived from these findings, grouped by time horizon. Each item notes sectors, potential tools/workflows, and assumptions or dependencies.
Immediate Applications
- Distill faster discrete text generators for lower‑latency, lower‑cost inference
- Sectors: software, media/marketing, customer support, education (assistive writing), enterprise productivity
- Tools/workflows:
- Train D‑MMD students from existing masked/uniform diffusion LMs and deploy few‑step generators (e.g., 16–64 steps vs. 256–512)
- Distill temperature/top‑p behavior directly into the student for consistent, mode‑seeking sampling defaults
- Integrate into block‑AR pipelines to generate token blocks in parallel while preserving AR conditioning
- Assumptions/dependencies:
- Requires a reasonably strong discrete diffusion teacher and a stable auxiliary model
- Min–max optimization needs careful hyperparameters; masked diffusion benefits from input noise conditioning
- Top‑p distillation must avoid logit spikes (use the “Δ‑offset” masking trick described in the paper)
- Quality should be validated beyond perplexity (e.g., GPT‑2 GM)
- Accelerate discrete image token generation to reduce latency and compute
- Sectors: creative tools, design, gaming, advertising
- Tools/workflows:
- Apply D‑MMD to discrete image token pipelines (e.g., pixel tokens or VQ‑token decoders)
- Use few‑step students (e.g., 8–32 steps) to replace 256–1024‑step teachers for batch generation and A/B testing
- Assumptions/dependencies:
- May lag continuous diffusion on absolute metrics; best as a speed‑quality trade‑off
- Requires compatible tokenization or pixel‑token training setup
- Replace generative perplexity with Gradient Moment (GM) metrics for evaluation and QA
- Sectors: MLOps, software, academia
- Tools/workflows:
- Add a GM‑based quality gate to CI for discrete generators to detect collapse, repetition, and atypicality
- Use conditional GM (conditioning on prompts or prefixes) for task‑specific evaluation
- Run parameter sweeps (temperature/top‑p) and choose settings that minimize GM while maintaining entropy
- Assumptions/dependencies:
- Requires a well‑trained reference AR model and dataset alignment; compute overhead for gradient evaluation
- GM complements, not replaces, human evaluation and downstream task metrics
- Training pipeline upgrade for discrete diffusion research and model maintenance
- Sectors: academia, industry R&D
- Tools/workflows:
- Adopt D‑MMD’s alternating min–max training with a fixed teacher and auxiliary model
- Use the paper’s practical tips: noise conditioning for masked diffusion; Δ‑offset for top‑p; posterior sampling via q(z_s | z_t, x)
- Assumptions/dependencies:
- Stability may depend on schedules, weighting functions, and sampler choices; tuning is expected
- On‑device or bandwidth‑constrained deployment of discrete generators
- Sectors: mobile, edge AI, consumer apps (keyboards, offline assistants)
- Tools/workflows:
- Deploy distilled few‑step students to cut FLOPs, memory bandwidth, and latency for short‑form generation
- Assumptions/dependencies:
- Device constraints still apply; model size and memory footprint may dominate over step count
- Safety, compliance, and monitoring for generative systems
- Sectors: policy/compliance, platform trust & safety
- Tools/workflows:
- Use GM metrics to monitor drift and detect over‑aggressive sampling (low temperature) in production
- Calibrate top‑p/temperature to avoid collapsed, repetitive, or ungrammatical outputs
- Assumptions/dependencies:
- Requires continuous monitoring and reference model upkeep; GM is sensitive to reference model/domain shifts
Long‑Term Applications
- Hybrid AR–diffusion architectures with block‑wise few‑step decoding
- Sectors: software, cloud AI platforms, creative AI
- Tools/products:
- LLMs that encode context autoregressively and decode blocks with a D‑MMD‑distilled diffusion head for parallelism
- SDKs that expose “block size × steps” knobs to trade off speed and quality
- Assumptions/dependencies:
- Requires robust conditioning across prompts; more research on long‑context stability and task generalization
- Multimodal discrete token generation at real‑time or near‑real‑time rates
- Sectors: audio (speech/music), video, gaming, AR/VR
- Tools/products:
- Apply D‑MMD to codebook‑based tokenizers (e.g., EnCodec‑like audio tokens, video tokens) to cut decoding steps
- Real‑time creative tools and interactive media pipelines
- Assumptions/dependencies:
- Needs strong discrete diffusion teachers for each modality; temporal correlation handling and latency budgets are critical
- Evaluation beyond FID/GPT‑2 GM (e.g., audio MOS, video metrics) must be standardized
- Energy‑ and cost‑efficient generative services at scale
- Sectors: cloud providers, SaaS
- Tools/products:
- Fleet‑wide replacement of high‑NFE discrete generators with D‑MMD students to reduce GPU hours and carbon footprint
- Cost‑aware routing: select student with minimal steps that meets GM/quality SLA
- Assumptions/dependencies:
- Requires production‑scale validation; cost models must include retraining/distillation overheads
- Standardization of typicality‑aware evaluation for discrete generators
- Sectors: academia, standards bodies, policy
- Tools/products:
- Benchmarks and leaderboards using Gradient Moment or similar reference‑gradient metrics
- Guidelines discouraging sole reliance on generative perplexity for discrete diffusion models
- Assumptions/dependencies:
- Community consensus on reference models and datasets; legal/licensing clarity for reference use
- Domain‑specific sequence generation (e.g., code, bio/chemistry, finance text)
- Sectors: software engineering, biotech, finance
- Tools/products:
- Few‑step discrete generators for structured or semi‑structured sequences (code tokens, protein tokens, financial narratives)
- Assumptions/dependencies:
- Requires domain‑specific teachers, tokenizers, and safety filters; rigorous task‑level evaluation is needed
- Generative codecs and communication systems
- Sectors: communications, streaming, AR/VR
- Tools/products:
- Discrete diffusion‑based codecs with D‑MMD‑distilled decoders for faster synthesis of compressed token streams
- Assumptions/dependencies:
- Must meet stringent latency and quality constraints; integration with hardware accelerators desirable
- Open‑source D‑MMD libraries and MLOps integrations
- Sectors: open‑source ecosystem, platform engineering
- Tools/products:
- Plugins for popular frameworks (e.g., JAX/PyTorch) exposing D‑MMD training loops, teacher‑student schedulers, safe top‑p distillation, and GM dashboards
- Assumptions/dependencies:
- Community adoption and maintenance; compatibility across diverse discrete diffusion implementations
- Risk and misuse mitigation policies for cheaper high‑quality generation
- Sectors: policy, platform governance
- Tools/products:
- Risk assessments and governance processes acknowledging that D‑MMD lowers generation cost and raises quality, potentially increasing misuse
- Auditing frameworks using GM (and other metrics) to monitor shifts and enforce guardrails
- Assumptions/dependencies:
- Requires cross‑organizational standards and enforcement mechanisms; continued research on robust, domain‑aligned evaluators
Glossary
- Absorbing state: A special terminal token in certain discrete diffusion processes that “absorbs” mass, preventing further transitions. "introduced an absorbing state or masked process."
- Auxiliary model: A helper network used during distillation to approximate target expectations and stabilize the adversarial objective. "The loss for the auxiliary model is:"
- Autoregressive (AR) model: A model that generates tokens sequentially, each conditioned on previous tokens. "Unlike standard autoregressive LLMs, distilled discrete diffusion models do not have a tractable sampling likelihood."
- Block autoregressive diffusion: A hybrid setup that generates blocks of tokens in parallel within an overall autoregressive framework. "Block autoregressive diffusion"
- Categorical distribution: A discrete probability distribution over a finite set of categories. "Sample ."
- Consistency-based distillation: A family of methods that enforce self-consistency across different sampling steps or time scales to distill diffusion models. "flow-map or consistency-based distillation approaches"
- Consistency models: Models trained to produce outputs consistent across different noise levels or steps, enabling few-step generation. "consistency models \citep{song2023consistency}"
- Cross-entropy loss: A standard loss measuring divergence between a target one-hot or distribution and predicted probabilities. "with the cross-entropy loss ."
- DDIM sampler: A deterministic sampler for diffusion models based on the probability flow ODE that accelerates generation. "often approximated by the DDIM sampler."
- Denoising steps: Iterative steps in diffusion sampling that progressively transform noisy inputs into clean samples. "using 1024 denoising steps."
- Discrete Moment Matching Distillation (D-MMD): The paper’s proposed method that distills discrete diffusion models by matching conditional expectations in a min–max framework. "Our method, Discrete Moment Matching Distillation (D-MMD), leverages ideas that have been highly successful in the continuous domain."
- Distribution matching: Stochastic distillation approaches that minimize divergence between the generator’s and teacher’s distributions. "sometimes referred to as distribution matching"
- Factorized distribution: A distribution that assumes independence across dimensions, modeled as a product of marginals. "leaves the factorized output distribution unchanged."
- FID (Fréchet Inception Distance): A metric for comparing distributions of images via features of a pretrained network. "We evaluate the performance using the FID metric,"
- Flow matching: A framework that learns continuous or discrete flows transforming a base distribution into data. "Both of these can also be formulated as discrete flow matching"
- Flow-map: A mapping that directly predicts the transport from one time to another in a learned flow, used for fast sampling/distillation. "flow-map or consistency-based distillation approaches"
- Generative perplexity: A proxy evaluation that measures how likely a reference AR model finds generated text, often gamed by low-temperature sampling. "the literature often evaluates these models using generative perplexity"
- GPT-2 Gradient Moment (GPT-2 GM): The proposed metric measuring the squared norm of centered gradients of a reference LLM on generated vs. data samples. "The resulting metric is thus the GPT-2 Gradient Moment (GPT-2 GM)."
- KL divergence: A measure of discrepancy between two probability distributions, often minimized in diffusion training. "Optimizing diffusion models can be viewed as minimizing the following KL-divergence:"
- Masked diffusion: A discrete diffusion process that gradually replaces tokens with a special mask token during the forward process. "For masked diffusion it is therefore equally valid to use either the soft or the hard ."
- Mode collapse: A failure mode where a generative model concentrates on few modes, reducing diversity. "Mode-collapsing behavior is often induced by reducing temperature or top-p sampling."
- Moment Matching Distillation (MMD): A distillation method aligning the conditional expectation of clean data between teacher and student across time. "generalizes the formulation of Moment Matching Distillation (MMD)"
- Number of Function Evaluations (NFE): The count of model forward passes during sampling, used as a measure of speed/cost. "for different NFEs on CIFAR10."
- Pareto front: The trade-off curve showing optimal balances (e.g., steps vs. quality) beyond which improvements in one dimension worsen another. "a substantially better Pareto front of steps vs FID than their teachers."
- Posterior (in diffusion): The distribution over earlier/noisier states given a later/less noisy state and (optionally) the clean data. "The posterior of this process given equals"
- Probability flow ODE: The deterministic ODE corresponding to the diffusion SDE that can be used for fast, non-stochastic sampling. "based on the probability flow ODE"
- Progressive distillation: An iterative distillation scheme that successively halves the number of sampling steps while matching intermediate trajectories. "iteratively learn the trajectory using the iterative progressive distillation"
- Reverse-KL: An optimization perspective that tends to focus mass on high-density regions (modes), often associated with mode-seeking behavior. "reminiscent of reverse-KL optimization."
- Score matching: A training objective where models learn the score (gradient of log-density) of the data distribution. "this formulation includes score matching"
- Softmax Jacobian: The Jacobian matrix of the softmax transformation, affecting gradient propagation through probability outputs. "Note that the softmax Jacobian of is not sufficiently small to cancel this term out."
- Stationary distribution: A time-invariant distribution that the forward diffusion approaches (e.g., uniform or mask), often factorized. "a factorized stationary distribution "
- Stop-gradient: An operation that blocks gradient flow through a variable during backpropagation to enforce independence in optimization. "by using a stop-gradient ."
- Temperature distillation: Distilling a student to match a teacher’s sharpened or softened logits via a temperature-scaled target. "For temperature distillation, the modification is relatively straightforward:"
- Top-p sampling: A sampling scheme that restricts choices to the smallest set of tokens whose cumulative probability exceeds p. "In top-p sampling, the idea is to select a subset of categories corresponding with a cumulative probability just over and mask out the other categories."
- Tweedie’s formula: A result relating posterior means to denoised estimates, adapted to discrete settings in recent work. "discrete versions of score matching and Tweedie's formula."
- Uniform diffusion: A discrete diffusion process where the forward corruption moves tokens toward a uniform categorical distribution. "In this work we consider both masked discrete diffusion \citep{austin2021structured}, where the destruction process gradually transforms tokens into a special masking token, and uniform diffusion \citep{hoogeboom2021argmaxflows}, which transforms tokens into a uniform distribution."
Collections
Sign up for free to add this paper to one or more collections.

