Compression is all you need: Modeling Mathematics
Abstract: Human mathematics (HM), the mathematics humans discover and value, is a vanishingly small subset of formal mathematics (FM), the totality of all valid deductions. We argue that HM is distinguished by its compressibility through hierarchically nested definitions, lemmas, and theorems. We model this with monoids. A mathematical deduction is a string of primitive symbols; a definition or theorem is a named substring or macro whose use compresses the string. In the free abelian monoid $A_n$, a logarithmically sparse macro set achieves exponential expansion of expressivity. In the free non-abelian monoid $F_n$, even a polynomially-dense macro set only yields linear expansion; superlinear expansion requires near-maximal density. We test these models against MathLib, a large Lean~4 library of mathematics that we take as a proxy for HM. Each element has a depth (layers of definitional nesting), a wrapped length (tokens in its definition), and an unwrapped length (primitive symbols after fully expanding all references). We find unwrapped length grows exponentially with both depth and wrapped length; wrapped length is approximately constant across all depths. These results are consistent with $A_n$ and inconsistent with $F_n$, supporting the thesis that HM occupies a polynomially-growing subset of the exponentially growing space FM. We discuss how compression, measured on the MathLib dependency graph, and a PageRank-style analysis of that graph can quantify mathematical interest and help direct automated reasoning toward the compressible regions where human mathematics lives.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Compression is all you need: Modeling Mathematics”
What’s this paper about?
The paper argues that the kind of mathematics humans discover and care about is all about compression: saying a lot with a little by building layers of ideas (definitions, lemmas, theorems) that act like shortcuts. The authors build simple models to study how much these shortcuts help, then check the models against real data from MathLib, a large library of formalized math in the Lean proof assistant.
What questions are the authors asking?
They focus on four plain questions:
- Why does human mathematics (what people actually find and use) feel different from the huge universe of all logically correct steps (formal mathematics)?
- Can we model “definitions as shortcuts” to measure how much they compress (or expand) what we can express?
- Which kind of model matches the way human math really grows: one where order doesn’t matter or one where it does?
- Do real measurements from MathLib match the model’s predictions?
How do they study it?
They use a simple but powerful idea: think of a proof as a string of symbols, like beads on a string or characters in a text.
- Shortcuts (also called “macros” in the paper) are named chunks you can reuse—like giving a complicated Lego build a single name so you can snap it in as one piece.
- They test two toy worlds:
- Bag-of-pieces world (called the free abelian monoid, written ): only the counts of pieces matter, not their order—like recipes where you only care how many eggs and cups of flour, not the order you added them.
- String world (called the free monoid, written ): order matters—like a sentence where swapping words changes the meaning.
They compare two things:
- Macro density: roughly, how many shortcuts you allow as lengths grow (few, some, or lots).
- Expansion: how far those shortcuts let you go with a fixed budget of steps—do you reach a little farther, a lot farther, or almost everywhere?
Then they test these ideas on MathLib:
- They turn MathLib into a dependency graph: each definition or theorem points to the things it uses.
- They define three simple measures:
- Wrapped length: the number of tokens (words/symbols) in the human-written definition or proof.
- Unwrapped length: how many primitive pieces you get if you expand every reference all the way down (like clicking through every link until you hit the basic building blocks).
- Depth: how many layers of references you have (how many links in the longest chain down to primitives).
What do they find in the models?
- In the bag-of-pieces world ():
- Place-value idea (like powers of 10 in decimal) gives huge power. With only a few shortcuts (logarithmically many, like “10, 100, 1000, …”), you can describe numbers exponentially larger with only a few symbols.
- Using shortcuts like “squares” or “-th powers” for each basic piece can be so strong that a small, steadily growing set of shortcuts lets you express everything with a fixed small number of steps (this uses Waring’s theorem; you don’t need the details—think “every big number breaks into a few perfect blocks”).
- In the string world ():
- If you only add a reasonable (polynomially growing) number of shortcuts, you don’t get much: expansion is only linear. That means your extra reach grows at about the same rate as your budget of steps.
- To do significantly better than linear, you need extremely many shortcuts (exponentially many). The authors even give a probabilistic way to pick “just enough” shortcuts so you get a superlinear boost, but it still requires a huge number of them overall.
The big takeaway from the models: human-level compression looks like the world (where order doesn’t matter much) rather than the world (where order is everything). In , sparse, well-chosen shortcuts create enormous expressive power.
What do they find in real data (MathLib)?
They measure millions of dependencies in MathLib and see three key patterns:
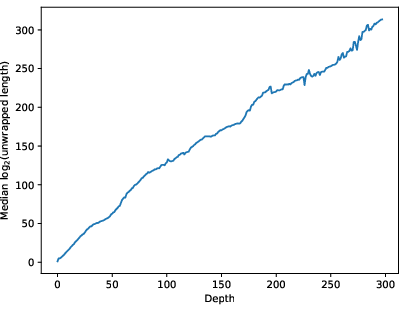
- Unwrapped length grows exponentially with depth. Each extra layer of definitions tends to multiply how many primitive pieces are hiding underneath.
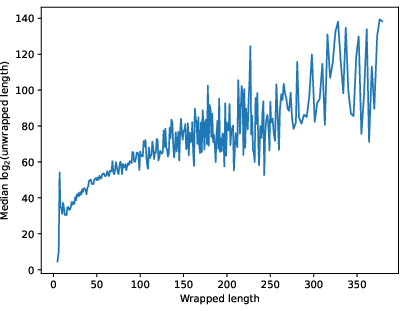
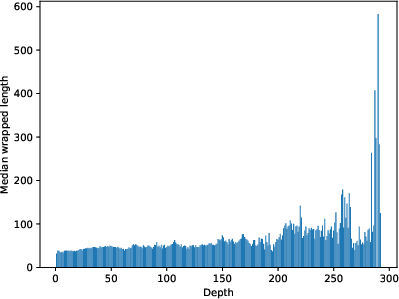
- Wrapped length stays about the same across depth. Deeper ideas don’t need longer statements; we keep building in manageable, human-sized chunks.
- Unwrapped length grows exponentially with wrapped length. A little more writing often hides a lot more underneath.
They even found one item that, when fully “unwrapped,” expands to about 10104 primitive pieces (a “googol” and more). These patterns match the model and don’t match the model. That supports the idea that human mathematics lives in a thin, highly compressible slice of all possible formal reasoning.
Why is this important?
- It explains why mathematical ideas feel elegant: definitions and theorems are powerful shortcuts that compress massive amounts of detail into short, reusable packages.
- It suggests that “human mathematics” is a tiny, structured, compressible part of the much larger space of all possible proofs. That helps us understand what kinds of ideas humans value.
What could this change or help in the future?
- Guiding AI to find interesting math: If compression is a sign of “interesting,” then AI tools can score how much a concept compresses (or is compressed by) others. This can act like a compass, pointing search toward fruitful areas.
- Ranking and discovery: A PageRank-style score (like how search engines rank web pages) on the dependency graph can highlight central, influential ideas. That can help both humans and machines focus attention where mathematical value concentrates.
- Better libraries and learning: Seeing where compression happens helps structure libraries, write clearer definitions, and teach concepts in the most powerful order.
In short: the paper argues that the magic of mathematics is compression—building layered shortcuts that let us say a lot with a little—and backs this up with both simple models and real data from a major math library.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following concrete gaps highlight what remains uncertain or unexplored and can guide future research:
- Formal identification of a “macro set” for human mathematics (HM): the paper models macros abstractly but does not extract or define a canonical macro inventory from MathLib (e.g., which declarations count as macros vs primitives, treatment of lemmas vs definitions vs tactics). Develop operational criteria and algorithms to recover a macro set from a formal library.
- Sensitivity to primitive choices: results depend on designating Lean core and Sort as “primitives.” Quantify how unwrapped length, depth, and inferred expansion change under alternative primitive sets (e.g., include subsets of MathLib core, typeclasses, or basic algebraic structures).
- Wrapped-length metric robustness: token-based wrapped length avoids tactic expansion artifacts but may undercount proof complexity. Compare with (i) reference-count-based length after normalization, (ii) tactic expansion to canonical micro-steps, and (iii) compressed AST size; assess which best approximates description length.
- Depth definition sensitivity: only longest-path depth is used. Evaluate alternative depth notions (e.g., average depth, weighted depth by multiplicities, or proof-depth vs definition-depth) and their effect on scaling laws.
- DAG vs full deduction hypergraph (DH): MathLib is a DAG projection that omits alternative proofs and hyperedges. Develop methods to reconstruct or approximate the DH and test whether compression findings persist when proof multiplicity and inference structure are restored.
- Collapsing strongly connected components: ~60 SCCs were collapsed to force acyclicity. Quantify the impact of this collapse on unwrapped length and depth, and explore principled handling of recursive definitions without collapsing.
- Tail behavior and finite-size effects: the paper notes frontier truncation. Perform longitudinal analyses (multiple MathLib snapshots) to model how tails of depth and unwrapped length evolve, and estimate asymptotic exponents with confidence intervals.
- Replication across ecosystems: validate findings in Coq, Isabelle, HOL, and Agda libraries; assess whether “A_n-like” compression generalizes beyond Lean/MathLib and across mathematical subfields.
- Domain heterogeneity: disaggregate by area (algebra, topology, analysis, geometry, category theory) to test whether compression rates, depth profiles, and wrapped-length constancy differ by domain.
- Statistical rigor of scaling claims: provide formal regressions, uncertainty quantification, and model comparisons (e.g., linear vs piecewise-linear vs subexponential fits) for log(unwrapped) vs depth and vs wrapped length, including robustness to outliers and leverage points.
- Measuring realized expansion vs expansion function: the data report achieved |u|G per element; the model’s f{G'}(s) measures coverage. Design procedures to empirically estimate f_{G'}(s) (e.g., by enumerating elements within a given wrapped budget) and compare to theory.
- Polylog-density gap in A_n: Theorem on polylog macro density gives only an upper bound (quasi-exponential). Construct matching lower-bound macro sets or prove tighter impossibility results to close the gap.
- Explicit constructions in F_n beyond probabilistic existence: Theorem on superlinear expansion employs random macro sets with vanishing sphere density. Find explicit, structured macro families realizing superlinear expansion and characterize minimal density thresholds.
- Intermediate-density thresholds in F_n: precisely locate the transition between linear and superlinear expansion as a function of macro density (ball vs sphere density), and determine sharp constants.
- Extent and proofs for free nilpotent monoids: the paper claims A_n results extend “straightforwardly” to free nilpotent monoids. Provide full statements, proofs, and empirical tests matching MathLib data to a calibrated nilpotent class.
- Partially commutative/trace monoid models: HM likely exhibits selective commutativity. Develop and test models between A_n and F_n (trace monoids, right-angled Artin monoids/groups) and infer an empirical “degree of commutativity” from MathLib.
- Alignment between monoid macros and typed dependent type theory: map monoid tokens to type-directed constructs (binders, implicit arguments, typeclass resolution) to validate that compression phenomena are not artifacts of ignoring type-level computation.
- Treatment of tactics and automation: current wrapped-length measure treats powerful tactics as single tokens. Normalize proofs to a standardized micro-step form to measure “true” deductive compression independent of automation.
- Subexpression sharing vs full flattening: unwrapped length fully expands all references, possibly overestimating “size” relative to DAG sharing. Compare with DAG-size or shared-term counts to assess whether compression stems from reuse vs depth.
- Macro budget and human parsimony: empirically estimate macro density as a function of radius in MathLib (e.g., growth of reusable mid-level lemmas/defs) and test whether it is logarithmic or polynomially sparse as hypothesized.
- Testing HM ⊂ FM polynomial-in-exponential claim: beyond anecdotal support, design quantitative tests that compare growth rates of “human-valued” regions vs synthetic random FM regions (e.g., random proofs/lemmas in proof search spaces).
- Interest measures and PageRank-style scoring: the paper proposes deductive and reductive compression metrics and a PageRank refinement but does not implement or validate them. Build these scores, release rankings, and correlate with expert judgments, usage frequencies, and downstream impact.
- Guidance for automated reasoning: demonstrate that compression-guided search (using the proposed interest measures) improves theorem proving success, discovery of reusable lemmas, or search efficiency compared to baselines.
- Causality vs correlation: determine whether compressible regions cause mathematical interest or whether editorial and tooling biases (e.g., library curation, typeclass inference) create the appearance of compression. Use controlled experiments or synthetic corpora.
- Data and pipeline reproducibility: provide full code and artifacts for dependency extraction, tokenization, depth computation, and length metrics; include ablation studies for key design choices (primitives, tokenization, SCC handling).
- Cross-validation with informal HM: compare formal-library compression to compression in human-authored mathematics (textbooks, survey articles) via MDL/Kolmogorov-complexity proxies to test whether the compression thesis holds outside formal proof assistants.
- Calibration of “1 bit per level” claim: verify the slope across scales, modules, and time; check for curvature, breakpoints, or depth-dependent deviations; and relate observed slopes to theoretical macro-density predictions.
- Bridging existence proofs to practice: the probabilistic F_n construction ensures macros that “halve” words exist almost surely; investigate constructive analogues aligned with HM semantics (e.g., structural repetition, periodicity, algebraic normal forms).
- Effects of multiplicity-only modeling: the dependency graph counts references without order. Analyze whether ignoring order loses essential structure for modeling proof compression and whether order-aware models change conclusions.
- Formal definition of an HM “measure” on FM: the paper suggests HM may be a fading measure on FM rather than a crisp subset. Provide a concrete, computable definition and empirical estimation procedure.
Glossary
- Aleph: a theorem-proving system for Lean used to formally verify results. "The \leanproof{} symbol below indicates that the theorem has been formally verified in Lean~4 by Aleph \cite{Aleph}."
- AM–GM inequality: the arithmetic mean–geometric mean inequality, a classical bound relating products and sums. "where the right-most inequality follows from AM-GM with :"
- ball (in a monoid): the set of elements of length at most a given radius with respect to a generating set. "Here, the ball of radius is , with defined analogously."
- Borel–Cantelli lemma: a probabilistic result stating that events with summable probabilities occur only finitely often almost surely. "By Borel--Cantelli, almost surely for all large ."
- Chernoff bound: a tail bound for sums of independent random variables that controls deviations from the mean. "A Chernoff bound gives"
- depth (in a dependency DAG): the length of the longest path from an element to primitives in the dependency graph. "Each element has a depth (layers of definitional nesting), a wrapped length (tokens in its definition), and an unwrapped length (primitive symbols after fully expanding all references)."
- directed acyclic graph (DAG): a directed graph with no cycles, used to encode dependency structures. "MathLib can be viewed as a DAG extracted from the full deduction hypergraph (Fig.~\ref{fig:dh-vs-dag})."
- directed hypergraph (DH): a generalization of a directed graph where hyperedges connect multiple premises to a conclusion. "Formal mathematics can be viewed as a directed hypergraph (DH) emerging from axioms and syntactical rules \cite{BDF}."
- elaboration (Lean): the compilation phase that resolves tactics and implicit arguments into concrete references. "tactics such as {simp} and {rw} expand during elaboration into many internal references to basic elements,"
- expansion function: a function measuring the coverage gain from using macros by comparing balls in different generating sets. "We quantify the effectiveness of such a strategy with the expansion function,"
- free abelian monoid (): a commutative monoid freely generated by n symbols, where order of generators does not matter. "We study two basic monoids on generators : the free abelian monoid and the free monoid ."
- free monoid (): the monoid of all finite strings over n generators with concatenation and no relations. "We study two basic monoids on generators : the free abelian monoid and the free monoid ."
- free non-abelian monoid: a free monoid in which generator order matters (non-commutative). "In the free non-abelian monoid , even a polynomially-dense macro set only yields linear expansion;"
- free nilpotent monoids: monoids with a nilpotent commutator structure, here considered in their free form. "Our study of macro sets in extends straightforwardly to the much larger class of free nilpotent monoids;"
- hyperedge: a relation in a hypergraph that connects multiple premises to an inference step. "In the DH, filled dots represent hyperedges: each groups the premises used in a single inference step."
- Lagrange's four-square theorem: the theorem that every nonnegative integer is a sum of four squares. "For , Lagrange's four-square theorem gives ,"
- Lean 4: a modern interactive theorem prover and programming language underpinning MathLib. "We test these models against MathLib, a large Lean~4 library of mathematics that we take as a proxy for HM."
- logarithmic density: a sparsity regime where the number of macros up to radius r grows on the order of log r. "has logarithmic density and satisfies"
- macro: a named substring or derived generator that abbreviates a longer expression for reuse. "a definition or theorem is a named substring or macro whose use compresses the string."
- macro set: the collection of macros added to a generating set, representing a compression strategy. "A macro set consists of additional generators, each defined by for some word "
- MathLib: a large community-maintained library of formalized mathematics for Lean. "We test these models against MathLib, a large Lean~4 library of mathematics that we take as a proxy for HM."
- PageRank-style analysis: a ranking approach inspired by PageRank to score importance within a graph. "and a PageRank-style analysis of that graph can quantify mathematical interest"
- polylogarithmic growth: growth bounded by a power of a logarithm in the size parameter. "be a macro set with polylogarithmic growth:"
- polynomial density: a regime where the number of macros within a ball grows polynomially with radius. "Polynomial density gives linear expansion"
- quasi-exponential (expansion): growth of the form between polynomial and exponential, e.g., exp(O(s log s)). "we next establish an upper bound: with polylogarithmically many macros, expansion is at most quasi-exponential."
- rw (Lean tactic): a Lean tactic that rewrites expressions using equalities or equivalences. "tactics such as {simp} and {rw} expand during elaboration into many internal references"
- simp (Lean tactic): a Lean tactic that simplifies expressions via rewrite rules and known lemmas. "tactics such as {simp} and {rw} expand during elaboration into many internal references"
- sphere density: the fraction of words of a fixed length that are chosen as macros. "The sphere density of satisfies ."
- strongly connected component: a maximal subgraph in which every vertex is reachable from every other vertex. "we collapse each strongly connected component into a single vertex, reducing the vertex count from 463,719 to 463,661."
- union bound: an inequality bounding the probability of a union of events by the sum of their probabilities. "By a union bound over all , "
- unwrapped length: the count of primitive symbols after recursively expanding all references in a definition. "The unwrapped length counts the primitives in the flattened string."
- vanishing sphere density: a condition where the fraction of macros among words of a given length tends to zero as length grows. "The next result shows that a macro set of vanishing sphere density---though still exponentially large in absolute terms---allows for superlinear expansion."
- Waring constant: the minimal number g(k) so every integer is a sum of at most g(k) k-th powers. "where is the Waring constant (the smallest integer such that every nonnegative integer is a sum of at most -th powers)."
- Waring's theorem: the theorem that every integer is a sum of a bounded number of k-th powers, for each fixed k. "via Waring's theorem (Theorem~\ref{thm:abelian-waring})."
- wrapped length: the number of tokens in an element’s defining expression before expansion. "The wrapped length counts the tokens in an element's defining expression;"
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed with today’s tooling, especially where formal corpora (e.g., Lean/MathLib) or dependency graphs already exist.
- CompressionScore and InterestRank dashboards for formal libraries
- Sector: software, AI/ML, academic infrastructure
- Use case: Build a dashboard that computes (i) deductive compression (statement length vs. fully unwrapped primitive length), (ii) reductive compression (degree to which definitions simplify expression trees), and (iii) a PageRank-style InterestRank over the dependency DAG to prioritize elements that “unlock” large regions of mathematics.
- Tools/products/workflows: Lean/Coq/Isabelle plugin; nightly CI job that extracts graphs (using the paper’s dependency-collection approach), computes scores, and surfaces heatmaps and leaderboards for maintainers and users.
- Assumptions/dependencies: Requires access to the internal dependency graph; consistent tokenization; acceptance that compression correlates with “mathematical interest.”
- Compression-guided proof search heuristics
- Sector: AI theorem proving, software
- Use case: Bias automated proof search toward regions/elements with high compression or high InterestRank, improving success rates and proof concision in Lean/Coq/Isabelle.
- Tools/products/workflows: Modify tactic engines/ATPs to score intermediate lemmas and goals by expected expansion; prune uncompressible branches; prioritize “Aₙ-like” (abelian/nilpotent) subspaces where exponential gains are likely.
- Assumptions/dependencies: Heuristic assumes MathLib-like compression patterns generalize; performance evaluation needed to avoid missing valid but “hard” (Fₙ-like) proofs.
- Definition/macro mining and refactoring suggestions
- Sector: software engineering, formal methods, developer tooling
- Use case: Suggest new definitions when repeated substructures cause large unwrapped lengths; surface candidates that would reduce wrapped length while preserving proof modularity.
- Tools/products/workflows: Static analysis on proof/code graphs; IDE lint that flags “high expansion, low abstraction” regions; automated PRs proposing named macros.
- Assumptions/dependencies: Requires good signal-to-noise threshold to avoid polluting libraries with low-value definitions; maintainers’ governance.
- Prioritization of library development and curation
- Sector: open-source math libraries, publishing
- Use case: Identify underdeveloped regions with high potential compression (large unwrapped length but shallow depth or low wrapped length), and direct contributor effort to maximize impact.
- Tools/products/workflows: Contributor issue queues ranked by InterestRank; triage meetings using compression heatmaps.
- Assumptions/dependencies: Community buy-in that these metrics capture value; availability of maintainers to act.
- Curriculum design and courseware authoring
- Sector: education, edtech
- Use case: Design syllabi with roughly constant statement length per “level” and exponential growth in conceptual reach across levels—mirroring the MathLib observation that wrapped length stays roughly constant while unwrapped length explodes with depth.
- Tools/products/workflows: Course planners map dependencies among concepts, optimize for hierarchical depth rather than bloated lesson size; adaptive tutors prioritize compressible conceptual chains.
- Assumptions/dependencies: Requires mapping course content to a dependency graph; assumes compressibility correlates with learnability/transfer.
- Ranking and discovery in mathematical search portals
- Sector: academic search/publishing
- Use case: Re-rank theorem/lemma search results by InterestRank and compression to surface definitions that enable the most reuse and downstream reasoning.
- Tools/products/workflows: Integrate scores into Mathlib/Arxiv/GPT-based math assistants; “This lemma unlocks X downstream results” indicators.
- Assumptions/dependencies: Effective indexing of dependency graphs; user studies to validate improved discovery.
- Compression-aware summarization for research assistants
- Sector: AI/ML, productivity tools
- Use case: Summarize papers or proof scripts by highlighting high-compression statements (short statements with massive proof bodies), helping researchers focus on pivotal ideas.
- Tools/products/workflows: LLM-based assistants that read proofs, compute compression metrics, and produce structured summaries and reading paths.
- Assumptions/dependencies: Reliable extraction from PDFs/LaTeX or proof systems; alignment between compression and human relevance.
- Knowledge base maintenance in enterprises
- Sector: software, knowledge management
- Use case: Apply compression metrics to internal technical wikis/docs to detect when introducing named concepts (macros) would massively reduce duplication and cognitive load.
- Tools/products/workflows: Dependency graph extraction (e.g., from cross-references), refactoring suggestions, glossary generation.
- Assumptions/dependencies: Requires consistent cross-referencing or embeddings to approximate dependencies.
- Planning and skill libraries in robotics and operations
- Sector: robotics, operations research
- Use case: Prefer hierarchical skill “macros” that compress many low-level actions (Aₙ-like regions), improving plan reuse and interpretability.
- Tools/products/workflows: Re-rank candidate plans by compression; option discovery pipelines that mine reusable macro-actions.
- Assumptions/dependencies: Assumes task structure admits reusable macro actions; availability of plan graphs.
- Factor-model and feature engineering hygiene
- Sector: finance, ML engineering
- Use case: Encourage “macro” features that compress many raw features (e.g., factor exposures), guiding towards hierarchical models that generalize better and reduce overfitting.
- Tools/products/workflows: Feature graphs with compression scores; refactor alerts when models over-rely on Fₙ-like, bespoke sequences.
- Assumptions/dependencies: Mapping features to dependency graphs; empirical validation on target tasks.
- Grant/project portfolio triage (pilot use)
- Sector: policy, research management
- Use case: Use proxy dependency graphs (citations, prerequisite matrices) and compression/InterestRank to prioritize proposals that create powerful, reusable abstractions.
- Tools/products/workflows: Internal scoring dashboards augmenting peer review.
- Assumptions/dependencies: Proxy graphs are coarse vs. formal proofs; should complement—not replace—peer assessment.
- Personal knowledge management (PKM) workflows
- Sector: daily life, productivity
- Use case: Organize notes as nested definitions/concepts to maximize compression; set goals for “constant wrapped length per level” while increasing depth for reach.
- Tools/products/workflows: Note-taking apps that visualize dependency depth and suggest “macro notes.”
- Assumptions/dependencies: Requires user discipline and software support for graph views.
Long-Term Applications
These require additional research, scaling, or development, including broader validation beyond MathLib and new algorithmic advances.
- Compression-aware AI mathematicians (“stay where HM lives”)
- Sector: AI/ML, academic research
- Use case: Full-stack proof agents that track deductive/reductive compression and InterestRank to navigate formal mathematics, selecting conjectures and proof paths in the most compressible subspaces.
- Tools/products/workflows: Joint learning of macro sets and search policies; interaction layers for Lean/Isabelle with feedback on compression gradients.
- Assumptions/dependencies: Robust generalization of MathLib findings; scalable graph analytics; community integration.
- Automated macro-set discovery (owner’s manual for HM)
- Sector: AI research, software tooling
- Use case: Learn a near-minimal set of definitions/lemmas that maximizes exponential expansion (Aₙ-like regimes) for a field, akin to discovering powers-of-10 for new domains.
- Tools/products/workflows: Structure learning over dependency graphs; objective functions that trade off macro density vs. expansion; ablation studies.
- Assumptions/dependencies: Feasible optimization landscape; human-acceptable abstractions; version control for evolving libraries.
- Compression-guided curriculum learning for foundation models
- Sector: AI/ML
- Use case: Train LLMs/TPPs on sequences that explicitly build hierarchical depth with bounded “wrapped” complexity per level to improve reasoning and transfer.
- Tools/products/workflows: Data curation pipelines that score and stage training samples by depth and compression; new pretraining objectives that reward compressibility.
- Assumptions/dependencies: Correlation between compression curricula and downstream performance; data availability with usable graphs.
- Generalization to other formal domains (law, circuits, biology)
- Sector: legal tech, EDA, biomedicine
- Use case: Apply Aₙ vs. Fₙ regime diagnostics to legal codebases, hardware libraries, or pathway models to find compressible abstractions and prioritize reusable precedents/modules.
- Tools/products/workflows: Domain-specific parsers to construct dependency graphs; compression scoring; “macro” proposals (e.g., legal doctrines, circuit macros).
- Assumptions/dependencies: Faithful graph extraction; domain acceptance of abstraction proposals.
- New evaluation metrics for research impact
- Sector: academia, policy
- Use case: Complement citations with measures of compressive leverage (how much a result reduces dependency length or increases reusable expansion).
- Tools/products/workflows: Bibliometric services integrating dependency-aware indices; dashboards for institutions/funders.
- Assumptions/dependencies: Constructing reliable “proof-like” or prerequisite graphs from publications; careful field normalization.
- Proof and program synthesis with expansion targets
- Sector: software, formal methods
- Use case: Synthesize proofs/circuit blocks/APIs to meet target expansion profiles (e.g., exponential coverage with logarithmic macro density), improving modularity and maintainability.
- Tools/products/workflows: Objective-guided synthesis that optimizes for compression; post-synthesis refactoring to introduce high-yield macros.
- Assumptions/dependencies: Objective alignment with functionality/performance; acceptance of synthesized abstractions.
- Hybrid abelian–nonabelian modeling to forecast effort
- Sector: R&D planning, project management
- Use case: Predict where progress will be “cheap” (Aₙ-like, compressible) vs. “expensive” (Fₙ-like, order-sensitive) within a project’s dependency space to allocate resources.
- Tools/products/workflows: Mixed-regime classifiers over graphs; effort estimators tied to macro density vs. expansion predictions.
- Assumptions/dependencies: Reliable signals to classify subgraphs; cross-domain validation.
- PageRank-like “interest markets” for automated exploration
- Sector: AI research automation
- Use case: Allocate compute budgets to conjectures/lemmas based on dynamic InterestRank, forming autonomous exploration markets that shift toward compressible frontiers.
- Tools/products/workflows: Bandit algorithms over graph nodes; reinforcement learning with compression-based rewards.
- Assumptions/dependencies: Preventing mode collapse on “too easy” regions; governance for shared compute.
- Standards for compressibility-aware documentation and APIs
- Sector: software, standards bodies
- Use case: Establish guidelines that APIs/modules should enable logarithmic-density macro reuse with exponential expansion—encouraging composable design.
- Tools/products/workflows: Static checks for compressibility; design reviews using expansion curves.
- Assumptions/dependencies: Consensus on metrics; tooling sophistication; cost of retrofitting legacy systems.
- Cross-modal knowledge distillation via compression
- Sector: education, publishing, AI/ML
- Use case: Translate compressible dependency chains into teaching modules, interactive texts, or multi-modal content that preserves expansion while minimizing cognitive load.
- Tools/products/workflows: Authoring systems that auto-generate learning paths from proof graphs; adaptive assessments keyed to depth.
- Assumptions/dependencies: Accurate mapping from proofs to pedagogy; user studies for efficacy.
- Policy frameworks for funding compressible knowledge
- Sector: policy
- Use case: Pilot frameworks where program calls emphasize creation of re-usable, high-expansion abstractions (definitions, tools, datasets), tracked by compression metrics.
- Tools/products/workflows: Portfolio analytics; milestone tracking driven by shifts in InterestRank.
- Assumptions/dependencies: Community validation; safeguards against gaming metrics; equity across fields.
Notable Assumptions and Cross-Cutting Dependencies
- The core premise—that human-valued mathematics (HM) aligns with highly compressible, hierarchical structures consistent with free abelian/nilpotent monoids—may not hold uniformly across all domains or subfields.
- Metrics depend on how “wrapped” vs. “unwrapped” length and “depth” are defined; tokenization and elaboration artifacts can bias results without careful normalization.
- Extracting high-fidelity dependency graphs is non-trivial outside formal systems; proxy graphs (citations, hyperlinks) introduce noise.
- The InterestRank/PageRank analogy presumes that supporting high-value results is a robust proxy for “interest”; empirical validation is required.
- Introducing many macros/definitions can create cognitive overhead; parsimony constraints and community norms must be respected.
These applications operationalize the paper’s key finding: that the regions where humans do (and prefer) mathematics are those that enable large expressive reach with sparse, hierarchically nested concepts—and that compression can be measured and used to steer tools, curricula, and automated reasoning toward those regions.
Collections
Sign up for free to add this paper to one or more collections.