- The paper demonstrates that symbolic regression discovers novel and compact parametrizations for implied volatility, surpassing the traditional SVI model.
- It introduces a framework that integrates arbitrage constraints and k-means clustering to enhance empirical fitting and reduce overfitting.
- Empirical results show that candidate expressions, such as f4(x), achieve lower complexity and improved log-loss performance across various quantile levels.
Data-Driven Discovery of Parametrizations for Implied Volatility via Symbolic Regression
Introduction
Parametric modeling of implied volatility (IV) surfaces is a central task for option market makers, facilitating interpolation, extrapolation, and validation of market quotes. Conventional approaches such as the SABR model and the SVI (Stochastic Volatility Inspired) parametrization have achieved broad adoption due to their empirical performance and interpretability. This paper investigates the possibility of discovering alternative, concise analytic parametrizations for IV slices using symbolic regression, thereby eschewing predefined functional forms. The methodology seeks to identify new candidate representations for total implied variance as a function of log-moneyness and maturity, directly from market data, and benchmarks their efficacy and complexity relative to SVI.
Symbolic Regression Framework and No-Arbitrage Considerations
Symbolic regression, as implemented via PySR, exhaustively searches for expressions mapping log-moneyness and maturity to implied variance, parameterized by slice-specific parameter vectors. Unlike standard regression techniques, symbolic regression does not constrain the functional form a priori, instead drawing upon a broad set of base functions (arithmetic, exponential, logarithmic, hyperbolic, etc.). The SVI model, for instance, arises in this framework as a relatively low-complexity expression.
In addition to empirical fit, the approach incorporates market viability constraints—specifically Lee's tail bounds—through penalization terms in the global objective. Durrleman's condition (relating to butterfly arbitrage) is monitored post-hoc, as its inclusion in the loss considerably complicates optimization. To address the prohibitive computational cost resulting from the large number of IV slices, k-means clustering reduces the optimization problem by aggregating slices into representative clusters.
The symbolic regression methodology is evaluated on two data sets: a comprehensive longitudinal SPX IV set (D1) and a curated sample of unusual volatility smiles (D2). Fitting performance is quantified through log-loss against the SVI baseline, with a focus on the complexity-accuracy tradeoff.
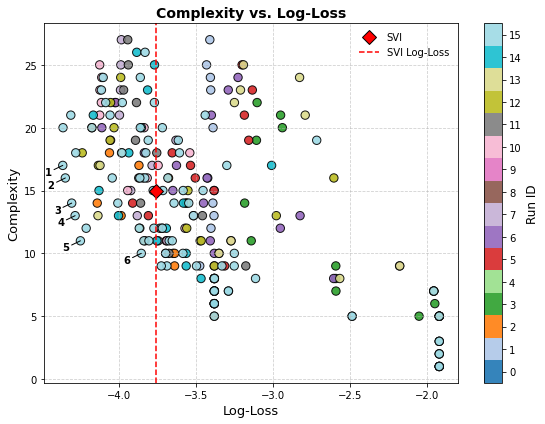
Figure 1: Complexity vs. log-loss for symbolic regression results, highlighting expressions on the efficient frontier outperforming SVI.
The analysis surfaced several candidate expressions with lower complexity and improved log-loss relative to SVI. Notably, the expression f4(x)=p4(tanh(p1x)+p2)(p3+x)+p5 exhibited both reduced complexity and superior empirical fit, with only minor increases in the arbitrage indicator αK. The efficient frontier analysis underscores symbolic regression's capacity to generate novel, compact parametrizations that rival industry standards.
Distributional and Quantile Analysis of Fit
A detailed comparison of log-loss distributions for f4 versus SVI reveals consistent improvement across nearly all IV slices.
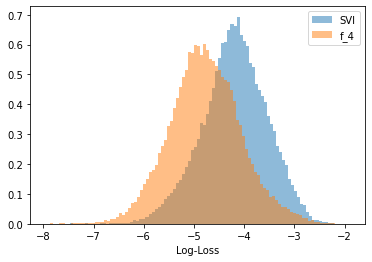
Figure 2: Log-loss distribution comparison between expression f4 and SVI.
Quantile analysis confirms robustness: f4 outperforms SVI at all quantile levels of fitting error, including lower decile, median, and upper decile cases.
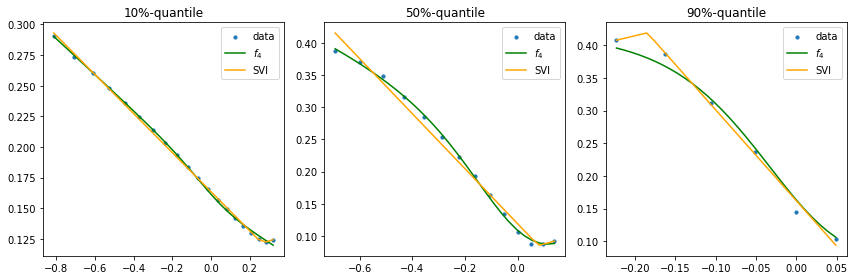
Figure 3: Three representative fits using f4 across 10\%, 50\%, and 90\% log-loss quantiles, with matched SVI fits for reference.
Parametrization Discovery on Curated Volatility Smiles
On the curated D2 set, symbolic regression reliably rediscovered SVI parametrization in slices where SVI is known to be near-perfect, especially when no-arbitrage penalization was activated. For more complex (e.g., W-shaped) slices, extensions of SVI with additive terms were identified, with 7- and 8-parameter forms fitting proprietary C6- and C8-types.
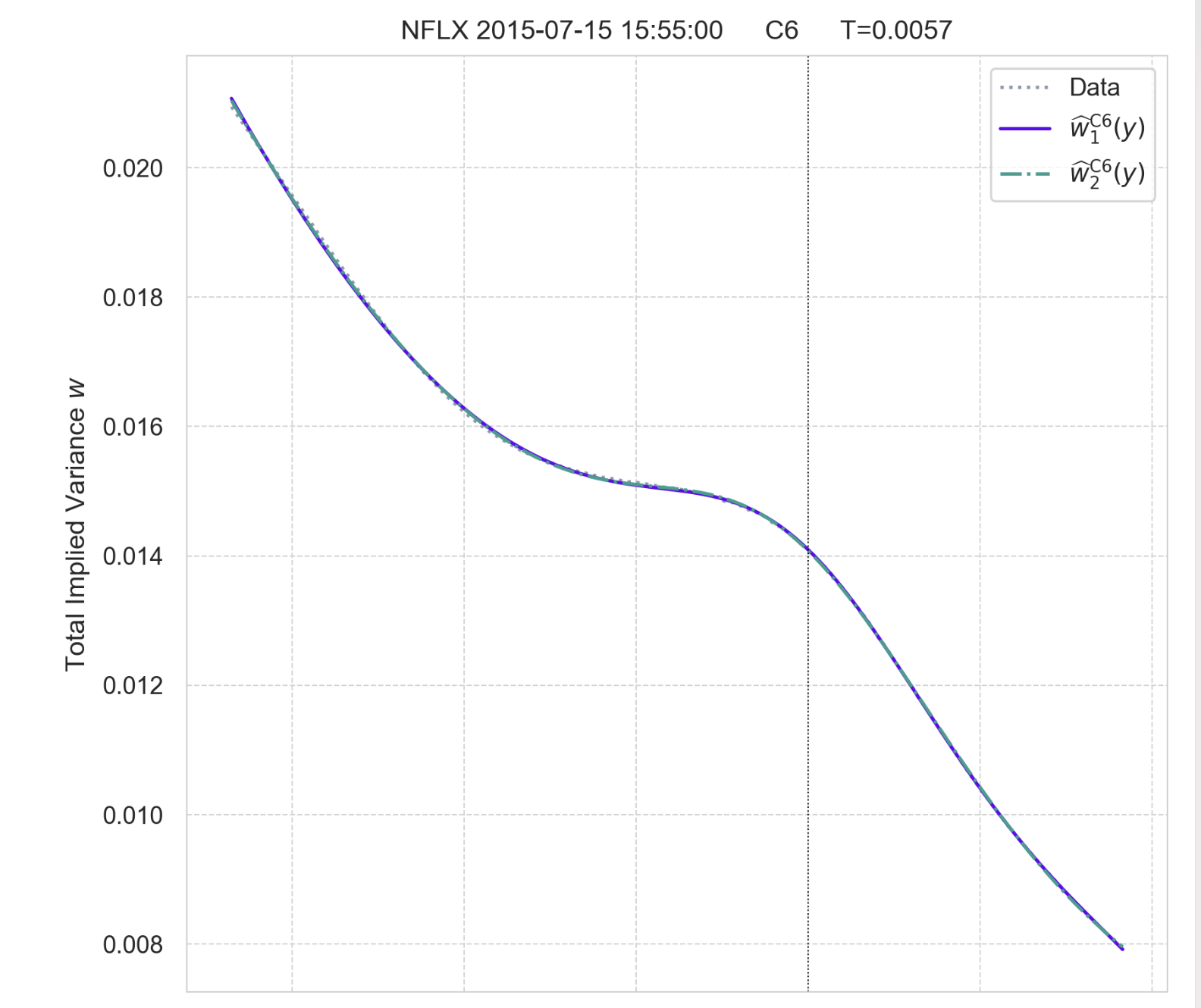
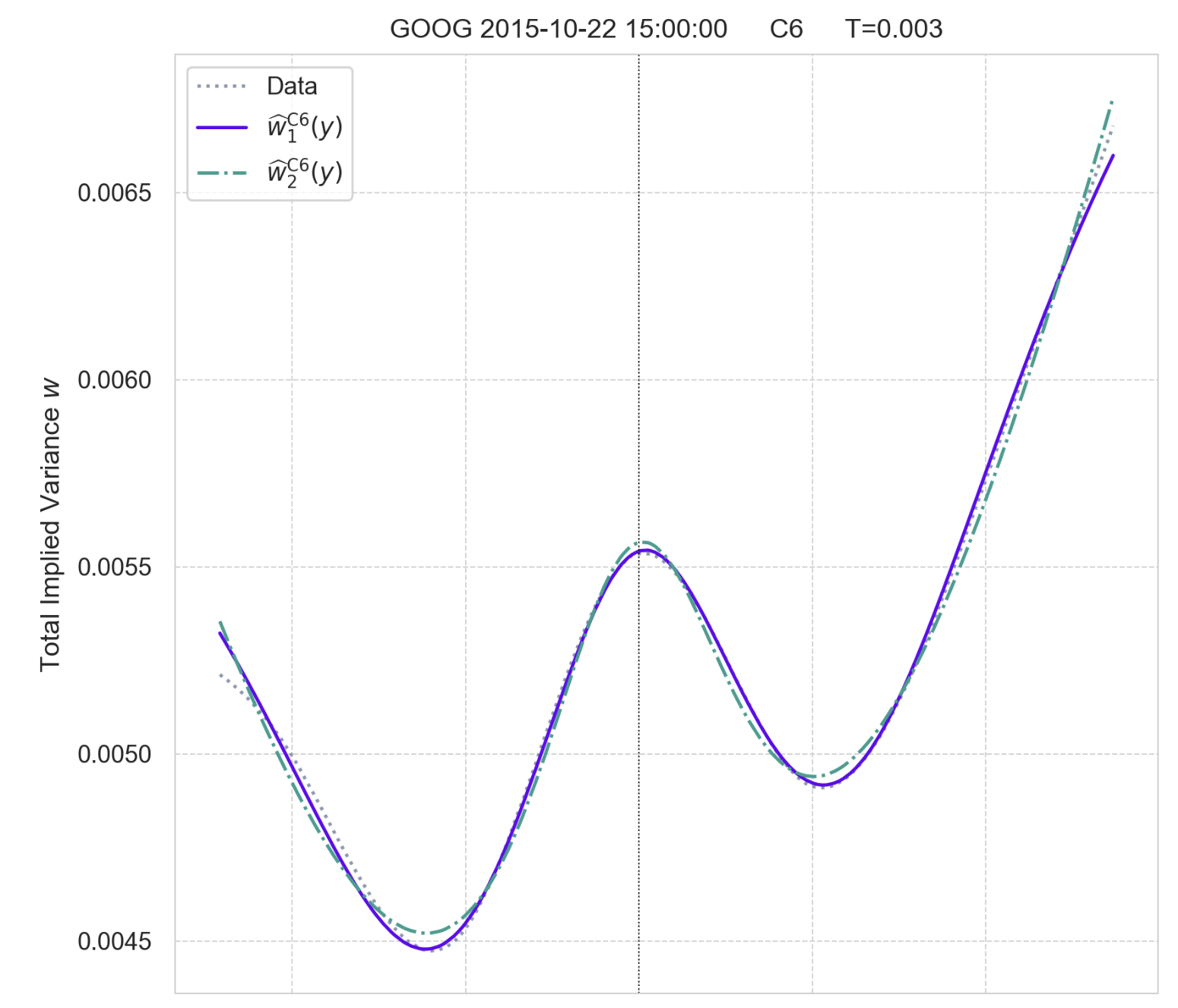
Figure 4: Fit of discovered C6-type parametrizations w^1C6 and w^2C6.
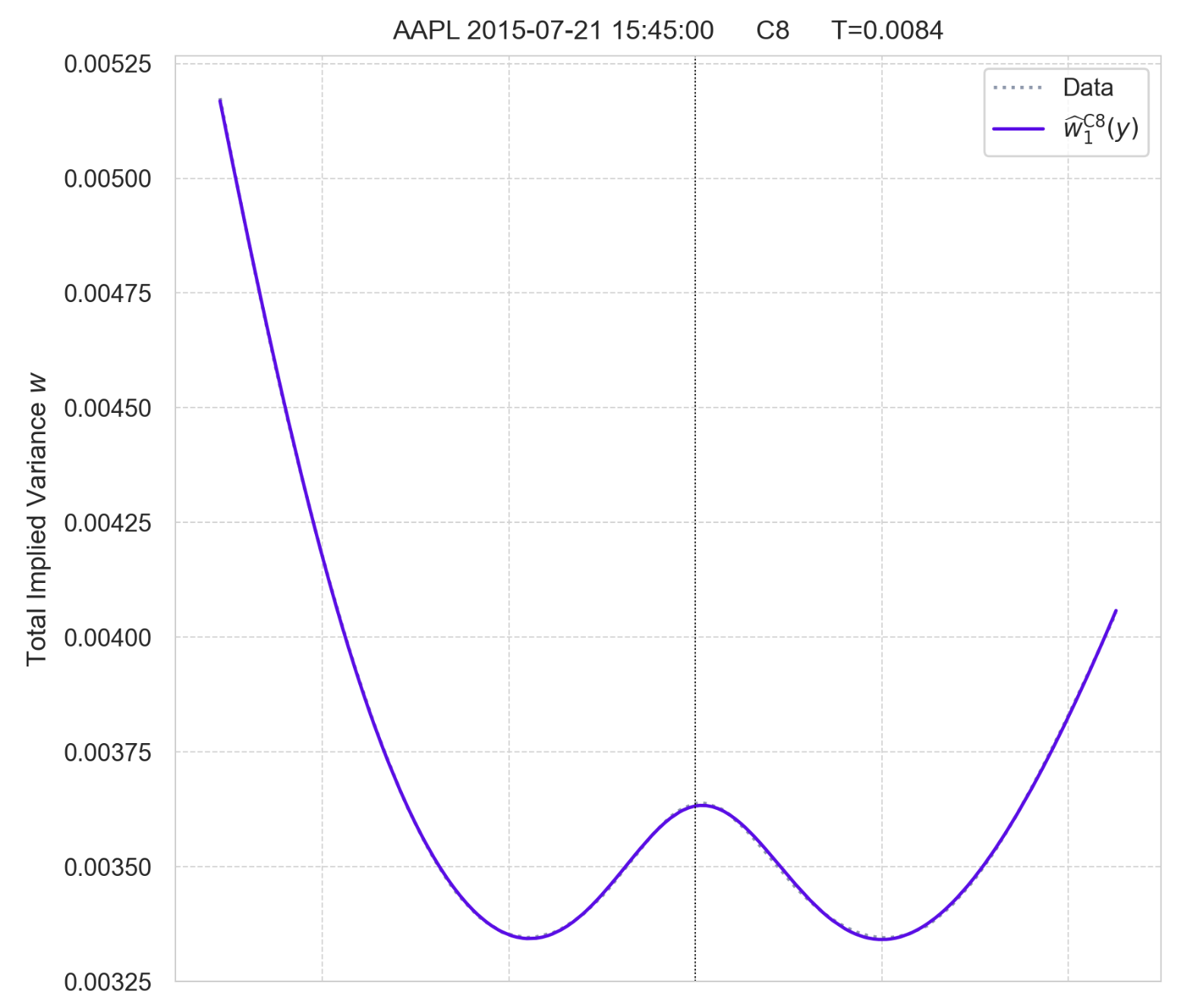
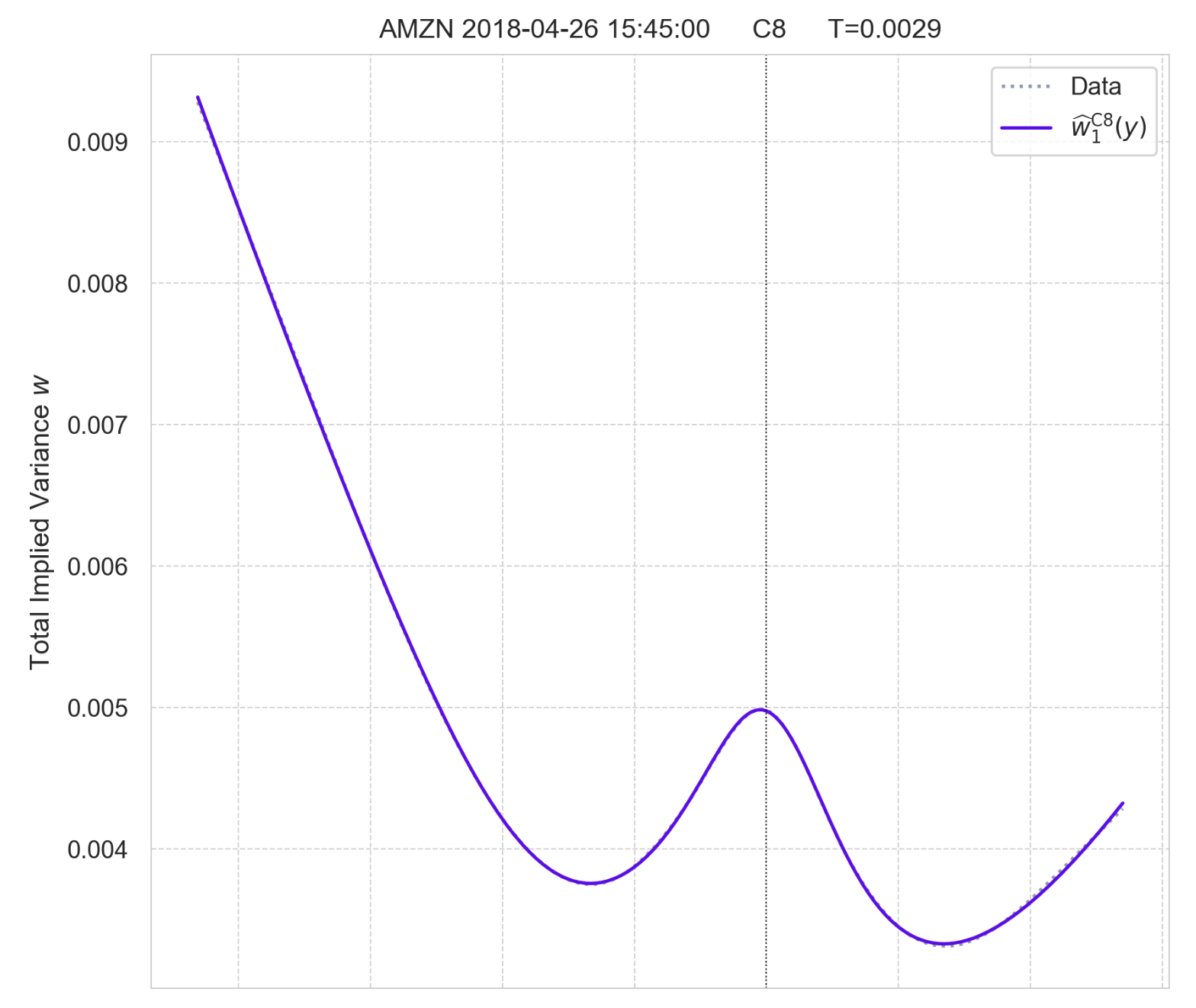
Figure 5: Fit of discovered C8-type parametrization w^1C8 to two C8-curves.
The discovered expressions extend SVI by additional nonlinear terms, enabling better modeling of anomalous slices without overfitting, as complexity penalties imposed by PySR act as a regularizer. The qualitative match across all curves in D2 further validates the method's flexibility.
Practical and Theoretical Implications
The study demonstrates that symbolic regression, under appropriately regularized complexity and arbitrage penalty, can discover analytic function families that are competitive with—if not superior to—SVI. The methodology generalizes well, avoids overfitting, and adapts to specialized IV patterns by learning extensions to canonical models. Incorporation of arbitrage constraints as penalties serves not only to enforce market viability but also as an effective inductive bias guiding search toward viable parametrizations.
Future work should address the computational integration of butterfly-arbitrage constraints (involving higher-order derivatives), and extend the approach to find parametrizations for whole volatility surfaces, capturing both strike and maturity jointly.
Conclusion
Symbolic regression provides a principled, data-driven avenue for uncovering new parametrizations of implied volatility that advance beyond traditional models in simplicity and fit. The approach is robust to overfitting, can rediscover established parametrizations, and flexibly adapts to atypical IV structures. The results highlight both the practical utility and theoretical relevance of symbolic regression in financial modeling, setting the stage for future enhancements in arbitrage-constrained optimization and surface-wide parametrization.