- The paper demonstrates that manifold recovery in diffusion models strictly outpaces density estimation by leveraging dominant local geometric structure.
- It introduces a novel δ-coverage criterion with minimax-optimal rates for recovering manifold projections, depending on the manifold's smoothness β.
- The findings reconcile empirical discrepancies and point to new architectures and training criteria that enhance privacy and data augmentation.
Manifold Generalization Provably Proceeds Memorization in Diffusion Models
Motivation and Problem Setting
Diffusion models deliver high-dimensional generative performance but exhibit a puzzling empirical fact: genuinely novel samples emerge predominantly during early training stages or under restricted score network capacity, when the learned score is notably inaccurate. This contradicts classical diffusion theory, which treats score learning as density estimation, predicting monotonic improvement in data fidelity as the score estimation improves. The paper investigates this discrepancy and formalizes the phenomenon under the manifold hypothesis: data is supported on a low-dimensional k-dimensional Cβ submanifold M⊂RD (k≪D). The operational target is not minimax density recovery but uniform coverage of the manifold at nontrivial spatial resolution.
Coverage and Statistical Rate Separation
The central technical contribution is a sharp statistical separation between geometry learning (manifold recovery) and density estimation. The authors introduce a coverage criterion: a distribution μ has δ-coverage of M if it assigns mass comparable to the population measure to every geodesic ball BM(y,δ) (y∈M). For empirical measures supported on N points, the finest possible resolution is O~(N−1/k), the classical minimax rate. However, the main claim is that diffusion models, trained only to coarse score accuracy, achieve coverage at much finer scale δ=O~(N−β/(4k)), depending only on manifold smoothness β.
Geometry Dominates Distribution in Score-Based Models
The core insight is the geometric expansion of the small-noise score function:
s⋆(x,t)=−tx−ProjM(x)+∇Mlogp(ProjM(x))+21H(x)+o(1)
where p is the on-manifold density, H mean curvature, and ProjM is the nearest-point projection. The leading term −(x−ProjM(x))/t dominates for small noise, rendering geometry (the manifold's projection structure) much easier to recover than the full population density. Subsequently, manifold recovery (and coverage) proceeds strictly faster than density estimation, especially in settings of irregular p.
Theoretical Guarantees and Algorithmic Realization
The hybrid sampler (reverse-time SDE down to t0, then probability-flow ODE to τ) reflects practical diffusion implementations. For sufficiently coarse scores, the terminal ODE stage essentially learns an approximate projection map. The main theorem asserts minimax-optimal Hausdorff recovery of M and uniform projection accuracy:
dHaus(M,M^)=O~(N−β/k),∥ProjM−Proj^∥∞=O~(N−β/(2k))
The resultant output distribution achieves δ-coverage at scale δ=O~(N−β/(4k)). Notably, this rate is strictly superior for large β compared to classical density estimation.
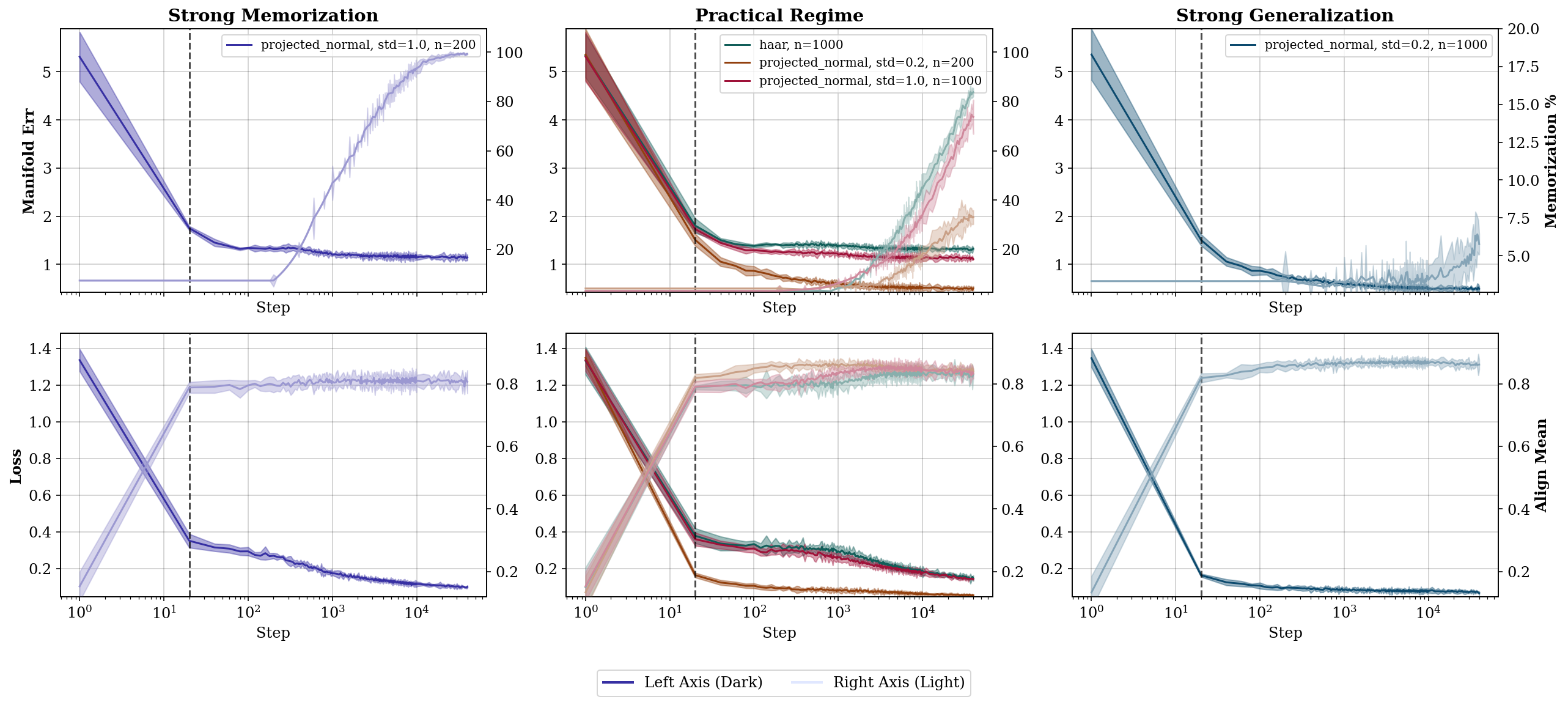
Figure 1: Manifold error drops rapidly while memorization rate stays low for coarsely optimized scores, indicating geometry learning precedes memorization; mean alignment demonstrates early recovery of projection geometry.
Function Classes and Local Representation
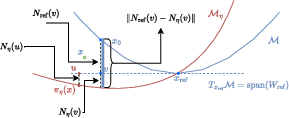
A rigorous characterization is provided for the function class underlying score recovery. Via the eikonal equation and local graph representation, member functions are shown to be distance-like, aligning the score network's implicit bias with projection geometry. The manifold's local chart admits a representation as a graph over the tangent space:
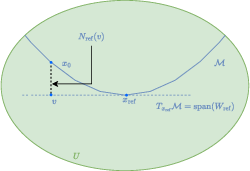
Figure 2: A local representation of a submanifold M∈Cβ by graphing a function over its tangent space neighborhood.
Both theoretical and analytic results ensure that, under mild regularity (reach and bounded derivatives), the learned score class induces smooth projection maps. The change of basis between hypothesis and ground-truth manifold is formalized with explicit bounds on derivatives:
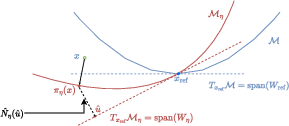
Figure 3: Visualization of the hypothesis score function class {sη} in local coordinates, illustrating unique projection and tangent representations.
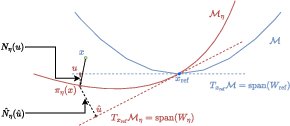
Figure 4: Change of basis for any x^ in M; coordinates in the hypothesis and ground truth basis are linked via invertible transformation.
Connection to Existing Literature and Contradictory Claims
The paper's statistical results contradict the standard paradigm where density recovery is necessary for generalization. Existing minimax manifold estimation frameworks (e.g., [AamariLevrard2019]) achieve similar rates for geometric recovery, but are fully nonparametric and do not provide coverage guarantees for diffusion models. Moreover, empirical literature on memorization mitigation and geometric diagnostics ([SSG23], [GDP23], [achilli2025memorization], [kadkhodaie2023generalization]) is reconciled via the geometric separation principle elucidated herein.
Practical and Theoretical Implications
Practically, the findings suggest that diffusion models can be reliably used to produce novel samples with strong manifold fidelity well before memorization or density fitting occurs, bolstering their utility in privacy and data augmentation scenarios. Theoretically, the separation between generalization and memorization calls for new architectural and training-criterion designs aligned with geometric inductive bias, potentially realized via physics-informed neural networks or modified score-matching objectives.
Future Directions
Several research avenues are laid out:
Conclusion
The analysis establishes that, under the manifold hypothesis, generalization in diffusion models is both provable and precedes memorization, mediated via fast geometric recovery of support rather than rigorous density estimation. This statistical and algorithmic separation motivates further developments in generative modeling that exploit data geometry, offering improved sample diversity and robustness in practice.
Reference: "Manifold Generalization Provably Proceeds Memorization in Diffusion Models" (2603.23792)