- The paper introduces a novel adversarial tracer that identifies causal representations in LMs without imposing geometric constraints.
- It uses a single-batch gradient procedure to induce and trace perturbations, revealing clear morphological, lexical, and syntactic abstraction with significant AUC improvements.
- The method demonstrates superior efficiency and selectivity compared to traditional probing techniques, offering robust insights into language model representation learning.
Perturbation: An Efficient Adversarial Tracer for Representation Learning in LLMs
Motivation and Theoretical Framing
This paper introduces perturbation, a formal and empirically robust method for causal representation discovery in deep LMs. The authors address longstanding methodological dilemmas in the study of neural representations—in particular, the trade-off between enforcing restrictive geometric constraints (e.g., linearity) and allowing excessive flexibility that trivializes representation discovery. Citing recent theoretical work, they demonstrate that probing and mechanistic interpretability methods such as DAS (Distributed Alignment Search) conflate correlational and causal structure, often finding representations in untrained models and failing to distinguish between linear and non-linear encodings. By reconceptualizing representations as conduits for learning, perturbation circumvents these dilemmas, grounding representation analysis in the transfer of induced perturbations across examples without geometric assumptions.
Perturbation Methodology
Perturbation operates by fine-tuning a LLM on a single adversarial remapping—modifying output probabilities for a critical region in context—and then systematically tracing the transfer (or "infection") of the perturbation to other examples. The framework defines remappings as 4-tuples over context and critical region in original and alternate strings. The perturbation objective is specified as the log-ratio,
L(M,p)=−log[p(Ro∣Co)p(Ra∣Ca)],
which is optimized via a single-batch gradient procedure, flipping the sign for gradients corresponding to the original critical region. Evaluation relies on a log odds-ratio of alternate/original predictions under perturbed and unperturbed models. Crucially, the method imposes no geometric constraints and is minimally supervised (requiring only the remapping design), increasing robustness to artifact-induced causal structures.
Results: Morphological, Lexical, and Syntactic Structure
Morphological Abstraction
The authors apply perturbation to morphological representations, specifically distinguishing deverbal from comparative uses of the English suffix -er, utilizing the BATS dataset and RoBERTa-large. In untrained models, transfer is dominated by shared tokenization effects. However, after training, transfer effects are tightly aligned to morphological class membership.
Key Numerical Result: AUC clusterability rises from 0.52 (untrained) to 0.89 (trained), with regression analyses confirming significant within-class transfer only in trained models (effect size = 1.73, p<0.001) and minimal between-class transfer (effect size = 0.003, p=0.97).
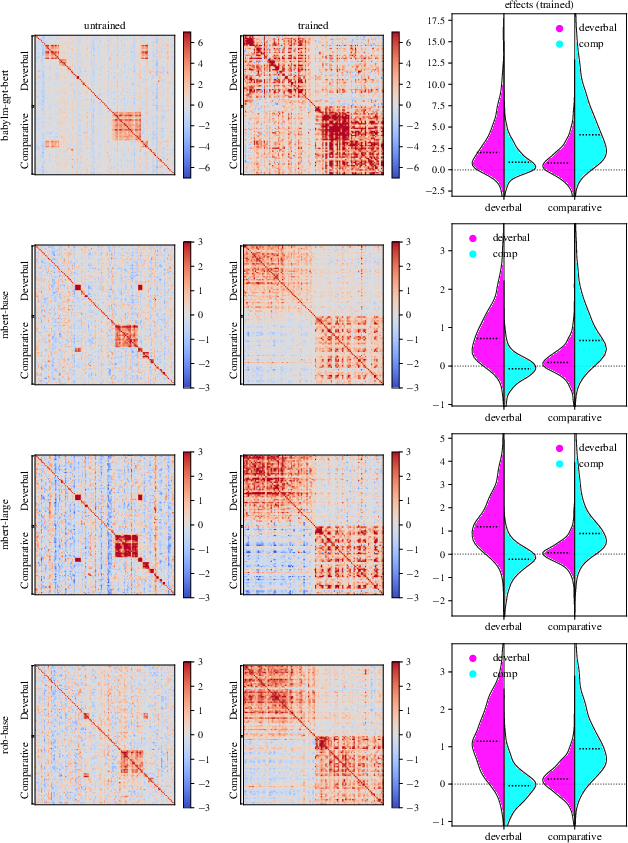
Figure 1: Transfer-based similarity heatmaps demonstrate discriminability for morphological class post-training, with effect distributions sharply concentrated along deverbal–comparative boundaries.
The implication is that LMs acquire stable morphological category representations, and perturbation efficiently distinguishes genuine representations from artifact-driven transfer.
Lexical Representation and Word Senses
For lexical abstraction, the authors target word sense disambiguation (WSD) using the CoarseWSD-20 dataset. They perturb models (ModernBERT-large, RoBERTa, GPT-BERT) by substituting ambiguous tokens with a nonce term and measure similarity matrices via transfer and cosine similarity (as a baseline).
Key Numerical Result: Perturbation achieves higher or comparable clusterability than the best oracle cosine baseline in 3/5 models (e.g., ModernBERT-L: perturbation AUC 0.871 vs. cosine best-layer AUC 0.801).
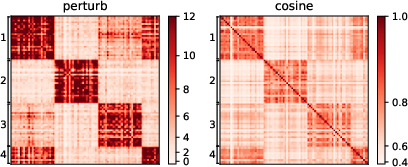
Figure 2: Similarity matrices for square reveal block structure corresponding to four annotated senses, with perturbation yielding finer sense clustering (AUC 0.94) than cosine similarity (AUC 0.87).
Perturbation thus substantiates the causal efficacy of word sense representations in trained LMs, outstripping correlational state similarity methods.
Syntactic Abstraction and Filler-Gap Constructions
The syntactic study uses perturbation to probe FG (filler-gap) dependency representations, leveraging a benchmark spanning wh-questions, relatives, clefts, pseudoclefts, and topicalization, with minimal and standard controls. Analyses trace transfer from FG perturbation across training epochs in Pythia-1.4B.
Key Numerical Result: Transfer to FG conditions diverges from non-FG only after 1k training steps, with baselined-transfer emerging at 2k–5k steps; between-condition transfer remains at chance in untrained models and becomes significant as FG abstraction is learned.
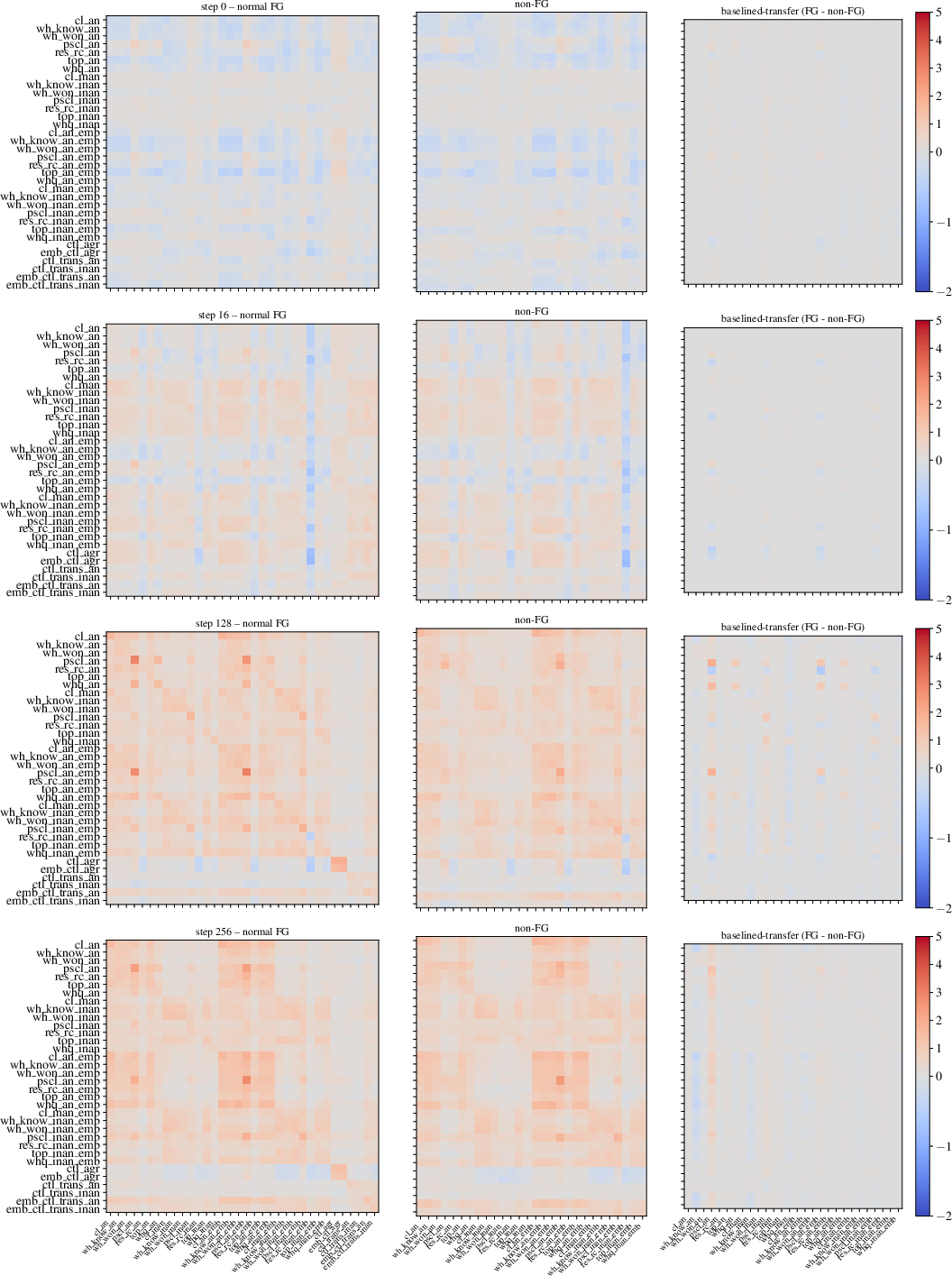
Figure 3: Baselined-transfer matrices across training checkpoints reveal the emergence and stabilization of FG abstraction, with high transfer within FG types post-training.
Regression further demonstrates significant effects along animacy and embeddedness dimensions, showing that syntactic abstraction learning is modulated by these correlates.
Comparative Advantages and Limitations
Perturbation outperforms DAS and probing techniques in several crucial aspects:
- Sensitivity and selectivity: No structure is found in untrained models, avoiding spurious representation inflation; robust clustering of linguistic classes is present only post-training.
- Minimal supervision: Only one unlabeled example is required per intervention, and controls can be tightly designed for conservative tests.
- Computational efficiency: Orders of magnitude faster than DAS (e.g., full FG experiments take 7 hours vs. 262 hours for DAS [related literature]).
- No geometric bias: Capable of discovering both linear and nonlinear representational structure.
Identified limitations include susceptibility to tokenization artifacts, constraints in perturbing bidirectional context for autoregressive models, and reliance on experimental remapping design for interpretability. The method is best suited for detecting shared representations; detailed mechanism extraction remains out of scope.
Practical and Theoretical Implications
Perturbation provides a scalable tracer for linguistic abstraction emergence, supporting usage-based theories of grammar in distributional LMs and providing convergent evidence for acquisition of morphology, lexical sense, and syntactic abstraction from raw experience. It is especially valuable for small, naturalistic datasets, and its unsupervised nature allows for nuanced studies of representation dynamics during training.
Practically, perturbation facilitates fine-grained causal analysis with tight controls, supporting researchers in comparative linguistics and interpretability. In theory, it suggests that LM induction of linguistic abstractions is contingent on statistical properties of experience, not on a priori architectural constraints. Future directions include extending perturbation to nonlinguistic domains and integrating it with downstream mechanism extraction tools.
Conclusion
Perturbation is established as a robust, efficient, and principled method for tracing causal representations in LMs without geometric presuppositions. Across diverse linguistic tasks, it reveals the dynamics and granularity of representation acquisition, overcoming limitations of prevalent supervised interpretability methods and providing empirical validation for bottom-up, experience-driven linguistic structure learning.
Figure 2: Similarity matrices for square (WSD) show the explicit block structure corresponding to distinct senses through perturbation and cosine similarity.
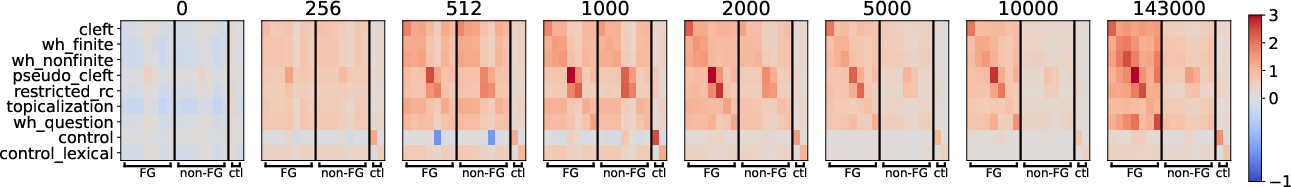
Figure 4: Transfer dynamics from FG and control conditions display the temporal divergence in abstraction acquisition, with transfer to non-FG decreasing only after FG is learned.
Figure 1: Trained and untrained model heatmaps display sharply increased effect size for morphological similarity, with substantial clustering post-training.
Figure 3: Baselined-transfer matrices for the syntactic FG task visualize the development of structured transfer among FG conditions across Pythia-1.4B training.
Short Conclusion
Perturbation offers a rigorously empirical, unsupervised method for causal representation discovery in LLMs, showing strong discriminability across morphological, lexical, and syntactic structures. Its minimal assumptions, efficiency, and selectivity position it as an indispensable tool for LM interpretability and linguistic abstraction research.

