- The paper presents a novel synthetic degradation data pipeline and a dual-phase training strategy to bridge the gap between synthetic and real degradations.
- It leverages an open-source large-scale image editing architecture and a hybrid curriculum to achieve competitive performance against proprietary systems.
- Empirical evaluations using RealIR-Bench and advanced metrics confirm improved restoration quality for nine distinct real-world degradation types.
RealRestorer: Generalizable Real-World Image Restoration with Large-Scale Image Editing Models
Introduction
Real-world image restoration tasks are critical in domains where input data undergoes complex degradations, notably in autonomous driving, remote sensing, and detection. However, existing restoration frameworks, especially those based on deep learning, are challenged by synthetic-to-real domain gap, limited data diversity, and overly simplistic degradation models, resulting in poor generalization. Large-scale image editing models such as Nano Banana Pro and GPT-Image-1.5 have demonstrated strong generalization for restoration, but their performance is not easily replicated due to their closed-source nature and proprietary datasets. The "RealRestorer" model addresses these limitations by leveraging open-source large-scale image editing architectures, a novel synthetic data generation pipeline, and a benchmark built on genuine real-world degradations, narrowing the performance gap with closed-source systems (2603.25502).
Synthetic Degradation Data Pipeline
A central contribution of this work is the design of a synthetic degradation data pipeline that closely approximates real-world degradations. Unlike previous pipelines, the new framework supports nine representative degradation types—blur, compression artifacts, moiré patterns, low-light, noise, flare, reflection, haze, and rain—and incorporates granular noise modeling, segment-aware perturbations, and web-style degradation emulation. This process distinctly narrows the gap between synthetic and real degradation distributions and facilitates the learning of restoration priors by the model.
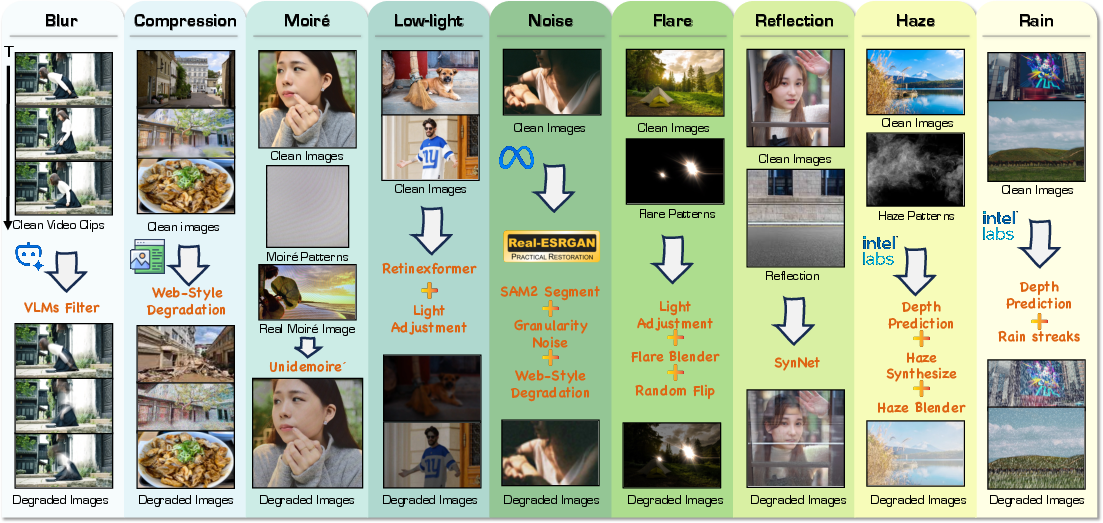
Figure 1: Overview of the large-scale Synthetic Degradation Data pipeline, integrating multiple degradation types with realistic noise and web artifact modeling.
Synthetic data generation exploits state-of-the-art open-source VLM and quality assessment models for filtering, structure and depth aware methods (e.g., SAM-2, MiDaS) for controlling the degradation process, and detailed strategies unique to each degradation (e.g., fusion of real and synthetic rain, physical perturbations, mixture of real scene reflections).

Figure 2: Example pairs from the training dataset, showcasing diversity across both synthetic (top) and real-world (bottom) degradation types.
Real-World Degradation Pairing and Data Curation
While synthetic data enables scale, robust generalization necessitates real degraded-clean pairs. RealRestorer harvests web-sourced real degraded examples and obtains clean references using advanced restoration models. A multilayered selection pipeline leveraging CLIP, Qwen3-VL, watermark filtering, and manual curation ensures high-fidelity correspondence and diversity in degradation severity and type.
RealRestorer Model Architecture and Training
The core model fine-tuned in RealRestorer is Step1X-Edit, which is underpinned by a DiT backbone, equipped with QwenVL for semantic encoding and a reference-image-centric dual-stream diffusion network. The training paradigm features:
- Transfer Training: Initial stage leveraging 1 million+ synthetic pairs to perform cross-domain transfer and broad capability acquisition at high resolution (1024×1024), balancing all nine degradation tasks.
- Supervised Fine-Tuning: Further stage utilizing real-world pairs (with a progressively mixed-in synthetic component), designed for task-specific adaptation and generalization. Cosine annealing is adopted for the learning rate to encourage robust convergence and avoid overfitting.
- Hybrid Curriculum: The two-stage progressive mixing strategy is critical in mediating underfitting of synthetic-only training and the overfitting/tailoring observed with real-only training, as empirically validated.
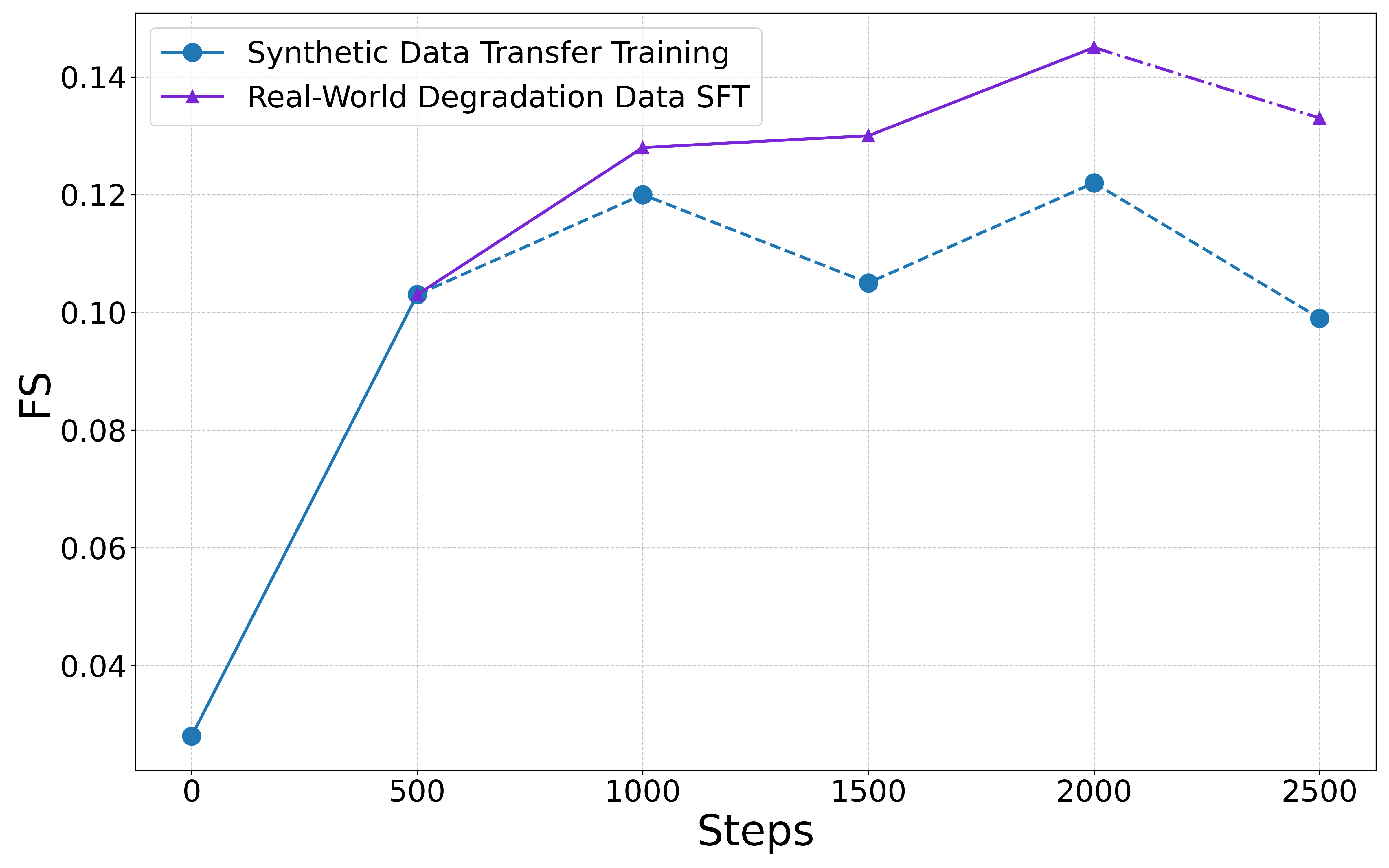
Figure 3: Model performance across training stages on RealIR-Bench, demonstrating the improvements and limitations of synthetic, real, and mixed-data training protocols.
Ablation demonstrates that solely synthetic or real data undermines either generalization or content consistency in output, whereas the two-phased strategy yields the best trade-off.

Figure 4: Qualitative training strategy comparison. Synthetic-only models lack robustness; real-only models overfit. The two-stage protocol of RealRestorer balances the two.
Benchmarking—RealIR-Bench and Evaluation Protocol
Existing restoration benchmarks are inadequate for real-world evaluation due to bias toward synthetic, reference-based, or narrowly focused single artifacts. RealRestorer introduces RealIR-Bench, a set of 464 genuinely degraded, web-curated test images covering the nine major degradations, each linked to a fixed natural-language prompt for open instruction evaluation.
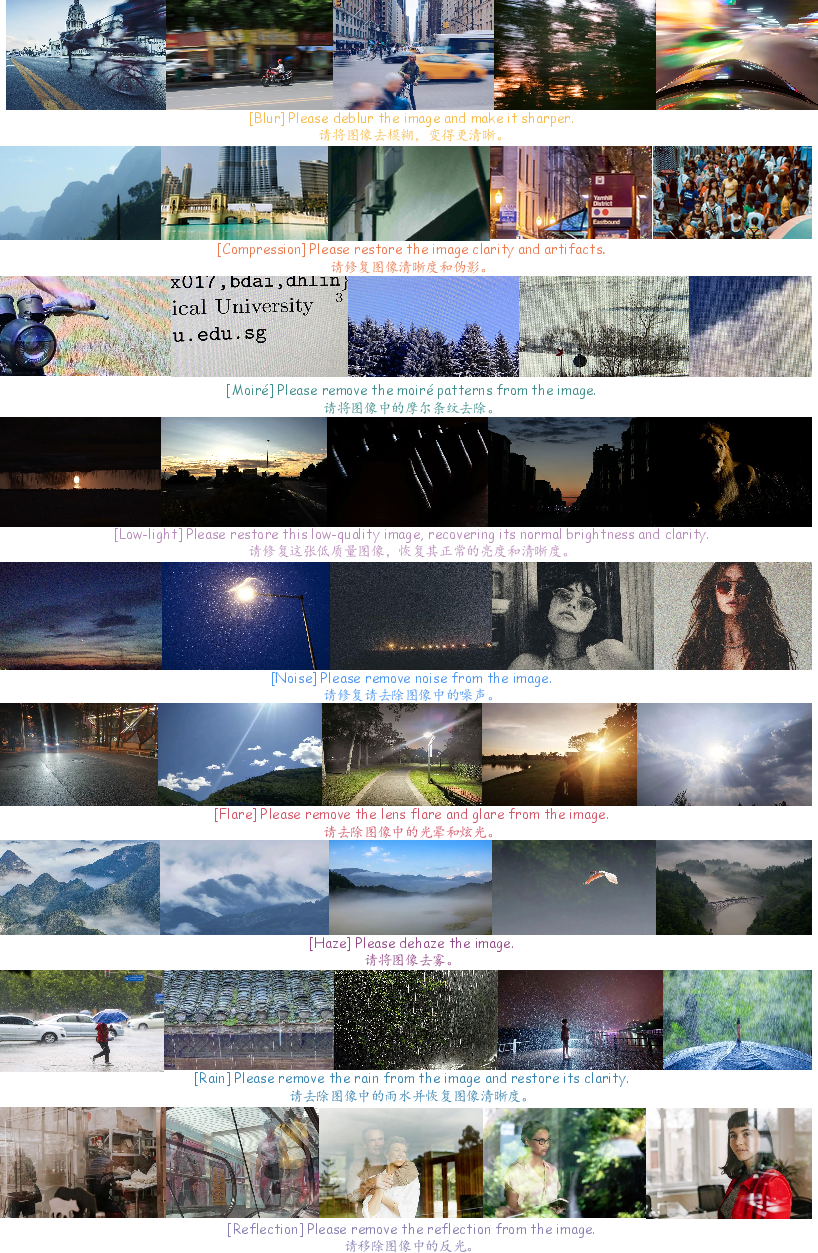
Figure 5: Example cases from RealIR-Bench, encompassing the full spectrum of real-world degradations.
The evaluation protocol is reference-free, employing a VLM-driven Restoration Score (RS) quantifying removal efficacy and LPIPS-based measures for content consistency/fidelity. The overall metric, Final Score (FS), integrates both facets.
Experimental Results
Quantitative and qualitative comparisons demonstrate that RealRestorer achieves state-of-the-art performance among open-source models, outperforming Qwen-Image-Edit-2511, LongCat-Image-Edit, FLUX.1-Kontext, and narrowing the gap to closed-source front-runners such as Nano Banana Pro to less than 0.01 FS points. RealRestorer ranks first or second on the majority of the nine major tasks, especially excelling in deblurring, low-light, and moiré pattern inputs.

Figure 6: Qualitative comparison with state-of-the-art image editing models on real-world degradation cases.
Further, when tested on the FoundIR reference-based benchmark (using PSNR/SSIM), RealRestorer exhibits the best performance on five of seven single degradations, confirming high data and methodology transferability.
(Figures 9–12)
Figures 9–12: Additional qualitative comparisons on diverse cases in RealIR-Bench, reinforcing visual consistency and restoration quality.
User studies using a controlled interface align with metric-based ranking (Kendall’s τb, SRCC, PLCC), validating the non-reference evaluation regime, with RealRestorer consistently rated just below closed-source systems but superior among open models.

Figure 7: User study protocol interface for human assessment of restoration quality.
Limitations
Despite substantial advances, RealRestorer inherits the high computational cost from large diffusion-based architectures. It struggles with highly ambiguous or extreme-edge degradations lacking sufficient pixel evidence and may hallucinate structures under physical ambiguity (e.g., complex reflections). Closed-source models can occasionally surpass its fidelity in highly entangled multi-degradation scenarios.
Theoretical and Practical Implications
Integrating a sophisticated synthetic degradation pipeline and hybrid real-world data interface within a large-scale DiT framework, RealRestorer substantiates that open-source models, when leveraged with advanced data synthesis, can match or closely approach the performance envelope of proprietary systems. The non-reference evaluation protocol using VLMs represents a practical alternative to traditional full-reference scores in real-world scenarios. In terms of zero-shot generalization, the model demonstrates strong transfer to unseen restoration domains (e.g., snow/old image recovery) by virtue of its learned restoration prior.
Practically, the methods and resources (model, data generation tools, benchmarks) open new research directions regarding scalable training for robust, general-purpose image restoration under unconstrained degradation. Further work on efficiency (denoising steps), extended degradation classes, and unsupervised real-pair curation is warranted as the community seeks universal, deployable restoration solutions.
Conclusion
RealRestorer presents a significant step toward open-source, generalizable real-world image restoration via large-scale image editing models and realistic, diverse degradation pipelines. The dual-phase training, novel evaluation metrics, and competitive results across open and closed benchmarks establish a new baseline for future restoration efforts. The public release of the model, dataset, and benchmark is set to provide an enduring resource for both applied and theoretical advancement in real-world image restoration (2603.25502).

