- The paper introduces WriteBack-RAG, a novel method that trains the knowledge base through evidence distillation and write-back enrichment, yielding consistent performance gains.
- It employs a two-phase process using gating and LLM-based distillation to compress and reorganize fragmented evidence into compact, retrieval-friendly units.
- The approach demonstrates cross-pipeline robustness and zero-cost inference enhancements, significantly improving accuracy across multiple QA benchmarks.
WriteBack-RAG: Optimizing the Retrieval Corpus via Evidence Distillation and Write-Back Enrichment
Motivation: Addressing Corpus Fragmentation in RAG Systems
Retrieval-Augmented Generation (RAG) pipelines traditionally treat the knowledge base as a fixed, immutable corpus. This paradigm neglects the reality that retrieval often returns fragmented, noisy, and only partly relevant document segments, diminishing the effectiveness of both retrieval and downstream generation.
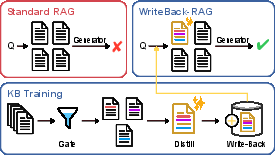
Figure 1: Standard RAG retrieves fragmented evidence from raw documents. WriteBack-RAG distills useful evidence into compact write-back documents that improve future retrieval and generation.
The paper "Training the Knowledge Base through Evidence Distillation and Write-Back Enrichment" (2603.25737) introduces a corpus-level optimization layer that systematically reorganizes knowledge within the RAG corpus itself. The WriteBack-RAG methodology implements a pipeline that detects retrieval bottlenecks, performs evidence fusion and filtering, and writes distilled, compact knowledge units back into the index. This approach explicitly positions the knowledge base as a trainable component, orthogonal to improvements in retriever and generator modules.
Architecture: Gating, Distillation, and Index Augmentation
The WriteBack-RAG pipeline operates in two distinct phases: offline corpus distillation and online retrieval over the jointly indexed knowledge base.
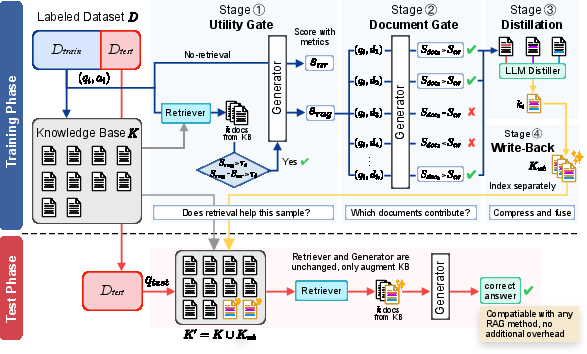
Figure 2: The WriteBack-RAG pipeline—gating identifies where retrieval is beneficial, distillation fuses evidence, and testing uses the enhanced knowledge base with the standard retriever/generator.
Training Phase: Gating and Distillation
- Utility Gating: For each labeled (q,a) sample, WriteBack-RAG computes baseline (no-retrieval) and RAG-augmented generation performance, selecting only those where retrieval yields a significant performance gain and absolute generation is satisfactory.
- Document Gating: Within positive samples, retrieved documents are subjected to a further filter that quantifies their independent contribution to answer reconstruction, thus isolating the most relevant evidence.
- Distillation: The selected minimal evidence set is provided to an LLM-based distillation module. The distiller fuses and compresses the evidence, synthesizing a compact document written in an encyclopedic, retrieval-friendly style. The distiller leverages only surface information (no answer leakage), ensuring the resulting snippet is likely to generalize across queries.
Write-Back Indexing
Distilled units are indexed alongside the original corpus in a parallel FAISS structure. At inference, retrieval proceeds over the merged space with no changes to the retriever or generator. The architecture ensures modularity: the retriever consumes the enhanced corpus seamlessly and no alterations are necessary to any RAG backbone.
Empirical Effects: Consistency Across Tasks, Models, and Pipelines
Comprehensive experiments span six benchmarks (NQ, BoolQ, FEVER, zsRE, HotpotQA, SQuAD), four retrieval/generation backbones (Naive RAG, RePlug, Self-RAG, FLARE), and two LLM scales (Llama-3.1-8B, Gemma-3-12B). WriteBack-RAG exhibits uniform improvement in all 48 settings, with an average absolute gain of +2.14%, and peaks of +5.81% (F1, SQuAD) depending on setup.
Notably:
- Gains are most pronounced in tasks characterized by evidence fragmentation (NQ, FEVER).
- The write-back corpus benefits all RAG variants, including highly adaptive retrieval schemes like FLARE and Self-RAG, indicating that corpus organization is a limiting factor even for sophisticated retrieval-control pipelines.
- Improvements are realized at zero inference-time cost, affecting only offline preprocessing.
Corpus Analysis: Compression, Evidence Selection, and Retrieval Dynamics
WriteBack-RAG is highly selective—less than half of training points yield a distilled document, except in dense multi-hop tasks. The average distilled document compresses evidence by factors ranging from 2.2× to 6.8×, reducing index bloat while amplifying retrieval relevance.
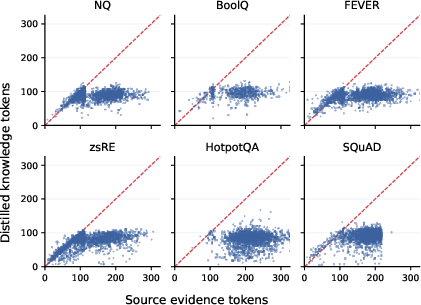
Figure 3: Source evidence length versus distilled write-back knowledge length; distilled knowledge is consistently more compact than the sum of selected evidence.
Analysis of evidence selection reveals task-adaptive behavior. In extractive QA (SQuAD), almost all distilled documents arise from top-1 and top-2 retrieved results, reflecting the fallback mechanism under sparse evidence. Multi-hop and open-domain tasks (HotpotQA, NQ) demonstrate more even rank utilization.
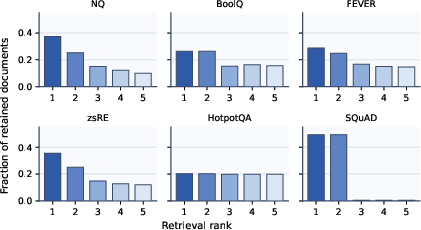
Figure 4: Retrieval-rank distribution of retained documents: top-ranked evidence is favored except in tasks with inherently distributed knowledge.
Robustness and Generalization: Cross-Pipeline Transferability
A critical finding is that write-back corpora produced under one RAG pipeline (e.g., Naive RAG) transfer seamlessly to another (e.g., RePlug) with negligible (<0.5%) or even superior increments in accuracy.
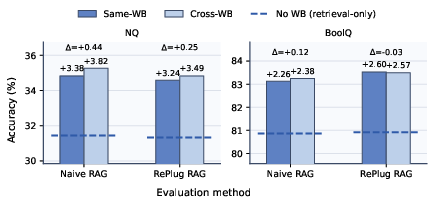
Figure 5: Same-WB (pipeline-matched) and Cross-WB (cross-pipeline) write-back corpora yield virtually identical downstream performance gains.
This transferability demonstrates that WriteBack-RAG does not overfit to any idiosyncrasies of retriever/generator interaction, but instead encodes corpus-level improvements accessible to any RAG method.
Theoretical and Practical Implications
The research formalizes knowledge base training as an evidence-driven, task-informed corpus distillation process. This reframes the approach to RAG optimization by promoting the external corpus to a first-class learnable component—distinct from, and complementary to, parametric editing techniques such as ROME or MEMIT.
Practically, the approach is implementation-agnostic: WriteBack-RAG may be bolted onto any RAG system, improving knowledge organization without retriever/generator retraining or parameter modification. The index modularity (keeping distilled units separate) enables incremental updates and rollback, facilitating safe deployment in continuously evolving or dynamic data settings.
The main limitations pertain to label dependency (write-back is supervised, though LLM-based judging is feasible), LLM distillation quality (possible hallucination propagation), and lack of corpus pruning mechanisms (additive-only enrichment). Future directions include unsupervised or self-supervised KB training, integration with corpus deduplication/contradiction detection, and extension to multilingual or cross-domain retrieval.
Conclusion
WriteBack-RAG (2603.25737) demonstrates that corpus-level evidence distillation and write-back enrichment provide systematic, robust, and transferable knowledge base improvement for retrieval-augmented generation. The method establishes the corpus as a trainable intermediate in the RAG stack, orthogonal to retriever and generator advances, enabling persistent performance gains with minimal architectural or computational burden at inference. These findings concretely motivate further exploration of corpus-centric adaptation, including dynamic corpus management and integration with non-parametric/model editing strategies within LLM-based knowledge-centric AI.