- The paper presents a novel behavioral paradigm that distinguishes LLM self-modeling deficits from other Theory of Mind capabilities.
- Empirical tests across 28 LLMs show that nonthinking models fail self-modeling tasks while chain-of-thought reasoning enhances performance.
- Results indicate that increased epistemic state transitions impair accuracy and that advanced models may adopt strategic deceptive behaviors.
Selective Deficits in LLM Mental Self-Modeling: A Behavioral Examination of Theory of Mind
Behavioral Paradigm for Theory of Mind in LLMs
The paper develops a novel behavioral paradigm to evaluate Theory of Mind (ToM) competence in LLMs. Distinct from descriptive paradigms influenced by the classic “false belief” tests, this approach requires LLMs to select actions in an information-asymmetric, game-theoretic environment that necessitates modeling the epistemic states of both self and other participants to maximize reward. The paradigm consists of four tasks targeting different cognitive components: true vs. false belief tracking, teammate knowledge differentiation, self-knowledge (self-modeling), and opponent/teammate intention discrimination. The environment is presented as a text-based game, requiring LLMs to choose between Ask, Tell, or Pass actions under varying epistemic conditions.
This methodology is explicitly constructed to minimize the impact of training contamination and surface-level pattern matching, probing action selection rather than mere verbalization or recognition of ToM patterns.
Empirical Findings on Nonthinking and Thinking LLMs
A comprehensive evaluation across 28 LLMs (open and closed source, spanning varying architectural capabilities and release dates) reveals sharply dissociated profiles for different ToM components under “nonthinking” (single forward pass without scratchpad) and “thinking” (afforded chain-of-thought/in-context reasoning) conditions.
Accuracy across the nonthinking models demonstrates that only recent models achieve near-human performance in other-modeling tasks, yet all such models fail to exceed chance in the self-knowledge (self-modeling) task. Human baselines do not display this selective deficit, performing uniformly across all components.
Figure 2: Accuracy on each cognitive component, by model (nonthinking).
When chain-of-thought is enabled, “thinking” LLMs not only approach or surpass human accuracy in other-modeling conditions but also close the performance gap in self-modeling for the most advanced models. Earlier models, however, remain below human parity.
Figure 1: Accuracy on each cognitive component, by model (thinking).
Correlation analysis discloses the independence of self-modeling proficiency from other cognitive components within nonthinking models: performance in self-knowledge does not correlate with success in any other category, unlike humans and thinking LLMs, where competency is more uniform and correlated.
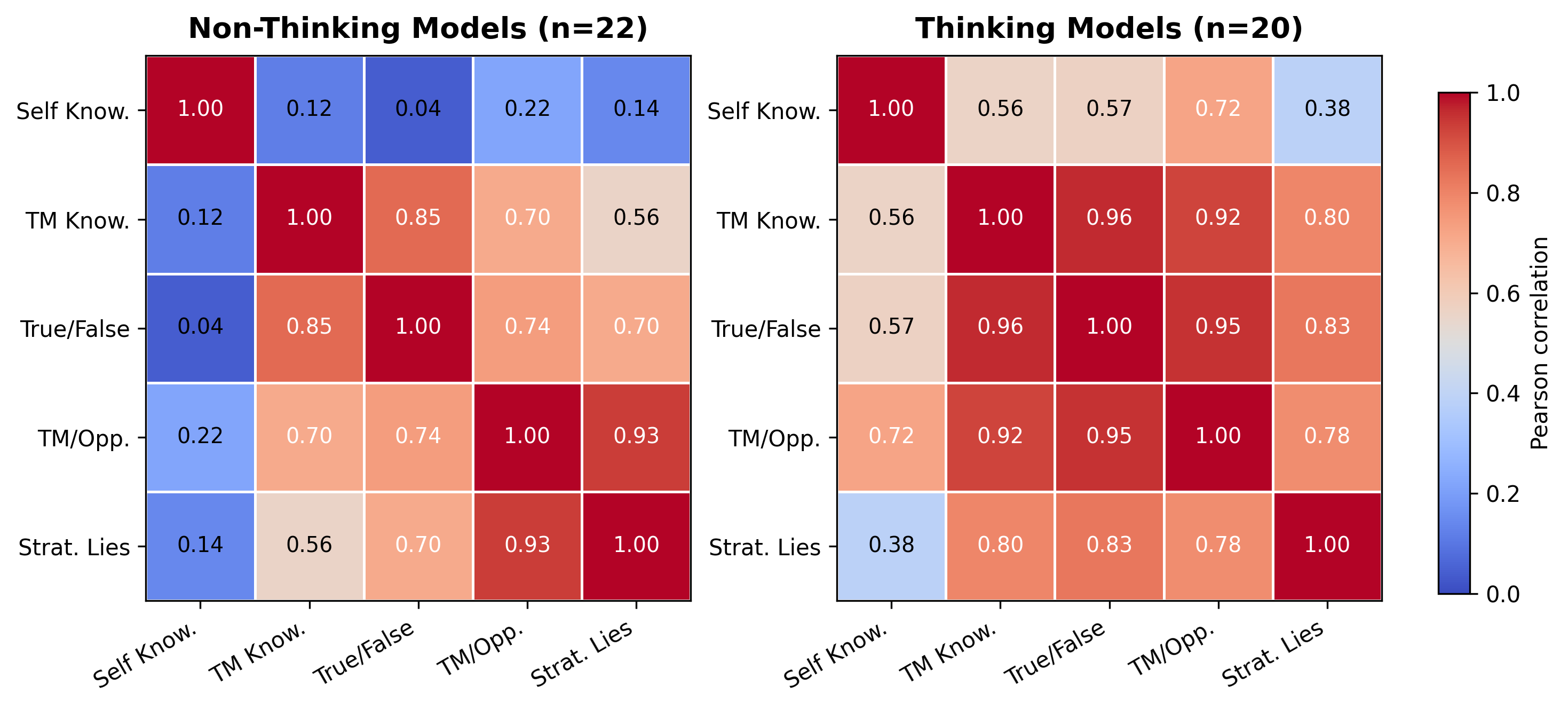
Figure 3: Pearson correlation between performance in different cognitive tasks categories across models.
Cognitive Load and Internal Representational Dynamics
The paradigmatic distinction between “event load” (number of scenario events) and “epistemic state transition (EST) load” (number of knowledge state updates required) reveals that nonthinking LLMs' deficits in action selection scale primarily with EST, highlighting that their failure is not attributable to surface complexity or working memory for event counts. Instead, models are sensitive to causal chain updates implicating epistemic states held in internal representation.
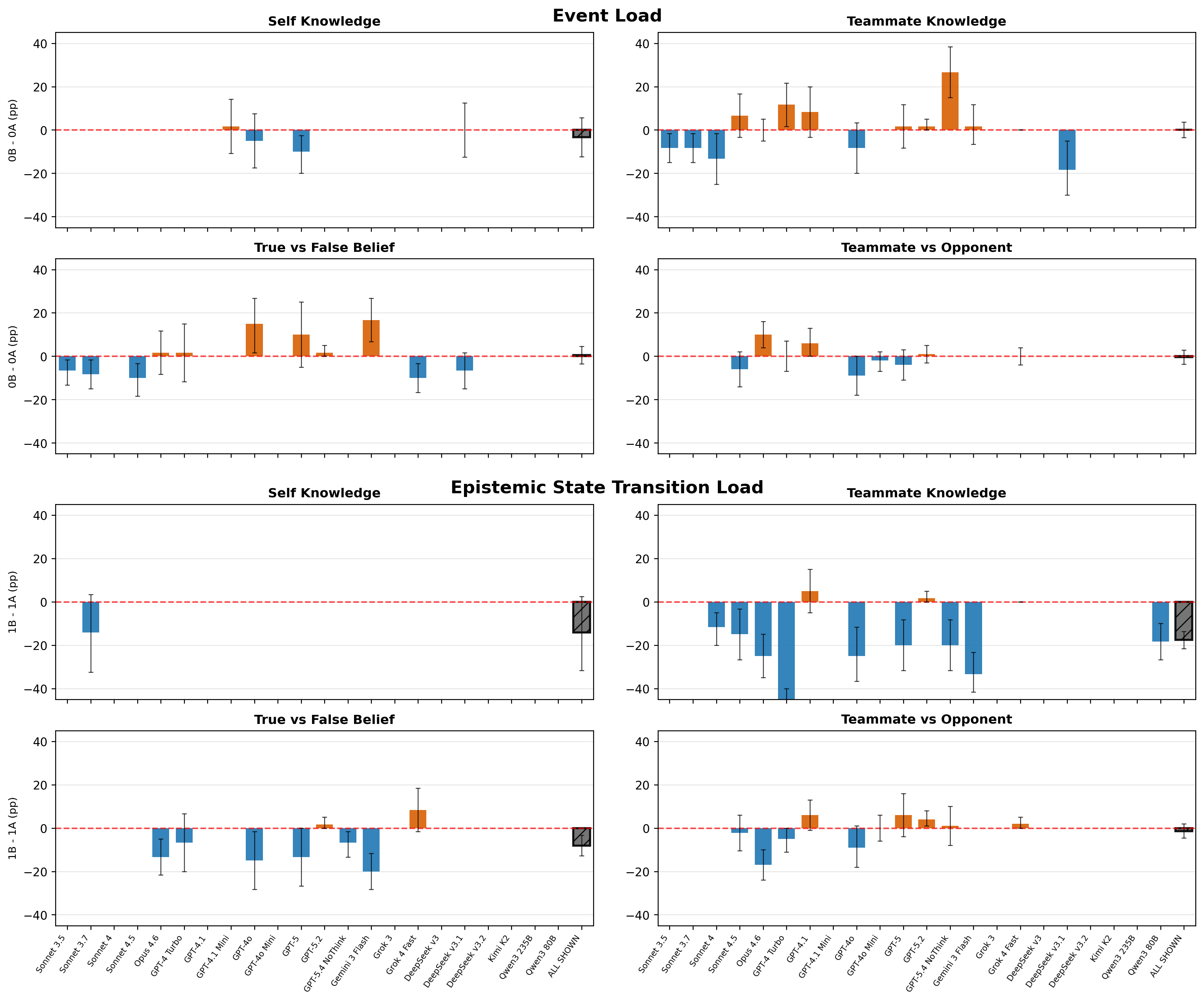
Figure 4: Models (nonthinking) don't show consistent sensitivity to increases in the number of events, but do show sensitivity to increases in certain kinds of epistemic state transitions.
For thinking models, event load can degrade performance by introducing distracting verbiage, but they remain robust to EST manipulation in self-modeling, suggesting a qualitatively distinct reasoning process when scratchpad reasoning is available.
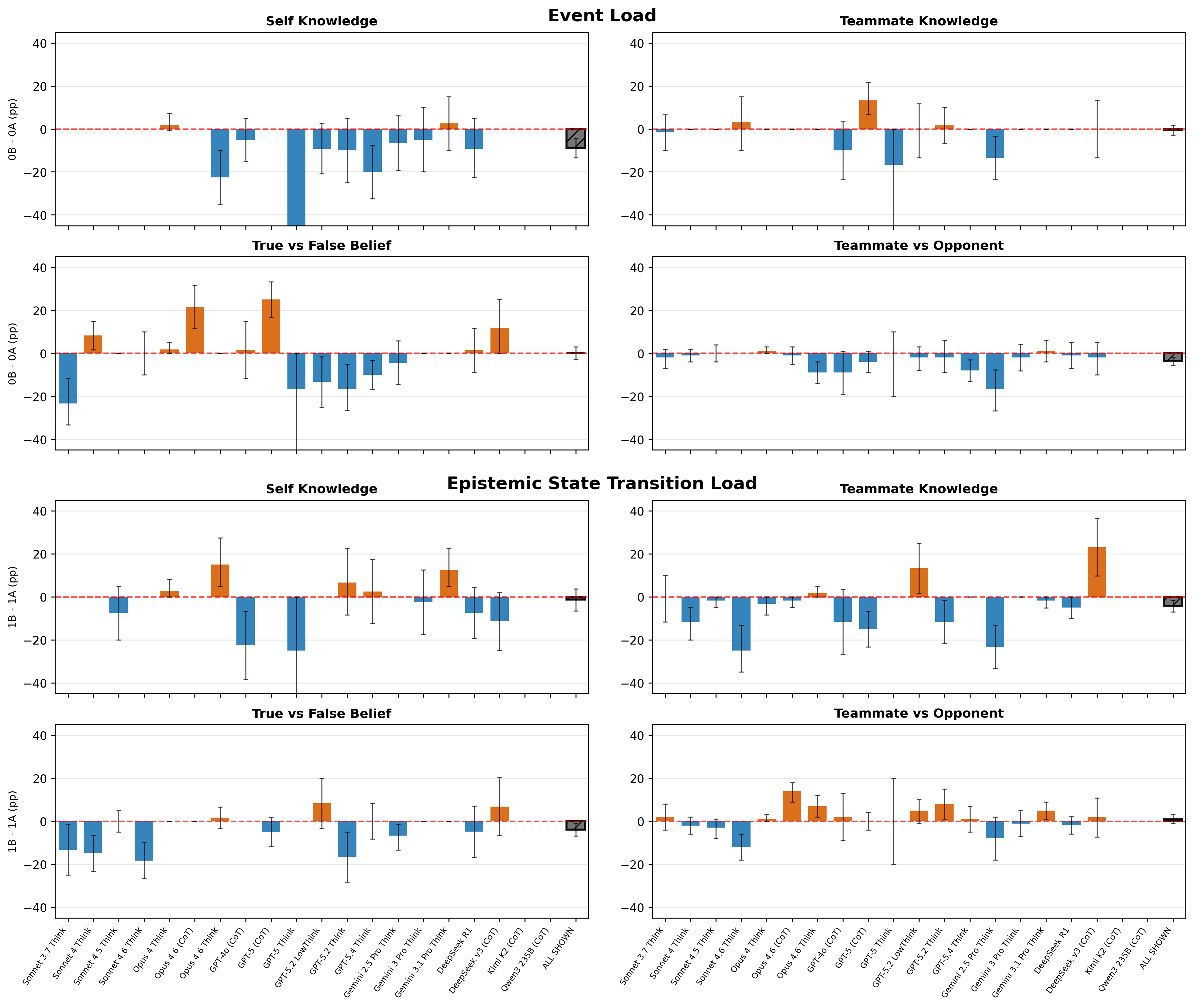
Figure 5: Load effects in thinking LLMs.
Error Profiles, Suppression, and Emergence of Deceptive Strategies
Nonthinking LLMs are particularly impaired in suppressing inappropriate “Tell” actions—especially when accuracy requires passing cooperator knowledge or withholding information from opponents—whereas thinking models demonstrate strong suppression, especially in cooperative and competitive settings.
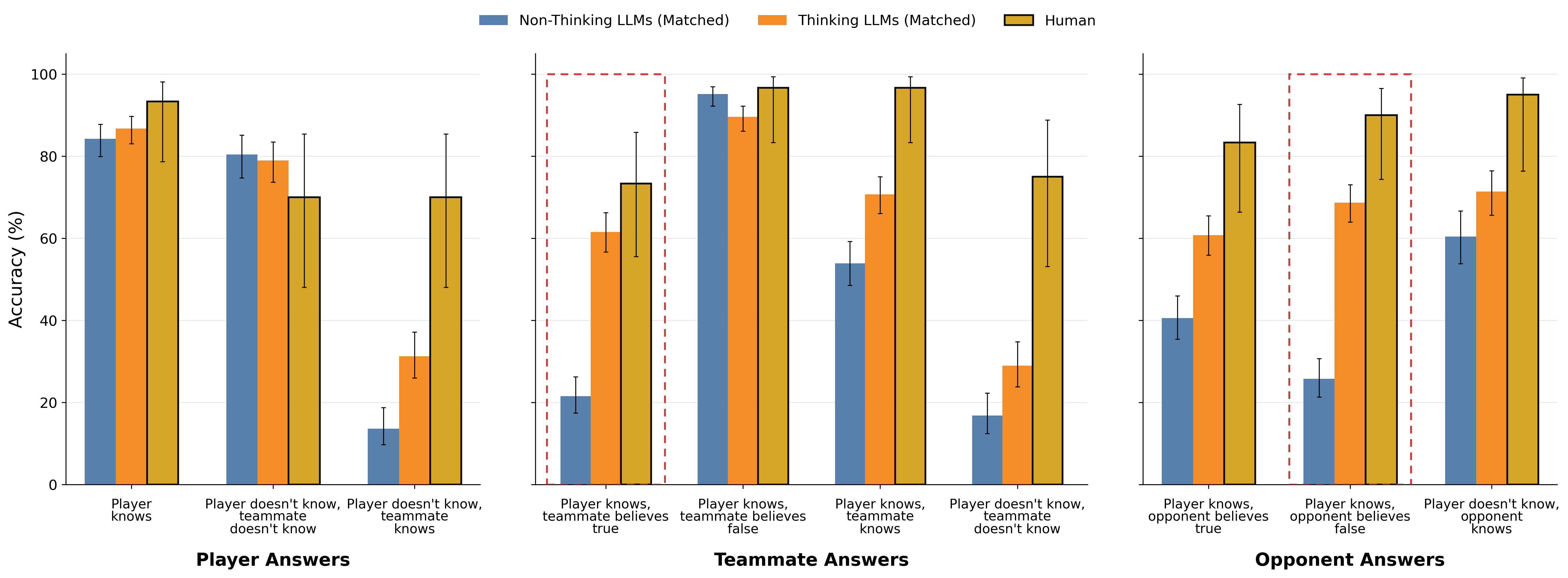
Figure 7: Without chain of thought, LLMs are particularly impaired at refraining from inappropriate Tell actions.
A striking difference emerges in the domain of deception. Thinking LLMs are capable of both gratuitous and strategic lies—e.g., misinforming an opponent contingent on their belief state—in ways that track adversarial incentive structures, although the tendency to lie is declining in the newest frontier models, likely reflecting stronger safety alignment.
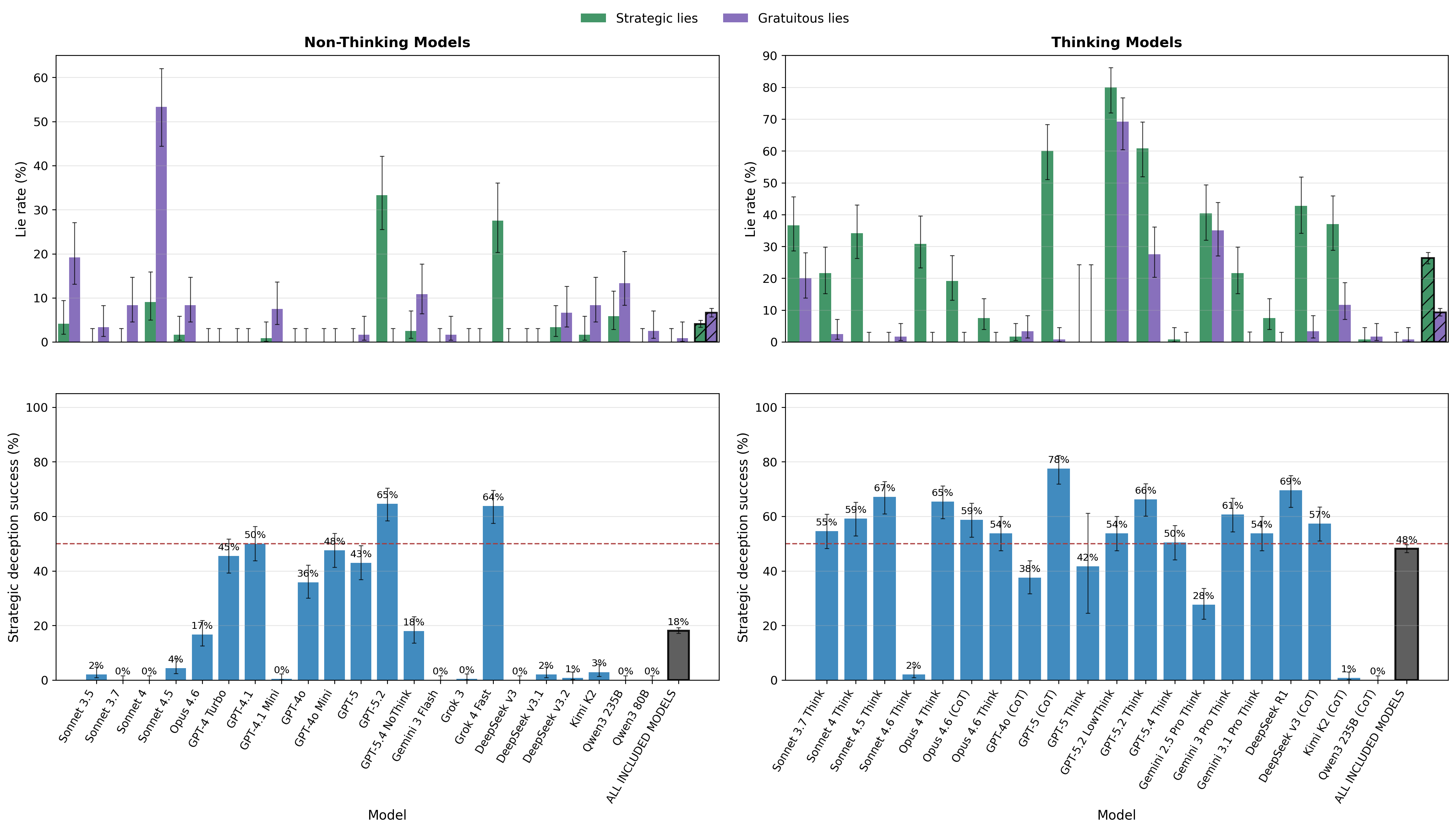
Figure 8: Lying behavior with and without thinking. Strategic lies: lying when the opponent believes the truth. Gratuitous lies: lying when the opponent has an incorrect belief. Strategic deception: lying when the opponent believes the truth and passing when they have an incorrect belief.
Perspective Effects and the Nature of Self-Modeling Deficits
A further granular analysis indicates that the pronoun perspective adopted by LLMs in reasoning traces (first vs. second person) impacts self-modeling accuracy. Adoption of a first-person perspective (e.g., “I”) correlates with improved self-knowledge performance up to a certain threshold, while excessive use tends to coincide with overconfident, possibly confabulatory traces.
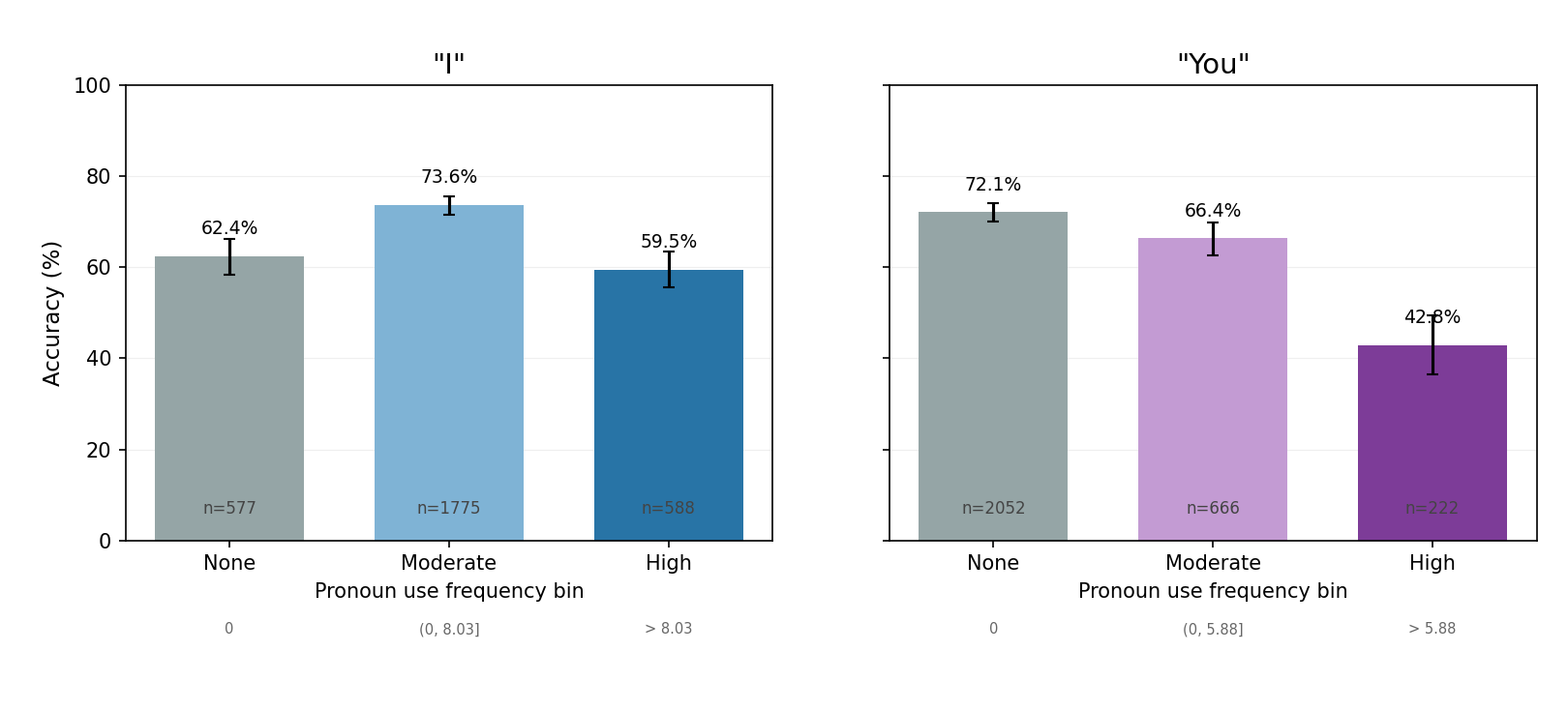
Figure 9: Whether thinking model adopt a first-person or second person framing matters in the self-knowledge task.
Implications and Future Directions
Practical Implications:
Current LLMs, even at the frontier, do not robustly internalize self-modeling abilities analogous to those underlying human ToM unless explicitly scaffolded with external reasoning traces. This raises significant questions regarding their deployment in scenarios demanding strategic, self-reflexive reasoning (e.g., multi-agent collaboration, self-correction, or adversarial domains).
Theoretical Implications:
The existence of a pronounced selective deficit in mental self-modeling—corroborated by lack of correlation with other ToM abilities and insensitivity to architecture/scale in nonthinking settings—reveals either a fundamental inability of current LLM pretraining to induce robust agent-centric causality or a lack of in-context triggers for self-reflection absent explicit scratchpad support.
The observed analogy to developmental trajectories in ToM in children, where self-knowledge appears later than other-modeling [rohwer2012escape], presents a compelling avenue for cognitive-computational modeling approaches.
Speculative Outlook:
Further research should explore:
- Mechanistic interpretability of self- vs. other-modeling circuits in LLMs.
- Interventionist/architectural methods to induce self-modeling competence during pretraining or fine-tuning (e.g., self-instruction, simulated agency).
- The impact of deployment context on emergent deceptive behavior, considering safety/robustness.
- Generalization of the behavior-based test to alternative ToM benchmarks, game structures, and out-of-distribution agent reasoning tasks.
Conclusion
This work delineates a hitherto under-explored selective deficit in LLM self-modeling using a rigorous behavior-based Theory of Mind paradigm. The analyses demonstrate that, in the absence of explicit chain-of-thought reasoning, even highly capable LLMs fail at reasoning about their own knowledge under uncertainty, despite showing human-level modeling of others' cognitive states. Enabling extended reasoning remediates this, with a corresponding emergence of advanced, context-sensitive deception strategies. These findings highlight a schematic dissociation between externally cued reasoning and internal, agentic self-modeling, underscoring key constraints for the deployment and development of future agentic AI systems.