- The paper identifies divergent thinking as the main driver of hallucinations in MCoT models, quantifying its impact using a novel visual entropy metric.
- It introduces a lightweight, training-free entropy-guided decoding intervention that selectively penalizes high-entropy steps to curb ungrounded reasoning.
- Experimental results on benchmarks like PixelReasoner-7B demonstrate significant improvements in both hallucination suppression and reasoning fidelity.
Understanding and Mitigating Hallucinations in Multimodal Chain-of-Thought Models
Introduction
The paper "Understanding and Mitigating Hallucinations in Multimodal Chain-of-Thought Models" (2603.27201) addresses the phenomenon of hallucinations in Multimodal Chain-of-Thought (MCoT) models—architectures unifying explicit step-wise reasoning over visual and textual modalities. While MCoT frameworks have demonstrated advanced capabilities in complex visual reasoning tasks, they remain susceptible to hallucinated outputs: fabricated textual content inconsistent with underlying visual evidence. This study systematically dissects the unique causes of hallucinations in MCoT models, introduces a principled entropy-based diagnostic, and proposes a lightweight mitigation strategy that dynamically intervenes in the decoding process to improve model faithfulness while preserving reasoning strength.
Analysis of Hallucination Mechanisms in MCoT Models
The investigation departs from classical attributions of hallucinations in LVLMs, which primarily focus on visual attention decay and language priors. MCoT models, by virtue of their explicit, multi-hop reasoning processes, introduce new factors. Experimental results on benchmarks such as Object HalBench and POPE reveal a strong positive correlation (ρ>0.96) between hallucinations occurring during the thinking (reasoning chain) and answering stages, implicating the self-attention mechanism as a conduit for propagating unfaithful information.
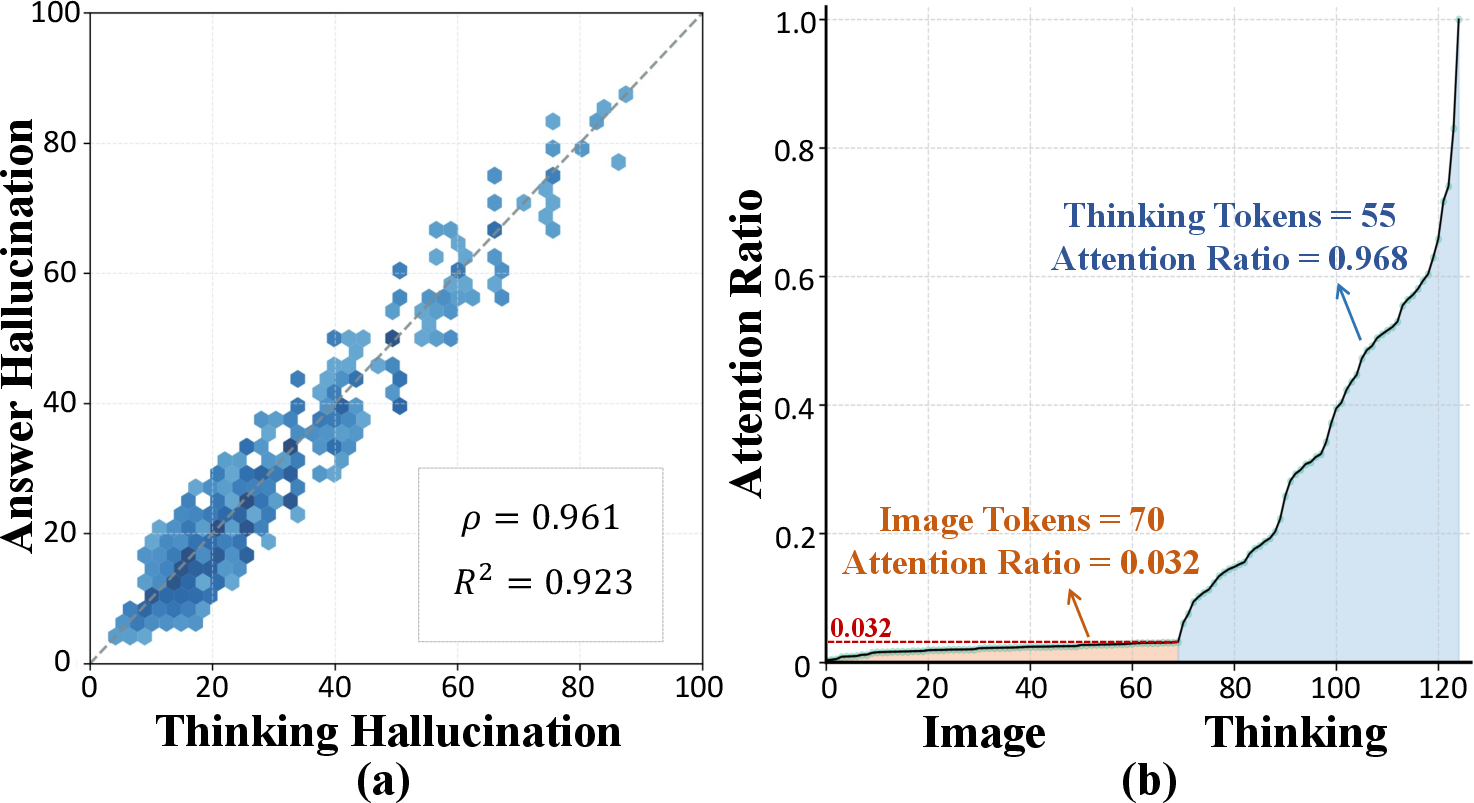
Figure 1: Hallucinations in the thinking process are positively correlated with those in answers, and biased attention toward the thinking chain further propagates erroneous content.
A key discovery is that hallucinations concentrate in specific steps—namely, during associative, non-grounded reasoning termed "divergent thinking." Contrasted with "normal" thinking, these divergent steps, where the model relies more on internal chains of associations than perceptual input, are approximately five times more likely to produce hallucinations.
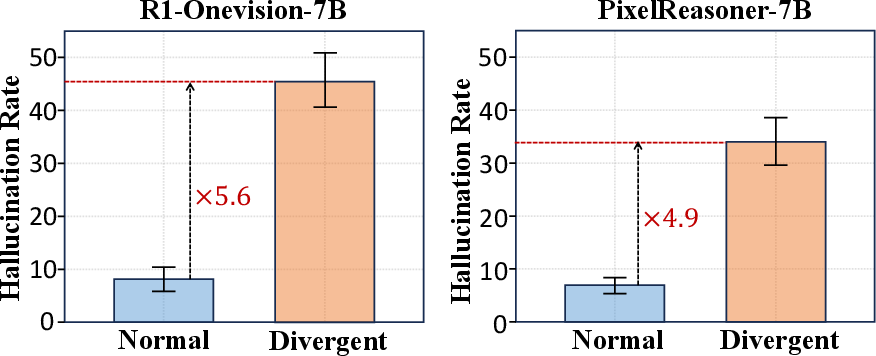
Figure 2: Divergent thinking steps yield significantly higher hallucination rates, indicating the non-uniform distribution of errors across reasoning chains.
This cognitive-parallel analysis is substantiated by visualizing attention distributions, which confirm a pronounced shift of focus from image to internal reasoning during divergent steps.
Entropy-Based Detection and Localization of Hallucinations
To operationalize the identification of divergent thinking, the authors propose a novel metric: visual entropy. This normalized entropy, computed over the probability distribution of generating the next token from each visual input token, quantifies model uncertainty regarding visual content at each reasoning step. Empirical analysis demonstrates that visual entropy reliably discriminates divergent from normal thinking steps; a simple logistic regression on entropy achieves pseudo-R2 exceeding 0.9 in detecting divergent reasoning.
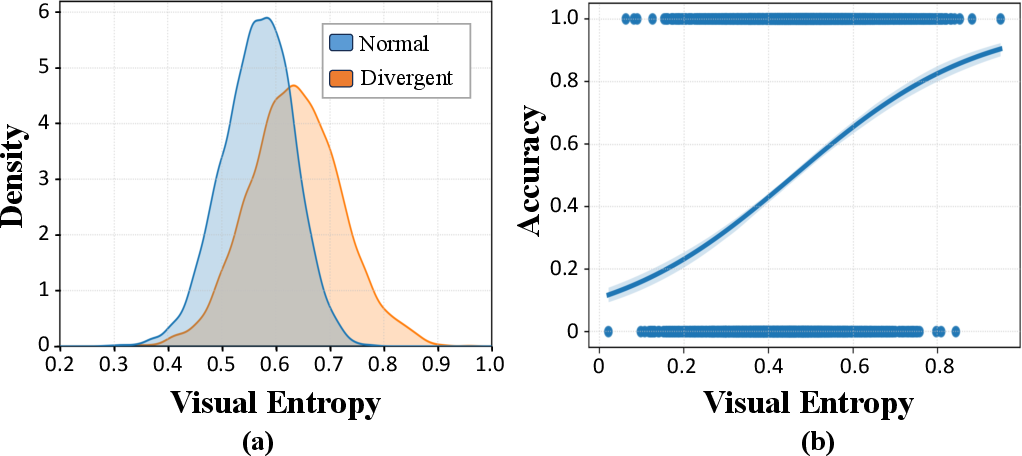
Figure 3: Visual entropy values are distinctly elevated in divergent thinking steps and serve as strong predictors of such steps via logistic modeling.
Qualitative visualization further confirms that divergent steps are characterized by dispersed, high entropy activations, which decrease upon intervention.

Figure 4: Visual entropy is visibly higher during divergent reasoning (left); after intervention, entropy is sharply reduced (right), reflecting less uncertainty and increased perceptual grounding.
Entropy-Guided Decoding Intervention
The mitigation strategy leverages visual entropy in a training-free, adaptive decoding scheme. For each decoding step, if visual entropy exceeds a model-agnostic threshold, the decoding distribution is reweighted to penalize token choices with high entropy:
p^t(⋅∣v,q,y<t)=pt(⋅∣v,q,y<t)⋅e−α⋅E(⋅,v)
This selective penalization curbs the generation of ungrounded content during high-risk divergent thinking while maintaining the original reasoning chain elsewhere.
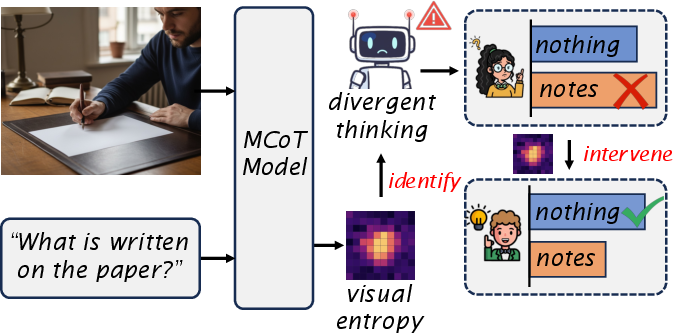
Figure 5: Overview of the proposed method—visual entropy signals guide dynamic intervention only during divergent thinking segments.
The method is lightweight, incurring negligible inference overhead as the required probabilities are precomputed during standard model forward passes.
Experimental Results and Ablations
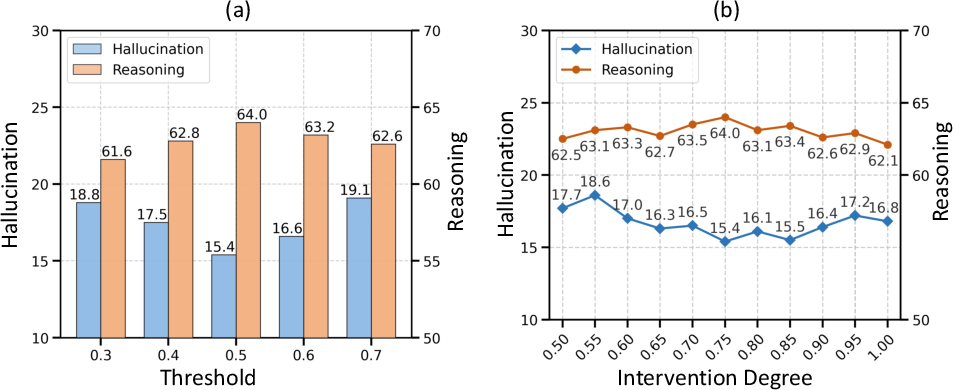
Experiments across three state-of-the-art MCoT backbones (GRIT-3B, PixelReasoner-7B, R1-Onevision-7B) and three hallucination benchmarks show that the entropy-guided intervention substantially outperforms prior mitigation approaches (DoLa, VCD, MemVR, FlexAC) in reducing sentence- and image-level hallucination rates. For instance, on PixelReasoner-7B, the method reduces CHAIRS by 6.6 points and improves MathVista accuracy by 1.4 absolute points over the baseline.
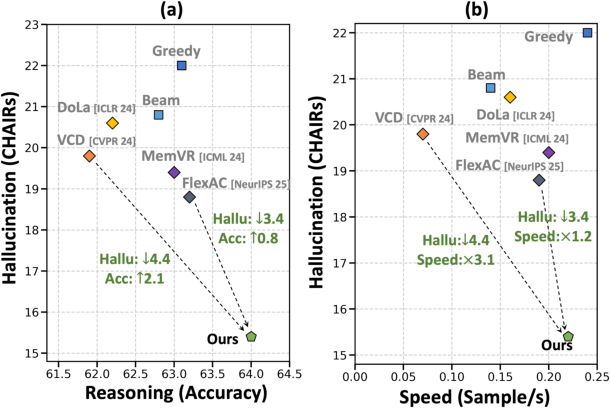
Figure 6: The method achieves a superior balance between hallucination suppression and reasoning accuracy, with improved effectiveness-efficiency tradeoff.
Ablation studies confirm:
Qualitative inspection illustrates that the method eliminates specific hallucinated content, yielding answers that remain more tightly grounded in visual evidence, even during explicit multi-step reasoning chains.
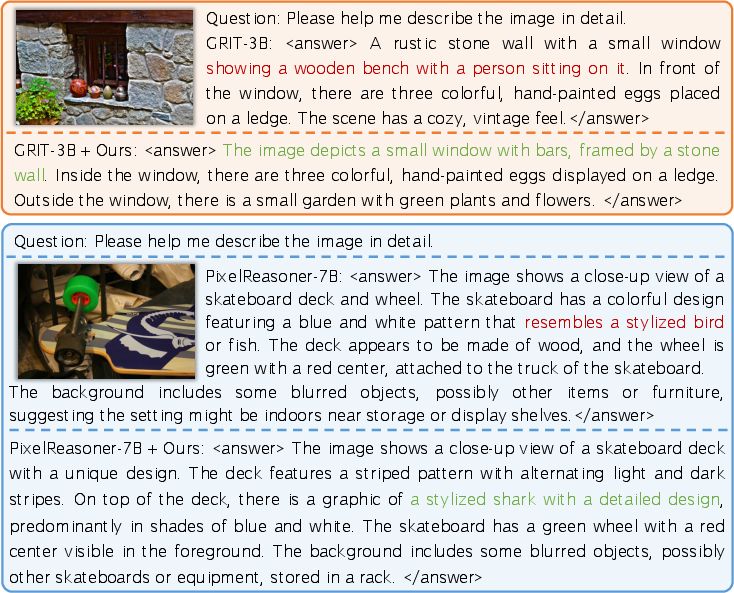
Figure 8: In qualitative cases, the method excises specific hallucinated statements in the MCoT reasoning chain, consistently producing more faithful answers.
Implications and Outlook
The study advances both practical mitigation and mechanistic interpretability for hallucinations in MCoT models. By revealing the centrality of divergent thinking and leveraging visual entropy as both diagnostic and intervention lever, it closes the gap between cognitive-inspired analysis and modern MLLM architectures. The lightweight, training-free nature and broad compatibility of the scheme is significant for scalable deployment and future compositional integrations with other calibration methods.
Theoretically, the work underscores the necessity to analyze intra-chain epistemics—how model uncertainty and inference patterns evolve across reasoning steps—in multimodal settings. This opens further avenues:
- Integration of uncertainty quantification techniques from Bayesian inference or post-hoc calibration with generative decoding.
- Unsupervised structure discovery in reasoning chains for real-time fidelity monitoring.
- Extension of entropy-informed interventions to more open-ended, generative multimodal tasks beyond image grounding.
Conclusion
This paper delivers an incisive analysis of hallucination phenomena in MCoT models, localizing the primary cause to divergent thinking steps and introducing visual entropy as both a fine-grained diagnostic and an actionable mitigation signal. The resulting adaptive decoding method achieves strong performance across perception and reasoning metrics, with minimal computational overhead and high compatibility with existing techniques. These contributions represent a meaningful step toward interpretable and robust multimodal reasoning systems, and lay groundwork for deeper analysis and control of model epistemics in the MCoT paradigm.