Uni-World VLA: Interleaved World Modeling and Planning for Autonomous Driving
Abstract: Autonomous driving requires reasoning about how the environment evolves and planning actions accordingly. Existing world-model-based approaches typically predict future scenes first and plan afterwards, resulting in open-loop imagination that may drift from the actual decision process. In this paper, we present Uni-World VLA, a unified vision-language-action (VLA) model that tightly interleaves future frame prediction and trajectory planning. Instead of generating a full world rollout before planning, our model alternates between predicting future frames and ego actions step by step, allowing planning decisions to be continuously conditioned on the imagined future observations. This interleaved generation forms a closed-loop interaction between world modeling and control, enabling more adaptive decision-making in dynamic traffic scenarios. In addition, we incorporate monocular depth information into frames to provide stronger geometric cues for world modeling, improving long-horizon scene prediction. Experiments on the NAVSIM benchmark show that our approach achieves competitive closed-loop planning performance while producing high-fidelity future frame predictions. These results demonstrate that tightly coupling world prediction and planning is a promising direction for scalable VLA driving systems.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about making self-driving cars think ahead more like people do. Instead of first “imagining” the whole future and then deciding what to do, the authors build a system that imagines a tiny bit of the future and immediately decides the car’s next move—then repeats this see-think-act cycle step by step. They call their model Uni-World VLA because it combines Vision (what the camera sees), Language (a smart AI brain that understands and reasons), and Action (the car’s next moves).
The big questions the researchers asked
- Can a self-driving car do better if it tightly links “imagining the world” and “planning what to do,” updating its plan every step instead of planning after a long, fixed prediction?
- Will adding a sense of depth (how far things are) to the camera images help the car imagine the future more accurately?
- Can this approach work well using just a single front camera, without extra sensors like LiDAR?
How the system works, in everyday terms
Think of playing a racing game:
- Open-loop (old way): Before you move, you try to imagine the next 4 seconds of the race all at once and then pick a plan. If something unexpected happens, your plan can go out of date.
- Closed-loop (this paper’s way): Every half second, you quickly imagine what the track will look like next, make a small steering/braking decision, then imagine again, decide again, and so on.
Here’s what Uni-World VLA does behind the scenes:
- It watches the last couple of seconds of video from a front-facing camera.
- It compresses each frame into “tokens,” which are like compact puzzle pieces or shorthand codes for the picture. This helps the AI handle video efficiently.
- It also estimates a depth map from each image—like a grayscale picture where brighter means closer and darker means farther. Depth gives the car a better sense of 3D space from a single camera.
- The AI then generates the future in tiny steps: it predicts the next short “slice” of what the camera would see and immediately chooses the car’s next waypoint (a little step along the future path). Then it repeats this: predict a bit of the world → choose an action → predict again → act again.
- This back-and-forth “interleaving” keeps planning tightly linked to what the car believes the world will look like, reducing mistakes that pile up when you imagine too far ahead without adjusting.
Some helpful analogies for the technical parts:
- “Tokens”: Like turning a big, detailed picture into a set of small, reusable building blocks so the AI can think faster.
- “Depth fusion”: Mixing a “how-far-away-is-it” map into the image features, so the AI better understands distances and shapes.
- “Autoregressive”: The AI builds the future step by step, each new step using what it already predicted.
What they tested and found
They evaluated their system in a realistic driving simulator called NAVSIM. Two kinds of results matter:
- Driving quality (PDMS score): This combines safety (avoiding crashes), staying on drivable areas, making smooth moves, keeping safe time-to-collision, and making good progress along the route.
- Video prediction quality (FVD score): How realistic the predicted future camera frames look.
Main findings:
- Higher overall driving score: Uni-World VLA reached the best combined driving score (PDMS) among the tested methods, even though it used only a single front camera. It especially improved “ego progress” (how well the car moves forward) and “time-to-collision” (safety margin).
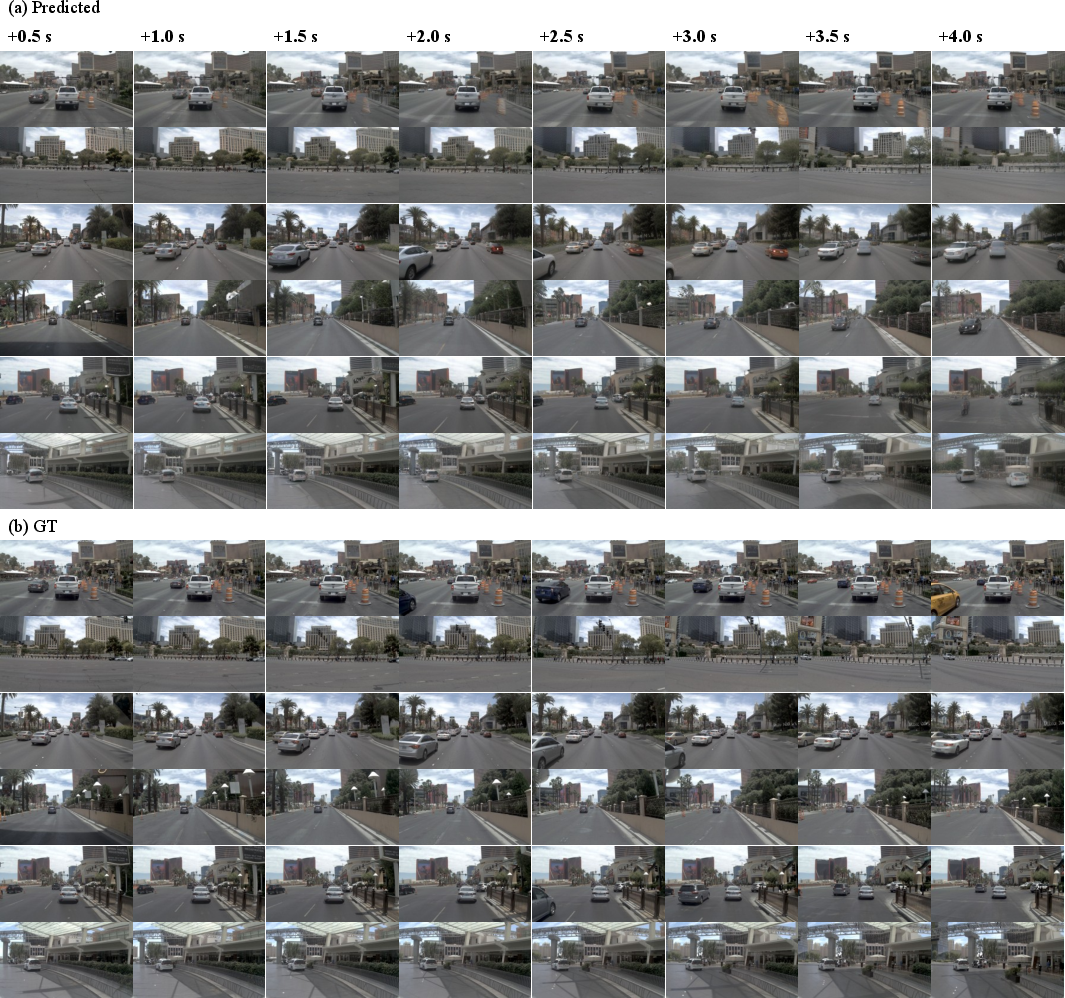
- Realistic future frames: It produced high-quality, believable short-term future videos of what the camera would see next.
- Depth helps: Adding depth information made long-horizon predictions clearer and more stable, especially during turns or at higher speeds.
- Interleaving helps: Alternating between predicting a bit of the future and immediately deciding the next action improved both planning and prediction, compared to methods that predict a long rollout first and only plan afterward.
Why this matters:
- When the world is changing quickly—like cars merging or pedestrians crossing—you don’t want to stick to an old plan based on a stale prediction. Updating your plan every step keeps decisions fresh and safer.
What this means going forward
This research suggests a better way to run self-driving systems:
- Keep the “world imagination” and “action planning” tightly coupled in a continuous loop, rather than separating them.
- Use depth cues from a single camera to improve 3D understanding without extra sensors.
- This can lead to safer, smoother, and more efficient driving decisions and could scale well as cars learn from more data and more varied roads.
In short, Uni-World VLA shows that thinking and acting in small, frequent steps—using both what you see and how far things are—helps a self-driving car adapt quickly and drive more safely in complex, changing traffic.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues that future research could address to strengthen, generalize, and stress-test Uni-World VLA.
- Real-to-sim generalization: results are only reported on NAVSIM; it remains unknown how the interleaved paradigm performs on real-world datasets (e.g., nuScenes, Waymo, BDD100K) or in on-vehicle tests, especially under domain shifts (weather, night, rare events).
- Sensor modality limitations: the model uses only a single front-view RGB camera; it is unclear how performance scales with multi-view cameras, LiDAR, radar, or fusion of these, and whether interleaving offers benefits beyond monocular setups.
- Short prediction and control horizon: the 4 s horizon at 2 Hz video generation (and aligned action frequency) may be insufficient for complex urban maneuvers; scalability to longer horizons (8–10 s) and higher action rates (10–50 Hz) remains untested.
- Closed-loop training vs. exposure bias: training appears to use supervised targets (teacher forcing) without on-policy rollouts; it is unclear whether DAgger/RL-style on-policy fine-tuning would reduce compounding errors in the interleaved loop.
- Uncertainty and multimodality: the approach predicts a single trajectory; handling multi-modal futures, calibrated uncertainty, risk-aware planning, and scenario sampling (e.g., multiple candidate futures/plans) is not explored.
- Interactive multi-agent behavior: other agents’ policies are not modeled explicitly; there is no mechanism for agent-ego negotiation or intent inference, nor ablations on highly interactive scenarios (merging, unprotected lefts with assertive opponents).
- Depth reliability and robustness: the method depends on Depth Anything 3 outputs; robustness to depth errors, adverse conditions, or cross-domain shifts is not evaluated, and comparisons to stereo/LiDAR depth or end-to-end learned geometric priors are missing.
- Limited geometric use at prediction time: depth is only fused in historical frames; the model does not predict or explicitly use geometry in future frames (e.g., future depth/BEV), leaving potential gains from explicit 3D forecasting unexplored.
- Tokenization constraints: discrete MagVIT-v2 tokenization (28 dynamic tokens/frame + fixed codebooks) may bottleneck fine-grained motion; the impact of token budget, codebook size, or continuous latent video models on planning and video fidelity is not studied.
- Frequency alignment vs. real control demands: Scheme E aligns to 2 Hz evaluation, but real systems need higher-rate control; how to reconcile interleaving at high frequency without degrading performance or incurring latency spikes is unclear.
- Runtime and deployment viability: no latency, throughput, or memory analysis is provided; feasibility on automotive-grade compute (vs. 32× H20 GPUs) and the impact of KV-caching on long sequences remain open.
- Safety guarantees and failure analysis: the method lacks formal safety constraints, verification, or falsification-based testing; there is no systematic analysis of failure modes, near-misses, or rare safety-critical events.
- Map and route priors: only a high-level command is used; the benefits of HD maps, lane-topology priors, and route context in the interleaved loop are not quantified.
- Evaluation breadth: planning is assessed primarily by PDMS and video by FVD; sensitivity to alternative/complimentary metrics (e.g., collision types, near-miss counts, jerk/comfort at higher frequency, human-in-the-loop ratings) is unknown.
- Robustness to sensor/model perturbations: no studies on camera occlusions, calibration errors, compression artifacts, or depth estimator degradation; adversarial or OOD robustness is untested.
- Comparative ablations on paradigms: while interleaving is motivated, a controlled within-architecture comparison to “predict-only,” “plan-only,” and “predict-then-plan” variants (with matched capacity and training budget) is missing.
- Action representation and control interface: the model regresses 2 Hz ego positions; the pathway to low-level actuation (steering/throttle/brake), controller compatibility, and tracking errors at execution time are not evaluated.
- Dataset mixing in ablations: some ablations supplement 10 Hz trajectories from nuPlan; the effect of cross-dataset supervision and potential biases on reported gains is not analyzed.
- Memory and temporal context: the model conditions on 2 s history; trade-offs between longer histories, memory mechanisms, and planning stability (including drift over extended horizons) are not explored.
- Explainability and human factors: despite using an MLLM backbone, the system does not expose interpretable rationales for plans or visual predictions; the role of language guidance or chain-of-thought in improving robustness is unexamined.
- Scalability of depth fusion strategy: depth encoders are frozen in joint training; it is unknown whether end-to-end fine-tuning, distillation into the backbone, or lightweight adapters could yield better spatial reasoning without destabilizing training.
- Fairness of baseline settings: some competitors use multi-sensor inputs; a matched-sensor comparison (e.g., Uni-World VLA with LiDAR/multi-view vs. LiDAR/multi-view baselines) is needed to isolate the contribution of interleaving.
- Scene graph/BEV reasoning: there is no explicit representation of lanes, static obstacles, or agent states (e.g., in BEV or scene-graph form); whether hybrid interleaving plus structured intermediate representations would improve planning remains open.
- Robust receding-horizon planning: the method interleaves imagination and actions but does not compare to strong receding-horizon planners that frequently replan from fresh observations; benefits beyond frequent replanning baselines are uncertain.
Practical Applications
Immediate Applications
The following use cases can be pursued with current capabilities described in the paper (camera-only, front-view input; 2 Hz, 4 s horizon; NAVSIM-scale validation; MagVIT-v2 tokenization; Show-o LLM; Depth Anything 3 fusion; KV-cache; dynamic focal loss).
- Closed-loop simulation-based planner evaluation and benchmarking
- Sector: Automotive (R&D), Academia
- What to do: Integrate the interleaved prediction–planning loop as a “policy-under-test” in high-fidelity simulators (e.g., NAVSIM) to measure PDMS, TTC, EP, and qualitative video forecasts side-by-side with planned waypoints.
- Tools/workflows: “Interleaved VLA” policy plugin; KD/AB testing of planners; automated scenario sweeps; report generation (PDMS + FVD).
- Assumptions/dependencies: Validated primarily in simulation (NAVSIM); single front camera; 2 Hz control horizon; compute budget for autoregressive LLM with KV-cache.
- What-if analysis and counterfactuals for planner debugging
- Sector: Automotive (planning teams), Academia
- What to do: Use interleaved generation to visualize how alternate actions (e.g., earlier braking) would change near-future frames and planned trajectories at each step.
- Tools/workflows: Counterfactual “action tokens” API; side-by-side video and trajectory diffs; TTC/EP overlays.
- Assumptions/dependencies: Requires calibrated mapping from action tokens to waypoints; fidelity depends on data domain match and tokenization quality.
- Data augmentation and consistency regularization for end-to-end driving models
- Sector: Automotive (ML engineering), Software/AI
- What to do: Generate short horizon future frames and waypoints to augment supervised datasets; use video–trajectory consistency losses to regularize imitation learners.
- Tools/workflows: Batch offline generation; curriculum schedules leveraging 2–4 s previews; dynamic focal loss to weight changing regions.
- Assumptions/dependencies: Risk of distribution shift and compounding errors; needs careful filtering (e.g., FVD thresholds) and confidence scoring.
- Explainable planning demos and reviewer tooling
- Sector: Automotive, Policy/Regulation (review/assessment)
- What to do: Present predicted frames alongside planned waypoints and metrics (TTC, EP) to internal safety boards or external reviewers to justify decision-making in complex maneuvers.
- Tools/workflows: “Future-view + path” explainer UI; on-scenario replay; automated metric annotations.
- Assumptions/dependencies: Not a formal safety argument; explainability is visual/proxy, not rule-verified; simulation domain.
- Hazard preview for driver training simulators
- Sector: Education/Training, Automotive
- What to do: In training sims, render near-future frames and expected ego path to help drivers practice anticipation (merging, unprotected turns, cut-ins).
- Tools/workflows: Unity/Unreal plugin; configurable horizons (2–4 s); curriculum tasks with increasing scene dynamics.
- Assumptions/dependencies: For simulators only; not suitable for on-road driver coaching without further validation.
- Robotics prototyping for camera-only mobile platforms
- Sector: Robotics (warehouses, AMRs), Academia
- What to do: Adapt the interleaved world-model–action loop to short-horizon navigation (e.g., aisle following, intersection negotiation) for camera-centric robots.
- Tools/workflows: Domain fine-tuning; tokenizers for environment-specific video; action head remapping to platform kinematics.
- Assumptions/dependencies: Requires dataset and action-space adaptation; limited to short horizons and benign dynamics initially.
- Depth-fusion adapters for long-horizon prediction
- Sector: Perception/Simulation (Automotive/Robotics), Software/AI
- What to do: Drop-in cross-attention modules that fuse monocular depth features (Depth Anything 3) into historical tokens to stabilize long-horizon predictions.
- Tools/workflows: Context-/dynamic-depth encoders (CDE/DDE); frozen backbone + fusion training stages; two-stage progressive training as described.
- Assumptions/dependencies: Monocular depth must generalize to target domain; quality degrades under adverse weather/low light.
- Efficient multi-modal autoregressive inference patterns
- Sector: Software/AI tooling
- What to do: Reuse the KV-cache and intra-frame bi-directional attention with causal masking as a template for efficient video–action generation in other AR tasks (e.g., sports analysis, surveillance forecasting).
- Tools/workflows: Library patterns for token caching; frame–action interleaving scaffolds.
- Assumptions/dependencies: Benefits hinge on tokenization quality and strict causal discipline; latency must be profiled per use case.
- Safety QA triage using short-horizon risk signals
- Sector: Automotive QA, Insurance Tech (internal R&D)
- What to do: Compute TTC and path feasibility from predicted frames/actions to flag scenarios with high collision risk for focused review.
- Tools/workflows: Batch offline inference on fleet sim logs; rule-based triage thresholds; reviewer dashboards.
- Assumptions/dependencies: Proxy metrics; not calibrated to real fleets; visual forecasts reflect training distribution.
- Benchmark design and curriculum learning studies
- Sector: Academia
- What to do: Use the interleaved setup to design tasks that penalize open-loop drift and reward adaptive, step-wise planning; ablate token orderings and depth usage.
- Tools/workflows: Public benchmark splits; ablation harness for schemes A–E; reproducible training recipes (dynamic focal loss, two-stage fusion).
- Assumptions/dependencies: Availability of comparable simulators and data; standardization of evaluation frequencies (2 Hz alignment).
Long-Term Applications
These concepts require additional research, domain adaptation, sensor fusion, real-world validation, scaling, or certification before production use.
- Core planner for L2+/L4 autonomous driving with multi-sensor fusion
- Sector: Automotive
- What it could enable: Interleaved world-model and planning as the primary decision module, fusing LiDAR/radar + surround cameras for robust multi-agent interactions.
- Tools/products: “Uni-World Planner” integrated into autonomy stacks; redundancy/failsafe pathways; online uncertainty estimation.
- Assumptions/dependencies: Real-world robustness, latency guarantees, verification/validation, safety case evidence, sensor fusion codebooks, fail-operational design.
- Generalist embodied agents with interleaved world modeling
- Sector: Robotics (delivery, drones), Logistics
- What it could enable: Cross-domain agents that anticipate and adapt to dynamic worlds (e.g., curbside delivery, urban UAV flight) via step-wise prediction–action loops.
- Tools/products: Domain-adapted tokenizers; 3D-aware actions; hierarchical control integration.
- Assumptions/dependencies: 3D geometry grounding, non-planar dynamics, regulatory constraints for air/sidewalk robots.
- Fleet learning and continual adaptation
- Sector: Automotive
- What it could enable: On-vehicle or cloud-assisted continual learning that refines the world model and planner jointly from fleet logs (closed-loop, scenario-driven).
- Tools/products: Federated training pipelines; data governance; online calibration.
- Assumptions/dependencies: Privacy and compliance, robust OOD detection, catastrophic forgetting mitigation.
- City-scale predictive digital twins and traffic management
- Sector: Smart Cities, Public Sector
- What it could enable: Near-term anticipatory simulation of urban traffic for control (signal timing, ramp metering), incident prediction, and road work planning.
- Tools/products: Ingestion from infrastructure cameras/V2X; multi-agent interleaved models; traffic control integration.
- Assumptions/dependencies: Multi-camera tracking, identity persistence, scaling beyond single ego, governance for data use.
- Cooperative V2X prediction and planning
- Sector: Automotive, Telecommunications
- What it could enable: Interleaved prediction incorporating V2X messages (intent, occupancy) to improve merges, unprotected turns, and occluded hazard handling.
- Tools/products: V2X-augmented token streams; message-to-token encoders; consensus planning.
- Assumptions/dependencies: Communication latency/robustness, standards alignment (C-V2X/DSRC), security.
- AR HUDs and driver assistance with future-view overlays
- Sector: Consumer Automotive, HMI
- What it could enable: In-vehicle displays showing anticipated path and critical agent dynamics 2–4 s ahead to improve driver situational awareness.
- Tools/products: Edge-optimized inference; human factors–validated visualizations; fallback strategies.
- Assumptions/dependencies: Real-time performance, distraction risk management, legal liability, on-road validation.
- Model-based RL and policy optimization with learned interleaved world models
- Sector: AI/ML research, Automotive
- What it could enable: Sample-efficient policy learning via closed-loop rollouts; planning under uncertainty with short-horizon lookahead.
- Tools/products: MBRL frameworks using tokenized world models; uncertainty-aware value estimation.
- Assumptions/dependencies: Stable long-horizon prediction, error compounding control, reward shaping.
- Safety certification methodologies leveraging visualized near-future evidence
- Sector: Policy/Regulation, Standards
- What it could enable: New guidelines and tests that require closed-loop foresight demonstrations (e.g., TTC evolution with visual projections) to substantiate safety cases.
- Tools/products: Conformance test suites; standardized metrics coupling PDMS-like scores and visual fidelity.
- Assumptions/dependencies: Consensus on measures, traceability from visual forecasts to verifiable safety artifacts.
- Insurance/telematics risk analytics from predictive perception
- Sector: Finance/Insurance
- What it could enable: Short-horizon hazard and maneuver difficulty scoring to inform risk models or coaching for commercial fleets.
- Tools/products: Onboard/edge inference; privacy-preserving aggregation; API for risk features.
- Assumptions/dependencies: Regulatory approval, privacy safeguards, robust real-world generalization; explainability.
- Hardware–software co-design for tokenized video–action inference
- Sector: Semiconductors, Edge AI
- What it could enable: Accelerators optimized for codebook lookups, KV-cache reuse, and interleaved decoding to meet tight latency budgets in vehicles/robots.
- Tools/products: Token-cache SRAM blocks; fused attention operators; compiler passes for causal masks.
- Assumptions/dependencies: Volume economics, evolving model architectures, standardization of tokenizers.
- Multi-view, multi-modality expansion and open-set robustness
- Sector: Automotive/Robotics
- What it could enable: Unified interleaved modeling that handles surround cameras, LiDAR, radar, adverse weather, and OOD conditions with calibrated uncertainty.
- Tools/products: Cross-modality token harmonization; domain-adaptive depth fusion; OOD detectors.
- Assumptions/dependencies: Diverse training data, robust codebooks across sensors, scalable training infrastructure.
Notes on Cross-Cutting Assumptions and Constraints
- Validation domain: Results are shown on NAVSIM; transferring to real-world driving requires careful domain adaptation and extensive on-road testing.
- Sensing: The reported model uses a single front camera; production systems will likely require multi-view and/or LiDAR/radar fusion.
- Temporal settings: The approach aligns best when generation and evaluation frequencies match (2 Hz in the paper); real deployments may need 10–20 Hz control loops.
- Compute and latency: Autoregressive interleaving with LLM backbones must meet strict real-time constraints; KV-cache helps but hardware optimization is needed.
- Safety and certification: Visual predictions aid interpretability but do not replace formal verification; regulatory acceptance will require standardized evidence.
- Monocular depth: Depth fusion improves long-horizon prediction but may degrade in adverse conditions; confidence estimation and fallback strategies are necessary.
Glossary
- 3D Gaussian Splatting: A neural rendering technique that represents scenes with explicit Gaussian primitives for fast, high-quality 3D reconstruction. "explicit 3D Gaussian Splatting~\cite{kerbl20233dgaussian,huang2024textits3gaussian}"
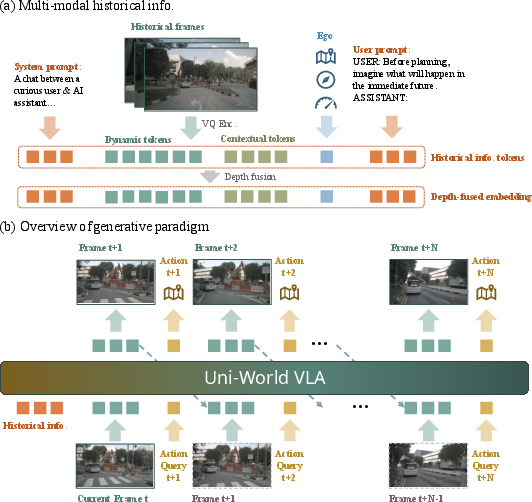
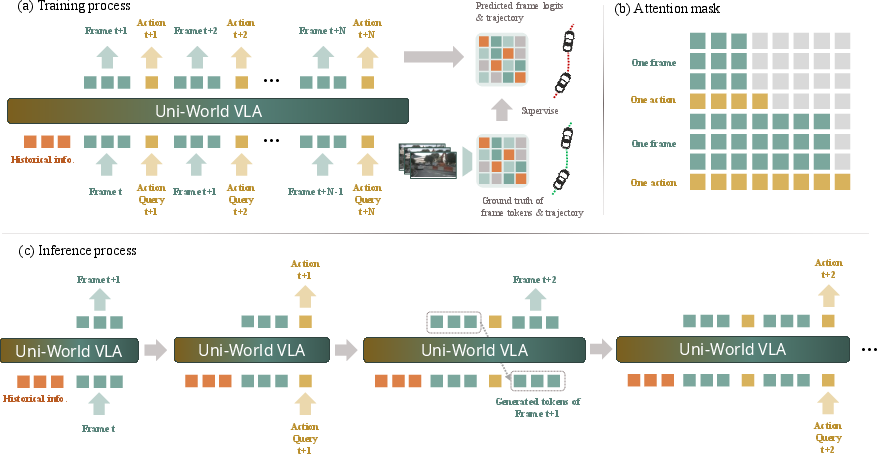
- autoregressive architecture: A sequence model that generates each token conditioned on previously generated tokens. "a unified autoregressive architecture that alternates between generating visual tokens and action tokens"
- BEV: Bird’s-Eye View; a top-down projection commonly used to visualize road layouts and trajectories in driving. "Visualization of predicted frames and BEV trajectories"
- bi-directional intra-frame attention: An attention mechanism that allows tokens within the same frame to attend to each other in both directions to capture spatial dependencies. "a bi-directional intra-frame attention mechanism"
- causal attention mask: An attention mask that enforces temporal causality by preventing a token from attending to future tokens. "Causal attention mask."
- causal masking: A constraint in sequence models that masks future information to preserve temporal causality. "preserving causal masking across time."
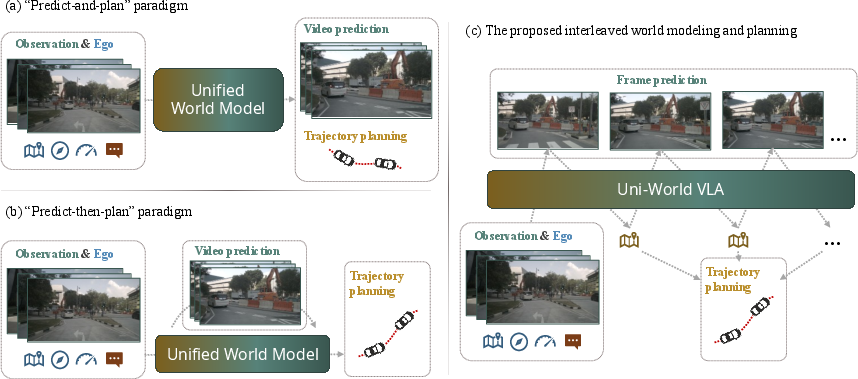
- closed-loop: A feedback process where predictions and actions are iteratively updated based on newly generated observations. "forming a closed-loop interaction"
- codebook: The discrete set of quantized token entries used by a vector-quantized tokenizer. "separate codebooks of size $8192$ each."
- cosine annealing schedule: A learning rate schedule that decreases the rate following a cosine curve to promote smooth convergence. "the learning rate follows a cosine annealing schedule."
- cross-attention: An attention mechanism that fuses information by attending from one modality’s queries to another modality’s keys and values. "fuses the geometric features with historical frames through a cross-attention mechanism"
- cross-entropy loss: A standard classification loss measuring the difference between predicted and true categorical distributions. "if simply supervise the logits with cross-entropy loss"
- Depth Anything 3: A monocular depth estimation foundation model used to extract depth maps from single images. "monocular depth maps are estimated using Depth Anything 3~\cite{lin2025depth3recoveringvisual}"
- discrete token space: A quantized representation where images or videos are converted into a sequence of discrete symbols for generative modeling. "Visual observations are first compressed into a discrete token space"
- Drivable Area Compliance (DAC): A metric indicating how well the planned trajectory remains within legally drivable regions. "drivable area compliance~(DAC)"
- Dynamic Focal Loss: A loss that emphasizes dynamic (changing) regions in video prediction by spatially reweighting errors. "we adopt the Dynamic Focal Loss~\cite{zhao2025pwm}"
- ego-centric: A viewpoint centered on the agent (vehicle), capturing the scene from its own perspective. "ego-centric RGB sequences"
- ego progress (EP): A planning metric measuring forward movement or progress toward the goal. "ego progress~(EP)"
- ego tokens: Encoded signals of the vehicle’s state and intent (e.g., velocity, acceleration, command) used by the model. "Ego tokens concatenate ego velocity, ego acceleration, and the high-level driving command at time "
- ego vehicle: The autonomous vehicle being controlled and planned for within the simulation or model. "the ego vehicleâs trajectory"
- Fréchet Video Distance (FVD): A metric for assessing realism of generated videos by comparing feature distributions of real and synthesized sequences. "Fréchet Video Distance~(FVD)"
- foundation model: A large pre-trained model that provides general-purpose representations for downstream tasks. "the pre-trained foundation model"
- implicit radiance fields: Continuous neural scene representations that model radiance and density for novel-view synthesis (e.g., NeRF). "implicit radiance fields~\cite{mildenhall2021nerf,xiao2025neuralradiancefieldsreal}"
- interleaved generation: Alternating prediction of future observations and actions to keep planning conditioned on the latest imagined states. "This interleaved generation forms a closed-loop interaction"
- KV-cache: A mechanism that caches transformer key/value tensors to avoid recomputation during autoregressive decoding. "we leverage a KV-cache"
- MagVIT-v2: A compressive vector-quantized video tokenizer used to convert frames into discrete tokens and reconstruct them. "MagVIT-v2~\cite{yu2024magvitv2}"
- MLLM: Multi-modal Large Model; a large model jointly processing multiple modalities like vision, language, and action. "multi-modal large models~(MLLM)"
- monocular depth maps: Depth estimates derived from a single camera frame without stereo or LiDAR. "monocular depth maps"
- multi-view stereo: A classical geometric method reconstructing depth by matching features across multiple images. "multi-view stereo~\cite{Seitz2006mvs,pepe2022uavplatformsandthesfm-mvsapproach}"
- NAVSIM: A high-fidelity simulated driving dataset used for closed-loop planning and video prediction evaluation. "the NAVSIM~\cite{daniel2024navsim, cao2025pseudosimulation} driving dataset"
- nuPlan: A large-scale driving dataset providing trajectories and annotations for training and evaluation. "nuPlan~\cite{caesar2021nuplan}"
- open-loop imagination: Predicting future scenes without incorporating feedback from planned actions, leading to drift. "open-loop imagination"
- Predictive Driver Model Score (PDMS): A composite score aggregating safety, comfort, and progress metrics for driving performance. "Predictive Driver Model Score (PDMS)"
- Phi-1.5: A lightweight LLM backbone variant used as the base for multimodal reasoning. "a Phi-1.5-based~\cite{Li2023phi-1.5} multimodal LLM."
- Policy World Model (PWM): A prior driving world model that jointly predicts states and actions, used for initialization here. "Policy World Model (PWM)"
- predict-and-plan: A paradigm where prediction and planning are performed jointly but functionally decoupled within one model. "parallel ``predict-and-plan''"
- predict-then-plan: A paradigm where future scenes are first predicted and then a trajectory is planned conditioned on them. "sequential ``predict-then-plan''"
- Show-o: A Phi-1.5-based multimodal LLM used as the generative backbone. "Show-o~\cite{xie2024showo}"
- spatiotemporal scene cues: Features that capture both spatial structure and temporal dynamics of the environment. "spatiotemporal scene cues"
- structure-from-motion: A geometric pipeline reconstructing 3D structure from sequences of 2D images and camera motion. "structure-from-motion~\cite{Schonberger2016sfmrevisited, pan2025globalsfmrevisited}"
- temporal causality: The principle that causes precede effects in time, enforced in model attention and generation. "respects the temporal causality of driving."
- time-to-collision (TTC): A safety metric estimating remaining time before a potential collision given current dynamics. "time-to-collision~(TTC)"
- vector quantization: A discretization technique mapping continuous features to the nearest entries in a codebook. "vector quantization"
- vision-language-action (VLA): Models that integrate vision, language understanding, and action generation for decision-making. "vision-language-action (VLA)"
- world models: Learned internal simulators that predict future states of the environment conditioned on actions. "world models~\cite{vista,zhang2025epona} have attracted increasing attention in autonomous driving."
Collections
Sign up for free to add this paper to one or more collections.

