- The paper demonstrates that zero-shot VLMs struggle with surgical tool detection, performing near a majority-class baseline even at large scales.
- Task-specific fine-tuning using LoRA and specialized models like YOLOv12-m significantly boosts in-domain accuracy despite challenges in out-of-distribution scenarios.
- Increased parameter scaling fails to overcome data fragmentation and distribution shifts, emphasizing the need for hierarchical, modular Med-AGI architectures.
A Comparative Analysis of Scaling Foundation Models and Specialized Architectures for Surgical Perception: Barriers to Med-AGI
Introduction
"A Comparative Study in Surgical AI: Datasets, Foundation Models, and Barriers to Med-AGI" (2603.27341) offers a rigorous empirical analysis of open-weight vision-LLMs (VLMs) and task-specific computer vision architectures for surgical tool detection. The study interrogates the prevailing Med-AGI scaling hypothesis by benchmarking 19 VLMs (2B–235B parameters), both zero-shot and after adaptation, on SDSC-EEA, a large neurosurgical video dataset, with further evaluation on the public CholecT50 laparoscopy corpus and proprietary frontier models. The work methodically dissects the contributions of dataset curation, fine-tuning, and architectures, revealing the persistent barriers and limitations of foundation models in specialized medical perception tasks.
Dataset Curation and Experimental Framework
The primary dataset, SDSC-EEA, is composed of 67,634 densely-annotated frames across 66 neurosurgical procedures. Data curation prioritized clinical fidelity and unbiased representation, with tool annotation spanning 31 classes. The study implements stringent train-validation splits at the procedure level to enforce realistic distribution shifts, critical for assessing OOD generalization.
The experimental regime is comprehensive:
- Zero-shot evaluation of 19 diverse VLMs with JSON-constrained prompting.
- LoRA-based fine-tuning of Gemma 3 27B using both JSON generation and a linear multi-label classification head.
- Sweeps of LoRA adapter rank (r=2 to $1024$, 4.7M–2.4B trainable parameters).
- Supervised training of YOLOv12-m (26M parameters), providing a domain-optimized computer vision baseline.
- External validation on CholecT50 and evaluation of several major proprietary VLMs.
Zero-shot performance on SDSC-EEA is systematically poor, with all open-weight VLMs at or near the majority-class baseline (13.4% exact match)—Qwen3-VL-235B achieves 14.5%, the highest observed.
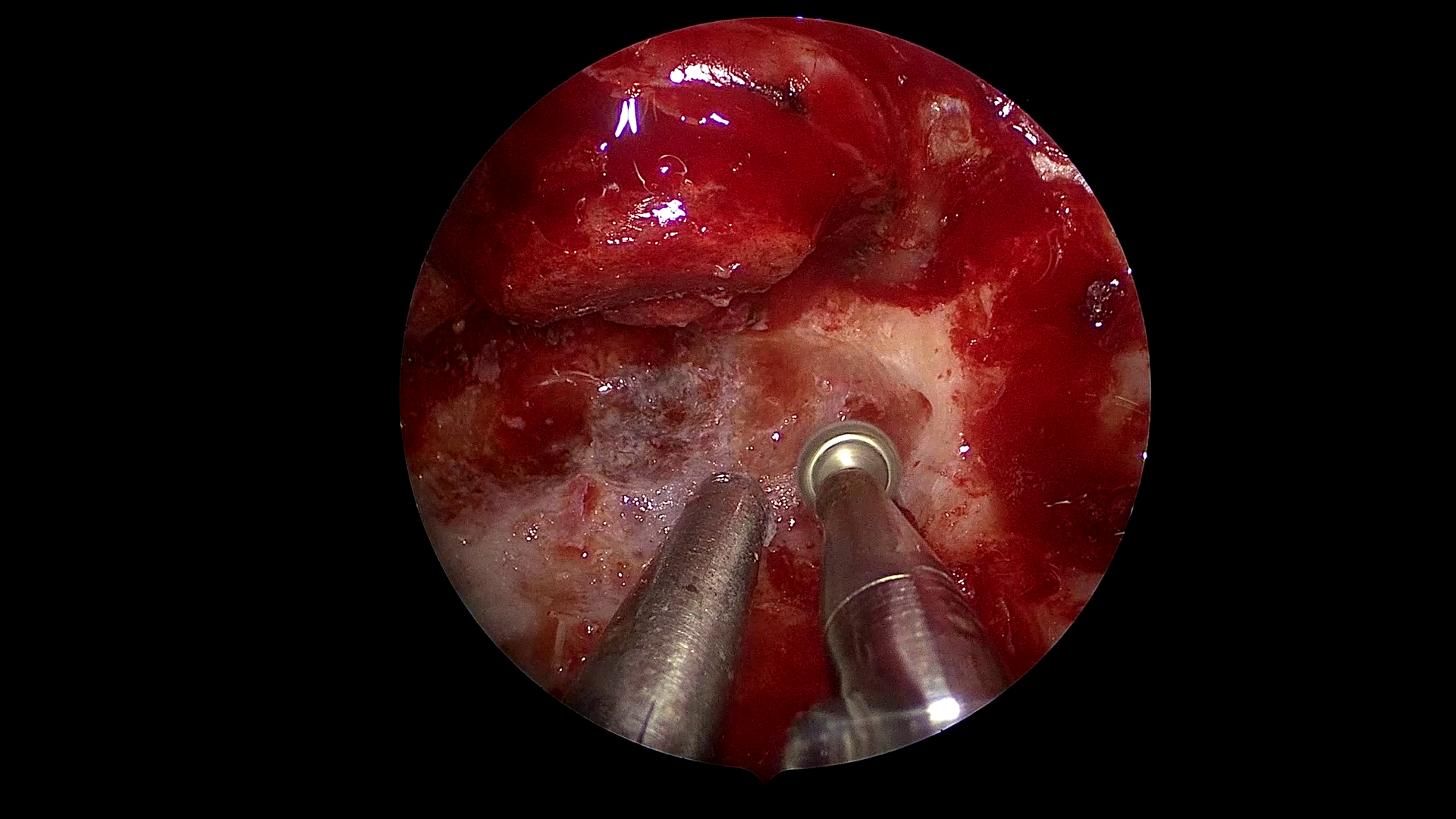
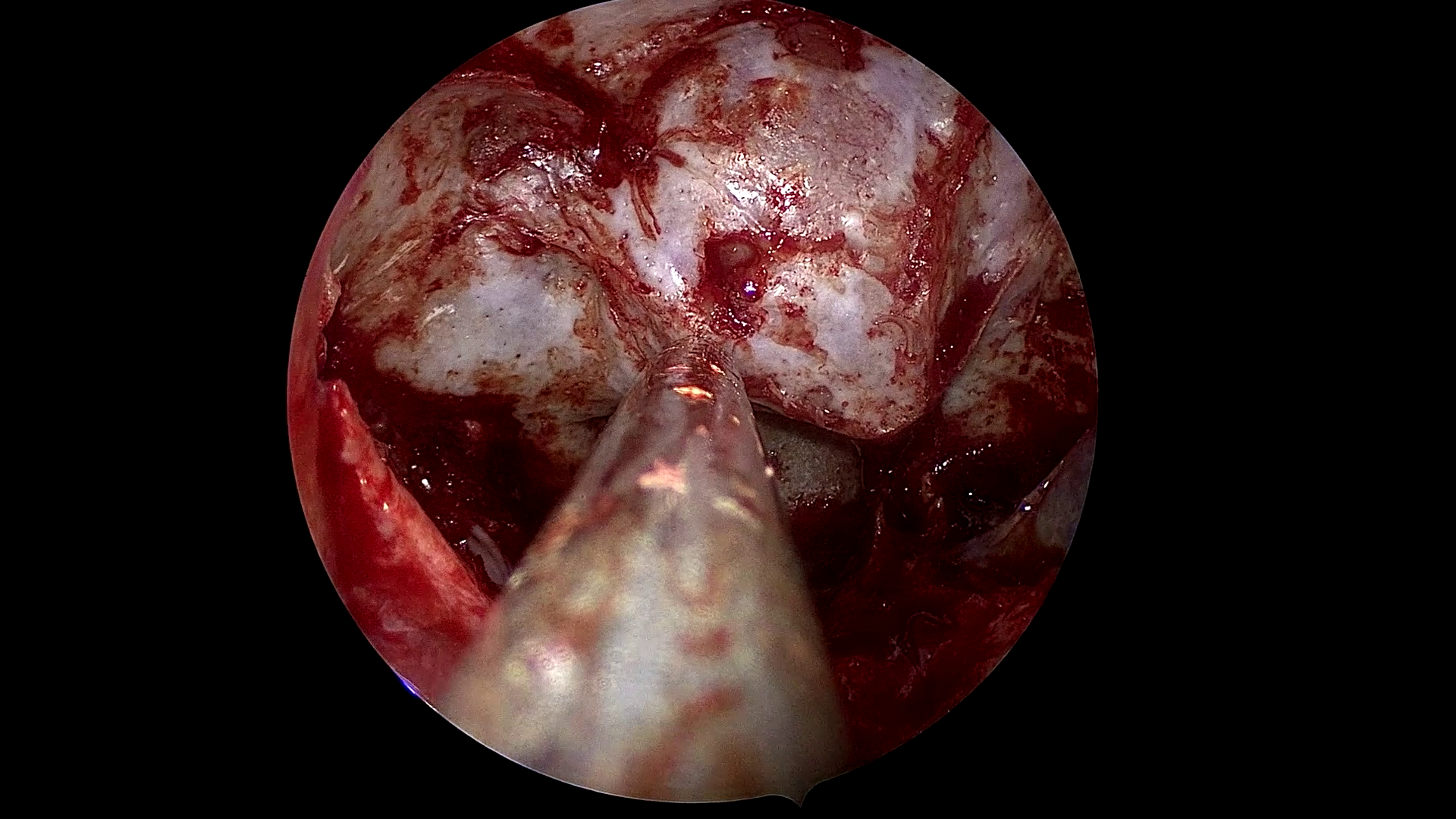
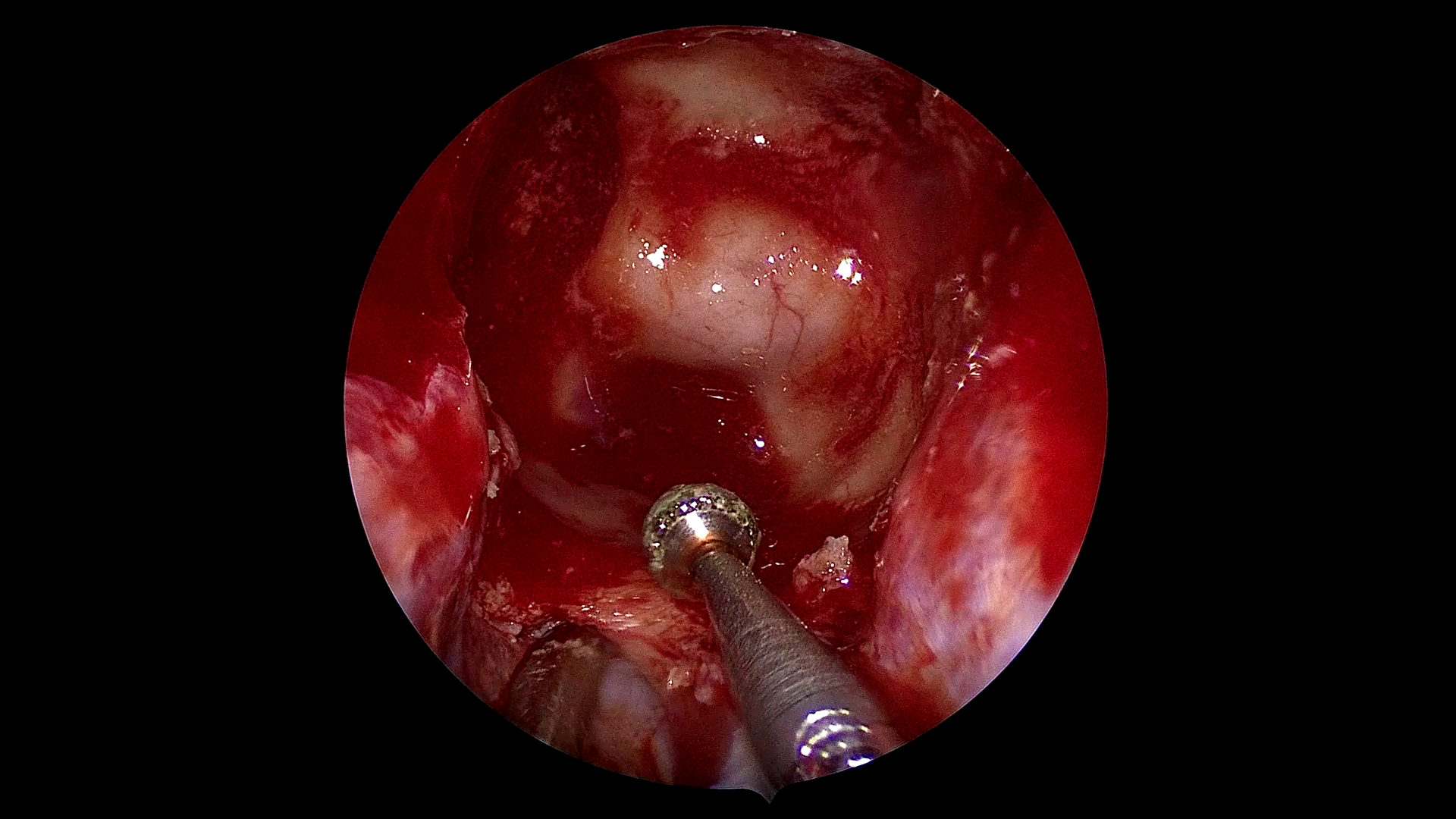
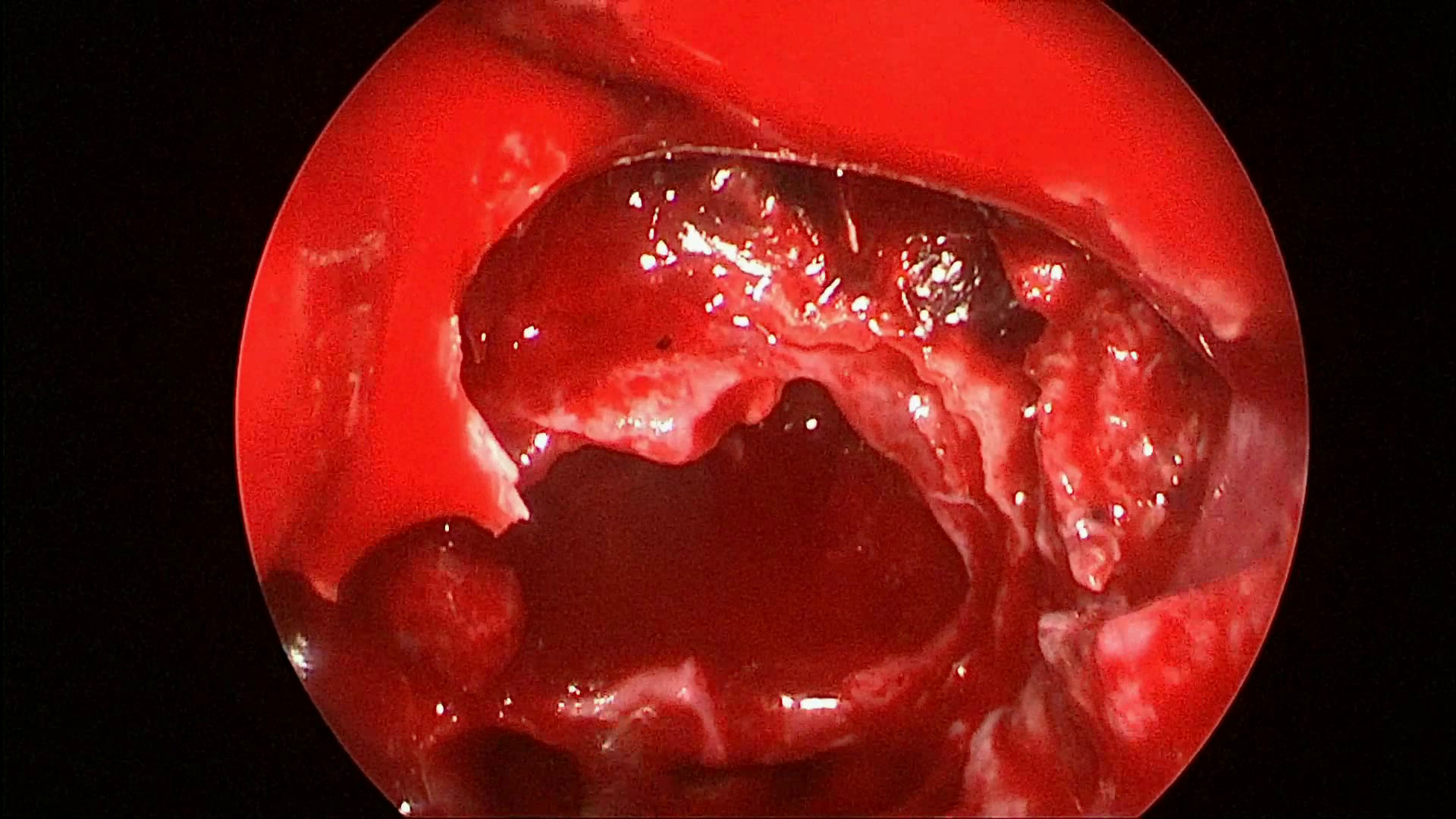
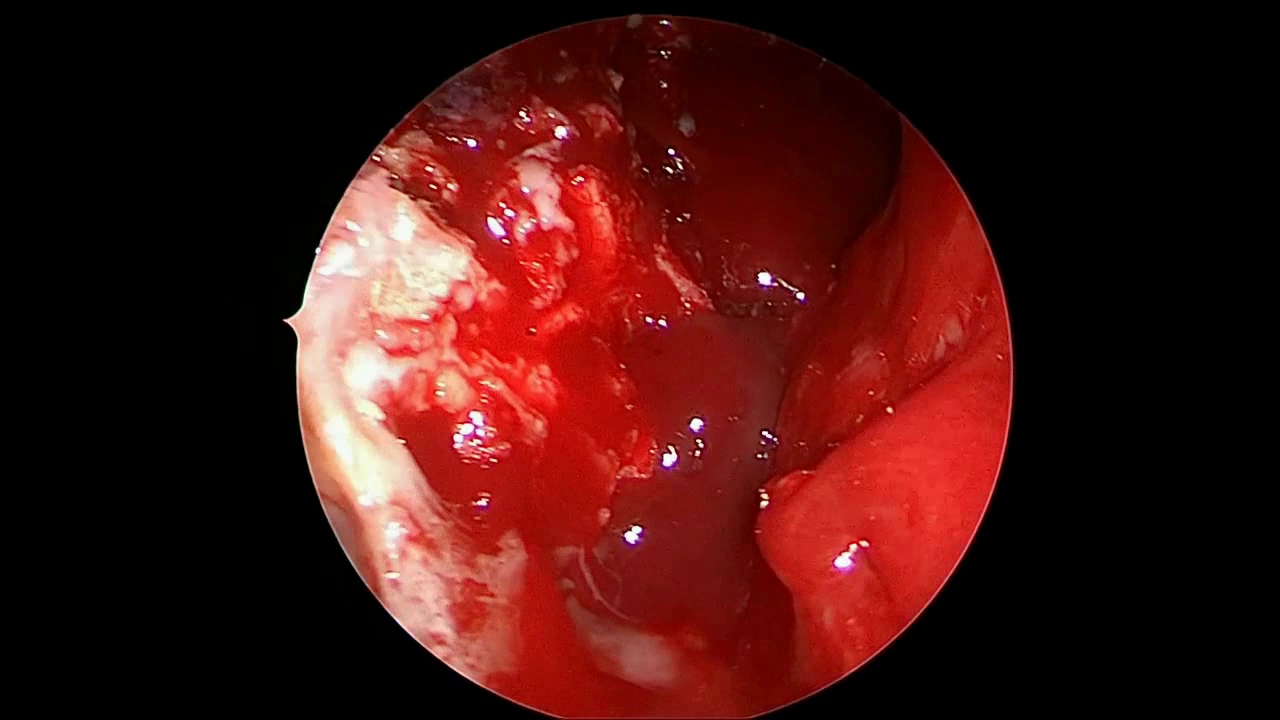
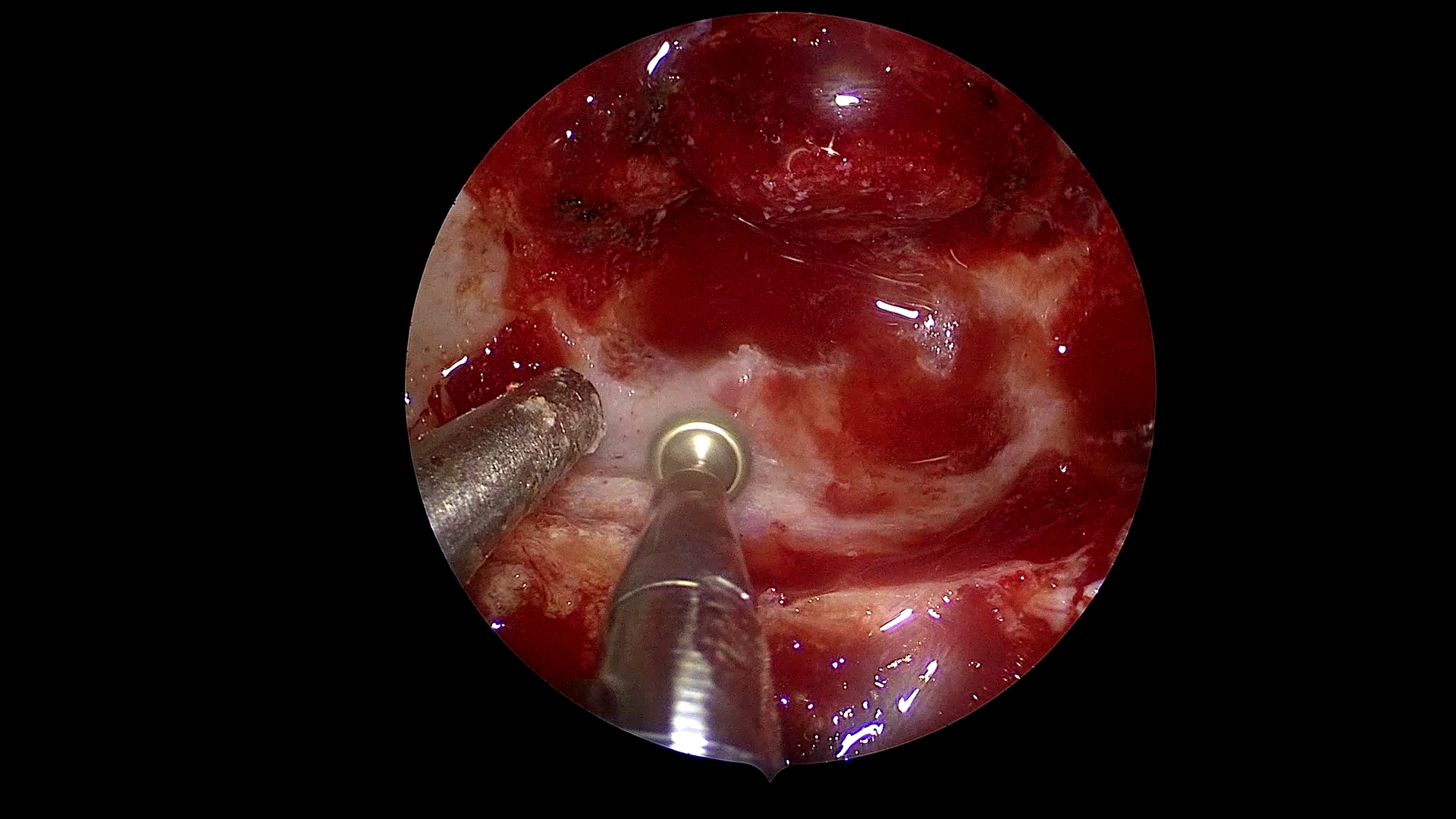
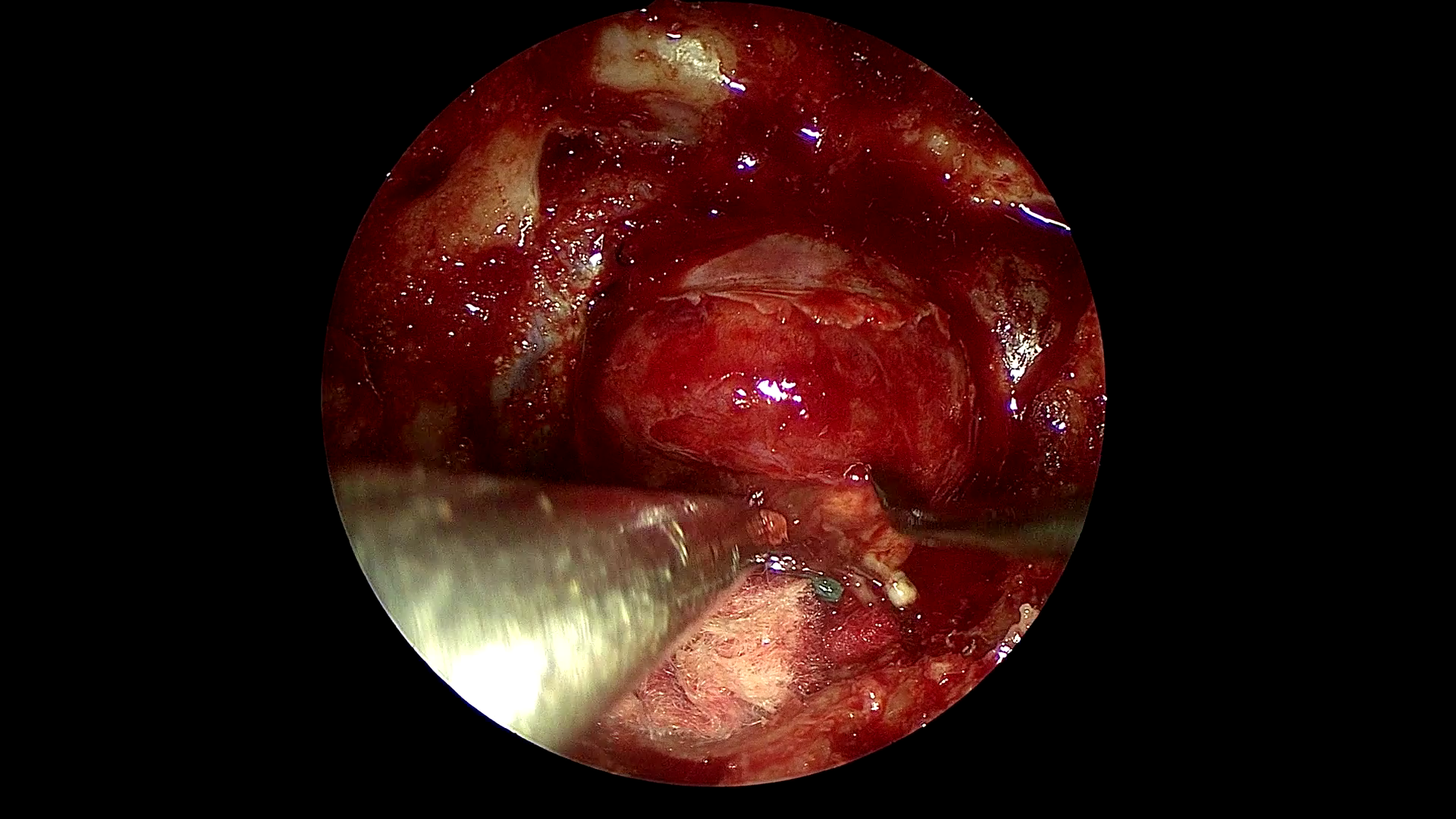
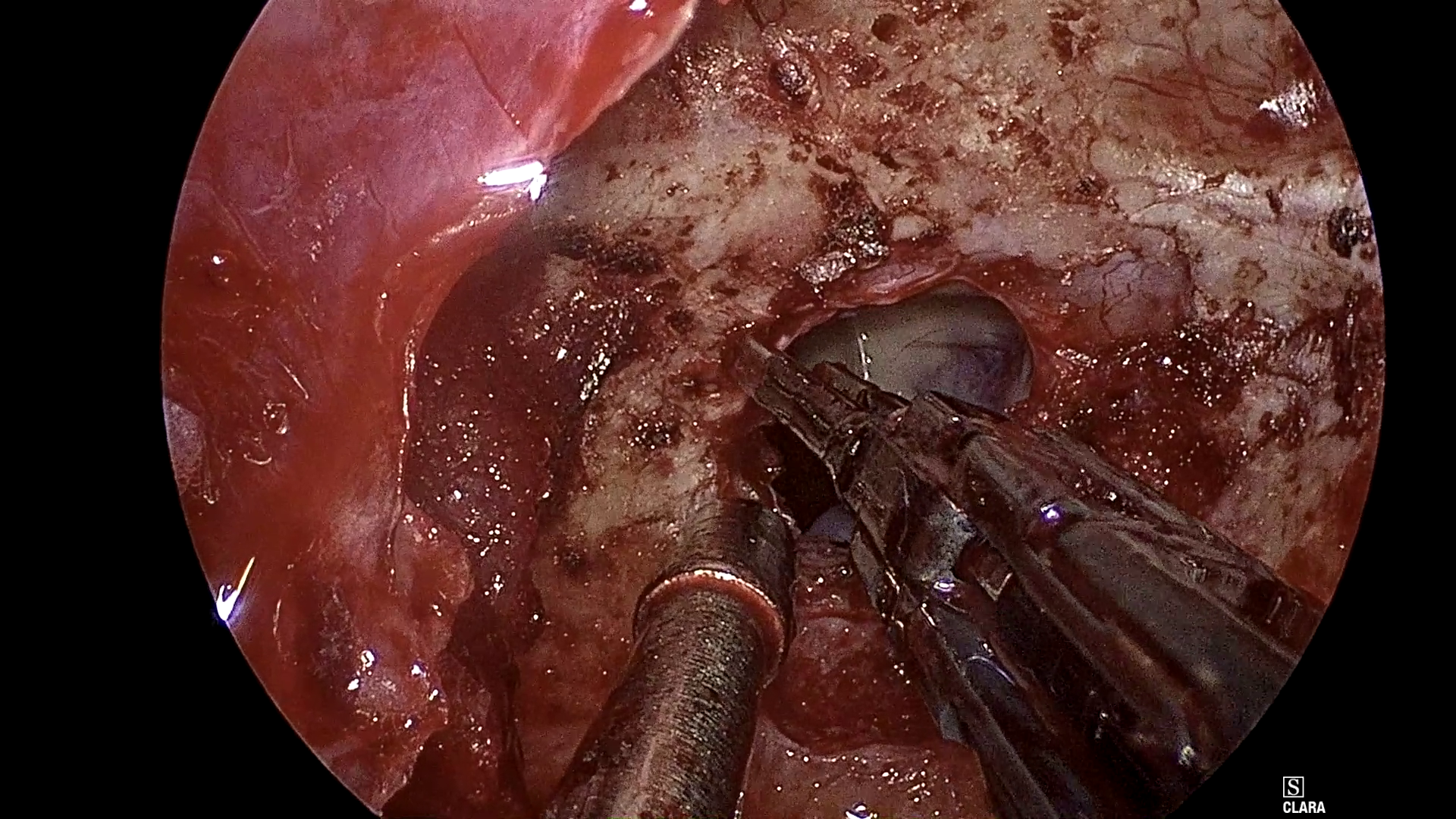
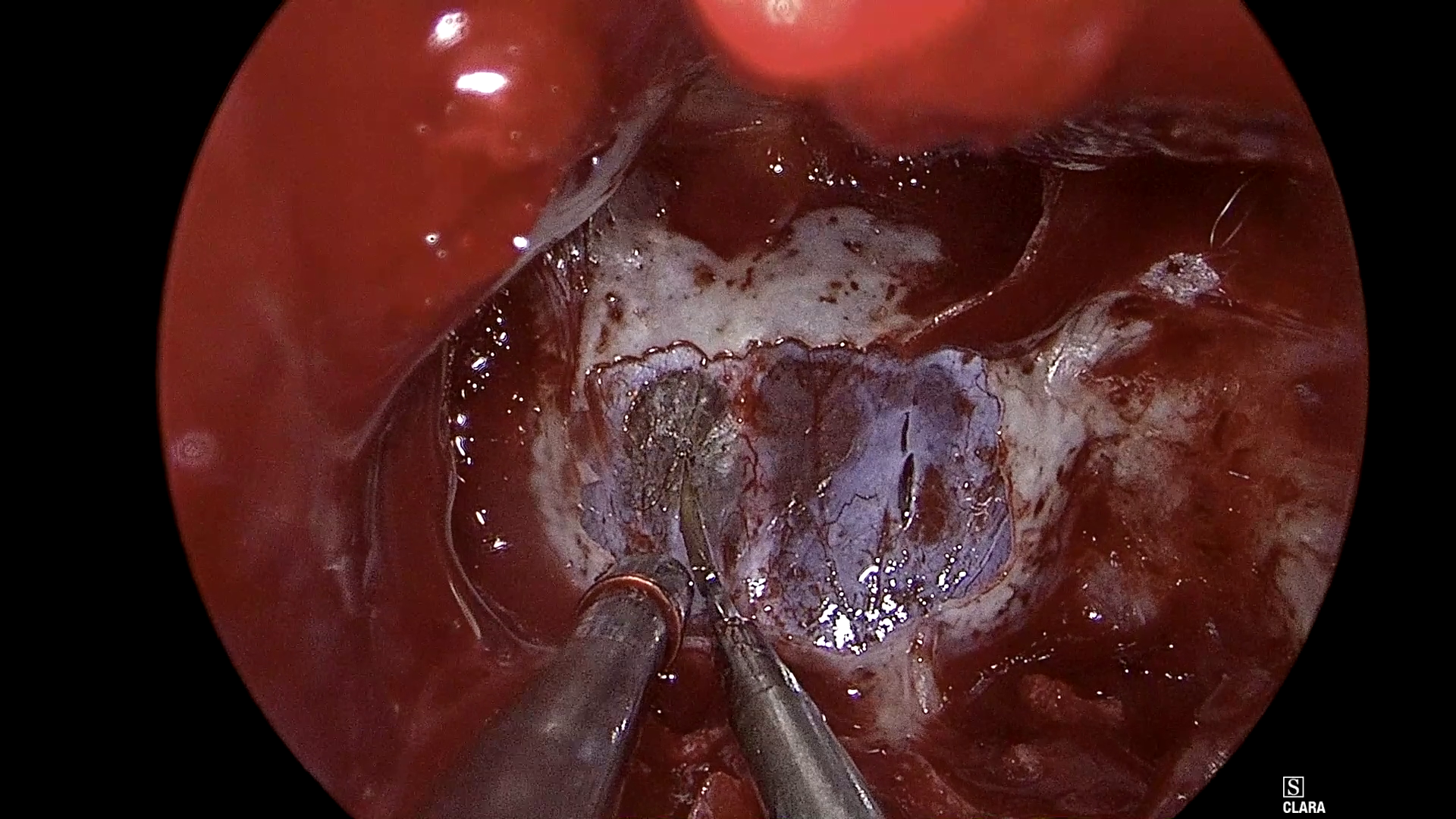
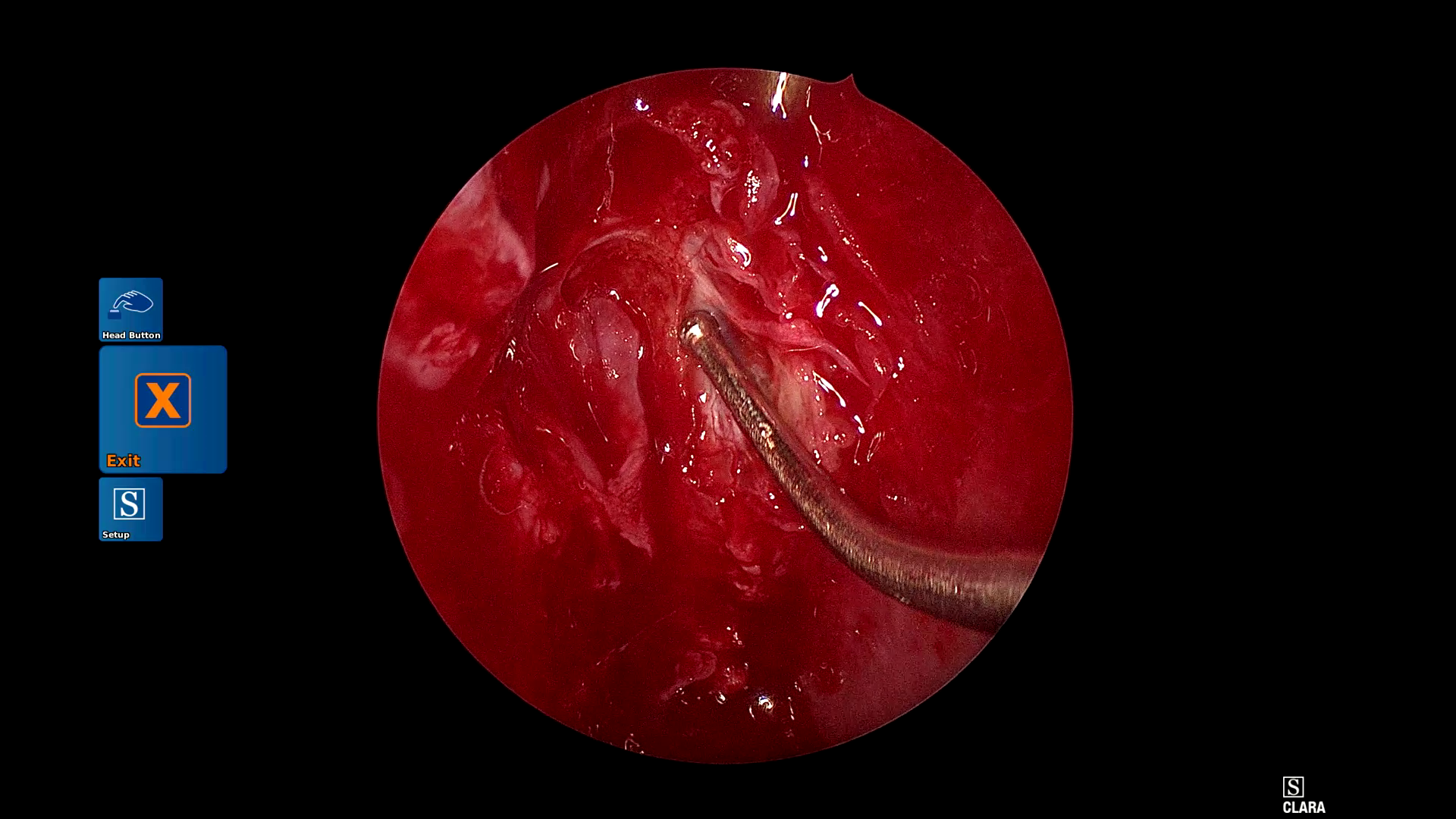
Figure 1: Example frames from SDSC-EEA illustrating successful and failed zero-shot Gemma 3 27B predictions.
This discrepancy persists despite orders-of-magnitude increases in parameter count and SOTA benchmark scores (MMBench >90; see Figure 2 and Figure 3).
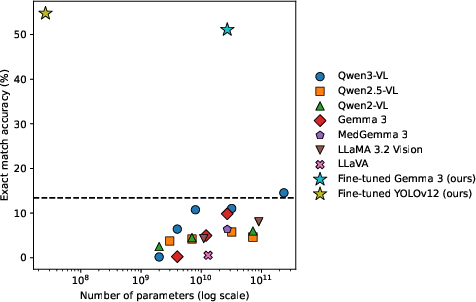
Figure 2: Exact-match accuracy on SDSC-EEA vs. model parameter count; Qwen models are family-wise superior, but absolute performance is low.
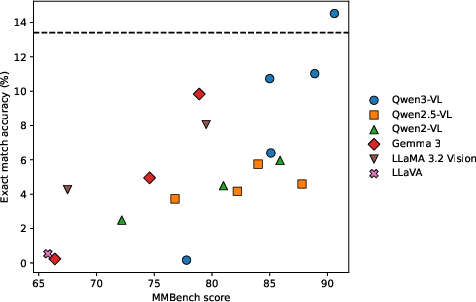
Figure 3: Zero-shot exact-match accuracy as a function of MMBench score; general capability does not translate to surgical tasks.
Qualitative analysis reveals that zero-shot outputs are dominated by label hallucinations or formatting errors (ontology and schema violations), highlighting brittle task transfer and incomplete alignment to medical ontologies.
Fine-Tuning and Adapter Scaling: Marginal Gains, Persistent Generalization Gaps
Task-specific fine-tuning with LoRA significantly increases in-domain performance: JSON-generation reaches 47.6% and classification-head tuning (preferred) achieves a best of 51.1% exact match (SDSC-EEA val set)—a marked improvement over all zero-shot and pre-training baselines.
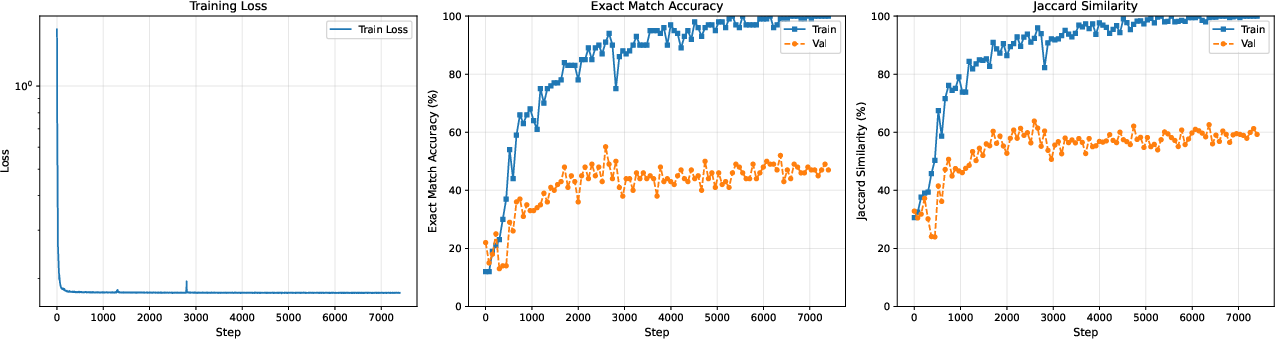
Figure 4: LoRA JSON-generation training curve: the persistent train–val gap illustrates limited generalization under realistic splits.
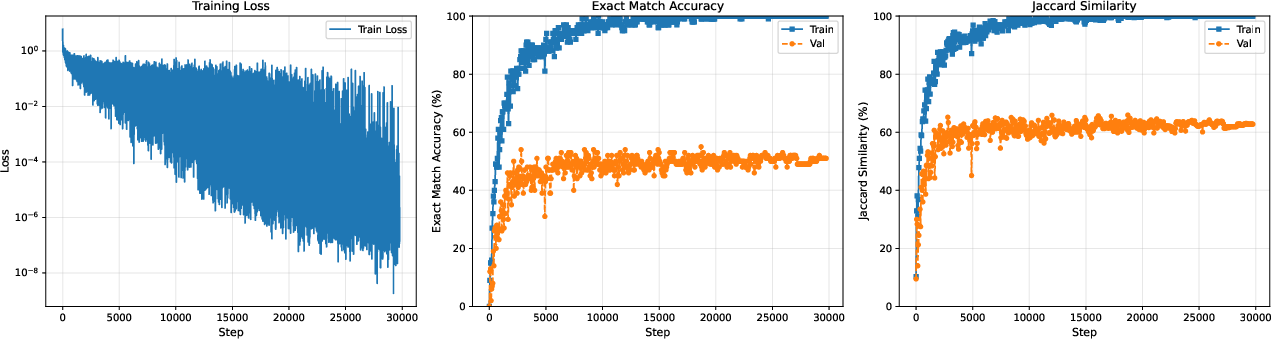
Figure 5: LoRA classifier head adaptation: in-domain gains, but the train–validation accuracy gap shows limited OOD robustness.
Adapter scale sweeps reveal a classical overfitting pattern. Training accuracy approaches 99% as r increases, but validation saturates, remaining below 40% (Figure 6).
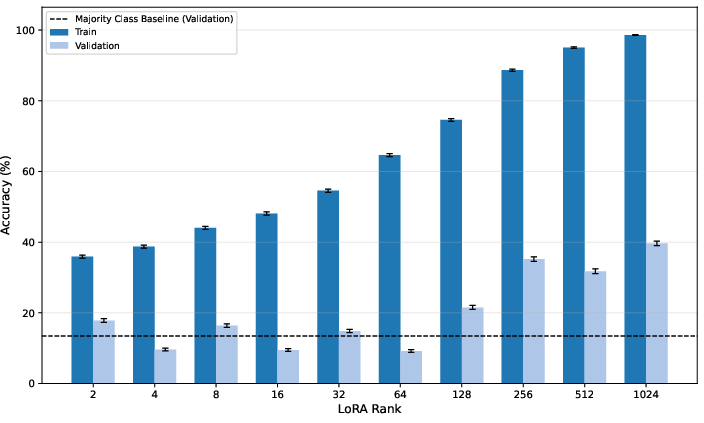
Figure 6: Exact match accuracy vs. LoRA rank for Gemma 3 27B (SDSC-EEA): increasing capacity does not transfer to distributional robustness.
Unlike scaling laws for language (Kaplan et al., 2020), increased adaptation capacity does not yield emergent generalization in this context; the bottleneck is data-centric.
Domain-Optimized Models: Small, Specialized Architectures Outperform VLMs
The 26M-parameter YOLOv12-m model exceeds all VLMs, obtaining 54.7% exact match on SDSC-EEA—surpassing Gemma 3 27B by 3.7 points while being >1000× smaller. Validation with a ResNet-50 trained solely on set-level labels but without bounding boxes achieves 39.6%, outperforming all zero-shot and low-capacity VLMs. This supports the conclusion that surgical perception is currently constrained more by data, class imbalance, and domain complexity than by model expressivity.
Cross-Domain and Closed-Model Validation
Replication on CholecT50 yields convergent results: zero-shot VLMs—even proprietary SOTA like GPT-5.4, Gemini 3.1 Pro, and Claude Opus—largely fail to surpass the majority-class baseline, while task-specific adaptation and YOLOv12-m reach 81–83%.
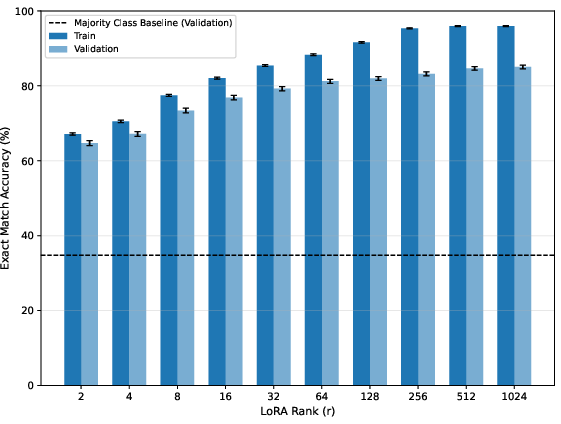
Figure 7: Exact match accuracy vs. LoRA rank on CholecT50; here, unlike SDSC-EEA, monotonic improvements are possible, pointing to the role of more uniform label distributions and fewer classes.
Notably, fine-tuning continues to confer large advantages over closed-source API models, indicating that strong Med-AGI transfer does not (yet) hold even for leading proprietary SOTA when labels and task distribution are complex and specialized.
Strong Empirical Claims
Key findings are supported by strong quantitative results:
- Zero-shot VLMs, regardless of scale, do not generalize to surgical tool detection tasks.
- Fine-tuned VLMs improve in-domain performance, yet suffer substantial OOD generalization failure under realistic (procedure-based) validation.
- Increased parameter scaling—up to three orders of magnitude—fails to close the train–validation gap.
- A small, specialized CV model outperforms VLMs by 3–18 points (SDSC-EEA, CholecT50), with orders-of-magnitude fewer parameters and lower inference/training cost.
- These patterns generalize across datasets and persist even when comparing to closed, commercial frontier models.
Implications for Med-AGI and AI System Design
The results constitute a clear empirical challenge to Med-AGI scaling optimism: surgical perception is not "solved" or reliably improvable by simply increasing parameter count or compute. The primary limitations are label/data fragmentation, domain heterogeneity, and distribution shift, not model class. This underscores that medical AI will likely require hierarchical or composite system architectures, where generalist VLMs orchestrate or delegate to specialized perception modules. Additionally, aggregation of large, curated, and institutionally diverse datasets is paramount.
The study further suggests that the "emergent abilities" paradigm, which holds in other language and vision tasks, does not translate to high-stakes medical perception without intentional label structure, domain coverage, and procedures addressing real-world class imbalance and complexity.
Practical and Theoretical Perspectives
Practically, deployments of surgical AI and med-tech solutions must integrate model selection with operational data-aggregation, annotation frameworks, and community-driven dataset standards. The study's results support the position that breakthroughs in Med-AGI for complex perception tasks are more likely to result from advances in distributed data sharing, consensus ontologies, and modular neuro-symbolic architectures than from further parameter scaling alone.
Theoretically, this analysis motivates new research in robust adaptation, compositional hybrid architectures, and transfer learning explicitly designed to handle the pathology of severe class imbalance, label noise, and realistic OOD shifts common in surgical video.
Conclusion
This comprehensive study provides clear evidence that current large multi-modal foundation models, even at significant scale and after task-specific adaptation, are insufficient for reliable fine-grained surgical perception. Future milestones in Surgical AI and, more broadly, Med-AGI will require advances in data curation and new hierarchical/hybrid architectures, rather than exclusive focus on larger, more generalist models. Community-driven aggregation of richly labeled surgical data and consensus-building around task ontologies are critical bottlenecks for the field’s advancement.
References:
- "A Comparative Study in Surgical AI: Datasets, Foundation Models, and Barriers to Med-AGI" (2603.27341)
- See also (Kaplan et al., 2020, Wei et al., 2022, Saab et al., 2024, Team et al., 25 Mar 2025) for context on scaling laws, emergent abilities, medical foundation models, and the Gemma 3 technical specifications.