Views on AI Existential Risk Before and After a Public Event at Harvard University
Abstract: We report the results of identical pre- and post-event surveys given to attendees of a talk, two-sided conversation, and Q&A centered around the book If Anyone Builds It, Everyone Dies at Harvard University in March 2026, covering perceived probability of AI-caused extinction or severe disempowerment resulting from unimpeded AI development, confidence in those estimates, and global priority. Among the 89 matched participants, the post-event median estimate of the probability of existential risk from advanced AI was 70%, and 96% agreed that mitigating AI existential risk should be a global priority. Although these self-selected respondents' pre-event views were already high (50% and 93%, respectively) relative to results of similar surveys that were previously administered to experts and the general public, the event produced increases on all measures when considering the respondents in aggregate. The magnitudes of increases in risk probability were negatively correlated with prior familiarity with the topic: among attendees with little prior familiarity, 60% shifted upward and none shifted downward, whereas among self-described experts, no respondents shifted upward and 20% shifted downward. Self-reported confidence also increased significantly, and confidence shifts were positively correlated with probability shifts. These findings indicate that a structured public engagement event can meaningfully shift risk perceptions, particularly among newcomers to the topic.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at how people’s opinions about “AI existential risk” change after they attend a public talk. “AI existential risk” means the chance that future, very advanced AI could wipe out humanity or take away our ability to control our own future. The authors ran a before-and-after survey at a Harvard event to see if hearing a two-sided, structured conversation would shift people’s beliefs, how sure they felt about those beliefs, and whether they thought reducing this risk should be a global priority.
What questions did the researchers want to answer?
The researchers focused on a few simple questions:
- How likely do people think it is that advanced AI could cause human extinction or permanent loss of control if AI development continues without big slow-downs?
- How confident (sure) are they about that estimate?
- Do they think reducing this risk should be a top global priority, like fighting pandemics or preventing nuclear war?
- Do these views change after a talk and discussion?
- Do people with different levels of prior knowledge about AI risks change their views differently?
How did they study it?
They held a public event at Harvard that included:
- A 13-minute talk explaining arguments that super-advanced AI could be dangerous.
- A 35-minute moderated, two-sided conversation that included counterarguments and common questions, like whether today’s LLMs might be easier to align with human values because they’re trained on human text.
- A 13-minute audience Q&A.
Before the event started, attendees answered a short anonymous survey on their phones (via QR code). Right after the event, they took the same survey again, plus one extra question about how much they already knew about AI risk.
What the survey asked:
- Probability of risk: People chose one of seven “bins” or buckets (like under 5%, 5–20%, up to above 95%) rather than typing a precise number. Think of this as choosing a range instead of guessing a specific percentage.
- Confidence: How sure they felt, on a 1–5 scale.
- Global priority: Whether they agreed that reducing AI extinction risk should be a worldwide priority.
- Role/affiliation (student, faculty, working outside academia, etc.).
- Prior exposure (after the event only): How much they’d heard about AI existential risk before.
They matched 89 people who took both the before and after surveys and compared each person’s answers. They used standard before-and-after statistics to check if the changes were likely real rather than random noise, and they looked at whether people with more or less prior knowledge shifted differently.
What did they find?
Big picture:
- People already started fairly worried, and they became a bit more worried on average after the event.
- They also became more confident in their opinions.
- Most people already thought AI risk should be a global priority, and agreement went up slightly.
Key results in plain terms:
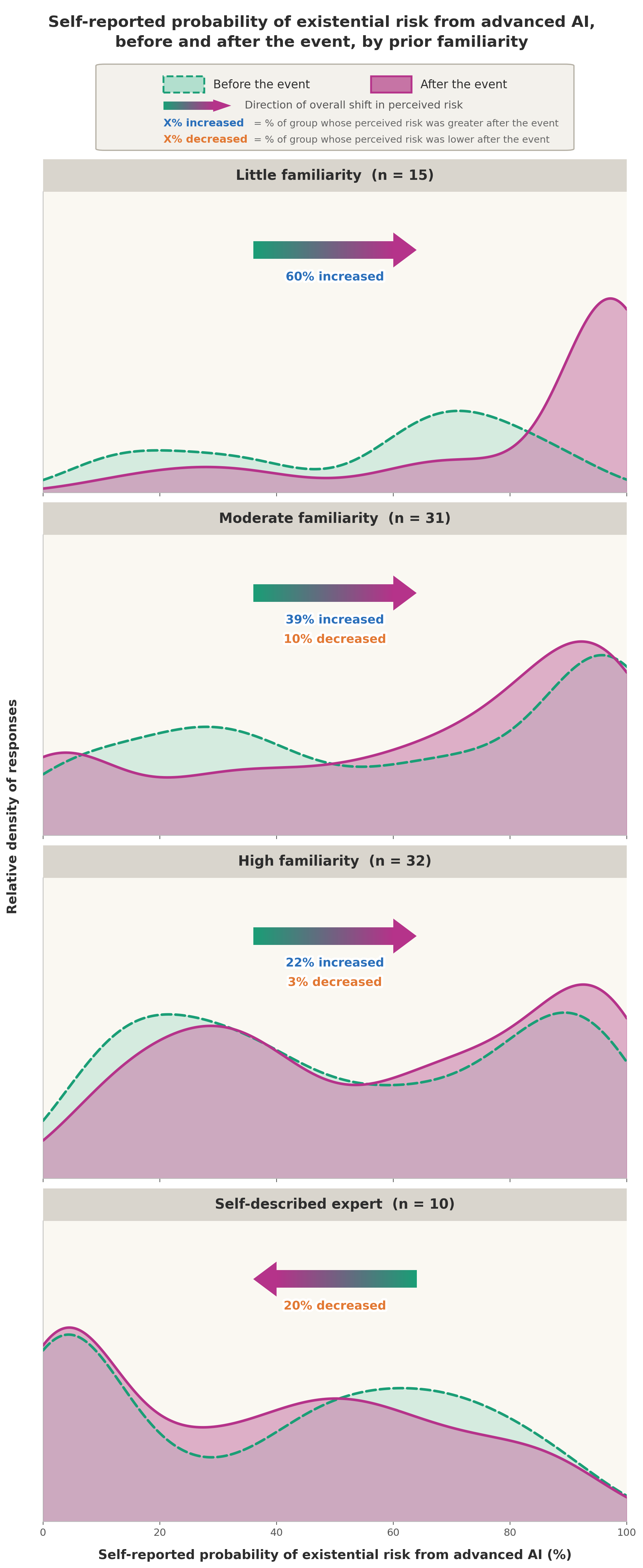
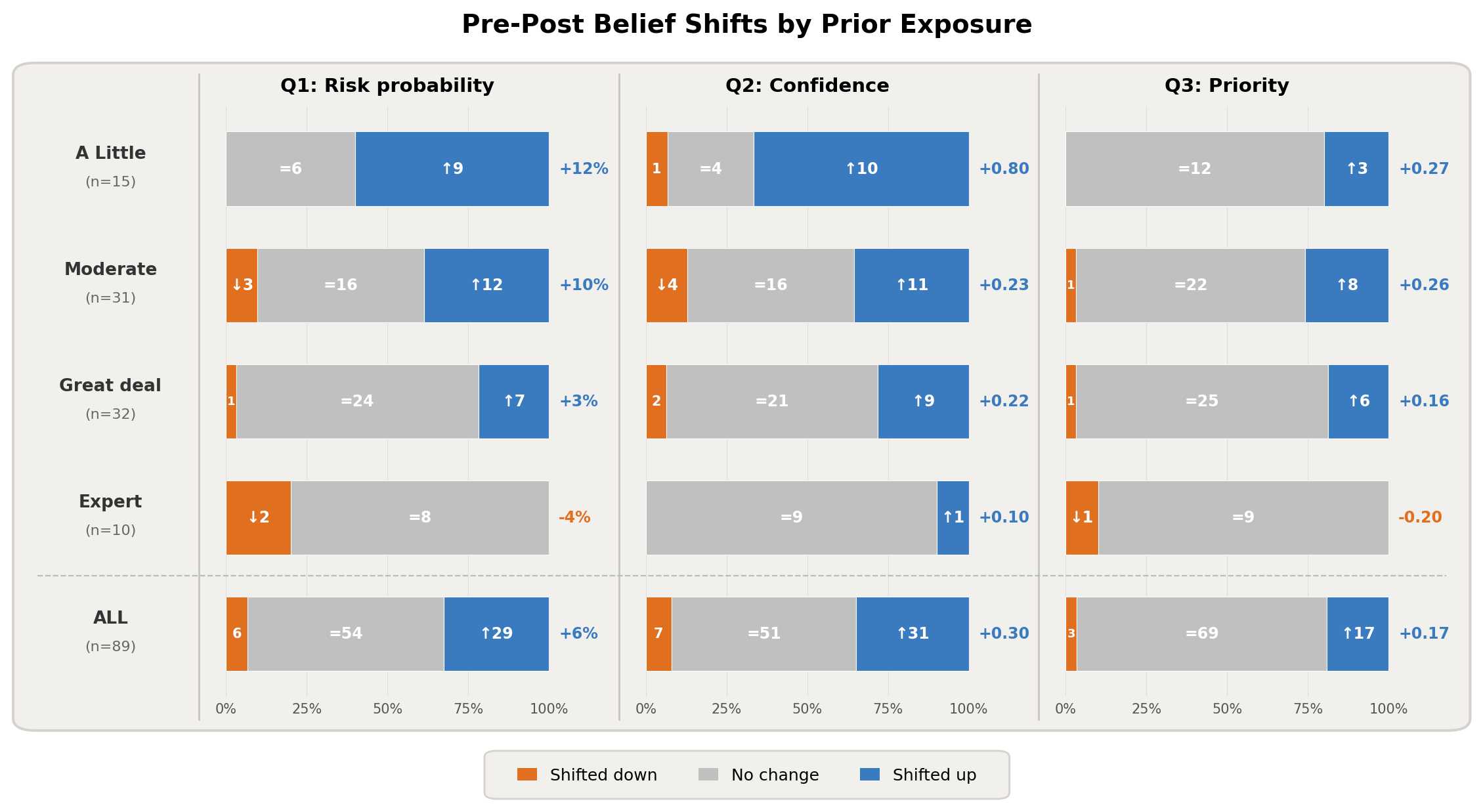
- Risk estimate went up: The middle (median) answer rose from “about 50% chance” to “about 70% chance” that unimpeded advanced AI could cause human extinction or a similar permanent loss of control. More people put the risk at 40% or higher after the event than before.
- Confidence rose: People felt more sure about their answers after the event. Many who changed their probability also felt more confident, suggesting they weren’t just confused—they felt they’d learned something.
- Priority rose: Agreement that reducing AI extinction risk should be a global priority increased from 93% to 96%, with more people “strongly agreeing.”
- Newcomers shifted the most: People who hadn’t heard much about AI risk before were the most likely to raise their risk estimates (60% moved up; none moved down). People who said they were “experts” didn’t move up, and a few moved down slightly. This suggests the event most strongly influenced newcomers, while experts sometimes became a bit less worried.
- Across backgrounds: There wasn’t a clear difference between people inside academia (students, faculty) and those outside it.
Comparisons to other surveys:
- An earlier 2023 survey of many AI researchers found much lower average risk estimates (median 5%). The Harvard audience started much higher (median 50% before the event). This likely reflects who chose to attend, the wording of the question (it asked people to assume AI development isn’t slowed), and the fact that AI has advanced a lot in the last few years.
- A 2023 national poll found about 70% agreed AI extinction risk should be a global priority. In this Harvard audience, it was 93% before and 96% after. Again, different groups at different times can give different results.
Why this matters
This study suggests that a single, carefully designed public event—one that includes both arguments and counterarguments—can meaningfully change how people think about AI risks, especially people who are new to the topic. It also shows that after such an event, people don’t just change their minds—they often feel more certain about why they think what they think.
However, there are limits:
- The audience chose to attend a talk about AI risks, so they may not represent the general public.
- Only about half the room completed both surveys.
- The “expert” group was small, so we should be cautious about conclusions there.
- The survey used broad bins instead of exact numbers, and people reported their own familiarity levels.
Even with these caveats, the results point to a simple takeaway: thoughtful, balanced public conversations about AI can shift opinions and increase understanding. As AI continues to advance, events like this could help communities and leaders decide how much attention and effort to put into making AI safe.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the study.
- No control/comparison group to isolate event effects from test–retest effects, demand characteristics, or secular trends; future work should randomize participants to alternative content (e.g., neutral talk, counter-argument talk, reading-only, no event).
- No longitudinal follow-up to assess durability of attitude and confidence changes; replicate with follow-ups at 1 week, 1–3 months, and 6–12 months.
- Self-selection and nonresponse biases are unquantified; compare characteristics and baseline views of matched vs. unmatched respondents and attendees vs. non-attendees, or recruit from a randomized sampling frame.
- Single-site, single-speaker design limits external validity; test across multiple universities, community venues, countries, and with diverse speakers (pro–con panels, domain experts with different affiliations).
- Event-component attribution is unknown; experimentally vary talk, moderated discussion, and Q&A segments to identify which elements drive belief change.
- Social desirability and demand characteristics not directly measured; include social desirability scales, list experiments, or indirect questioning to assess pressure to report higher risk.
- Measurement granularity constrained by seven bins; use continuous probability sliders or unfolding brackets to detect smaller shifts and quantify within-bin movement.
- Potential ceiling effects on the “global priority” item (very high pre-event agreement) obscure additional change; use more discriminating items and alternative framings.
- Prior familiarity is self-assessed and unvalidated; add objective knowledge tests, exposure inventories, or behavioral proxies to calibrate “familiarity.”
- “Expert” classification is unverified (n=10); validate expertise via credentials, publications, or technical skill assessments and increase sample for adequate power.
- Immediate post-event measurement may capture transient persuasion; assess whether shifts persist, attenuate, or backfire over time, especially among self-described experts.
- Mechanisms of change are unspecified; collect and code open-ended rationales, measure argument acceptance, perceived credibility, and affect to disentangle information vs. persuasion vs. anxiety.
- No assessment of comprehension or calibration; pair confidence ratings with accuracy/knowledge checks to detect overconfidence or miscalibrated certainty.
- Unknown behavioral or policy implications; measure downstream outcomes (policy support, donation intentions, voting preferences, information-seeking) to link belief change to action.
- Framing effects untested; experimentally vary question wording (e.g., include/exclude the “unimpeded development” clause, specify time horizons, define “severe disempowerment”) to estimate framing sensitivity.
- Time horizon for “extinction or disempowerment” unspecified; test whether short-, medium-, or long-term horizons change probability estimates.
- Comparative benchmarks are outdated and non-equivalent; run contemporaneous surveys of AI researchers and the general public using identical wording and response formats to enable clean comparisons.
- The influence of the speaker’s affiliation (MIRI) and the book’s framing is not isolated; compare effects across speakers with differing institutional ties and rhetorical styles.
- Heterogeneity beyond familiarity is unexplored; collect and analyze demographics (age, gender, ideology, country, occupation), AI usage, and media diet to model moderators of change.
- Attrition bias in the matched sample is not examined; compare pre-event responses of those who did vs. did not complete post-event surveys.
- Potential anchoring from pre-survey to post-survey is unmanaged; randomize item order, use Solomon four-group designs, or only post-test some arms.
- Kernel density plots of ordinal, binned data may mislead; adopt ordinal mixed-effects models and report distributional changes without smoothing artifacts.
- Multiple testing and subgroup analyses lack correction or preregistration; preregister hypotheses and adjust for multiple comparisons.
- Likelihood ratio approach is nonstandard and minimally justified; report effect sizes with confidence intervals, Bayes factors from explicit models, or full Bayesian ordinal models.
- “No difference between academia vs. non-academia” analysis is underpowered and coarse; refine role categories and ensure sufficient cell sizes for interaction tests.
- No content analysis of the talk/discussion; code the transcript for claims, uncertainty, and counterarguments to link specific content to shifts.
- Absence of sensitivity checks for bin–midpoint coding assumptions; rerun analyses with alternative codings, ordinal models, and nonparametric approaches.
- No assessment of emotional responses (e.g., anxiety, hope, fatalism) that might mediate changes; include affect scales and test mediation.
- Unclear whether participants attended the full event; track attendance duration and attention to assess dose–response.
- Generalizability to online formats is unknown; compare in-person vs. livestream/recording vs. text-only interventions.
- No test of backfire or reactance beyond experts; predefine criteria for backfire and examine in subgroups exposed to strong counterarguments.
- Dataset and code availability not indicated; share anonymized data and analysis code for replication and reanalysis.
- Power analysis absent; plan sample sizes a priori to detect plausible effect sizes within subgroups (especially experts and “nothing at all” exposure).
- The study does not evaluate how updated beliefs relate to objective evidence or expert consensus; include calibration exercises against expert forecasts or probabilistic scenarios.
- Reliability of scales across pre/post is not established; assess test–retest reliability and measurement invariance across exposure groups.
Practical Applications
Immediate Applications
Below are deployable, concrete uses of the paper’s findings and methods across sectors, with key assumptions/dependencies noted.
- Evidence-based public engagement playbook for AI risk (public policy, education, NGOs)
- What: Run two-sided talks + moderated Q&A with identical pre/post surveys to shift and measure risk perceptions, prioritizing newcomers.
- Why: Newcomers showed 60% upward shifts (none downward); confidence rose; prioritization increased.
- Tools/workflow: Slide templates, facilitator guide for “two-sided” dialogue, QR-code survey kit, analysis script (Wilcoxon, Spearman, likelihood ratios).
- Dependencies: Audience recruitment; anonymity assurance; trained moderator; venue/AV; cultural/context fit.
- Audience segmentation by prior familiarity (communications across sectors)
- What: Screen for “nothing/a little/moderate/great deal/expert” familiarity and tailor content accordingly.
- Why: Shift magnitude decreased monotonically with prior exposure; experts showed some downward shifts.
- Tools/workflow: Brief intake poll; branching content; separate expert breakouts.
- Dependencies: Honest self-reporting; ability to run parallel tracks.
- Pre/post measurement workflow for outreach effectiveness (academia, government, industry)
- What: Standardize identical pre/post items on risk probability (binned), confidence, and global-priority agreement.
- Why: Demonstrated statistically significant shifts and clear analytics (LRs provide intuitive evidential strength).
- Tools/workflow: Survey module (e.g., Slido, Mentimeter) with bin midpoints; auto-report with LRs and nonparametric tests.
- Dependencies: Sufficient matched responses; data governance for anonymous matching.
- Corporate AI governance training with shift tracking (software/AI, finance, healthcare)
- What: Integrate the event format into annual responsible-AI training; monitor risk perception and confidence shifts among staff.
- Why: Builds risk-aware culture; identifies departments needing deeper alignment/safety education.
- Tools/workflow: Internal LMS module; QR-linked surveys; dashboard of shifts by team.
- Dependencies: Executive buy-in; psychological safety; compliance alignment.
- Policy town halls on AI safety with quantitative feedback (public policy)
- What: Run community forums using the paper’s format to gauge support for interventions (e.g., evaluation requirements, compute limits).
- Why: Post-event priority agreement was 96%; useful for democratic legitimacy and policy design.
- Tools/workflow: Town hall kit; CAIS-statement item; report summarizing shifts and LRs for policymakers.
- Dependencies: Nonpartisan facilitation; representative attendance; clear framing of “unimpeded development” assumption.
- University and K–12 curriculum modules on AI risk literacy (education)
- What: Plug-and-play lecture + two-sided discussion with pre/post assessment on risk and confidence.
- Why: Increases student clarity and engagement; provides instructors with measurable learning outcomes.
- Tools/workflow: Open syllabus unit; calibrated question bank; grading rubric for reflection on confidence shifts.
- Dependencies: Instructor readiness; IRB/ethics guidance if collecting data for research.
- Media and science-communication segments with embedded polling (media, journalism)
- What: Publish explainers paired with pre/post micro-polls to measure belief updates in readers/viewers.
- Why: Demonstrates transparency and impact of journalism on public understanding.
- Tools/workflow: Article-embedded polls; shift visualization; likelihood-ratio badge indicating evidential strength.
- Dependencies: Reader consent; platform integration; guardrails against manipulation.
- NGO program evaluation for AI-risk outreach (nonprofits, philanthropy)
- What: Use the measurement protocol to assess which formats/materials drive the largest shifts in target populations.
- Why: Optimizes allocation of outreach funds toward high-ROI interventions (newcomer-focused).
- Tools/workflow: A/B testing across materials; segmentation by familiarity; standardized KPI dashboard.
- Dependencies: Adequate sample sizes; ethical persuasion standards.
- Product safety and alignment briefings for engineers (software/AI, robotics)
- What: Two-sided internal seminars before high-risk feature releases; track whether engineers’ risk estimates/confidence change.
- Why: Informs go/no-go criteria and alignment work prioritization; flags expert backfire risks.
- Tools/workflow: Pre-release briefing pack; risk-probability card; internal survey analytics.
- Dependencies: Time in development cycles; trust in facilitators; integration with safety case documentation.
- Hospital adoption committees for clinical AI tools (healthcare)
- What: Briefings for clinicians/admins with pre/post measures on perceived risk and confidence specific to AI CDS/triage tools.
- Why: Surfaces trust and risk concerns; informs training and guardrail design prior to deployment.
- Tools/workflow: Department-level sessions; tailored risk items (patient safety focus); outcome-linked follow-ups.
- Dependencies: Clinical leadership support; alignment with regulatory/IRB norms.
- Risk-culture pulse checks in regulated sectors (finance, critical infrastructure)
- What: Periodic organization-wide assessments of AI-risk beliefs/confidence to inform model-risk management.
- Why: Supports SR 11-7–style governance in finance and analogous frameworks elsewhere.
- Tools/workflow: Quarterly pulse surveys; trend analysis; escalation triggers for training.
- Dependencies: Confidentiality; regulatory compatibility; analytic capacity.
- Open-source “Risk Perception Shift Dashboard” (cross-sector)
- What: Lightweight toolkit to ingest pre/post data, compute nonparametric tests, and display shifts by segment.
- Why: Lowers barrier to evidence-based engagement at institutions without data teams.
- Tools/workflow: Python/R package; templated report; API for common polling platforms.
- Dependencies: Minimal IT support; consistent survey IDs for matching.
- Confidence-as-an-outcome tracking in training (HR, compliance)
- What: Add confidence measures to existing ethics/safety courses to detect hollow agreement vs. genuine understanding.
- Why: Paper shows confidence increases track with belief updates; prevents false positives.
- Tools/workflow: Confidence items alongside knowledge checks; remediation paths for low-confidence learners.
- Dependencies: LMS modifications; psychometric validation over time.
- Expert-focused “steelman clinics” (academia, industry)
- What: For expert audiences, emphasize unresolved debates and empirical counterevidence to avoid backfire.
- Why: Experts showed no upward shifts and some downward shifts; content should be calibrated differently.
- Tools/workflow: Debate-style sessions; reading packets with competing views; expert panel Q&A.
- Dependencies: Availability of qualified discussants; clear goals (clarity vs. persuasion).
- Ethics and consent template for low-risk public polls (academia, public engagement)
- What: Reuse the paper’s anonymous, voluntary format to minimize IRB burden when evaluating talks.
- Why: Enables rapid, compliant evaluation of engagement events.
- Tools/workflow: Consent language, PII-free design, data-retention policy template.
- Dependencies: Institutional policies; jurisdictional differences.
Long-Term Applications
These applications require further research, scaling, or development before widespread deployment.
- National/regional randomized controlled trials on AI-risk communication (public policy, academia)
- What: RCTs comparing formats, framings, and speakers across diverse populations with long-term follow-up.
- Why: Establishes causal efficacy, durability of shifts, and behavioral impacts (e.g., voting, support for regulation).
- Dependencies: Funding; representative sampling; ethics review; preregistration infrastructure.
- Longitudinal “AI Risk Literacy” index and standards (regulators, insurers, industry)
- What: Standardized measures of risk probability, confidence, and prioritization tracked over time and across sectors.
- Why: Informs policy readiness, insurance underwriting, and organizational risk culture benchmarks.
- Dependencies: Consensus on metrics; data-sharing agreements; governance to prevent misuse.
- Adaptive, personalized risk-literacy tutors (education, corporate L&D)
- What: AI-driven modules that tailor content by prior familiarity and dynamically adjust based on belief/confidence updates.
- Why: Maximizes learning gains and minimizes backfire in expert subgroups.
- Dependencies: Content libraries; privacy-preserving learner models; validation studies.
- Civic deliberation platforms with built-in pre/post analytics (e-government, NGOs)
- What: Scalable digital forums that host two-sided materials, support small-group discussion, and automatically measure shifts.
- Why: Enables inclusive, data-informed public consultation for AI policy.
- Dependencies: Secure identity systems; accessibility; moderation; interoperability with public records.
- Integration with product “safety case” frameworks (software/AI, robotics, healthcare)
- What: Require evidence of informed stakeholder understanding (measured shifts) as part of release gates for high-risk AI systems.
- Why: Strengthens socio-technical safety cases beyond technical evals.
- Dependencies: Industry standards; regulator acceptance; process automation.
- Cross-risk transfer to other existential/societal risks (biosecurity, nuclear, climate geoengineering)
- What: Adapt the method to communicate and measure belief updates about other high-stakes technologies.
- Why: Generalizable approach for risk governance and public trust.
- Dependencies: Domain-specific content; sector partners; careful framing to avoid alarmism.
- Ethics frameworks for persuasive risk communication (academia, policy)
- What: Develop guidelines and oversight to balance informing vs. unduly influencing public beliefs.
- Why: Mitigates concerns about social desirability bias and fairness.
- Dependencies: Interdisciplinary consensus; oversight bodies; public input.
- Culturally localized content libraries and moderators (global NGOs, multinationals)
- What: Translate and adapt two-sided materials to cultural contexts; train local moderators.
- Why: Improves generalizability and legitimacy outside elite institutions.
- Dependencies: Partnerships with local orgs; co-creation; evaluation in-situ.
- Behavioral outcome linkage (academia, industry, policy)
- What: Move beyond beliefs/confidence to test effects on concrete behaviors (e.g., secure model usage, incident reporting).
- Why: Determines whether attitude shifts translate to safer practices.
- Dependencies: Access to behavior data; privacy protections; experimental designs.
- Advanced analytics package with causal modeling and interpretability (data science)
- What: Tooling that supports mediation analysis (e.g., confidence as mediator), heterogeneous treatment effects by subgroup.
- Why: Guides precision communication strategies.
- Dependencies: Larger datasets; statistical expertise; open methods.
- Public sentiment early-warning system for AI releases (regulators, labs)
- What: Continuous monitoring of risk perceptions around major AI model launches, feeding into staged release decisions.
- Why: Aligns release policies with societal readiness and concerns.
- Dependencies: Collaboration with labs; rapid polling infrastructure; thresholds for action.
- Professional certification in AI risk communication (education, industry associations)
- What: Credential for moderators/educators trained in two-sided risk engagement and measurement.
- Why: Ensures quality and consistency at scale.
- Dependencies: Accrediting bodies; curriculum; assessment standards.
- Privacy-preserving matching for pre/post surveys (tech, research)
- What: Cryptographic or federated methods to match responses over time without PII leakage.
- Why: Enables rigorous longitudinal measurement while protecting participants.
- Dependencies: Technical development; usability; auditability.
- Expert-track engagement redesign (academia, industry)
- What: Develop formats that engage experts without increasing polarization (e.g., collaborative forecasting workshops).
- Why: Paper suggests different dynamics for experts vs. newcomers.
- Dependencies: Access to domain experts; facilitation capacity; evaluation.
Assumptions and dependencies common across many applications:
- Representativeness: The paper’s audience was self-selected and highly concerned; broader populations may respond differently.
- Social desirability and context effects: Even anonymous settings can influence responses; careful design needed.
- Timeliness: Rapid AI capability shifts may change baseline perceptions; materials require frequent updates.
- Ethical oversight: As interventions become more persuasive and scaled, IRB/ethics governance becomes essential.
Glossary
- AI alignment: The field concerned with ensuring advanced AI systems pursue goals that are compatible with human values and intentions. "AI architectures and AI alignment research."
- AI existential risk: The possibility that advanced AI could cause human extinction or permanent, severe loss of human control and autonomy. "Agreement that AI existential risk should be a global priority was high before the event and increased further"
- Autonomous agents: AI systems that act independently in the world, perceiving and acting to achieve goals without continuous human oversight. "as AI systems increasingly operate autonomously as agents in the world,"
- Bin midpoints: Representative numerical values assigned to categorical bins, typically the midpoint of each interval, used for analysis or visualization. "responses were coded to bin midpoints (2.5\%, 12.5\%, 30\%, 50\%, 70\%, 87.5\%, 97.5\%)."
- Binned responses: A survey design technique where continuous values are grouped into discrete intervals to simplify respondent choices. "we used binned responses for ease of completion by a general audience."
- Descriptive statistics: Numerical summaries (e.g., means, medians, proportions) that describe and summarize features of a dataset. "We report descriptive statistics stratified by prior exposure level (Q5)."
- Generalizability: The extent to which findings from a study apply to other settings, populations, or times. "Generalizability to other formats, speakers, or audiences is unknown."
- Human subjects research: Research that involves living individuals from whom data are obtained through intervention or interaction, or identifiable private information. "Given the anonymous, voluntary nature of the survey and the absence of personally identifiable information, this study is not deemed human subjects research."
- Kernel density estimates: A nonparametric method to estimate the probability density function of a random variable, smoothing observed data into a continuous curve. "Each panel shows kernel density estimates of pre-event (teal, dashed outline) and post-event (purple/pink, solid) distributions for one familiarity group."
- Likelihood ratio (LR): A measure comparing how well two hypotheses explain the observed data, often the best-fit hypothesis versus a null. "In addition to -values, we report likelihood ratios (LRs) comparing the best-fit hypothesis to the null."
- Likert scale: A psychometric scale commonly used in questionnaires to measure attitudes or opinions across ordered response options. "The answer choices were a five-point Likert scale from
Strongly disagree'' toStrongly agree.''" - Matched sample: A set of participants measured at multiple time points (or matched across groups), allowing within-subject comparisons. "The demographic and exposure composition of the matched sample () is shown in Table~\ref{tab:demographics}."
- Monotonic relationship: A relationship that consistently increases or decreases but does not change direction. "The monotonic relationship between prior exposure and probability shift was confirmed by Spearman correlation (, , LR )."
- Nonresponse bias: Systematic error introduced when individuals who do not respond differ meaningfully from those who do. "Of the approximately 180 attendees, only a subset completed the surveys, introducing a potential nonresponse bias."
- Null model: A baseline hypothesis or model representing no effect or no relationship, used as a comparator in statistical tests. "For shift analyses, the LR compares a model where the probability of upward shift equals the observed proportion to the null model where upward and downward shifts are equally likely."
- One-sided test: A statistical test that evaluates evidence for an effect in a single specified direction. "Wilcoxon signed-rank tests (one-sided) and likelihood ratios (LR) are reported for each group, testing for upward shift except in the Expert row which tests for downward shift."
- Self-selection bias: Bias arising when participants select themselves into a study or condition, potentially making the sample unrepresentative. "There is likely self-selection bias in our sample given that attendees chose to attend an event with a provocative title about AI existential risk."
- Spearman rank correlation (ρ): A nonparametric measure of the strength and direction of a monotonic association between two ranked variables. "To assess the relationship between prior exposure and the magnitude of shifts, we used Spearman rank correlations."
- Stratified analysis: Analysis that divides data into subgroups (strata) based on characteristics to compare patterns within or across those groups. "We report descriptive statistics stratified by prior exposure level (Q5)."
- Wilcoxon signed-rank test: A nonparametric test for comparing paired samples to assess whether their population mean ranks differ. "To test for overall shifts, we used Wilcoxon signed-rank tests."
Collections
Sign up for free to add this paper to one or more collections.

