- The paper introduces an automated method that leverages manifold and metric learning for geometry-aware prototype discovery in reinforcement learning.
- The method decouples prototype selection from policy training and integrates with Prototype-Wrapper Networks to maintain performance.
- Empirical evaluations and user studies demonstrate the approach’s scalability and enhanced interpretability across diverse RL tasks.
Principal Prototype Analysis on Manifold for Interpretable Reinforcement Learning
Introduction
As deep reinforcement learning (RL) systems reach unprecedented performance in domains such as games, robotics, and LLM fine-tuning, the interpretability of their underlying decision processes remains a bottleneck for real-world deployment. Interpretability in RL is challenged by opaque neural policies and the lack of effective, scalable methods for generating faithful and actionable explanations. Existing prototype-based methods for interpretability, notably Prototype-Wrapper Networks (PW-Nets), have shown initial promise but rely on manually curated prototypes that are domain- and instance-specific, limiting scalability and cross-task generalization.
This paper introduces an automated method for prototype discovery—Principal Prototype Analysis on Manifold—that leverages both metric and manifold learning principles to select geometry-aware, data-driven prototypes from trajectories of a pre-trained black-box RL agent. The approach achieves competitive performance with the original RL architectures and surpasses reliance on human-annotated exemplars, opening the door for scalable, reproducible interpretable RL.
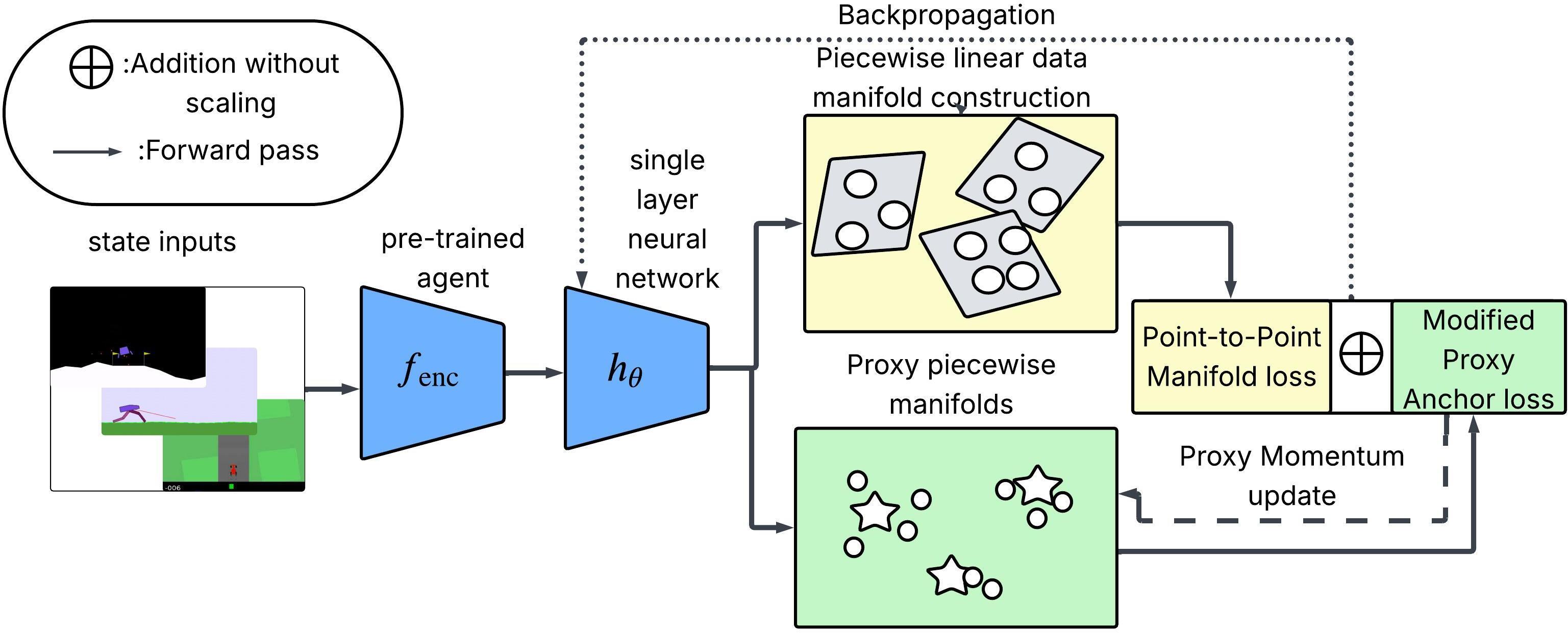
Figure 1: Overview of the proposed method using manifold and metric learning to select geometry-aware prototypes for RL interpretability.
Automated and Geometry-aware Prototype Discovery
Traditional prototype selection in interpretability frameworks is often anchored on statistics such as class means or medoids in the embedding space, which inadequately capture the problem’s underlying manifold structure and can be semantically uninformative or sensitive to outliers. The method presented here advances the field by decoupling prototype discovery from the main RL policy training and introducing a two-stage architecture:
- Stage 1: Manifold-guided prototype selection. A lightweight neural network hθ jointly optimizes a piecewise-linear manifold learning objective and a metric learning (Proxy Anchor loss) objective over encoded state-action pairs sampled from policy rollouts. Prototypes are initialized as learnable proxies and then mapped to real training instances to ensure semantic fidelity.
- Stage 2: Integration in PW-net. The automatically selected prototypes are fixed and incorporated into the Prototype-Wrapper Network, which is then trained for interpretable policy prediction with no performance loss relative to the original black-box model.
Unlike prior works, the selected prototypes are geometry-aware—inferred directly from the encoded representation manifold—and discriminative with respect to action-driven class separation.
Methodological Details
Manifold Decomposition and Metric Learning
The approach relies on the manifold hypothesis, decomposing high-dimensional RL representations into locally linear submanifolds using an iterative PCA anchor-and-neighborhood procedure. Each anchor region produces a local basis used to evaluate both geometric and projected distances between samples.
- Proxy Anchor loss is adapted for Euclidean metrics and encourages tight intra-class clustering and inter-class separation, using proxies as class-level representatives.
- Manifold Point-to-Point loss penalizes mismatch between Euclidean embedding distances and manifold-based similarities, directly preserving the local geometry of the data in the learned feature space.
This dual-objective training yields proxies that are mapped to their nearest real sample, maintaining both interpretability and faithfulness.
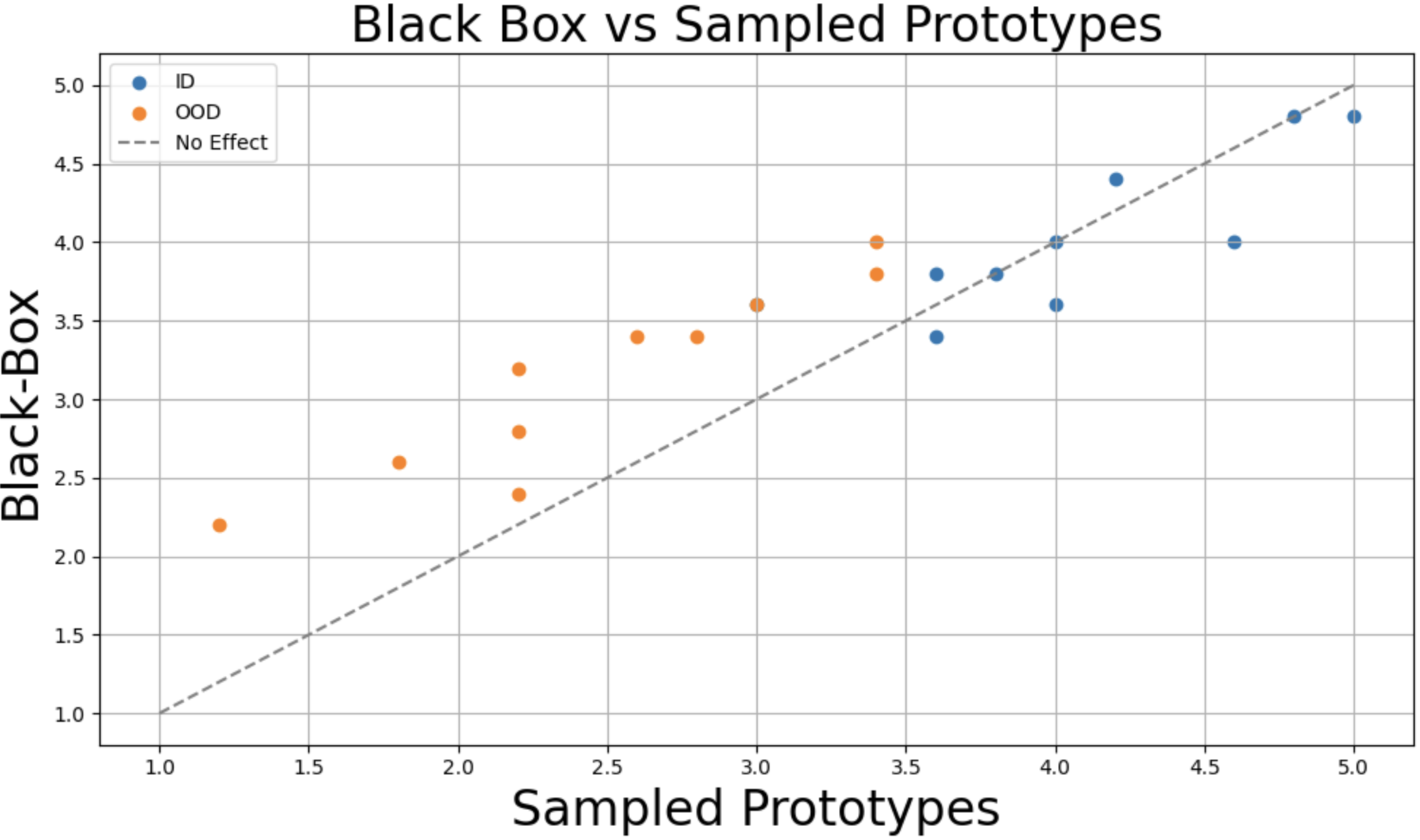
Figure 2: IID and OOD distribution plots highlight participant sensitivity to agent failures when provided with prototype-based explanations.
Empirical Evaluation
Comprehensive reinforcement learning benchmarks—across Car Racing, BipedalWalker, Humanoid Standup, Pong, Lunar Lander, and Acrobot—demonstrate that the proposed geometry-aware prototype discovery results in policy reward metrics that are consistent with, or marginally improve upon, both PW-Net (with human-selected prototypes) and the underlying black-box agents. Notably, the approach is robust in high-dimensional, continuous control tasks, where manual prototype selection is infeasible.
User Study and Interpretability
A controlled user study in the Car Racing environment measured participant ability to anticipate agent failures with and without prototype-based explanations. Prototypes discovered automatically by the proposed method showed comparable interpretability ratings to human-curated ones. Participants in the prototype condition exhibited heightened sensitivity to true agent failure cases, especially under distribution shift, substantiating the practical interpretability and utility of geometry-aware prototypes.
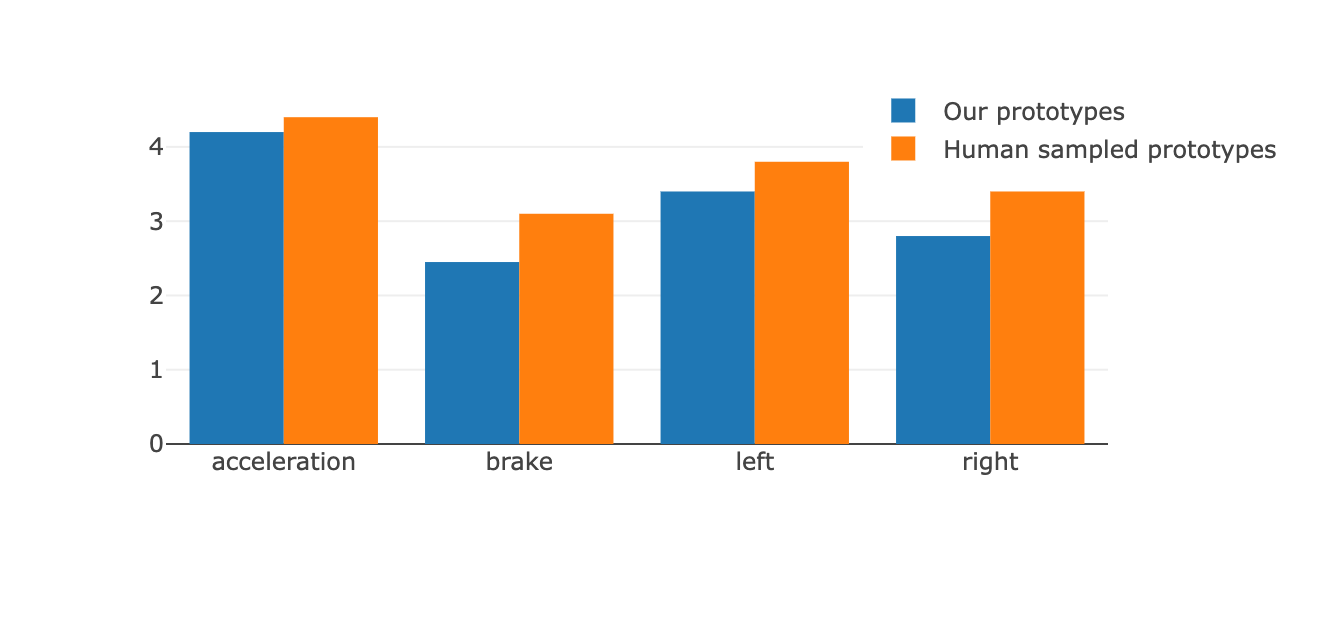
Figure 3: Comparison of visual similarity between prototypes—automated prototypes closely match the semantic content of human-selected exemplars.
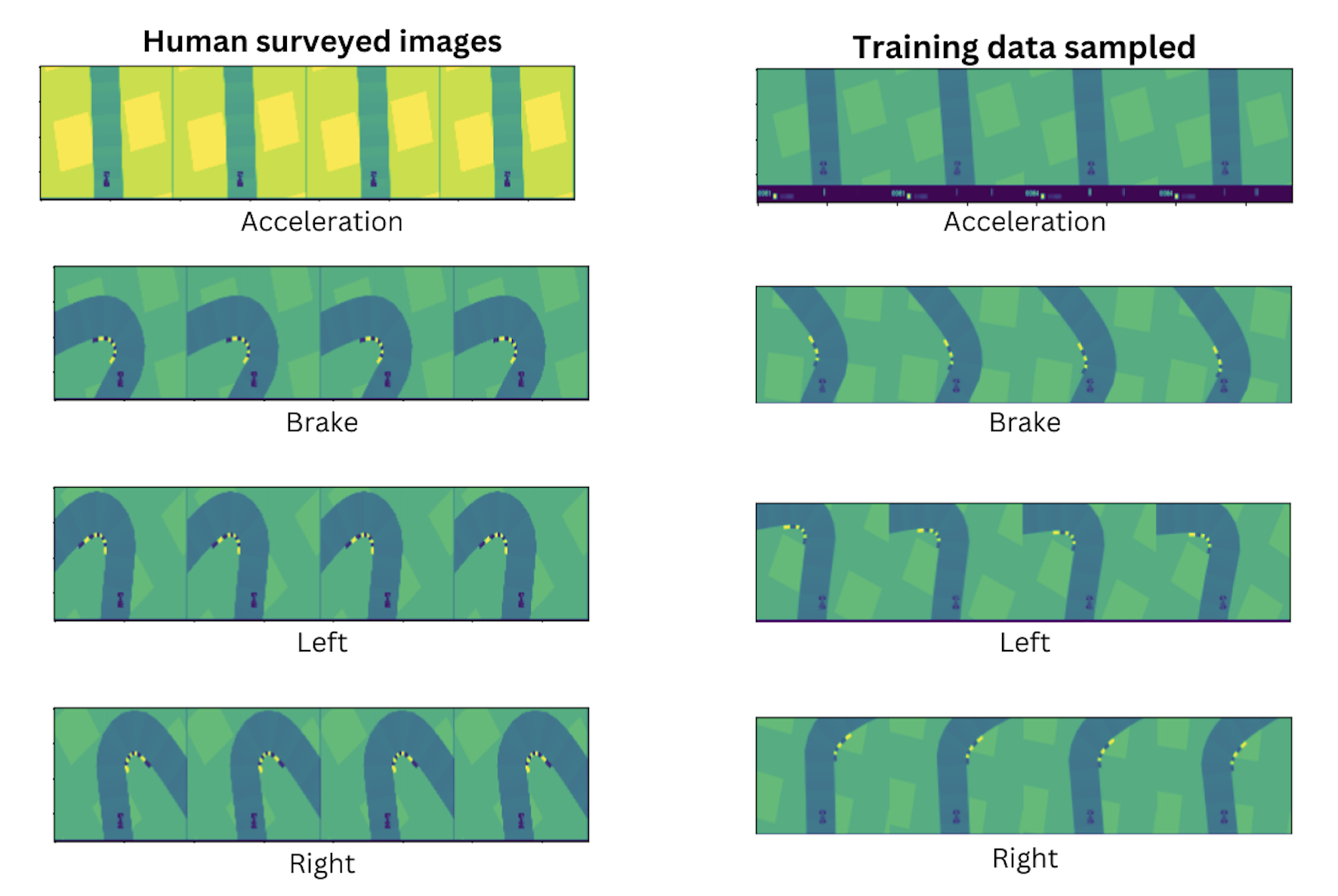
Figure 4: Visual comparison of human-annotated versus automatically discovered prototypes for key action classes.
Figure 5: User study design and key findings, including increased anticipation of agent failures when using prototype explanations.
Methodological and Hyperparameter Analysis
An extensive ablation study across both continuous (BipedalWalker) and pixel-based (Atari Pong) domains reveals the sensitivity of the model to critical hyperparameters such as manifold dimension m, momentum γ, similarity decay rates Nα/Nβ, and the number of prototypes per class. Optimal performance is observed for low-dimensional manifold approximations and careful tuning of margin and sharpness parameters in the metric learning objective. Increasing the prototype count supports performance improvements in symbolic (structured) state spaces, while for high-dimensional pixel-based inputs, excessive prototype allocation can induce noise and degrade performance.
Implications and Future Directions
This work addresses a critical gap in scalable, reproducible interpretable RL: removing the reliance on human-annotated prototypes and enabling geometry- and class-informed prototype selection. The method is applicable across both discrete and continuous action spaces and successfully generalizes to high-dimensional RL environments.
The formal decoupling of prototype discovery and policy optimization opens new avenues for research into, e.g., hierarchical prototype libraries for large-vocabulary LLMs, integration of geometry-aware prototype selection as a regularizer during RL policy training, and expansion to multi-task or transfer-learning paradigms. Practical extensions to real-world RL domains—autonomous driving, robotics—where model oversight and transparency are essential, represent a promising direction for impactful deployment.
Conclusion
Principal Prototype Analysis on Manifold provides an effective and scalable approach for interpretable reinforcement learning by automatically selecting geometry-aware, data-driven prototypes from pre-trained agent rollouts. The method consistently matches black-box RL performance while delivering actionable, human-interpretable explanations, validated through both numerical and human studies. Its flexibility and empirical robustness underscore its value in advancing trustworthy RL systems and its potential for further methodological extensions in interpretable AI research.