- The paper proposes a leaf-centric paradigm that mitigates routing polarization by evenly distributing traffic across spine switches.
- It employs an ILP formulation and matrix decomposition techniques to compute logical topologies in polynomial time for τ≥2.
- Simulation results demonstrate up to 19.27% improvement in job runtime and massive reductions in topology computation overhead.
Leaf-centric Logical Topology Design for OCS-based GPU Clusters
Motivation and Problem Definition
Optical circuit switches (OCS) are increasingly adopted in modern GPU clusters, driven by the demand for high-bandwidth, low-latency communication in large-scale ML training environments. OCS enable circuit-based interconnects that are dynamically reconfigurable, thereby supporting efficient ML workload distribution. A prevalent architectural pattern is a three-tier topology—leaf-spine-OCS—where servers attach to leaf packet switches (EPS), leaves aggregate via spine EPS within Pods, and inter-Pod connectivity is provisioned via OCS in the core.
A critical bottleneck unique to OCS-based topologies is routing polarization: uneven allocation of bandwidth across spine switches, causing traffic concentration on particular leaf-to-spine links and degrading throughput for ML coflows. Traditional Pod-centric logical topology design, which optimizes based on inter-Pod bandwidth requirements, fails to mitigate this issue. In response, the paper advocates a leaf-centric paradigm to distribute traffic originating from a single leaf across spine switches more evenly.
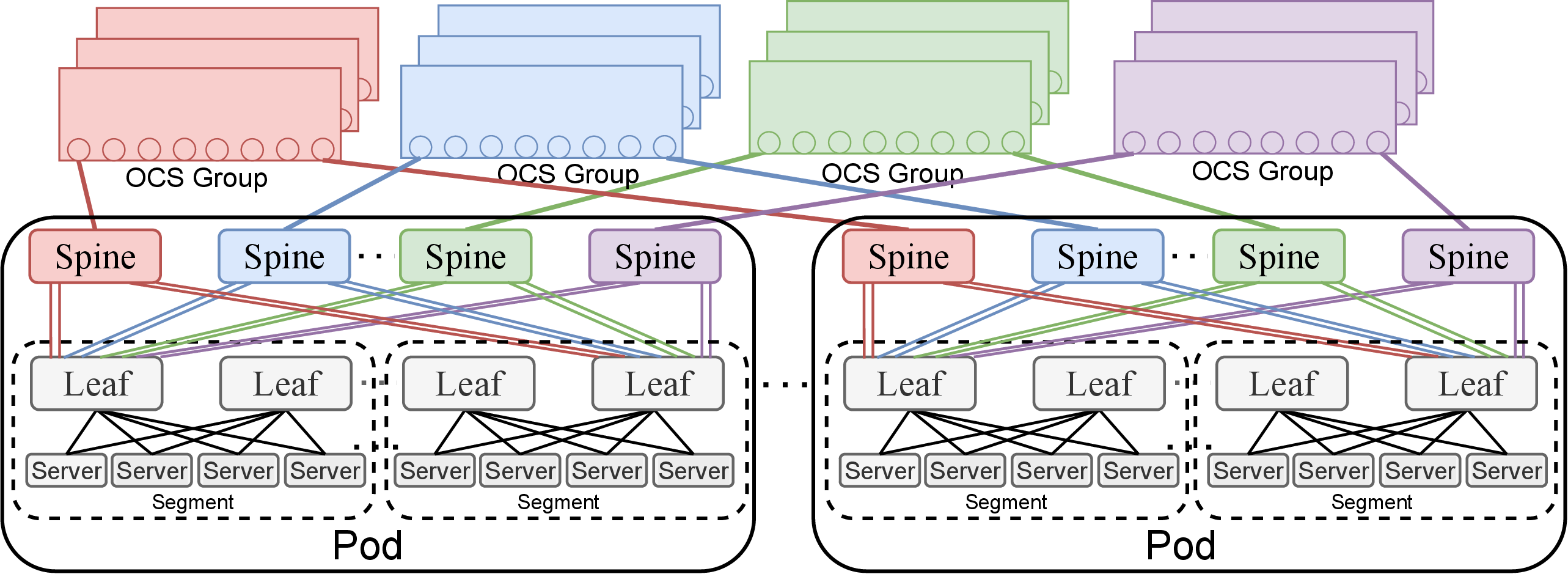
Figure 1: LumosCore architecture employing a three-tier topology with leaf, spine, and optical core layers.
The proposed LumosCore framework systematically addresses routing polarization by unifying logical topology design and intra-Pod physical topology configuration.
Key Concepts
- Physical Topology: Specifies intra-Pod connectivity between leaves and spines, and inter-Pod OCS connections.
- Leaf-level Network Requirement: Specifies the disjoint cross-Pod paths required between leaf pairs, derived from job-specific ML communication demands.
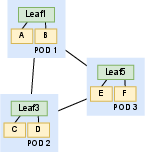
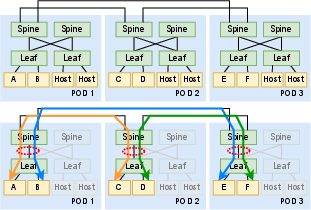
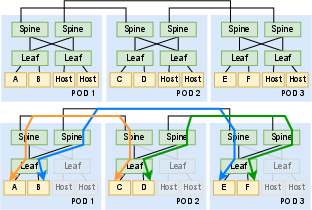
Figure 2: Example of Leaf-level Network Requirement—cross-Pod leaf pairs require disjoint bidirectional links.
- Logical Topology: Configured by the OCS layer, determining feasible inter-spine connections.
- Routing Polarization: Arises when inter-Pod paths are unevenly mapped to intra-Pod spine switches, causing bottlenecks.
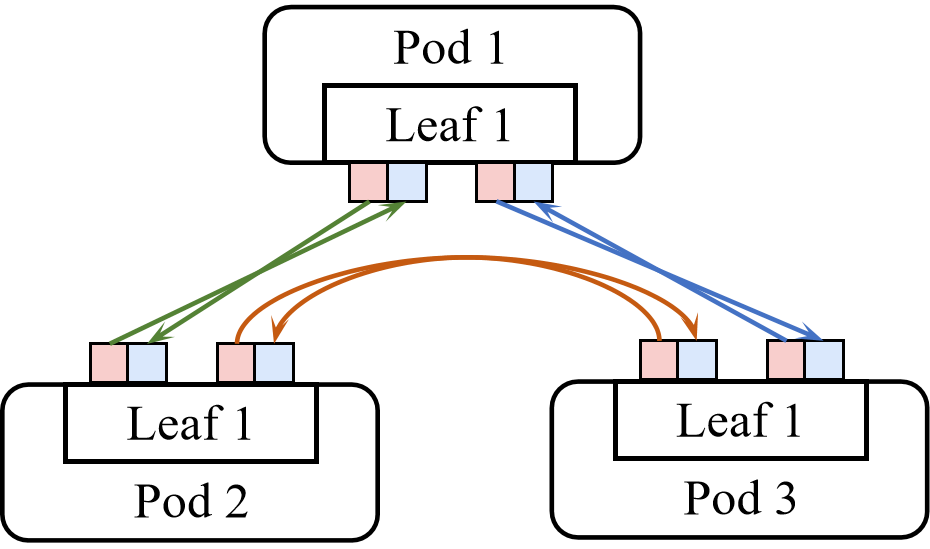
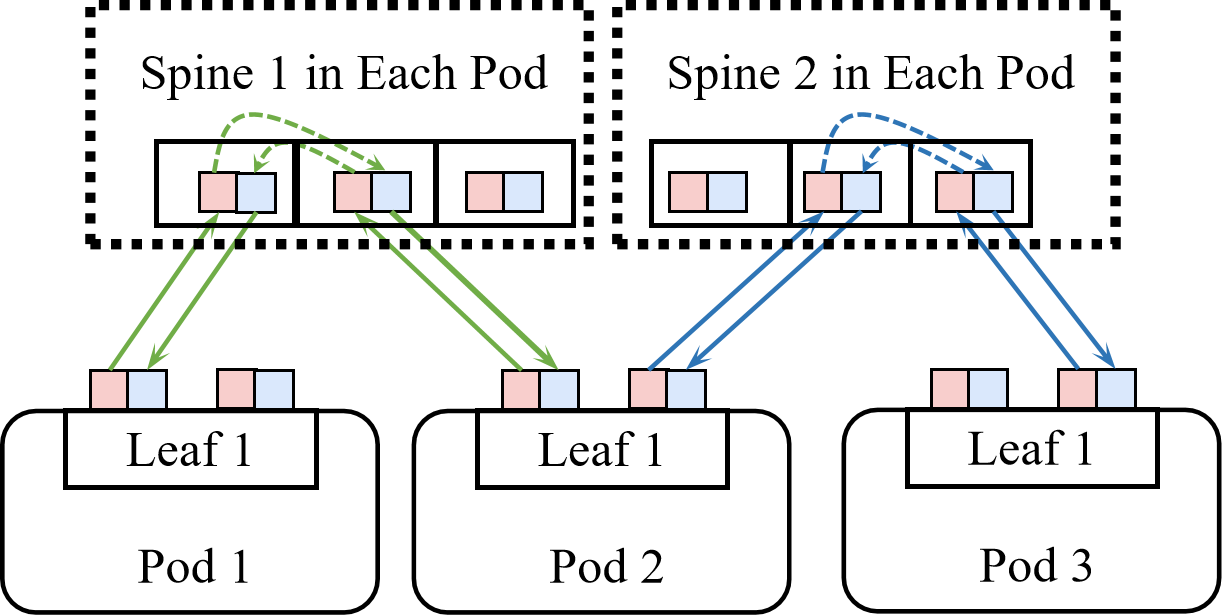
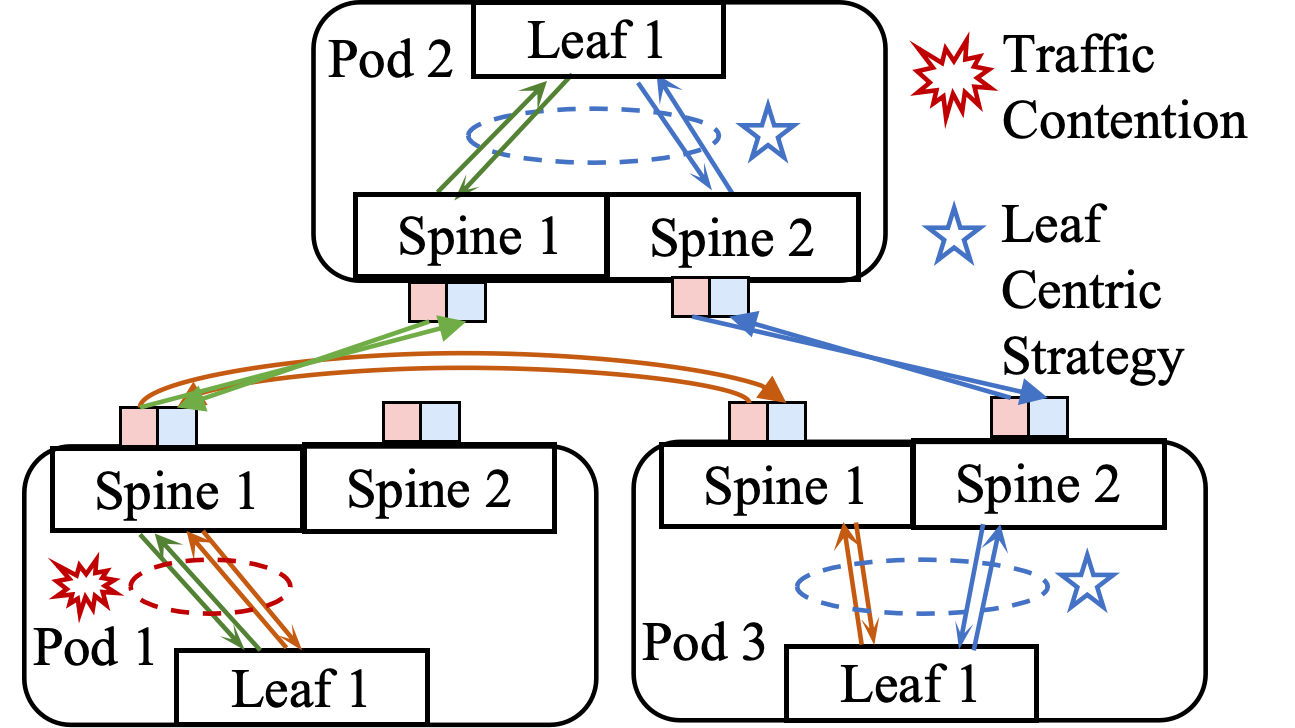
Figure 3: Illustration of routing polarization due to misaligned logical choices, contrasted with balanced leaf-centric design.
Design Requirements
A robust logical topology must:
- Preserve L2 protocol compatibility (bidirectional links).
- Avoid routing polarization (uniform intra-Pod link utilization).
- Be computationally tractable (preferably polynomial-time complexity).
The paper formulates an ILP that encapsulates leaf-level demands, intra-Pod link multiplicity (τ), and logical topology variables. It demonstrates that, when intra-Pod connections are sparse (τ=1), the logical topology problem is NP-complete due to equivalence with the multi-coloring problem. However, with τ≥2, polynomial-time algorithms—exploiting matrix decomposition theorems—enable contention-free topology computation.
Algorithmic Framework and Intra-Pod Design
The LumosCore methodology hinges on:
- Symmetric Matrix Decomposition: Enables division of traffic demand matrices into balanced components.
- Integer Matrix Decomposition: Further splits demand matrices across available spine switches, ensuring bandwidth spread and minimizing polarization.
- Heuristic-Decomposition Algorithm: Realizes logical topology computation with O(η6logη) complexity, where η is the leaf count.
A critical insight is that intra-Pod design, especially setting τ=2 (each leaf connects to each spine via two links), guarantees polynomial-time solvability and eliminates routing polarization. For τ=1, a greedy algorithm suffices only under restrictive demand constraints.
Large-Scale Simulation and Empirical Evaluation
The paper deploys RapidAISim for flow-based simulation on clusters up to 16,384 GPUs, benchmarking LumosCore against Pod-centric, Clos, and Helios approaches. Comprehensive tests leverage real ML workload traces and systematically explore cluster scale, load, and routing strategies.
Numerical Highlights:
- LumosCore (leaf-centric, τ=2) achieves up to 19.27% improvement in job runtime (JRT) relative to Pod-centric design (Figure 4).
- 99.16% reduction in logical topology computation time versus MIP-based leaf-centric approaches (Figure 5).
- Leaf-centric (τ=2) sustains performance parity with Clos networks at a fraction of hardware cost.
- For jobs with substantial cross-Pod communication, average JRT reductions remain significant, and the performance advantage persists across cluster scale and workload intensity.
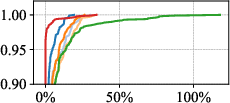
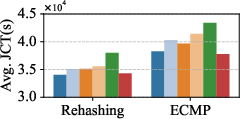
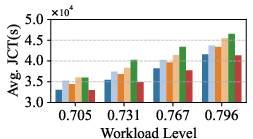
Figure 4: CDF of JRT slow down ratio—LumosCore achieves lower slowdowns and shorter tails.
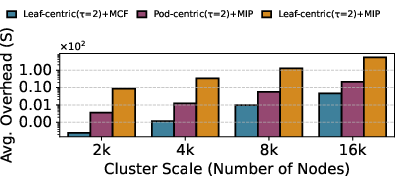
Figure 5: Comparison of topology computation overhead—LumosCore provides orders-of-magnitude efficiency gains.
Robustness and Practical Considerations
Extensive robustness checks demonstrate:
- Superior performance across ECMP and rehash-based load balancing regimes.
- Strong scalability: consistent advantage from 2,048 to 16,384 GPUs.
- JCT improvements notably exceed JRT due to queueing dynamics.
Hash polarization remains a distinct concern for multi-tier hash-based load balancing. However, routing polarization, addressed by LumosCore’s leaf-centric paradigm, is orthogonal; integrating both approaches yields additive benefits.
ML Traffic Patterns and Applicability
ML workloads exhibit highly regular yet skewed communication patterns: Tensor Parallelism (TP), Pipeline Parallelism (PP), Data Parallelism (DP), and Expert Parallelism (EP) are mapped to hierarchical network domains.
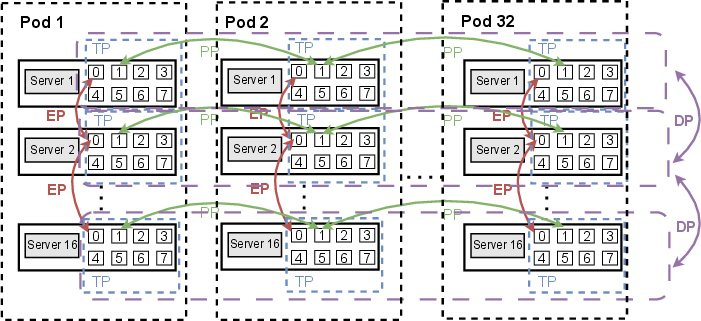
Figure 6: Communication patterns for Megatron (TP-PP-DP-EP) highlight regular structure for physical topology engineering.
LumosCore exploits these patterns by proactively engineering leaf-level requirements, ensuring physical and logical topology alignment.
Implications, Limitations, and Future Directions
Practically, LumosCore’s tractable topology computation enables dynamic reconfiguration at the granularity of ML tasks, supporting both industrial and SME deployments. Theoretical advances—the use of decomposition theorems—may generalize to other resource allocation problems in disjoint-path constrained networks. However, generating optimal leaf-level requirements and tight integration with advanced communication primitives (e.g., low-latency MoE scheduling) are open areas for further research.
Future developments in AI system design will likely demand even more granular and adaptive topology engineering. As OCS hardware matures and ML workload complexity rises, robust polynomial-time design methodologies such as LumosCore will become increasingly central to cluster scalability and throughput optimization.
Conclusion
LumosCore establishes a foundational leaf-centric logical topology design paradigm for OCS-based GPU clusters, rigorously eliminating routing polarization via careful intra-Pod architecture and efficient matrix decomposition algorithms. Empirical evaluation substantiates notable throughput gains and massive computational overhead reductions. The work provides both immediate practical tools and theoretical routes for next-generation AI infrastructure engineering.