Beta-Scheduling: Momentum from Critical Damping as a Diagnostic and Correction Tool for Neural Network Training
Published 30 Mar 2026 in cs.LG and cs.AI | (2603.28921v1)
Abstract: Standard neural network training uses constant momentum (typically 0.9), a convention dating to 1964 with limited theoretical justification for its optimality. We derive a time-varying momentum schedule from the critically damped harmonic oscillator: mu(t) = 1 - 2*sqrt(alpha(t)), where alpha(t) is the current learning rate. This beta-schedule requires zero free parameters beyond the existing learning rate schedule. On ResNet-18/CIFAR-10, beta-scheduling delivers 1.9x faster convergence to 90% accuracy compared to constant momentum. More importantly, the per-layer gradient attribution under this schedule produces a cross-optimizer invariant diagnostic: the same three problem layers are identified regardless of whether the model was trained with SGD or Adam (100% overlap). Surgical correction of only these layers fixes 62 misclassifications while retraining only 18% of parameters. A hybrid schedule -- physics momentum for fast early convergence, then constant momentum for the final refinement -- reaches 95% accuracy fastest among five methods tested. The main contribution is not an accuracy improvement but a principled, parameter-free tool for localizing and correcting specific failure modes in trained networks.
The paper introduces a layer-level diagnostic using physics-derived momentum scheduling to rapidly achieve critical damping for improved convergence.
It presents an optimizer-agnostic approach leveraging error-localized gradient attribution to accurately locate and surgically repair problematic neural network layers.
Empirical results on ResNet-18/CIFAR-10 show 1.9× faster convergence and significant compute savings compared to standard training methods.
Diagnostic Momentum Scheduling and Gradient Attribution for Layer-Level Neural Network Repair
Introduction
This work introduces a unified pipeline for diagnosing and repairing neural network failures by leveraging the oscillator model of stochastic gradient descent (SGD) with momentum to identify layer-level architectural bottlenecks responsible for specific error patterns. The pipeline connects regimen classification based on damping theory, error-localized gradient attribution, and surgical correction using physics-motivated momentum scheduling. The method is shown to deliver optimizer-agnostic diagnostics, outperform parameter-level selection strategies, and considerably accelerate convergence through zero-parameter momentum schedules (2603.28921).
Oscillator Model and Momentum Scheduling
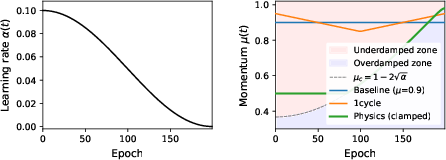
The theoretical foundation is the equivalence between SGD with momentum and a damped harmonic oscillator, as previously formalized by Qian. The global critical damping condition is specified as μ(t)=1−2α(t), which prescribes momentum as a deterministic function of the learning rate, annihilating the need for manual tuning.
The empirical validation demonstrates that momentum schedules derived from this criterion:
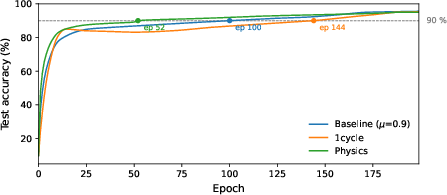
Result in 1.9× faster convergence to intermediate accuracy (90%) compared to standard constant-momentum and heuristic 1cycle schedules.
Achieve competitive final accuracy and exhibit strictly monotonic training curves during the high learning-rate phase.
Figure 1: Cosine annealing learning rate schedule and corresponding momentum trajectories. The physics curve traces the critical damping schedule μc=1−2α. Regions of underdamping and overdamping are shaded.
Figure 2: Test accuracy during training: physics-based scheduling (green) converges to 90\% at epoch 52, outperforming both baseline and 1cycle approaches.
The regime scan, based on epoch-by-epoch comparison of actual versus critical momentum, confirms that the standard μ=0.9 schedule is underdamped in 85% of training epochs, with the physics-based approach maintaining near-critical damping throughout.
Figure 3: Damping regime classification across 200 epochs shows that the physics approach remains at or near critical damping whereas baseline training is predominantly underdamped.
Diagnostic Pipeline: From Failure Localization to Surgical Repair
Error-Localized Gradient Attribution
The pipeline computes per-layer gradient norms using only misclassified test examples to localize the architectural sources of error. This diagnostic identifies a sparse set of problematic layers (e.g., layer3, conv1, layer2 in ResNet-18), with clear dichotomy between anomalous and healthy subsystems.
Cross-Optimizer Invariance
A salient outcome is that problematic layers identified via error-localized gradients on SGD-trained models exhibit 100% overlap with those identified from Adam-trained models, despite distinct optimization paths and error counts. This strongly suggests that the diagnostic captures persistent architectural limitations rather than optimizer-specific artifacts.
Layer- vs. Parameter-Level Correction
Empirical comparisons of correction strategies reveal:
Layer-group-level surgical retraining fixes more errors (62) than parameter-level selection (42–46), with significantly lower introduction of new errors.
The best variant (iKFAD-informed selection) achieves a net +22 error reduction and 82% compute savings compared to full-model retraining.
Cross-optimizer diagnostic transfer is perfect, though applying physics-based correction to Adam-trained models reveals the need for hyperparameter tuning due to scale differences introduced by the optimizer.
Implications for Large-Scale and Modular Networks
The pipeline's architectural focus and optimizer-agnosticism position it as a viable tool for diagnosis and repair in much larger models, including transformers and LLMs. The authors propose direct extensions to these domains, such as identifying error-concentrating transformer layers on factuality and bias probes, and targeted LoRA adaptation.
The method complements and extends previous approaches such as ROME, MEMIT, and Representation Engineering by targeting the localization of errors to specific computational layers and providing a mechanism for layer-level intervention rather than distributed or parameter-sparse edits.
Momentum Scheduling: Practical and Theoretical Impact
The oscillator-derived schedule, μ(t)=1−2α(t), not only accelerates training convergence but also reduces optimizer hyperparameter redundancy by collapsing the learning rate–momentum search space to a single dimension.
A hybrid momentum schedule—physics-scheduled momentum until 90% accuracy, then constant μ=0.9 for the final phase—combines rapid early convergence with underdamped late-phase exploration, consistently achieving the fastest path to target accuracy.
Limitations and Future Work
All empirical results are from single-seed runs on ResNet-18/CIFAR-10. Key directions for extension include multi-seed validation, benchmarking on additional architectures and datasets (CIFAR-100, ImageNet, ViT), and scaling to LLMs. Correction efficacy for Adam-trained models requires further optimizer-specific tuning.
An observed side effect is introduction of some new errors upon layer-group correction; this can potentially be mitigated by finer partitioning (e.g., block-level correction), regularization strategies (such as EWC), and iterative repair.
Conclusion
This work demonstrates that physical diagnostic analogies, particularly the critical damping formulation for SGD momentum, can be operationalized into a robust, optimizer-agnostic pipeline for layer-level error attribution and “surgical” repair in neural networks. Noteworthy outcomes include:
Optimizer-invariant identification of bottleneck layers via error-localized gradient attribution,
Substantial compute savings and superior efficacy of layer-level versus parameter-level correction,
A prescriptive, zero-parameter momentum schedule with strong empirical acceleration of convergence,
A diagnostic methodology that is extensible to emerging architectures such as transformers and LLMs.
By shifting the paradigm from untargeted retraining to targeted, diagnosis-driven interventions, the framework enables more principled, resource-efficient, and interpretable model repair methodologies. The implications extend toward rigorous model auditing, efficient mitigation of failure cases in high-stakes applications, and automated debugging in future large-scale neural architectures.