- The paper introduces a unified architecture that fuses unsupervised object decomposition with hierarchical dynamics to capture temporal structure and causal relations.
- It employs a two-stage training process that first enforces spatial specialization before engaging dynamic prediction, ensuring object-centric representations.
- Empirical results on robotic tasks validate improved reconstruction and next-state prediction, demonstrating scalable multi-object tracking capabilities.
Hierarchical Causal Latent State Machines for Object-Centric World Modeling
Motivation and Context
The design of world models capable of predictive video representation learning is centered on three unresolved axes: the capacity to discover and track discrete objects, the ability to model temporal structure at multiple effective scales, and the encoding of explicit causal relations. Existing methods such as V-JEPA, DreamerV3, and SlotFormer offer considerable advances, but none join these principles in a unified, end-to-end differentiable architecture. HCLSM directly addresses these limitations, introducing a model that performs unsupervised object decomposition, learns hierarchical temporal dynamics, and induces an interpretable causal representation of object interactions.
Architectural Overview
HCLSM’s architecture is composed of five tightly integrated layers:
- Perception: Video frames are encoded by a ViT backbone into unified patch-based representations with explicit temporal position encodings.
- Object Decomposition: Slot Attention with a spatial broadcast decoder (SBD) encourages each slot to specialize in reconstructing a distinct spatial region, while an existence head manages slot proposal and death. The relational structure is derived by a GNN operating on slot pairs.
- Hierarchical Dynamics: Three distinct modules implement a hierarchy: per-object selective state space models (SSM) capture continuous low-level dynamics; a sparse event-driven transformer processes discrete changes; a goal transformer operates at the highest abstraction level via compressed event summaries.
- Causal Reasoning: Object-to-object influences are mediated by GNN edge weights and regularized using DAG constraints in the spirit of NOTEARS.
- Continual Memory: Hopfield-like architectures and EWC maintain long-term memory and stability.
A two-stage training process is critical: the model is first forced to spatially specialize via SBD loss before activating dynamics and prediction losses, ensuring structured, object-aware representations before learning to predict temporal evolution.

Figure 1: Spatial decomposition emerges from the slot-wise spatial broadcast decoder: each slot reconstructs distinct spatial regions, as shown by alpha masks and overlay segmentation.
Training and Implementation Details
The model, with 68 million parameters, is evaluated on the PushT robotic manipulation task using data from Open X-Embodiment. The full pipeline is implemented in PyTorch, featuring a custom Triton kernel that accelerates SSM computation by 38× compared to a PyTorch baseline. Numerical stability in bfloat16 precision is achieved through careful initialization and bounded activations; slot tracking adopts a fully differentiable GPU-native Sinkhorn-Knopp implementation to avoid CPU overhead.
A critical design insight is that naive end-to-end training collapses all structure: early activation of the JEPA loss steers the slots into undifferentiated distributed codes, prohibiting specialization. The two-stage protocol—reconstruction before prediction—mirrors a developmental separation between recognition and dynamics learning and is essential for successful emergence of object-centricity.
Empirical Results and Analysis
Quantitatively, two-stage HCLSM training yields 0.008 MSE for next-state prediction and a complementary SBD reconstruction loss of 0.0075. While the prediction loss is numerically lower without SBD ($0.002$), the resultant representations are purely distributed and lack object specialization. The diversity penalty is reduced with SBD-enabled training, supporting the claim that object slots become more differentiated.
Visually, slot decomposition demonstrates partial spatial specialization: in PushT, despite the task containing three effective objects, 32 slots remain active, with most objects being split across multiple slots, highlighting the demand for further constraints or adaptive slot mechanisms to match slot count with semantic object count.
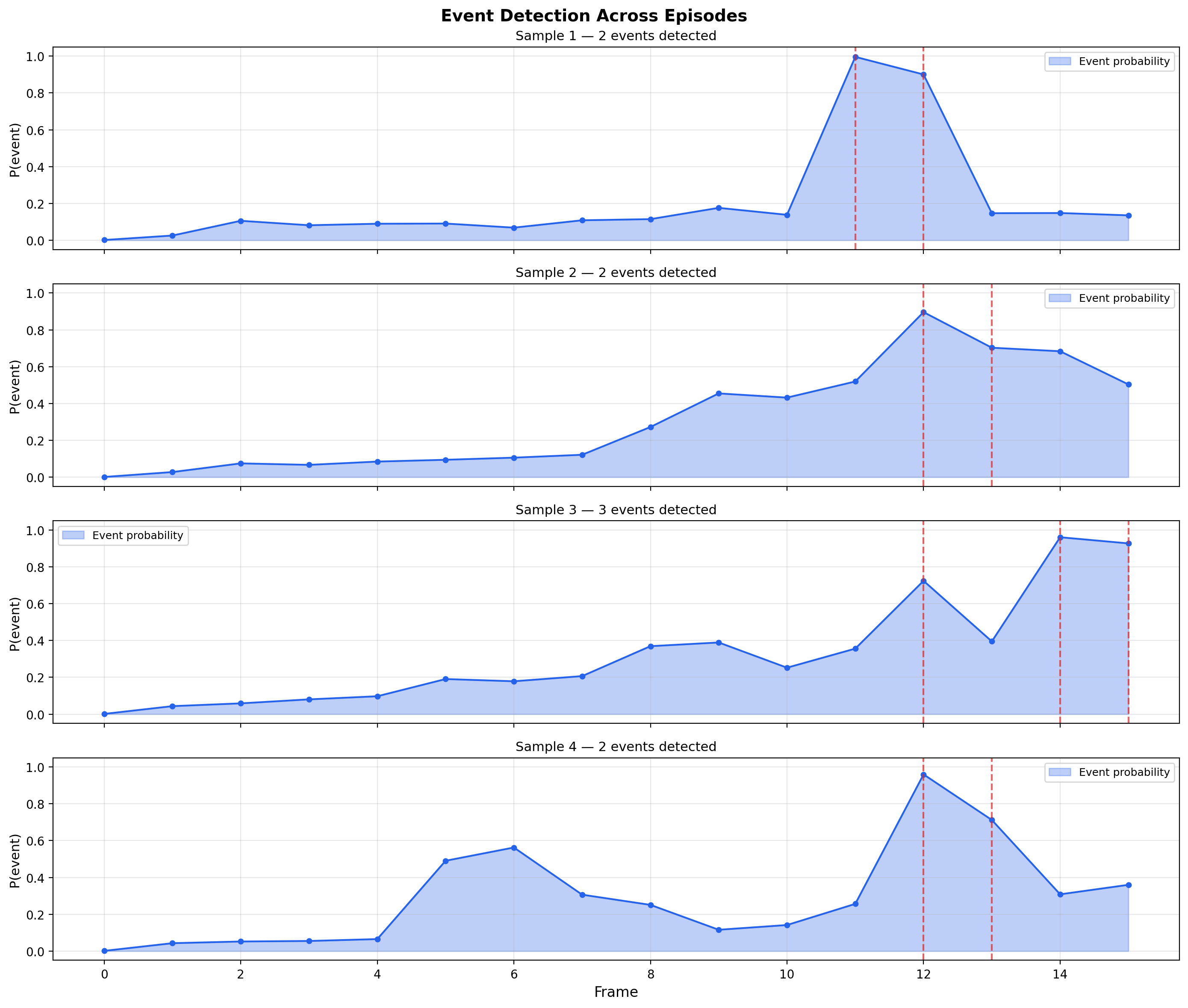
Figure 2: The event detector identifies temporally sparse state transitions, enabling efficient higher-level sequence modeling with a sparse transformer.
Event boundary detectors, trained contrastively from the SSM output, reliably identify meaningful state changes—such as contact or manipulation events—demonstrating robust hierarchical modeling.
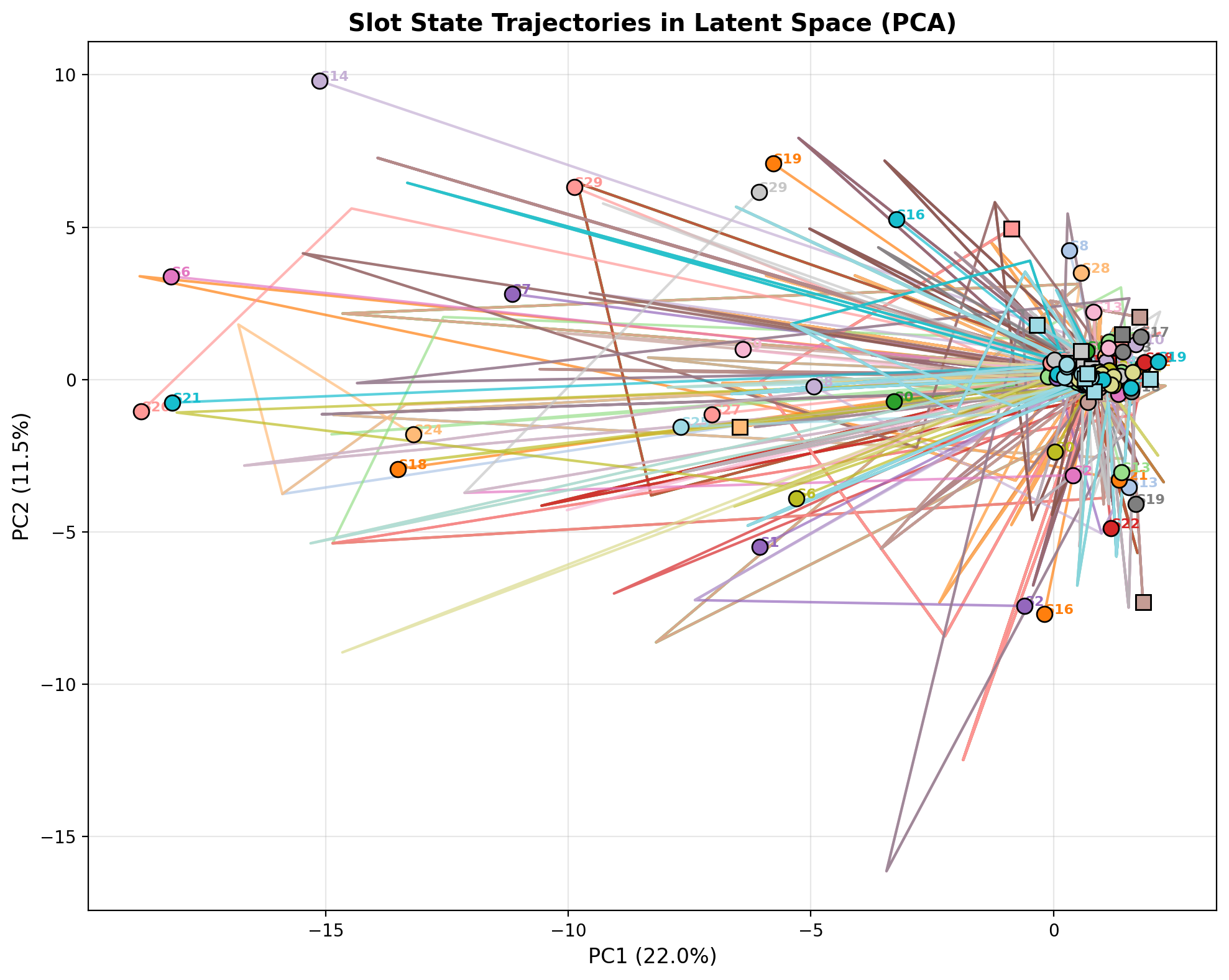
Figure 3: Slot trajectories lie on structured, smoothly evolving manifolds, punctuated by reorientations at event boundaries, verifying that learned states support meaningful temporal abstraction.
Slot state dynamics projected via PCA exhibit smooth, distinct trajectories for each slot, clustered around major events, corroborating the hierarchical separation and structured dynamics modeled by HCLSM.
Practical and Theoretical Implications
HCLSM establishes a pathway for real-world world models that support abstraction, factorization, and interpretability—a precondition for counterfactual reasoning and compositional planning required in model-based RL and robotics. Its integration of compressed transformers and event detectors suggests scalable modeling of long-horizon, multi-object interaction episodes without strictly per-step quadratic complexity.
Several system limitations remain: persistent slot over-provisioning, underutilized causal adjacency matrices (which collapse to all-zeroes under current regularization), extreme seed sensitivity in training, and difficulties scaling beyond 68M parameters in bfloat16. Addressing these issues—through adaptive slot selection, robust causal induction, pre-trained vision backbones, and improved numerical guarantees—would permit deployment in more complex environments and seamless integration with hierarchical planners.
Future Directions
Potential research avenues include:
- Adopting adaptive slot attention or learned slot codebooks to dynamically match slot allocation to object count, potentially leveraging methods outlined in MetaSlot or Adaptive Slot Attention.
- Training on richer, more object-dense interactions and diverse tasks (e.g., ALOHA benchmarks).
- Leveraging pre-trained vision-LLMs for more semantic spatial targets in SBD.
- Integrating the learned world model with trajectory optimization or stochastic planners (CEM/MPPI) for closed-loop control.
- Investigating scaling laws for causal graph recovery and planning performance relative to SSM size, transformer depth, and slot regularization.
Conclusion
HCLSM provides a comprehensive and extensible framework for object-centric, temporally hierarchical, and causally grounded video world modeling. Empirical results confirm that a separation of spatial specialization and temporal prediction is necessary for strong object-centricity. While significant obstacles remain for practical deployment at scale, HCLSM’s release details technical routes for further improvements and sets a new benchmark for unified object-centric latent world models.
(2603.29090)